
ホームページ >テクノロジー周辺機器 >AI >チャットボットはナレッジ グラフを通じてどのように質問に答えますか?
チャットボットはナレッジ グラフを通じてどのように質問に答えますか?

- PHPz転載
- 2023-04-17 09:13:021054ブラウズ
序文
1950年、チューリングは画期的な論文「コンピューティング機械とインテリジェンス」(コンピューティング機械とインテリジェンス)を発表し、ロボットに関する有名な判断原理を提案しました - 図チューリングテスト、別名チューリングテストチューリング判決は、第三者が人間とAIマシンの反応の違いを区別できない場合、そのマシンは人工知能を持っていると結論付けることができると指摘しています。
2008 年、マーベルの「アイアンマン」の AI 執事であるジャービスは、AI が人間 (トニー) に投げかけられたさまざまな問題を解決するのにどのように正確に役立つかを人々に知らせました。 ..

2023 年の初め、2C の方法でテクノロジー業界にブレイクした無料のチャット ロボット ChatGPT が世界を席巻しました。
UBS の調査レポートによると、月間アクティブ ユーザー数は 1 月に 1 億人に達し、今も成長を続けており、史上最も急速に成長している消費者となっています。さらに、その所有者であるOpenAIは、月額42ドルのProバージョンをリリースした後、月額約20ドルと言われているPlusバージョンを間もなくリリースする予定です。新しいものに月次アクティブ ユーザー数、トラフィック、商業収益化が何億人もいる場合、その背後にあるさまざまなテクノロジーに興味が湧きますか?たとえば、チャットボットはどのようにして大量のデータを処理し、クエリを実行するのでしょうか?
ChatGPT を体験した友人も同じ感想を持っています。Tmall Elf や Xiao Aitong Shoes よりも明らかに賢く、「無敵のスピーキング スキル」と自然言語を備えたチャット ロボットです。処理ツール、大規模な言語モデル、人工知能アプリケーション。完全に擬人化されたコミュニケーションだけでなく、質問内容のコンテキストに基づいて人間と対話し、推論して作成し、不適切と判断した質問を拒否することもできます。
現時点での評価は賛否両論ですが、技術開発の観点からはチューリングテストにも合格する可能性もあります。質問させてください、それとコミュニケーションをとるとき、その(初心者にとっては)豊富な知識と甘美な答えは、まったく知らないと、相手が人間であるか機械であるかを区別することは困難です(
おそらくここが危険なところです - ChatGPT のコアは依然として深層学習のカテゴリに属しており、多くのブラック ボックスと説明不能な部分があります! )。
では、チャットボットはどのようにして 3,000 億の単語と 1,750 億のパラメーターからトレーニング コーパスを迅速に整理して出力し、コンテキストと組み合わせて、コミュニケーションに自由に応答できるのでしょうか?人間が「習得」した知識に基づいて?実際には、チャットボットにも脳があり、私たち人間と同じように学習し、訓練する必要があります。
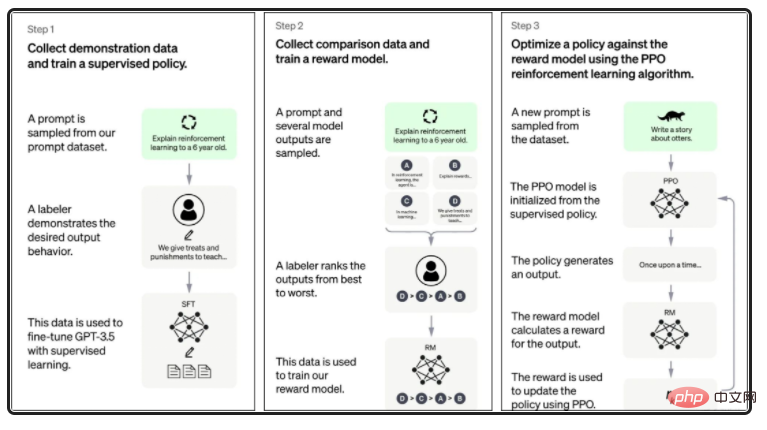 図 2: ChatGPT の学習とトレーニングのチャート (出典公式 Web サイト)
図 2: ChatGPT の学習とトレーニングのチャート (出典公式 Web サイト)
NLP (自然言語処理)、ターゲット認識、マルチモーダル認識などを使用して、大量のテキスト、画像、その他の非構造化ファイルをセマンティクスに従ってナレッジ グラフに構造化します。このナレッジ グラフはチャットの頭脳です。ロボット。
# 図 3: 医療を例に挙げると、人工知能は複数のソースからのデータを質問と回答、検索などのシナリオに変換します。ナレッジ グラフでは、
#ナレッジ グラフは何で構成されていますか?
#ナレッジ グラフは何で構成されていますか?
points(エンティティ) と edges (リレーションシップ) で構成されており、以下に示すように、人、物、事、その他の関連情報を統合して包括的なグラフを形成できます。
#図 4: 文字点と属性エッジで構成されるグラフ (サブグラフ)
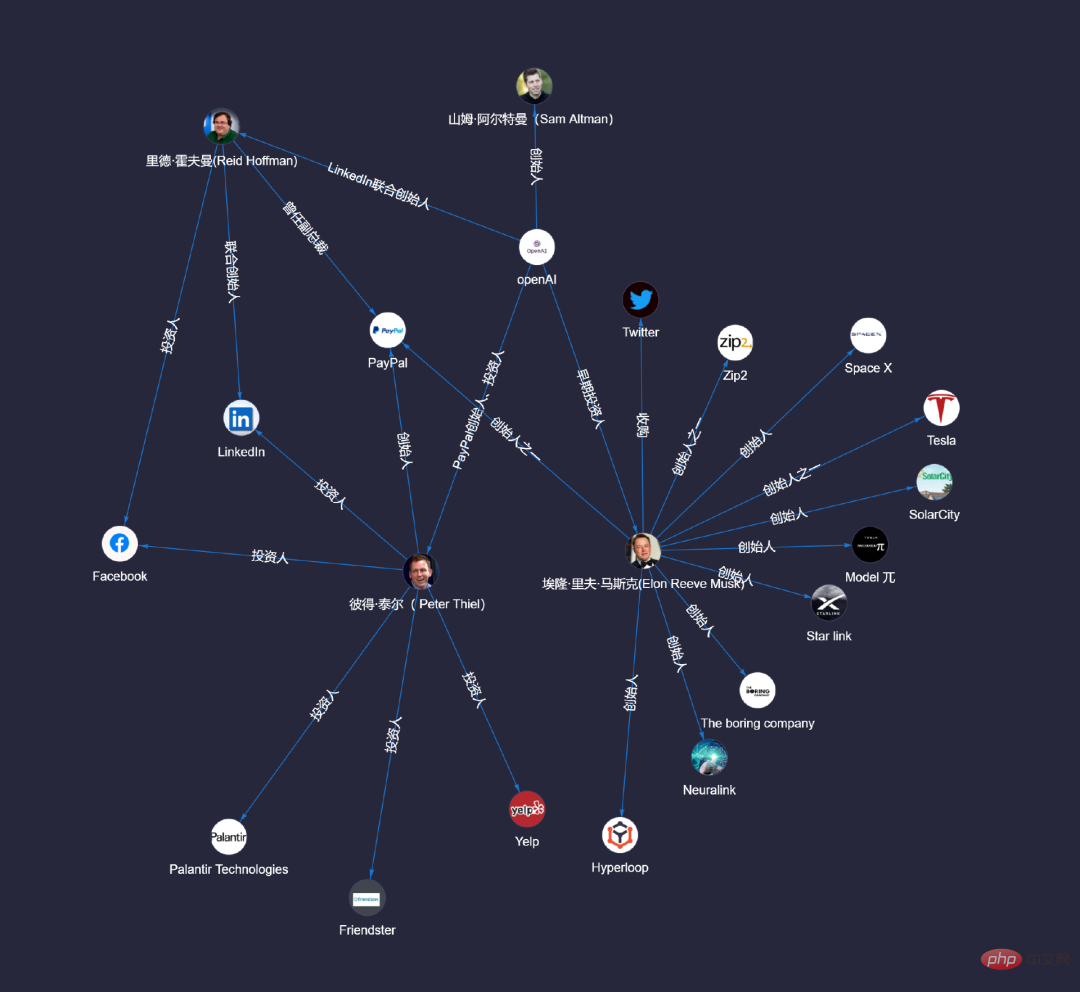
「OpenAI の創設者は誰ですか?」と尋ねられると、チャットボットの脳は独自のナレッジ ベースをすばやく検索して見つけ出し、まずユーザーの質問からターゲットを特定します。 ## をクリックします。 # "penAI" と入力すると、ユーザーの質問に基づいて、別の ポイント が表示されます - 創設者 "Sam Altman"。
図 5: エッジによるポイント「OpenAI」から別のポイント「Sam Altman」への接続
実際、 「OpenAI の創設者は誰ですか」と尋ねると、チャットボットは、point を囲むすべての写真を独自のナレッジ ベースに関連付けます。したがって、私たちが関連する質問をすると、すでに私たちの予測が予測されています。たとえば、「マスク氏は OpenAI の創設チームのメンバーですか?」と尋ねると、次の図に示すように、コマンドを 1 つだけ実行するだけで、すでにメンバー全員にクエリが実行されています (1,000 人から 1 人のケースを複製)。
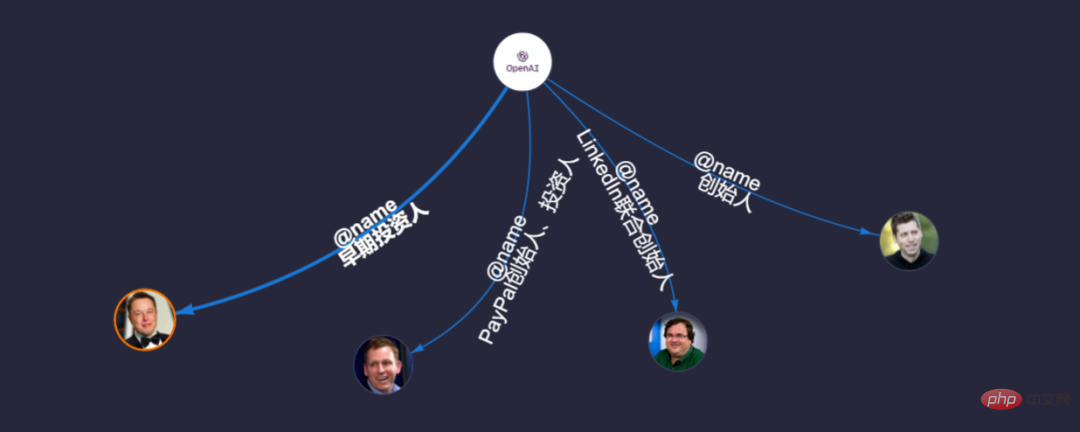
# #さらに、ライブラリに他の「学習教材」が含まれている場合、その「脳」は、以下に示すように、「人工知能ロボットの製品は何ですか?」などの関連画像も関連付けられます。

もちろん、チャットボットは人間と同じで、次の図に示すように、質問への回答はチャットボット自身の知識の蓄えによって制限されます。人の脳が決定する 不幸か、賢いかどうかの判断は何でしょうか?人間の観点から見ると、最も単純な基準の 1 つは、1 つの例から推論を導き出す能力です。
孔子はこう言いました。「怒らなければ悟りは開かれない、怒らなければ怒らない。三つのことで反撃しなければ、あなたは死ぬだろう」
——論語・シュルピアン
2000 年前から、孔子は次の重要性を強調していました。ある事例から推論を導き、ある事例から他の事例への類似点を導き、類似点を描くことができます。チャットボットの場合、回答の質はナレッジ グラフを構築するコンピューティング能力に依存します。
一般知識グラフの構築では、長い間 NLP と視覚的プレゼンテーションに重点が置かれてきましたが、計算の適時性やデータ モデリングは無視されてきたことを私たちは知っています。柔軟性、クエリなどの問題(計算) プロセスと結果の解釈可能性 。特に今、全世界がビッグデータ時代からディープデータ時代に移行しつつあり、これまで SQL や NoSQL に基づいて構築された従来のグラフの欠点により、大規模で複雑で動的なデータを効率的に処理することができなくなりました。単独の相関関係、洞察のマイニングと分析?では、従来のナレッジグラフが直面する課題にはどのような特徴があるのでしょうか?
まず、コンピューティング能力が低い (非効率) 。 SQL または NoSQL データベース システムを使用して構築されたナレッジ グラフの基礎となるアーキテクチャは非効率的であり、高次元のデータを高速に処理できません。
第二に、柔軟性が低いです。リレーショナル データベース、ドキュメント データベース、または低パフォーマンスのグラフ データベースに基づいて構築されたナレッジ グラフは、通常、基礎となるアーキテクチャによって制限され、エンティティ間の実際の関係を効率的に復元できません。例えば、単純なグラフしかサポートしていないものもあり、多面的なグラフデータを入力すると情報が失われやすくなったり、グラフの作成にコストがかかったりすることがあります。
第三に、これは単なる表面的なものです。 2020 年以前は、基盤となるコンピューティング能力に実際に注目している人はほとんどおらず、ほぼすべてのナレッジ グラフ システム構築は NLP と視覚化のみに焦点を当てていました。基礎となるコンピューティング能力のないナレッジ グラフは、オントロジーとトリプルの抽出と構築のみを目的としており、詳細なクエリ、速度、解釈可能性などの問題を解決する能力はありません。
[注: ここでは、従来のリレーショナル データベースとグラフ データベースのパフォーマンスの比較については説明しません。興味のある読者は次の記事を参照してください: グラフ データベースとグラフ データベースとはリレーショナル データベースの違い ?グラフデータベースはどのような問題を解決しますか? ]
ここまで、チャットロボットのインテリジェントナレッジグラフの話題と、もう一つの最先端技術であるグラフデータベース(グラフコンピューティング)の技術分野について話しました。 。
グラフデータベース(グラフコンピューティング)とは何ですか?
グラフ データベース[参考文献 1 を参照] は、エンティティの属性を保存できるグラフ理論の応用です。情報と実体の関係情報。定義上、Graph (グラフ)はノードpoint#に基づいています。 ##[参考資料 2 を参照] および edge[参考資料 2 を参照] によって定義されるデータ構造。
#グラフはナレッジ グラフ ストレージおよびアプリケーション サービスの基盤であり、強力なデータ関連付け機能と知識表現機能を備えているため、学術界や産業界で人気があります。感嘆の声。
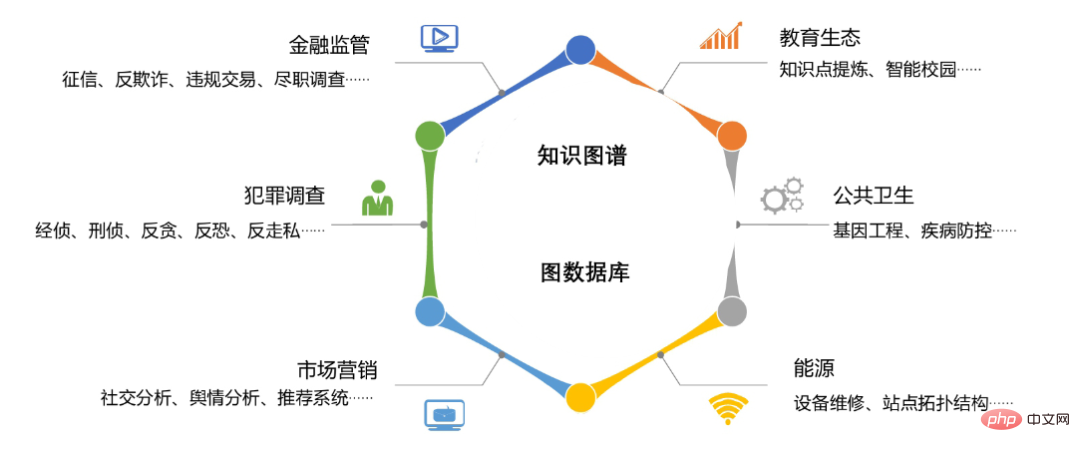 図 8: グラフ データベースとナレッジ グラフは、マーケティング、犯罪捜査、金融監督、教育環境、公共分野で使用されています。健康 エネルギーやエネルギーなどの分野でのアプリケーション シナリオ
図 8: グラフ データベースとナレッジ グラフは、マーケティング、犯罪捜査、金融監督、教育環境、公共分野で使用されています。健康 エネルギーやエネルギーなどの分野でのアプリケーション シナリオ
上図に示すように、リアルタイム グラフ データベース (グラフ コンピューティング) エンジンの助けを借りて、業界さまざまなデータをリアルタイムで分析できます。それらの間に深い相関関係があるさまざまな関係を見つけたり、人間の脳が及ばない最適な知的パスを見つけることさえできます。これはグラフ データベースの高次元性によるものです。
高次元とは何ですか?グラフは、人間の脳の思考習慣に準拠し、現実世界を直感的にモデル化できるツールとして機能するだけでなく、深い洞察 (ディープ グラフ トラバーサル) を確立することもできます。
たとえば、膨大な量のデータや情報の中で、一見無関係に見える 2 つ以上のエンティティ間の微妙な関係を捉える「バタフライ効果」は誰もが知っています。データ処理アーキテクチャでは、グラフ データベース (グラフ コンピューティング) テクノロジの助けなしにこれを達成することは非常に困難です。 [注: グラフ データベースとグラフ コンピューティングを区別する方法についてはここでは説明しません。興味のある友人は次の記事を読んでください: 「グラフ」からの課題は何ですか?グラフ データベースとグラフ コンピューティングを区別するにはどうすればよいですか? 1 つの記事で簡単に説明]
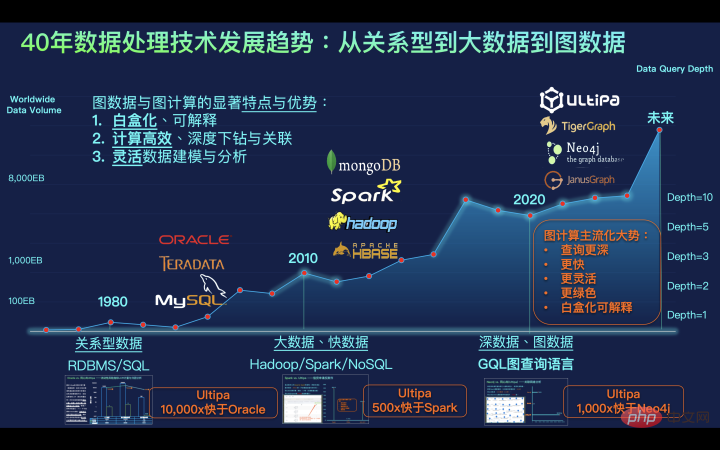
# 図 9: 過去 40 年間にわたるデータ処理テクノロジの開発傾向はリレーショナルからビッグデータから画像データへ
リスク管理は典型的なシナリオの 1 つです。 2008 年の金融危機は、米国第 4 位の投資銀行であるリーマン ブラザーズの破綻によって引き起こされましたが、創業 158 年の投資銀行の破綻がその後の国際金融機関の一連の破綻の引き金となるとは誰も予想していませんでした。銀行業界この傾向...その影響の広さと範囲は予想外であり、リアルタイム グラフ データベース (グラフ コンピューティング) テクノロジーにより、すべての主要なノード、リスク要因、およびリスクのリスク伝播経路を見つけることができます...そして管理 あらゆる財務リスクについて事前に警告します。

現在、多くのメーカーがナレッジ グラフを構築できるにもかかわらず、現実には、グラフ企業 100 社中、(高性能) グラフ データベースを使用している (低パフォーマンス) グラフ データベースは 5 社未満であることを指摘する必要があります。コンピューティング能力をサポートするため。5%)。 Ultipa は、高密度同時実行性、動的プルーニング、マルチレベル ストレージなどの革新的な特許技術によって実現された、世界で唯一の第 4 世代リアルタイム グラフ データベースです。コンピューティングの高速化 あらゆるサイズのデータセットに対する超詳細なリアルタイムドリルダウン。 まず、高いコンピューティング能力です。 企業の最終受益者 (実際の管理者および大株主とも呼ばれる) を見つけることを例に挙げます。この種の問題の課題は、現実世界では、最終受益者と検査対象の企業体の間に多くのノード (ペーパーカンパニー体) が存在することが多いこと、または複数の自然人または法人間に複数の投資または株式保有パスが存在する可能性があることです。他の企業に対する支配。従来のリレーショナル データベースやドキュメント データベース、さらにはほとんどのグラフ データベースでも、この種のグラフ浸透の問題をリアルタイムで解決することはできません。 Ultipa Yingtu リアルタイム グラフ データベース システムは、上記の課題の多くを解決します。その高同時実行性のデータ構造と高性能コンピューティングおよびストレージ エンジンは、他のグラフ システムよりも 100 倍以上の速さで詳細なマイニングを実行し、リアルタイム (マイクロ秒以内) ネットワークで最終的な受益者を見つけたり、巨大な投資関係を発見したりできます。一方、マイクロ秒のレイテンシは同時実行性とシステム スループットの向上を意味し、ミリ秒のレイテンシを主張するシステムと比較してパフォーマンスが 1000 倍向上します。 現実のシナリオを例に挙げると、中国中信銀行の前頭取である孫徳氏は、金融的手段を利用して複数の「影の会社」を設立し、利益の移転を完了しました。 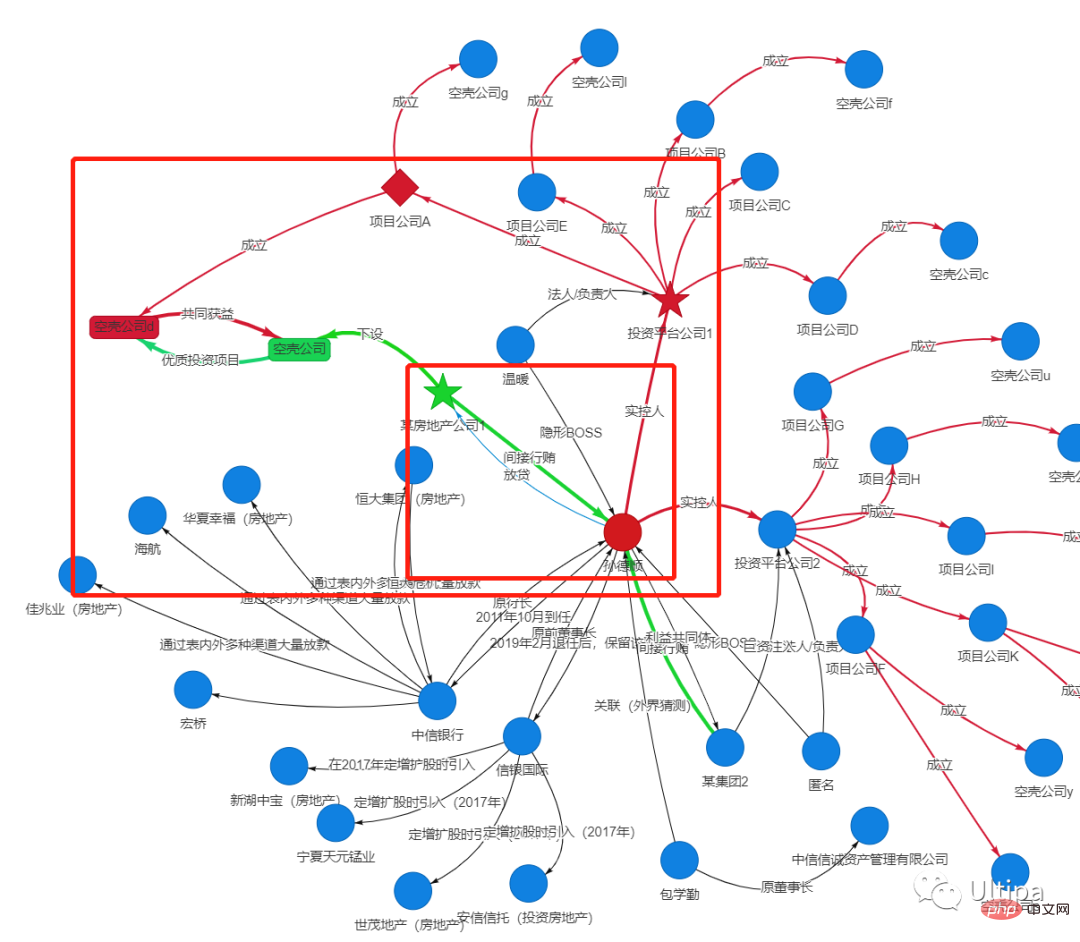
図 11: Sun Deshun は、シャドウ カンパニーの複数の層がネストされた、非常に複雑な構造を持つ複数の「ファイアウォール」を設計しました。監視を回避して利益を得るために層ごとに層を作ります。

図 12: 接続: 孫徳順 - CITIC 銀行 - ビジネス オーナー - (空の殻会社) 投資プラットフォーム会社 - Sun Deshun
##上の図に示すように、Sun Deshun は # を使用します。 # #CITICBank には 企業の上司 # に融資を与える公的権限があり、それに応じて企業の上司は次のことを行うことができます。投資名を送信する、または高品質の投資プロジェクト、投資機会などを送信する、両当事者がそれぞれの ペーパーカンパニー を通じて直接取引を完了する、または事業主は孫徳順が実際に管理する投資プラットフォーム会社に注入するために巨額の資金を送金し、プラットフォーム会社はこれらの資金を使って投資します。上司が提供するプロジェクトを実行し、お金を使ってお金を稼ぎ、全員が協力して利益と配当を共有し、最終的には利益のコミュニティを形成します。
Ultipa リアルタイムグラフデータベースシステムは、ホワイトボックスの浸透により、人と企業、企業と企業の複雑な関係を掘り起こし、最後の人物をその背後に閉じ込めます。リアルタイムのシーン。#2 つ目は柔軟性です。
グラフ システムの柔軟性は非常に広範なトピックになる可能性があり、これには通常、データ モデリング、クエリと計算ロジック、結果の表示、インターフェイスのサポート、スケーラビリティなどが含まれます。 。
データ モデリングはすべてのリレーショナル グラフの基礎であり、グラフ システム (グラフ データベース) の基礎となる機能と密接に関連しています。たとえば、ClickHouse のような列データベース上に構築されたグラフ データベース システムは、トランザクション ネットワークの最も一般的な特徴は 2 つの口座間の複数の送金ですが、ClickHouse は複数の送金を 1 つにマージする傾向があるため、金融取引グラフをまったく保持できません。このアプローチはデータの混乱 (歪み) を引き起こす可能性があります。片面グラフの概念に基づいて構築された一部のグラフ データベース システムは、トランザクションを表現するために頂点 (エンティティ) を使用する傾向があり、その結果、データ量が増大し (ストレージの無駄)、グラフ クエリの複雑さが指数関数的に増大します (適時性)。変更)、差異)。
インターフェイスのサポート レベルは、ユーザー エクスペリエンスに関係します。簡単な例を挙げると、本番環境のグラフ システムが CSV 形式のみをサポートしている場合、グラフに含める前にすべてのデータ形式を CSV 形式に変換する必要があり、効率が低すぎることは明らかですが、これは事実です。多くのグラフ システムに存在します。
クエリと計算ロジックの柔軟性についてはどうですか?引き続き「バタフライ効果」を例に挙げてみましょう。マップ内の 2 人の人、物、または物の間には、何らかの因果関係 (強い相関関係) 効果があるでしょうか。単純な 1 ステップの相関関係であれば、従来の検索エンジン、ビッグ データ NoSQL フレームワーク、さらにはリレーショナル データベースでも解決できますが、ニュートンとジンギスカンの相関などの深い相関関係の場合、どのように計算するかが重要になります。 ?毛織物?
Ultipa Yingtu リアルタイム グラフ データ システムは、上記の問題を解決する複数の方法を提供します。たとえば、ポイントツーポイントのディープ パス検索、マルチポイント ネットワーク検索、特定のファジー検索条件に基づくテンプレート マッチング検索、Web 検索エンジンに似たグラフ指向のファジー テキスト パス検索などです。
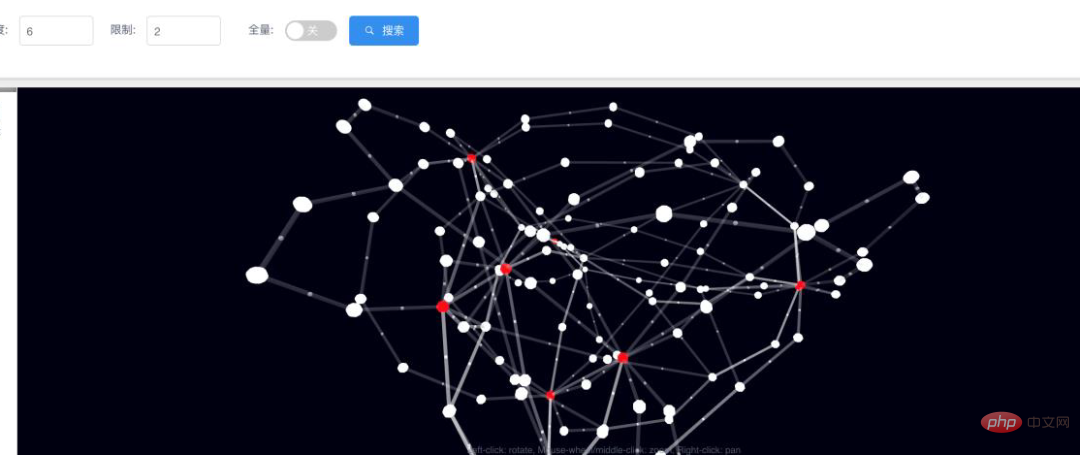
図 13: 検索深度 ≥ 6 ホップの大きなグラフ (サブグラフの形成) で視覚化されたリアルタイム ネットワーキングの結果
グラフには、柔軟なフィルタリング条件に基づく点、エッジ、パスの検索、パターン認識、コミュニティなど、高い柔軟性とコンピューティング能力に依存する必要があるタスクが他にもたくさんあります。 、顧客グループの検出、ノードのすべてまたは特定の隣接ノードの検索 (またはより深い隣接ノードの再帰的検出)、グラフ内の類似した属性を持つエンティティまたは関係の検索... つまり、グラフ コンピューティング能力のサポートがないナレッジ グラフは、魂はなく、肉体は表面的なものにすぎません。さまざまな挑戦的で詳細な検索機能を完了できません。
3 つ目は、ローコードであり、目に見えるものがそのまま得られるということです。
上記の高いコンピューティング能力と柔軟性に加えて、グラフ システムはホワイトボックス化 (解釈可能) かつフォームベース (ローコード、ノーコード) である必要もあります。 )および WYSIWYG 方式でビジネスを強化する機能。

図 14: ゼロ コードのワンクリック検索。検索範囲の値を入力するだけで、2D、3D、リスト、テーブルが表示されます。異種データ融合のための複数のビジュアル モードの柔軟な変換です。
Ultipa リアルタイム グラフ データベース システムでは、開発者は Ultipa GQL を 1 文入力するだけで、ビジネス担当者は、プリセットのフォームベースのプラグインを使用して、ゼロコードでビジネスにクエリを実行できます。このアプローチは、従業員の作業効率の向上、組織の運用コストの削減、部門間のコミュニケーションの壁の解消に大きく役立ちました。
要約すると、ナレッジ グラフとグラフ データベースの組み合わせは、あらゆる分野でデータセンターのビジネス構築を加速するのに役立ちますが、金融業界などでは専門性とセキュリティが必要です。信頼性、安定性、リアルタイム性、精度が高い業界では、リレーショナル データベースを使用して上位層のアプリケーションをサポートしても、良好なデータ処理パフォーマンスを提供できず、さらには完全なデータ処理タスクを提供することもできません。ペンのトレーサビリティ、正確な測定モニタリング、および早期警告パフォーマンスを備えたグラフ データベース (グラフ コンピューティング) テクノロジーだけが、組織が戦略をより適切に計画し、数千マイルを獲得できるようにすることができます。
この時点で、私は突然、ソフォンロックという非常に興味深い点について言及したヒット作「三体問題」を思い出しました。おそらくトリソラ文明は、地球の技術がそれを超えることを阻止するために、人類の基礎科学を妨害して様々な妨害を行ってきたということだろう。人類文明の飛躍は基礎科学の発展と大躍進にかかっており、人類の基礎科学を阻止することは、地球の文明レベル向上の道を阻止することに等しい… もちろん著者が言いたいのは、グラフ技術は人工知能に属するインフラの一つ、正確にはグラフ技術=拡張知能説明型AIであり、開発プロセスにおいてAIとビッグデータが融合することによって必然的に生み出されるものです。
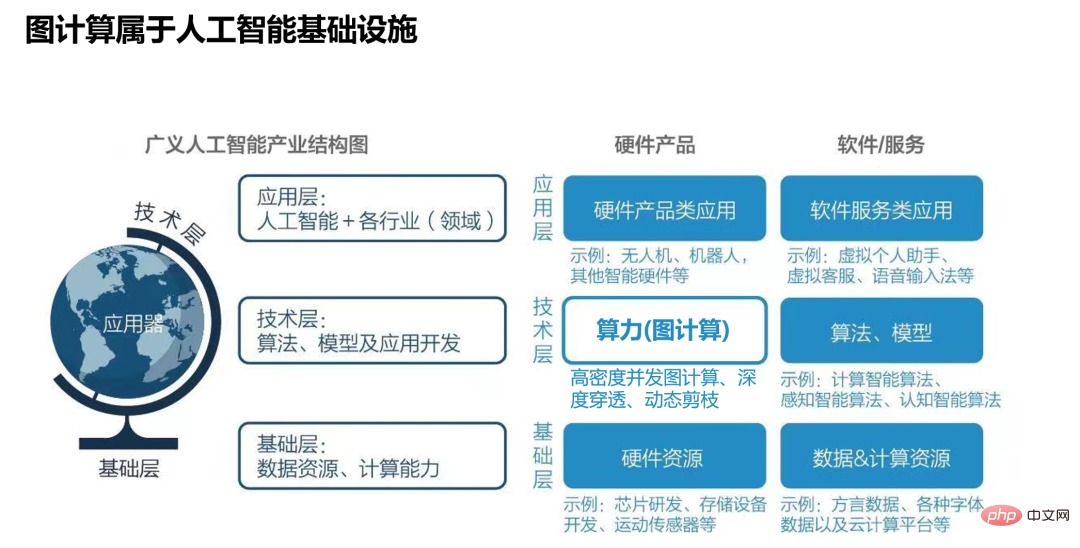
図 15: 人工知能インフラストラクチャに属するグラフ データベース (グラフ コンピューティング) 技術
以上がチャットボットはナレッジ グラフを通じてどのように質問に答えますか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。