
ホームページ >テクノロジー周辺機器 >AI >ChatGPT と Bing Chat がストーリーを紡ぐのが得意な理由
ChatGPT と Bing Chat がストーリーを紡ぐのが得意な理由

- PHPz転載
- 2023-04-17 08:37:021372ブラウズ

なぜ AI チャットボットはナンセンスをでっち上げるのでしょうか?また、その出力を完全に信頼できるでしょうか?この目的のために、私たちは数人の専門家に質問し、これらの AI モデルがどのように機能するのかをさらに深く掘り下げました。答えを見つけるために働きます。
「イリュージョン」 - 人工知能における偏見のある用語
AI チャットボット (OpenAI の ChatGPT など) は、「大規模言語モデル」 (LLM) インテリジェンスと呼ばれる一種の人工知能に依存して、彼らの反応。 LLM は、人間が自然に書いたり話したりするのと同じように、「自然言語」のテキスト言語を読み取って生成するために、何百万ものテキスト ソースでトレーニングされたコンピューター プログラムです。残念ながら、彼らも間違いを犯します。
学術文献では、AI 研究者はこれらのエラーを「幻覚」と呼ぶことがよくあります。このトピックが主流になるにつれて、このラベルはますます物議を醸しており、AI モデルを擬人化する (人間のような特徴があると示唆する) か、それを暗示しるべきではないときにモデルを AI モデルに割り当てると考える人もいます。彼らは自分たちで選択できるということ)。さらに、商用 LLM の作成者は、出力自体に責任を負うのではなく、誤った出力を AI モデルのせいにする言い訳として幻想を使用する可能性もあります。
それでも、生成 AI は非常に新しい分野であり、これらの高度に技術的な概念を広く一般に説明するには、既存のアイデアから比喩を借用する必要があります。この場合、同様に不完全ではあるものの、「作話」という言葉の方が「幻覚」という比喩よりも優れた比喩であると感じます。人間の心理学において、「フィクション」とは誰かの記憶の隙間を指し、脳は意図的に他人を騙すことなく、忘れられた経験を説得力のある架空の事実で埋めます。 ChatGPT は人間の脳のようには機能しませんが、「フィクション」という用語は、(意図的に騙すのではなく) 創造的にギャップを埋める原理に基づいて機能するため、おそらく「フィクション」という用語の方が適切な比喩です。これについては以下で説明します。
架空の問題
AI ボットが誤解を招く、または中傷的な効果をもたらす可能性のある虚偽の情報を生成すると、大きな問題になります。最近、ワシントン・ポストは、ChatGPT が他人にセクハラをした法学者のリストに自分を含めていたことを発見した法学教授について報じた。しかし、この件は虚偽であり、ChatGPTによって完全に捏造されました。同じ日に、アルスはまた、オーストラリアの市長が、収賄で有罪判決を受けて投獄されたというChatGPTの主張も完全にでっち上げであることを発見したと報告した。
ChatGPT の開始後すぐに、人々は検索エンジンの終焉を主張し始めました。しかし同時に、ChatGPT の多くの架空の事例がソーシャル メディア上で広く流通し始めました。 AI ボットは、存在しない書籍や研究、教授が書いていない出版物、偽の学術論文、偽の法的引用、存在しない Linux システムの機能、非現実的な小売店のマスコット、無意味な技術詳細を発明しました。
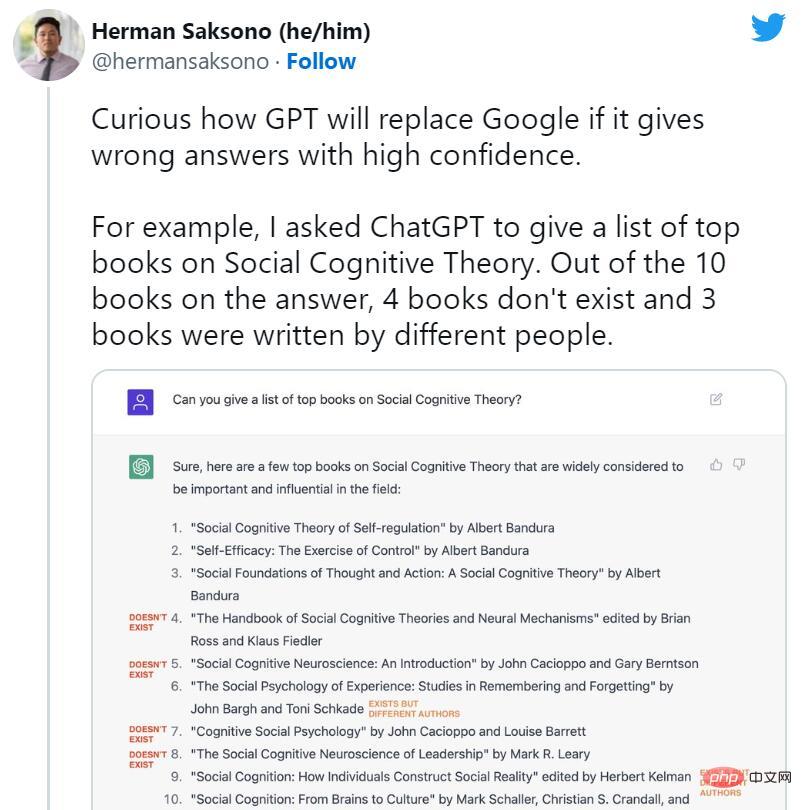
しかし、ChatGPT はカジュアルなフィクションを好む傾向があるにもかかわらず、フィクションが抑圧されていることが、まさに今日私たちがこの問題について話している理由です。一部の専門家は、ChatGPT は、一部の質問への回答を拒否したり、回答が不正確な可能性がある場合に通知したりできるという点で、通常の GPT-3 (その前モデル) よりも技術的に改良されていると指摘しています。
大規模言語モデルの専門家であり、Scale AI のプロンプト エンジニアであるライリー グッドサイド氏は、「ChatGPT の成功の主な要因は、フィクションをうまく抑制し、多くの一般的な問題を目立たなくすることにあります。以前のバージョンと比較して、 、ChatGPT はでっち上げの傾向が大幅に低いです。」
ブレーンストーミング ツールとして使用すると、ChatGPT の論理的な飛躍とごっこが創造的なブレークスルーにつながる可能性があります。しかし、ChatGPT を事実の参照として使用すると、実害を及ぼす可能性があり、OpenAI はそれを認識しています。
このモデルがリリースされた直後、OpenAI CEO の Sam Altman 氏はツイートしました、「ChatGPT は機能が非常に限られていますが、ある意味で誤解を招く印象を与えるには十分です。これに依存するのは間違いです」 「今は重要なことは何もありません。これは進歩のプレビューです。堅牢性と信頼性の観点からは、やるべきことがまだたくさんあります。」
その後のツイート 記事の中で、彼は次のようにも書いています。多くのことはありますが、危険なのは、大部分の場合、盲目的に自信を持ち、間違っていることです。」
何が起こっているのですか?
ChatGPT の仕組み
ChatGPT や Bing Chat などの GPT モデルがどのように「架空化」されるかを理解するには、GPT モデルがどのように機能するかを知る必要があります。 OpenAI はまだ ChatGPT、Bing Chat、さらには GPT-4 の技術的な詳細を発表していませんが、2020 年には GPT-3 (その前身) を紹介する研究論文が発表されると予想されます。
研究者は、「教師なし学習」と呼ばれるプロセスを使用して、GPT-3 や GPT-4 などの大規模な言語モデルを構築 (トレーニング) します。これは、モデルのトレーニングに使用するデータに特別な注釈やマークが付けられていないことを意味します。このプロセスでは、モデルに大量のテキスト (何百万もの書籍、Web サイト、記事、詩、原稿、その他のソース) が供給され、一連の単語ごとに次の単語の予測を繰り返し試行します。モデルの予測が実際の次の単語に近い場合、ニューラル ネットワークはパラメーターを更新して、その予測につながったパターンを強化します。
逆に、予測が正しくない場合、モデルはパフォーマンスを向上させるためにパラメーターを調整し、再試行します。この試行錯誤のプロセスは、バックプロパゲーションと呼ばれる手法ですが、モデルが間違いから学習し、トレーニング中に徐々に予測を改善できるようになります。
したがって、GPT は、データセット内の単語と関連する概念の間の統計的な関連性を学習します。 OpenAI のチーフサイエンティスト、イリヤ・サツケヴァー氏のように、GPT モデルはこれよりもさらに進んで、次善のトークンをより正確に予測できるように現実の内部モデルを構築すると信じている人もいますが、この考えには議論の余地があります。 GPT モデルがニューラル ネットワーク内で次のトークンを提案する方法の正確な詳細はまだ不明です。

GPT モデルの現在の波では、このコア トレーニング (現在は「プレトレーニング」と呼ばれることが多い) は 1 回だけ行われます。この後、トレーニングされたニューラル ネットワークを「推論モード」で使用できるようになり、ユーザーはトレーニングされたネットワークに入力を入力して結果を取得できるようになります。推論中、GPT モデルへの入力シーケンスは常に人間によって提供され、これは「プロンプト」と呼ばれます。プロンプトはモデルの出力を決定します。プロンプトを少しでも変更すると、モデルによって生成される結果が大幅に変わる可能性があります。
たとえば、GPT-3 に「Mary had a...」というプロンプトを表示すると、通常は「子羊」で文が完成します。これは、GPT-3 のトレーニング データ セットにはおそらく「メアリーには子羊がいた」という例が何万件もあり、妥当な出力となるためです。ただし、「病院で、メアリーは」など、プロンプトにさらにコンテキストを追加すると、結果が変わり、「赤ちゃん」や「一連の検査」などの単語が返されます。
これが ChatGPT の興味深い点です。なぜなら、ChatGPT は単なる直接的なテキスト生成ジョブではなく、エージェントとの会話として設定されているからです。 ChatGPT の場合、入力プロンプトは、最初の質問または発言から始まる ChatGPT との会話全体であり、シミュレートされた会話が始まる前に ChatGPT に提供される特定の指示も含まれます。このプロセス中、ChatGPT は、それとユーザーが書いたすべての内容に関する短期記憶 (「コンテキスト ウィンドウ」と呼ばれます) を維持し、ユーザーと「会話」しながら、会話のテキスト生成タスクを完了しようとします。
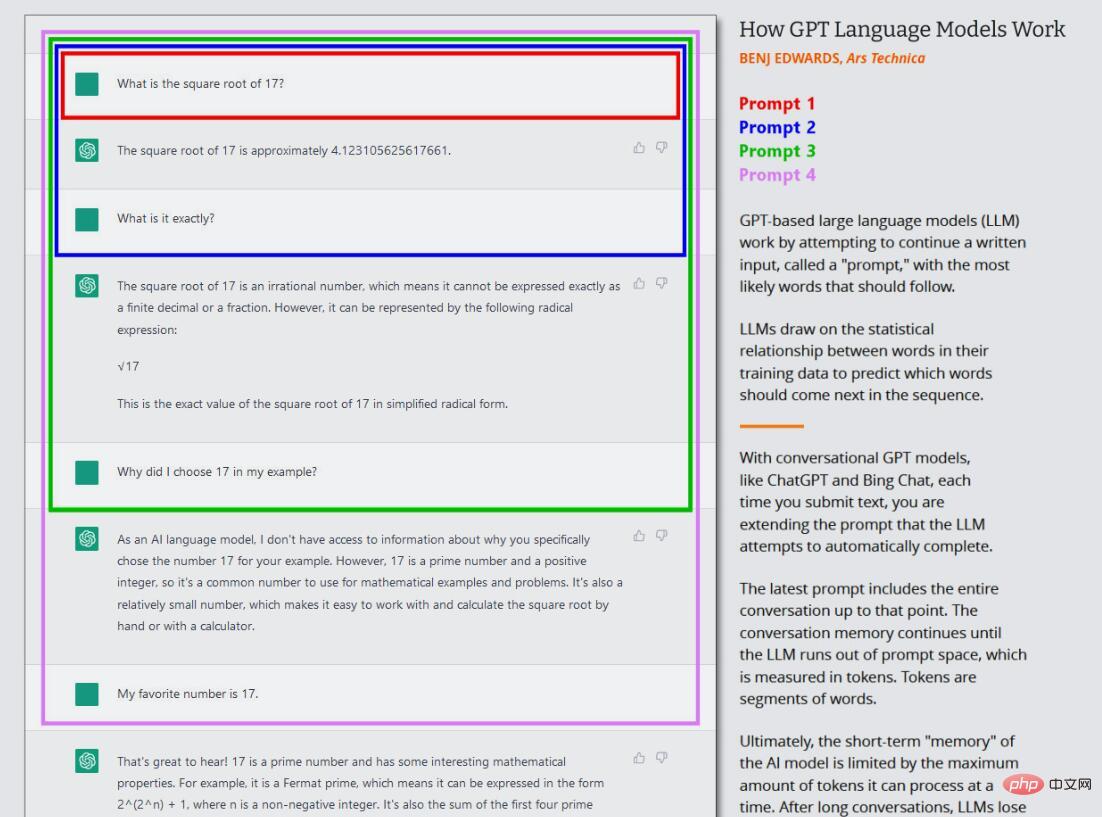
さらに、ChatGPT は人間が書いた会話テキストでもトレーニングされるという点で通常の GPT-3 とは異なります。 OpenAI は、ChatGPT の最初の立ち上げページに次のように書いています、「私たちは教師あり微調整を使用して初期モデルをトレーニングしました。人間の AI トレーナーは、ユーザーと AI の両方の当事者として機能する会話を提供します。アシスタント。私たちはトレーナーにモデル作成の提案を提供します。
ChatGPT は、人間によるフィードバックによる強化学習 (RLHF) Big Tweak と呼ばれる手法を使用して更新されます。この手法では、人間の評価者が好みに基づいて ChatGPT 応答をランク付けし、この情報をフィードします。モデルに戻ります。 RLHF を通じて、OpenAI は「正確に答えられない質問への回答を避ける」という目標をモデルに植え付けることができます。これにより、ChatGPT は、基本モデルよりもフィクションが少なく、一貫した応答を生成できます。しかし、不正確な情報が依然として漏れてしまう可能性があります。
ChatGPT がフィクションを生成する理由
本質的に、GPT モデルの元のデータセットには、事実とフィクションを区別するものは何もありません。
LLM の動作は、依然として活発な研究分野です。これらの GPT モデルを作成した研究者でさえ、最初に開発されたときには誰も予測しなかったテクノロジーの驚くべき特性を今でも発見しています。言語翻訳、プログラミング、チェスなど、現在私たちが目にしている興味深いことの多くを実行できる GPT の能力は、かつて研究者たちを驚かせました。
したがって、ChatGPT がアーティファクトを生成する理由を尋ねると、技術的に正確な答えを見つけるのは困難です。ニューラル ネットワークの重みには「ブラック ボックス」要素があるため、複雑なプロンプトが与えられた場合に正確な出力を予測することは困難 (または不可能) です。それにもかかわらず、私たちはフィクションが生じる基本的な理由をいくつか知っています。
理解ChatGPT虛構能力的關鍵是理解它作為預測機器的角色。當ChatGPT進行虛構時,它正在尋找資料集中不存在的資訊或分析,並用聽起來似是而非的單字填滿空白。 ChatGPT特別擅長編造東西,因為它必須處理的數據量非常大,而且它收集單字上下文的能力非常好,這有助於它將錯誤訊息無縫地放置到周圍的文本中。
軟體開發人員Simon Willison表示,「我認為思考虛構的最佳方法是思考大型語言模型的本質:它們唯一知道怎麼做的事情是根據統計機率,根據訓練集選擇下一個最好的單字。」
在2021年的一篇論文中,來自牛津大學和OpenAI的三位研究人員確定了像ChatGPT這樣的LLMs可能產生的兩種主要類型的謊言。第一個來自其訓練資料集中不準確的來源資料,例如常見的誤解(如,「吃火雞會讓你昏昏欲睡」)。第二種源自於對其訓練資料集中不存在的特定情況進行推論;這屬於前面提到的「幻覺」標籤。
GPT模型是否會做出瘋狂的猜測,取決於AI研究人員所說的「溫度」(temperature)屬性,它通常被描述為「創造力」(creativity)設定。如果創造力被設定得很高,模型就會瘋狂猜測;如果它被設定為低,它將根據它的資料集確定地吐出資料。
最近,微軟員工Mikhail Parakhin在推特上談到了Bing Chat的幻覺傾向,以及產生幻覺的原因。他寫道,「這就是我之前試圖解釋的:幻覺=創造力。它試圖使用其處理的所有資料產生字串的最高機率連續。它通常是正確的。有時人們從未製作過這樣的連續。 」
Parakhin補充道,這些瘋狂的創意跳躍正是LLM有趣的地方。你可以抑制幻覺,但你會發現這樣超級無聊。因為它總是回答“我不知道”,或只回饋搜尋結果中的內容(有時也不正確)。現在缺少的是語調:在這些情況下,它不應該表現得那麼自信。 」
當涉及微調像ChatGPT這樣的語言模型時,平衡創造性和準確性是一個挑戰。一方面,提出創造性回應的能力使ChatGPT成為產生新想法或消除作者瓶頸的強大工具。這也使模型聽起來更人性化。另一方面,當涉及到產生可靠的資訊和避免虛構時,來源材料的準確性至關重要。對於語言模型的開發來說,在兩者之間找到正確的平衡是一個持續的挑戰,但這對於開發一個既有用又值得信賴的工具是至關重要的。
還有壓縮的問題。在訓練過程中,GPT-3考慮了PB級的訊息,但得到的神經網路的大小只是它的一小部分。在一篇被廣泛閱讀的《紐約客》文章中,作者Ted Chiang稱這是一張「模糊的網路JPEG」。這意味著大部分事實訓練資料會遺失,但GPT-3透過學習概念之間的關係來彌補了這一點,之後它可以使用這些概念重新制定這些事實的新排列。就像一個有缺陷記憶的人根據預感工作一樣,它有時會出錯。當然,如果它不知道答案,它會給出最好的猜測。
我們不能忘記提示符在虛構中的作用。在某些方面,ChatGPT是一面鏡子:你給它什麼,它就給你什麼。如果你給它灌輸謊言,它就會傾向於同意你的觀點,並沿著這些路線「思考」。這就是為什麼在改變話題或遇到不想要的回應時,用一個新的提示重新開始是很重要的。ChatGPT是機率性的,這意味著它在本質上是部分隨機的。即使使用相同的提示,它輸出的內容也可能在會話之間發生變化。
所有這些都得出了一個結論,OpenAI也同意這個結論:ChatGPT目前的設計並不是一個可靠的事實資訊來源,也不值得信任。AI公司Hugging Face的研究員兼首席倫理科學家Margaret Mitchell博士認為,「ChatGPT在某些事情上非常有用,例如在縮小寫作瓶頸或提出創意想法時。它不是為事實而建的,因此也不會是事實。就是這麼簡單。 」
說謊能被糾正嗎?
盲目地相信AI聊天機器人是一個錯誤,但隨著底層技術的改進,這種情況可能會改變。自去年11月發布以來,ChatGPT已經升級了幾次,其中一些升級包括準確性的提高,以及拒絕回答它不知道答案的問題的能力。
那麼OpenAI計劃如何讓ChatGPT更準確呢?在過去的幾個月裡,我們多次就這個問題聯繫OpenAI,但沒有得到任何回應。但我們可以從OpenAI發布的文件和有關該公司試圖引導ChatGPT與人類員工保持一致的新聞報道中找到線索。
如前所述,ChatGPT如此成功的原因之一是因為使用RLHF進行了廣泛的訓練。 OpenAI解釋稱,「為了讓我們的模型更安全、更有幫助、更一致,我們使用了一種名為『基於人類反饋強化學習(RLHF)』的現有技術。根據客戶向API提交的提示,我們的標籤器提供所需模型行為的演示,並對來自模型的幾個輸出進行排序。然後,我們使用這些數據對GPT-3進行微調。」
OpenAI的Sutskever認為,透過RLHF進行額外的訓練可以解決幻覺問題。 Sutskever在本月稍早接受《富比士》採訪時稱,「我非常希望,透過簡單地改進這個後續RLHF教會它不要產生幻覺。」

他繼續說,「我們今天做事的方式是僱人來教我們的神經網路如何反應,教聊天工具如何反應。你只需與它互動,它就會從你的反應中看出,哦,這不是你想要的。你對它的輸出不滿意。因此,輸出不是很好,下次應該做一些不同的事情。我認為這是一個很大的變化,這種方法將能夠完全解決幻覺問題。」
其他人並不同意。 Meta的首席人工智慧科學家Yann LeCun認為,目前使用GPT架構的LLM無法解決幻覺問題。但是有一種新出現的方法,可能會在目前架構下為LLM帶來更高的準確性。他解釋稱,「在LLM中增加真實性的最活躍的研究方法之一是檢索增強——向模型提供外部文檔作為來源和支持上下文。透過這種技術,研究人員希望教會模型使用谷歌這樣的外部搜尋引擎,像人類研究人員一樣,在答案中引用可靠的來源,減少對模型訓練中學習到的不可靠的事實知識的依賴。」
Bing Chat和Google Bard已經透過網路搜尋實現了這一點,很快,一個支援瀏覽器的ChatGPT版本也會實現。此外,ChatGPT插件旨在補充GPT-4的訓練數據,它從外部來源檢索信息,如網路和專門建造的資料庫。這種增強類似於有百科全書的人會比沒有百科全書的人更準確地描述事實。
此外,也有可能訓練一個像GPT-4這樣的模型,讓它意識到自己何時在瞎編,並做出相應的調整。 Mitchell認為,「人們可以做一些更深入的事情,讓ChatGPT和類似的東西從一開始就更加真實,包括更複雜的數據管理,以及使用一種類似於PageRank的方法,將訓練數據與'信任'分數聯繫起來…當它對答覆不那麼有信心時,還可以對模型進行微調以對沖風險。」
因此,雖然ChatGPT目前因其虛構問題而陷入困境,但也許還有一條出路,隨著越來越多的人開始依賴這些工具作為基本助手,相信可靠性的改進應該很快就會到來。
以上がChatGPT と Bing Chat がストーリーを紡ぐのが得意な理由の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。