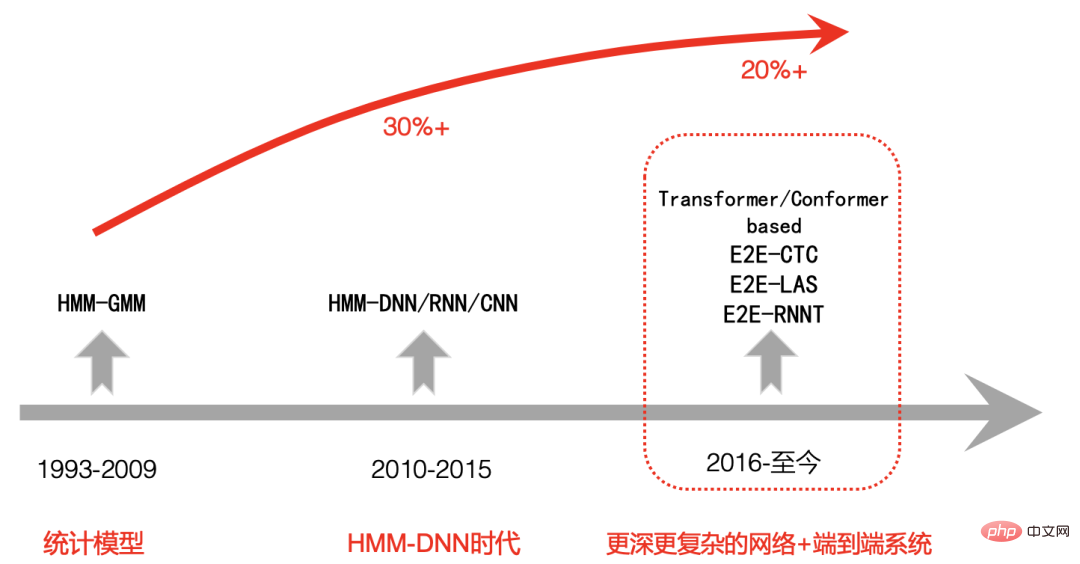
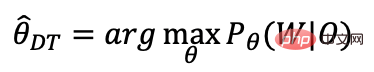10.2|
##5.8 |
|
上記は、それぞれ 2,000 時間と 15,000 時間のビデオ トレーニング データに基づいたステーション B の生活シーンと食事シーンの結果です。Chain と E2E-CTC は、同じコーパスでトレーニングされた拡張言語モデルを使用しています。
E2E-AED および E2E-RNNT は拡張言語モデルを使用せず、エンドツーエンド システムは Conformer モデルに基づいています。
2 番目の表から、単一の E2E-CTC システムの精度は他のエンドツーエンド システムに比べて大幅に劣っているわけではありませんが、同時に E2E-CTC システムには次の特徴があることがわかります。利点:
- ニューラル ネットワークには自己回帰 (AED デコーダーと RNNT 予測) 構造がないため、E2E-CTC システムにはストリーミング、デコード速度、展開コストの点で自然な利点があります。
ビジネスのカスタマイズの観点から、E2E-CTC システムは、さまざまな言語モデル (nnlm および ngram) を外部接続することも容易であり、汎用化の安定性が一般的なオープン フィールドの他のエンドツーエンド システムよりも大幅に優れています。完全にカバーするのに十分なデータがありません。 -
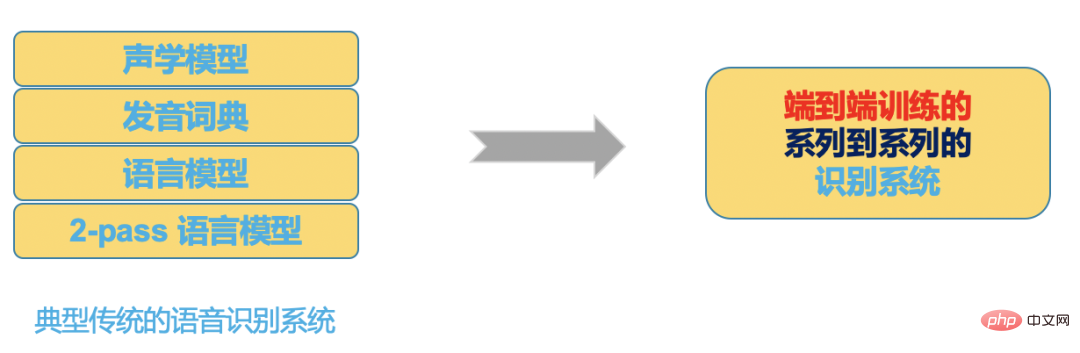
高品質の ASR ソリューション
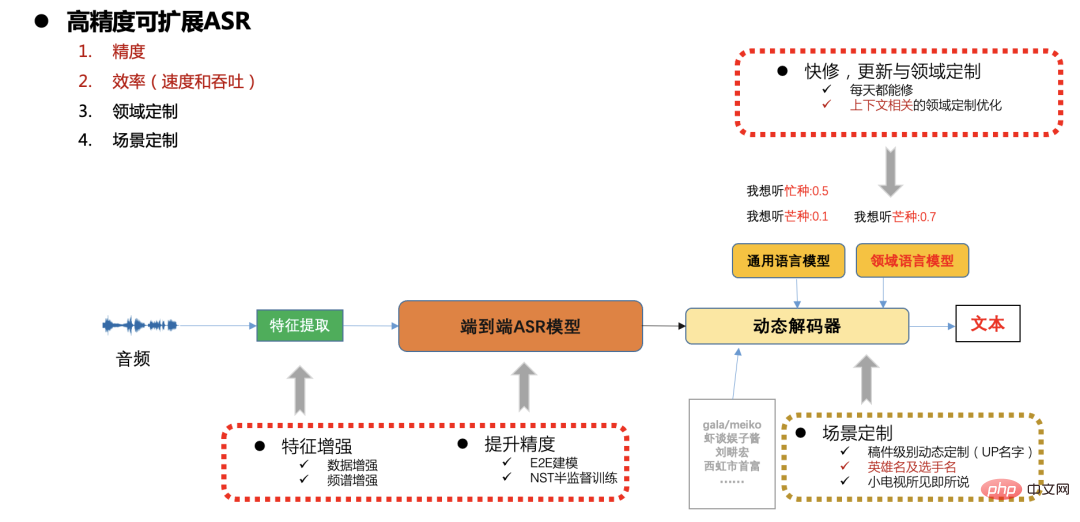
高精度でスケーラブルな ASR フレームワーク

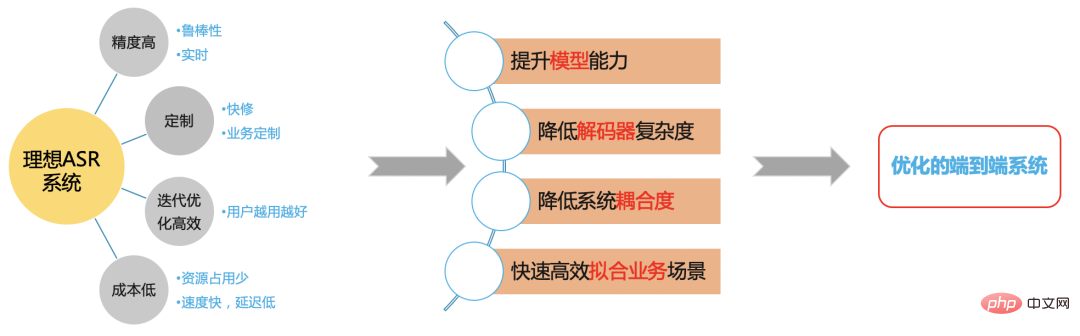
図 7ステーション B の実稼働環境では、速度、精度、リソース消費に対する高い要件があり、また、急速な更新も行われます。さまざまなシナリオとカスタマイズのニーズ (原稿に関連するエンティティの単語、人気のあるゲームやスポーツ イベントのカスタマイズなど)、ここでは、通常、スケーラビリティのカスタマイズを解決するためにエンドツーエンドの CTC システムを使用します。ダイナミック デコーダを通じて問題を解決します。以下では、モデルの精度、速度、スケーラビリティの最適化作業に焦点を当てます。
エンドツーエンドの CTC 識別トレーニング
当社のシステムは漢字と英語の BPE モデリングを使用しており、AED と CTC に基づいたマルチタスク トレーニングの後は、 CTC 部分については、後で識別トレーニングを実行します。エンドツーエンド ラティス フリー mmi を使用します[6][7] 識別トレーニング:
# #従来の識別トレーニングとの違い
a. まず、CPU 上のすべてのトレーニング コーパスに対応するアライメントとデコード ラティスを生成します;
b .トレーニング中、各ミニバッチは事前に生成されたアライメントと格子を使用して分子と分母の勾配をそれぞれ計算し、モデルを更新します。
2. 私たちのアプローチ
a. トレーニング中、各ミニバッチは直接in GPU で分子と分母の勾配を計算し、モデルを更新します;
- とカルディの電話ベースのラティスフリー mmi 識別トレーニングの違い
## 1. 文字と英語 BPE の直接エンドツーエンド モデリング、電話の状態転送構造を放棄;
2. モデリングの粒度が大きく、トレーニング入力はほぼ切り捨てられておらず、コンテキストは文全体です;
次の表は 15,000 時間のデータに基づいています。CTC トレーニングが完了した後、3,000 時間が、デコードの信頼性. エンドツーエンド ラティス フリー mmi の識別トレーニング結果は、従来の DT の結果よりも優れていることがわかります。トレーニングでは、精度の向上に加えて、トレーニング プロセス全体を tensorflow/pytorch GPU で完了できます。
|
B ステーション ビデオ テスト セット
|
#CTC ベースライン | #6.96 |
伝統的なDT6.63 |
E2E LFMMI DT |
6.13 |
ハイブリッド システムと比較すると、エンドツーエンド システムのデコード結果のタイムスタンプはあまり正確ではありません。AED トレーニングは時間と単調に一致しません。CTC トレーニングされたモデルは AED タイムスタンプよりもはるかに正確ですが、スパイクもあります毎回、単語の長さが不正確になります;
エンドツーエンドの識別トレーニングの後、モデルの出力はより平坦になり、デコード結果のタイムスタンプ境界はより正確になります;
エンドツーエンドのエンド CTC デコーダ
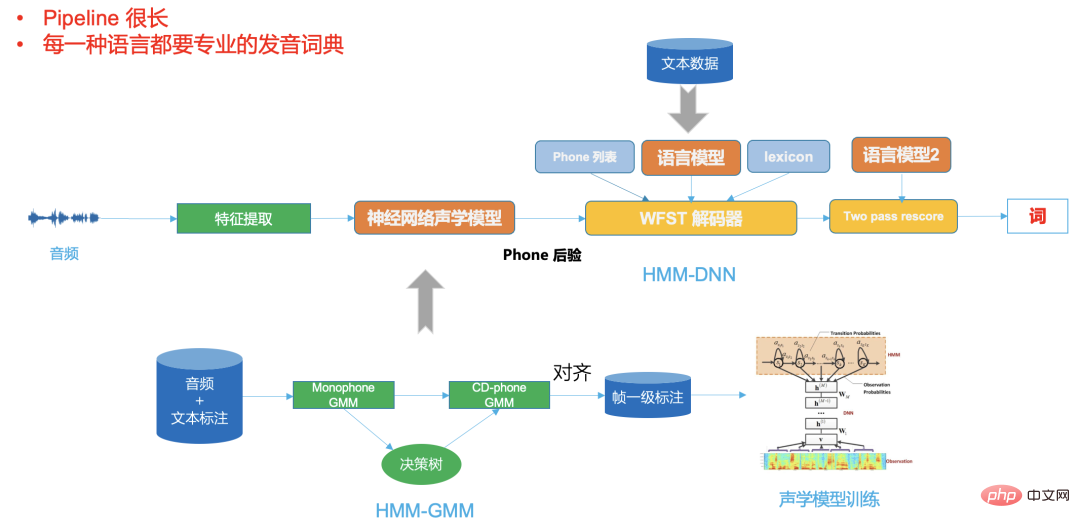
音声認識技術の開発プロセスにおいて、GMM-HMM に基づく第 1 段階であっても、DNN に基づく第 2 段階であっても-HMM ハイブリッド フレームワークでは、デコーダが非常に重要です。
デコーダのパフォーマンスは、最終的な ASR システムの速度と精度を直接決定します。ビジネスの拡張とカスタマイズも、主に柔軟で効率的なデコーダ ソリューションに依存します。従来のデコーダは、動的デコーダであっても、WFST に基づく静的デコーダであっても、非常に複雑です。多くの理論的知識に依存するだけでなく、専門的なソフトウェア エンジニアリング設計も必要です。優れたパフォーマンスを持つ従来のデコード エンジンを開発するには、初期段階では多くの人材育成が必要であり、その後の維持コストも非常に高くなります。
典型的な従来の WFST デコーダは、hmm、トライフォン コンテキスト、辞書、および言語モデルを統合ネットワーク (つまり、統合 FST ネットワーク検索スペース内の HCLG) にコンパイルする必要があり、これによりデコード速度が向上します。正確さ。
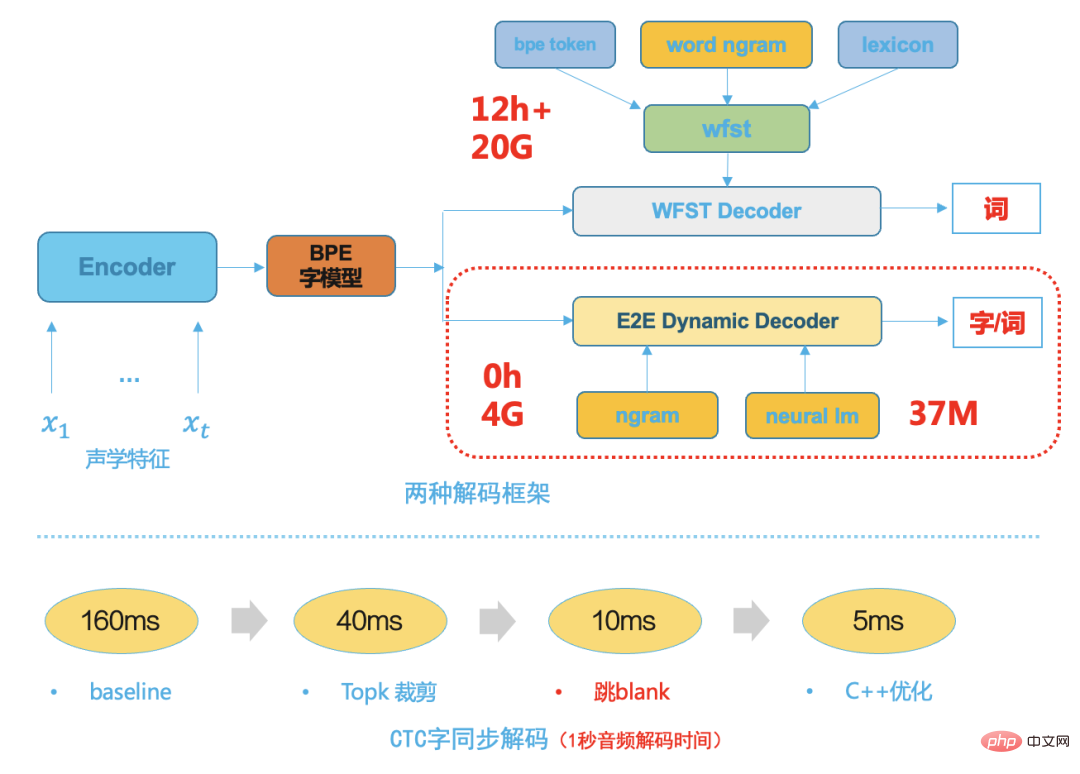
エンドツーエンド システム テクノロジの成熟に伴い、エンドツーエンド システム モデリング ユニットは、中国語の単語や英語の単語片など、より大きな粒度を持ちます。これは、従来の HMM 転送構造、トライフォン コンテキスト、およびこれにより、その後のデコード検索スペースが大幅に小さくなります。そのため、ビーム検索に基づいたシンプルで効率的な動的デコーダを選択します。次の図は、2 つのデコード フレームワークを示しています。従来の WFST デコーダと比較して、エンドツーエンド動的デコード デコーダには次の利点があります:
- 必要なリソースが少なく、通常は WFST デコード リソースの 1/5 です;
- 低結合なのでビジネスに便利ですカスタマイズとさまざまな言語モデルとの簡単な統合 デコード、変更ごとにデコード リソースを再コンパイルする必要はありません;
- デコード速度は高速で、ワード同期デコード [8] を使用しており、通常は WFST デコードより 5 倍高速です
図 8
モデル推論のデプロイメント
合理的かつ効率的な最終目的では、 to-end ASR フレームワークの中で、最も計算量の多い部分はニューラル ネットワーク モデルの推論に関して、この計算集約的な部分は GPU の計算能力を最大限に活用することができ、推論からモデル推論展開を最適化しますサービス、モデル構造、モデルの定量化:
- F16 半精度推論を使用したモデル;
- モデルは、nvidia の高度に最適化されたトランスフォーマーに基づいて、FasterTransformer[9] に変換されます。
- triton を使用して推論モデルをデプロイし、バッチを自動的に編成し、GPU の使用効率を完全に向上させます。
シングル GPU T4 では、速度が 30% 向上し、スループットが向上します。 2 倍になり、3000 時間の音声を 1 時間で書き起こすことができます。
#この記事では主に、B ステーション シナリオでの音声認識技術の実装、トレーニング データの問題をゼロから解決する方法、全体的な技術ソリューションの選択、モデルを含むサブモジュールのさまざまな導入と最適化について紹介します。トレーニング、デコーダの最適化、サービス推論の展開。将来的には、インスタント ホットワード テクノロジーを使用して関連するエンティティ ワードの精度を原稿レベルで最適化するなど、関連するランディング シナリオでのユーザー エクスペリエンスをさらに向上させます。ストリーミング ASR 関連テクノロジーと組み合わせて、より効率的なカスタマイズをリアルタイムでサポートします。ゲームやスポーツイベントの字幕転写。 参考文献[1] A Baevski、H Zhou、他 wav2vec 2.0: 音声表現の自己教師あり学習のためのフレームワーク[2] A Baevski 、 W Hsu ら、data2vec: 音声、視覚、言語における自己教師あり学習のための一般的なフレームワーク[3] Daniel S、Y Zhang ら、自動音声認識のためのノイズの多い学生トレーニングの改善[4] C Lüscher、E Beck、他 LibriSpeech 用 RWTH ASR システム: ハイブリッド vs アテンション -- データ拡張なし[5] R Prabhavalkar、K Rao、他音声認識のためのシーケンス間モデルの比較##[6] D Povey、V Peddinti1、他、格子フリー MMI に基づく ASR 用の純粋にシーケンストレーニングされたニューラル ネットワーク
# [7] H Xiang、Z Ou、CTC トポロジーを使用した CRF ベースのシングルステージ音響モデリング[8] Z Chen、W Deng、他、CTC Lattice を使用した電話同期デコーディング [9] https://www.php.cn/link/2ea6241cf767c279cf1e80a790df1885
この問題の著者: Deng Wei
シニア アルゴリズム エンジニアBilibili 音声認識ディレクション部門責任者


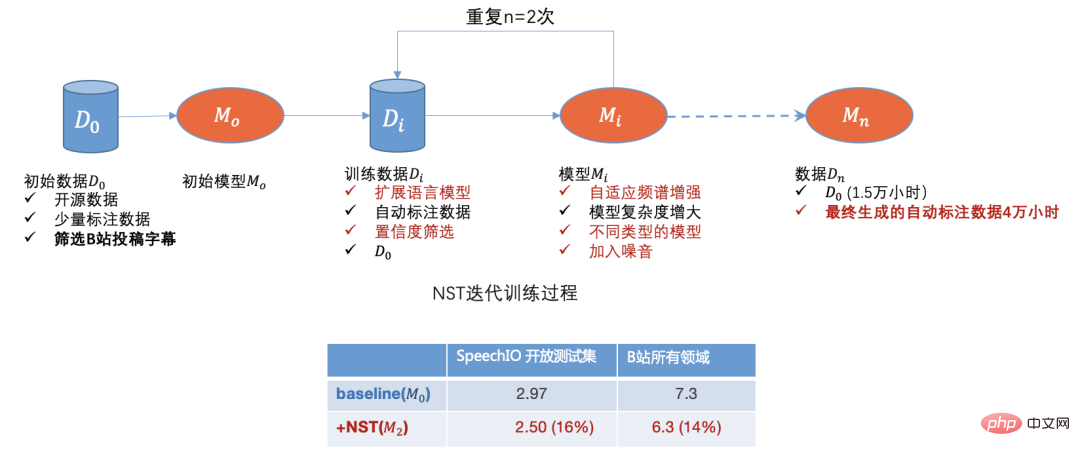 オープンソース データ、B ステーション送信データ、手動注釈データ、自動注釈データを通じて、データのコールド スタート問題を最初に解決しました。モデルを使用 反復することで、識別が不十分なドメイン データをさらに除外できます。
オープンソース データ、B ステーション送信データ、手動注釈データ、自動注釈データを通じて、データのコールド スタート問題を最初に解決しました。モデルを使用 反復することで、識別が不十分なドメイン データをさらに除外できます。