
ホームページ >テクノロジー周辺機器 >AI >実際の深い畳み込み敵対的生成ネットワーク
実際の深い畳み込み敵対的生成ネットワーク

- 王林転載
- 2023-04-12 14:22:12920ブラウズ
翻訳者 | Zhu Xianzhong
評者 | Sun Shujuan

Red Vineyard (著者: Vincent van Gogh)
ニューヨーク・タイムズ紙によると、企業が収集したデータのほとんどはいかなる形でも分析または使用されないため、データセンターのエネルギーの 90% が無駄になっています。より具体的には、これは「ダークデータ」と呼ばれます。
「ダーク データ」とは、さまざまなコンピューター ネットワーク操作を通じて取得されたものの、洞察を導き出したり意思決定を行うためにはまったく使用されなかったデータを指します。組織のデータ収集能力は、データ分析のスループットを超える場合があります。場合によっては、組織はデータが収集されていることさえ知らない場合があります。 IBM は、センサーとアナログからデジタルへの変換によって生成されたデータの約 90% が使用されないと推定しています。 — Wikipedia の「ダーク データ」の定義 このデータが機械学習の観点から洞察を引き出すのに役に立たない主な理由の 1 つは、ラベルが欠如していることです。このため、教師なし学習アルゴリズムは、このデータの可能性をマイニングする上で非常に魅力的になります。
敵対的生成ネットワーク
2014 年、Ian Goodfello らは、敵対的プロセスを通じて生成モデルを推定する新しい方法を提案しました。これには、2 つの独立したモデルを同時にトレーニングする必要があります。1 つはデータ分布のモデル化を試みるジェネレーター モデル、もう 1 つはジェネレーターを介して入力をトレーニング データまたは偽データとして分類しようとするディスクリミネーターです。
この論文は、現代の機械学習の分野において非常に重要なマイルストーンを設定し、教師なし学習の新しい道を切り開きます。 2015年にRadfordらによって発表された深層畳み込みGANの論文では、畳み込みネットワークの原理を適用することで2D画像の生成に成功しており、この論文では引き続きこのアイデアを発展させています。
この記事では、上記の論文で説明した主要なコンポーネントについて説明し、PyTorch フレームワークを使用して実装することを試みます。 GAN の魅力的な側面は何ですか?
GAN または DCGAN (Deep Convolutional Generative Adversarial Networks) の重要性を理解するために、まず、GAN または DCGAN がなぜこれほど人気があるのかを理解しましょう。
1. 実際のデータのほとんどにはラベルがないため、GAN の教師なし学習特性により、このようなユースケースには理想的です。
2. ジェネレーターとディスクリミネーターは、ラベル付きデータが限られたユースケースに対して非常に優れた特徴抽出器として機能するか、追加データを生成して二次モデルのトレーニングを改善します (代わりに偽のサンプルを生成できるため、拡張手法を使用します)。
3. GAN は、最尤法に代わる手法を提供します。敵対的学習プロセスと非ヒューリスティックなコスト関数により、強化学習にとって非常に魅力的になります。
4. GAN に関する研究は非常に魅力的であり、その結果は ML/DL の影響について広範な議論を引き起こしました。たとえば、ディープフェイクは、対象となる人物に人の顔を重ねる GAN のアプリケーションですが、不正な目的に使用される可能性があるため、本質的に非常に物議を醸しています。
5. 最後になりましたが、この種のネットワークを使用するのは素晴らしいことですし、この分野の新しい研究はどれも興味深いものです。
全体的なアーキテクチャ
深層畳み込み GAN のアーキテクチャ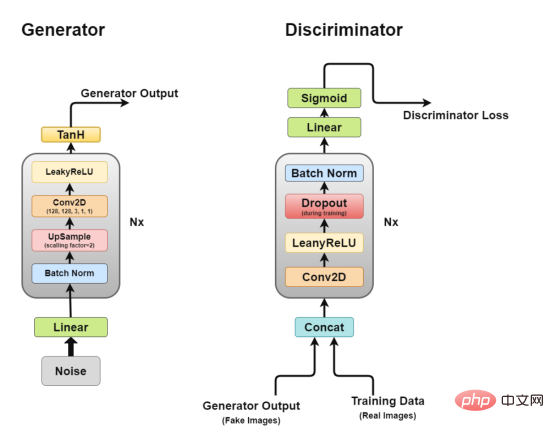 先ほど説明したように、DCGAN、DCGAN の実装を試みます。リアルな画像を生成する畳み込みネットワークである GAN の核となるアイデア。
先ほど説明したように、DCGAN、DCGAN の実装を試みます。リアルな画像を生成する畳み込みネットワークである GAN の核となるアイデア。
DCGAN は 2 つの独立したモデルで構成されます。ジェネレーター (G) は入力としてランダム ノイズ ベクトルをモデル化し、データ分布を学習して偽のサンプルを生成しようとします。もう 1 つはトレーニング データを取得するディスクリミネーター (D) です。 (本物のサンプル) と生成されたデータ (偽のサンプル) を分類してみます。これら 2 つのモデル間の闘争は、敵対的トレーニング プロセスと呼ばれるもので、一方の損失が他方の利益になります。
ジェネレーター
ジェネレーター アーキテクチャ図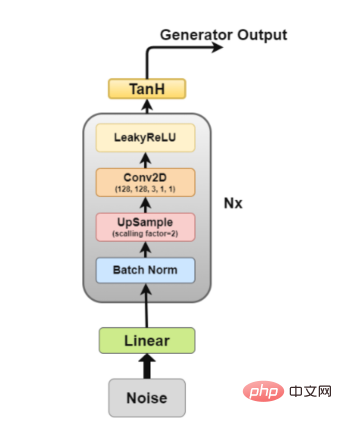 ジェネレーターは、偽の画像を生成するジェネレーターであるため、最も関心のある部分です。差別者を騙そうとする。
ジェネレーターは、偽の画像を生成するジェネレーターであるため、最も関心のある部分です。差別者を騙そうとする。
ここで、ジェネレーターのアーキテクチャをさらに詳しく見てみましょう。
- 線形層: ノイズ ベクトルは全結合層に入力され、その出力は 4D テンソルに変換されます。
- バッチ正規化レイヤー: 入力をゼロ平均と単位分散に正規化することで学習を安定化します。これにより、勾配の消失や爆発などのトレーニングの問題が回避され、勾配がネットワークを流れることが可能になります。
- アップサンプリング層: この論文の私の解釈によると、アップサンプリングに畳み込み転置層を使用するのではなく、アップサンプリングを使用し、その上に単純な畳み込み層を適用することが記載されています。ただし、畳み込み転置を使用している人もいるので、具体的なアプリケーション戦略はあなた次第です。
- 2D 畳み込み層: 行列をアップサンプリングする場合、行列を 1 のストライドで畳み込み層に通し、同じパディングを使用して、アップサンプリングされたデータから学習できるようにします。
- ReLU レイヤー: この記事では、モデルがすぐに飽和してトレーニング分布の色空間をカバーできるため、ジェネレーターとして LeakyReLU の代わりに ReLU を使用することに言及しています。
- TanH 活性化層: この記事では、TanH 活性化関数を使用してジェネレーターの出力を計算することを推奨していますが、その理由については詳しく説明しません。推測する必要があるとすれば、これは TanH の特性によりモデルの収束が速くなるからです。
このうち、レイヤー 2 からレイヤー 5 はコア ジェネレーター ブロックを構成し、これを N 回繰り返すことで目的の出力画像形状を得ることができます。
以下は、PyTorch での実装方法の重要なコードです (完全なソース コードについては、アドレス https://github.com/akash-agni/ReadThePaper/blob/main/DCGAN/dcgan を参照してください) .py)。
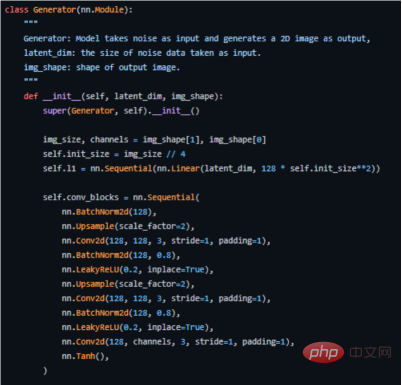
PyTorch フレームワークのジェネレーターを使用してキー コードを実装します
Discriminator
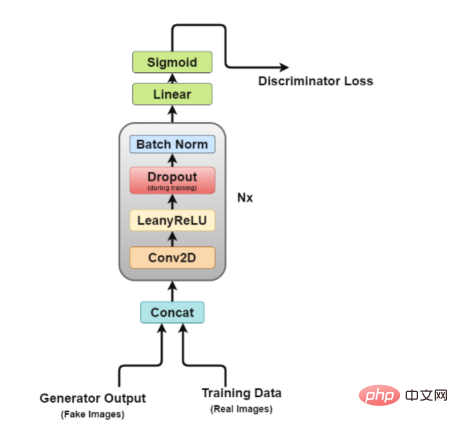
Discriminatorアーキテクチャ 図
この図から、ディスクリミネーターは画像分類ネットワークに似ていますが、若干の調整が加えられていることが簡単にわかります。たとえば、ダウンサンプリングにプーリング層を使用する代わりに、ストライド畳み込み層と呼ばれる特別な畳み込み層を使用します。これにより、独自のダウンサンプリングを学習できます。
ここで、識別器のアーキテクチャを詳しく見てみましょう。
- Concat レイヤー: このレイヤーは、偽の画像と実際の画像をバッチで結合して弁別器に供給しますが、ジェネレーターの損失を取得するためだけに、これを個別に実行することもできます。
- 畳み込み層: ここではストライド畳み込みを使用します。これにより、1 回のトレーニング セッションで画像をダウンサンプリングし、フィルターを学習できます。
- LeakyReLU 層: 論文で述べられているように、Leakyrelus は元の GAN 論文の最大出力関数と比較して簡単にトレーニングできるため、識別器にとって非常に有用であることがわかりました。
- ドロップアウト層: トレーニングのみに使用され、過学習の回避に役立ちます。モデルは実際の画像データを記憶する傾向があり、その時点でディスクリミネーターがジェネレーターによって「騙される」ことができなくなるため、トレーニングが失敗する可能性があります。
- バッチ正規化層: この論文では、各識別子ブロック (最初のブロックを除く) の最後にバッチ正規化を適用すると述べています。論文で述べられている理由は、各層にバッチ正規化を適用するとサンプルの振動やモデルの不安定性が生じる可能性があるためです。
- 線形レイヤー: 適用された 2D バッチ正規化レイヤーから再形成されたベクトルを取得する完全に接続されたレイヤー。
- Sigmoid Activation Layer: 弁別器出力のバイナリ分類を扱っているため、Sigmoidd 層の論理的な選択が行われます。
このアーキテクチャでは、レイヤー 2 からレイヤー 5 が識別器のコア ブロックを形成し、計算を N 回繰り返すことで、トレーニング データごとにモデルをより複雑にすることができます。
これを PyTorch で実装する方法を示します (完全なソース コードについては、アドレス https://github.com/akash-agni/ReadThePaper/blob/main/DCGAN/dcgan.py を参照してください)。
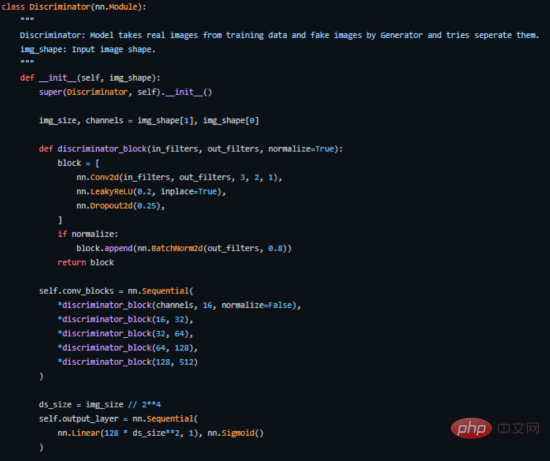
PyTorch で実装された弁別器のキー コード部分
敵対的トレーニング
正しい値を最大化するために弁別器 (D) をトレーニングします。ラベルがトレーニング サンプルとジェネレーターからのサンプルに割り当てられる確率 (G)。これは、log(D(x)) を最小化することで実現できます。同時に log(1 − D(G(z))) を最小化するように G を学習させます。ここで、z はノイズ ベクトルを表します。つまり、D と G の両方が値関数 V (G, D) を使用して、次の 2 プレイヤー ミニマックス ゲームをプレイします。
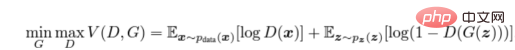
敵対的コスト関数の計算式
実際のアプリケーション環境では、上記の方程式は G が適切に学習するのに十分な勾配を提供しない可能性があります。学習の初期段階では、G が不十分な場合、サンプルはトレーニング データと大幅に異なるため、D は高い信頼度でサンプルを拒否できます。この場合、log(1 − D(G(z))) 関数は飽和に達します。 log(1 − D(G(z))) を最小化するように G を訓練する代わりに、logD(G(z)) を最大化するように G を訓練します。この目的関数は、動的 G と D に対して同じ固定点を生成しますが、学習の初期段階でより強力な勾配計算を提供します。 —— arxiv 論文
これは、2 つのモデルを同時にトレーニングしているため、難しい場合があります。GAN はトレーニングが難しいことで有名です。これについては後で説明します。既知の問題はモード崩壊と呼ばれます。
この論文では、学習率 0.0002 の Adam オプティマイザーを使用することを推奨しています。このような低い学習率は、GAN が非常に早く発散する傾向があることを示しています。また、値が 0.5 および 0.999 の 1 次および 2 次の運動量を使用して、トレーニングをさらに高速化します。モデルは、平均が 0、標準偏差が 0.02 の正規加重分布に初期化されます。
以下は、このためのトレーニング ループを実装する方法を示しています (完全なソース コードについては、https://github.com/akash-agni/ReadThePaper/blob/main/DCGAN/dcgan.py を参照してください)。
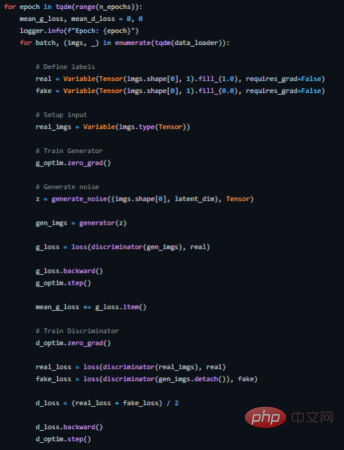
DCGAN のトレーニング ループ
モード崩壊
理想的には、ジェネレーターがさまざまな出力を生成するようにします。たとえば、顔を生成する場合は、ランダムな入力ごとに新しい顔を生成する必要があります。ただし、ジェネレーターがディスクリミネーターを欺くのに十分な妥当性のある出力を生成する場合、同じ出力を何度も生成する可能性があります。
最終的に、ジェネレーターは単一の識別器を過剰に最適化し、少数の出力セットの間でローテーションすることになります。これは「モード崩壊」と呼ばれる状況です。
次の方法を使用して状況を修正できます。
- Wasserstein 損失関数法 (Wasserstein 損失): Wasserstein 損失関数を使用すると、勾配の消失を気にせずに最適になるように識別器をトレーニングできるため、モード崩壊が軽減されます。弁別器が極小値に引っかからない場合、弁別器は生成器の安定した出力を拒否することを学習します。したがって、ジェネレーターは新しいことに挑戦する必要があります。
- アンロールド GAN メソッド (アンロールド GAN): アンロールド GAN は、現在の弁別器の分類だけでなく、将来の弁別器バージョンの出力も含むジェネレーター損失関数を使用します。したがって、単一の識別子に対してジェネレーターを過剰に最適化することはできません。
APPS
- スタイルシフト: 顔レタッチ アプリが今大流行しています。その中には、顔の老化、泣き顔、有名人の顔の変形など、ソーシャル メディアで広く普及しているアプリケーションのほんの一部です。
- ビデオ ゲーム: 3D オブジェクトのテクスチャ生成や画像ベースのシーン生成は、ビデオ ゲーム業界がより大規模なゲームをより迅速に開発できるよう支援しているアプリケーションのほんの一部です。
- 映画業界: CGI (コンピューター生成画像) はモデル映画の大きな部分を占めるようになり、GAN によってもたらされる可能性により、映画製作者はこれまで以上に大きな夢を見ることができるようになりました。
- 音声生成: 一部の企業は、GAN を使用してテキスト読み上げアプリケーションを改善し、より現実的な音声を生成しています。
- 画像の復元: GAN を使用して、破損した画像のノイズ除去と復元、過去の画像のカラー化、欠落したフレームを生成してフレーム レートを高めることで古いビデオを改善します。
結論
つまり、上記の GAN と DCGAN に関する論文は、教師なし学習の新しい章、新しい方法を開いたという点で、単に画期的な論文にすぎません。その中で提案されている敵対的トレーニング方法は、現実世界の学習プロセスを厳密にシミュレートするモデルをトレーニングするための新しい方法を提供します。したがって、この分野がどのように発展するかを見るのは非常に興味深いでしょう。
最後に、この記事のサンプル プロジェクトの完全な実装ソース コードは、私の GitHub ソース コード リポジトリにあります。 翻訳者紹介
Zhu Xianzhong 氏、51CTO コミュニティ編集者、濰坊市の大学のコンピューター教師、フリーランス プログラミング業界のベテラン。
元のタイトル:Implementing Deep Convolutional GAN 、著者: Akash Agnihotri
以上が実際の深い畳み込み敵対的生成ネットワークの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。