
ホームページ >テクノロジー周辺機器 >AI >自然言語の事前トレーニング技術の進化に関する予備調査
自然言語の事前トレーニング技術の進化に関する予備調査

- 王林転載
- 2023-04-11 22:04:041283ブラウズ
人工知能の 3 つのレベル:
コンピューティング機能: データ ストレージとコンピューティング機能。機械は人間よりもはるかに優れています。
知覚機能: 視覚、聴覚、その他の能力 機械は、音声認識や画像認識の分野ではすでに人間に匹敵します。
認知的インテリジェンス: 自然言語処理、常識モデリング、推論などのタスクに関しては、機械にはまだ長い道のりがあります。
自然言語処理は認知知能のカテゴリーに属します。自然言語には抽象化、組み合わせ、曖昧さ、知識、進化という特性があるため、機械処理に大きな課題をもたらします。自然言語を使用して処理を行う人もいます。自然言語 言語処理は人工知能の至宝と呼ばれています。近年、BERT に代表される事前トレーニング済み言語モデルが登場し、自然言語処理に新しい時代をもたらしました。つまり、特定のタスクに合わせて微調整された事前トレーニング済み言語モデルです。この記事は、すべての人とのコミュニケーションと学習を目的として、自然言語事前トレーニング テクノロジーの進化を整理することを目的としています。欠点や誤りに対する批判と修正を歓迎します。
1. 古代 - 単語表現
1.1 ワンホット エンコーディング
語彙のサイズのベクトルを使用して単語を表現します。単語の対応する位置は 1 で、残りの位置は 0 です。欠点:
- 高次元の疎性
- 意味論的な類似性を表現できない: 2 つの同義語のワンホット ベクトル類似度は 0
1.2 分布式
分散意味論仮説: 類似した単語には類似したコンテキストがあり、単語の意味論はコンテキストによって表現できます。この考えに基づいて、各単語のコンテキスト分布を使用して単語を表現できます。
1.2.1 単語の頻度表現
コーパスに基づいて、単語の文脈を使用して共起頻度テーブルを構築します。単語テーブルの各行は、単語のベクトル表現を表します。単語。さまざまなコンテキストの選択を通じて、さまざまな言語情報を取得できます。たとえば、文中の単語の周囲にある固定ウィンドウ内の単語がコンテキストとして使用される場合、単語のよりローカルな情報 (語彙情報や構文情報) が取得されます。ドキュメントがコンテキストとして使用され、単語によって表されるトピック情報をより多く取得します。短所:
- 高頻度の単語の問題。
- 高次の関係は反映できません: (A, B) (B, C) (C, D) !=> (A, D)。
- スパース性の問題がまだ残っています。
1.2.2 TF-IDF 表現
単語頻度表現の値を TF-IDF に置き換えます。これにより、主に単語頻度表現における高頻度単語の問題が軽減されます。
1.2.3 点相互情報量表現
また、単語頻度表現の高頻度単語問題も軽減され、単語頻度表現の値が単語の点相互情報量に置き換えられます。 :

1.2.4 LSA
単語頻度行列に対して特異値分解 (SVD) を実行することにより、低次元の連続した密なベクトル表現が得られます。各単語の潜在的な意味を表すと考えることができ、この手法は潜在意味解析 (Latent Semantic Analysis、LSA) とも呼ばれます。

LSA は、高頻度の単語、高次の関係、スパース性などの問題を軽減し、その効果は従来の機械学習アルゴリズムでも良好ですが、いくつかの欠点もあります:
- 語彙リストが大きい場合、SVD は遅くなります。
- 新しいコーパスに追いつけません。コーパスが変更されたり、新しいコーパスが追加された場合は、再トレーニングする必要があります。
2. 現代 - 静的単語ベクトル
テキストの順序性と単語間の共起関係は、自然言語処理に自然な自己教師あり学習信号を提供し、システムを可能にします。手作業による追加の注釈なしでテキストから知識を学習できます。
2.1 Word2Vec
2.1.1 CBOW
CBOW(Continous Bag-of-Words)は、コンテキスト (ウィンドウ) を使用してターゲット単語を予測し、単語を組み合わせます。文脈単語ベクトルは算術平均され、ターゲット単語の確率が予測されます。

2.1.2 Skip-gram
Skip-gram は単語ごとにコンテキストを予測します。

2.2 GloVe
GloVe (単語表現のためのグローバル ベクトル) は、単語ベクトルを使用して単語の共起行列を予測し、暗黙的な行列分解を実装します。まず、距離加重共起行列 X が単語のコンテキスト ウィンドウに基づいて構築され、次に単語とコンテキストのベクトルを使用して共起行列 X が適合されます。

#損失関数は次のとおりです。


 # はマスクされたシーケンスを表します
# はマスクされたシーケンスを表します
3.1 コーナーストーン—トランスフォーマー
##3.1.1 アテンション モデル
3.1.2 マルチヘッドセルフアテンション
Q、K、V が同じベクトル シーケンスに由来する場合、それは自己注意モデルになります。 

 セルフアテンションモデルは入力ベクトルの位置情報を考慮しないためただし、位置情報はシーケンス モデリングにとって重要です。位置情報は、位置埋め込みまたは位置エンコーディングを通じて導入できます。Transformer は位置エンコーディングを使用します。
セルフアテンションモデルは入力ベクトルの位置情報を考慮しないためただし、位置情報はシーケンス モデリングにとって重要です。位置情報は、位置埋め込みまたは位置エンコーディングを通じて導入できます。Transformer は位置エンコーディングを使用します。
 さらに、Transformer ブロックでは、残差接続、レイヤー正規化、その他のテクノロジーも使用されます。
さらに、Transformer ブロックでは、残差接続、レイヤー正規化、その他のテクノロジーも使用されます。
3.1.5 利点と欠点
利点:RNN と比較して、長距離の依存関係をモデル化できます。メカニズムにより、単語間の距離が 1 に短縮され、長いシーケンス データをモデル化する能力が強化されます。
RNN と比較して、GPU の並列計算能力をより有効に活用できます。- 豊かな表現力。
- 欠点:
RNN と比較してパラメータが大きいため、学習の難易度が上がり、より多くの学習データが必要になります。
- 3.2 自己回帰言語モデル
- 3.2.1 ELMo
ELMo: 言語モデルからの埋め込み
入力層
単語の埋め込みを直接使用することも、単語内の文字シーケンスを CNN または他のモデルを通じて使用することもできます。
モデル構造

ELMo は、LSTM を通じて前方言語モデルと後方言語モデルを独立してモデル化します。前方言語モデル:

下位言語モデル:

最適化目標
最大化:

ダウンストリーム アプリケーション
ELMo がトレーニングされた後、ダウンストリーム タスクで使用するために次のベクトルを取得できます。

は入力層によって取得された単語埋め込みであり、前方および後方の LSTM 出力を結合した結果です。
ダウンストリーム タスクで使用する場合、各レイヤーのベクトルを重み付けして ELMo のベクトル表現を取得し、重みを使用して ELMo ベクトルをスケーリングできます。

さまざまなレベルの隠れ層ベクトルには、さまざまなレベルまたは粒度のテキスト情報が含まれます。
- 最上位層は、より多くのセマンティック情報をエンコードします
- 最下層は、より語彙的および構文的な情報をエンコードします
3.2.2 GPT シリーズ
GPT-1
モデル構造
GPT-1 (Generative Pre-Training) では、12 個のトランスフォーマー ブロック構造をデコーダーとして使用する一方向言語モデルです。各トランスフォーマー ブロックはマルチヘッドのセルフ アテンション メカニズムです。完全接続による出力の確率分布。


- #U: 単語のワンホット ベクトル
- ##We: 単語ベクトル行列
- Wp: 位置ベクトル行列
- 最適化目標

ダウンストリーム タスクでは、ラベル付きデータ セットの場合、各インスタンスにラベルで構成される入力トークンがあります。まず、これらのトークンがトレーニング済みの事前トレーニング モデルに入力されて、最終的な特徴ベクトルが取得されます。次に、完全に接続された層を通じて予測結果が取得されます:
 下流の教師ありタスクの目標は、次のことを最大化することです:
下流の教師ありタスクの目標は、次のことを最大化することです:
 致命的な忘却の問題を防ぐために、特定の重みの事前トレーニング損失を微調整損失 (通常は事前トレーニング損失) に追加できます。
致命的な忘却の問題を防ぐために、特定の重みの事前トレーニング損失を微調整損失 (通常は事前トレーニング損失) に追加できます。

GPT-2
GPT-2 の核となる考え方は次のように要約できます: 教師ありタスクは言語モデルのサブセットです。モデルの容量が非常に大きく、その量が非常に大きい場合、データは十分に豊富なので、トレーニングだけでも言語モデルの学習で他の教師あり学習タスクを完了できます。したがって、GPT-2 は GPT-1 ネットワーク上で多くの構造革新や設計を実行しませんでした。より多くのネットワーク パラメーターとより大きなデータ セットを使用しただけです。目標は、より強力な汎化能力を持つワード ベクトルをトレーニングすることでした。モデル。
GPT-2 は 8 つの言語モデル タスクのうち、7 つのタスクがゼロショット学習だけで当時の最先端の手法を上回っています (もちろん、一部のタスクは依然として監修モデル)良い)。 GPT-2 の最大の貢献は、大量のデータと多数のパラメーターを使用してトレーニングされたワード ベクトル モデルが、追加のトレーニングなしで他のカテゴリのタスクに転送できることを検証したことです。
同時に、GPT-2 は、モデルの容量と学習データの量 (品質) が増加するにつれて、その可能性をさらに発展させる余地があることを示し、この考えに基づいて GPT-3 が誕生しました。
GPT-3
モデル構造に変更はありませんが、モデル容量、学習データ量、品質が向上しています。とても良い。
概要

GPT-1 から GPT-3 まで、モデルの容量とトレーニング データの量が増加するにつれて、モデルによって学習される言語知識も増加します。リッチ、自然言語処理のパラダイムは、「トレーニング前モデルの微調整」から「トレーニング前モデルのゼロショット/フューショット学習」へと徐々に変化してきました。 GPT の欠点は、一方向の言語モデルを使用していることですが、BERT は、双方向の言語モデルを使用することでモデルの効果が向上することを証明しました。
3.2.3 XLNet
XLNet は、置換言語モデル (置換言語モデル) を通じて双方向のコンテキスト情報を導入します。特別なタグを導入せず、事前トレーニングでの不一致なトークン配布を回避します。そしてフェーズの微調整が問題です。同時に、Transformer-XL がモデルの主要な構造として使用され、長いテキストに対する効果が向上します。
置換言語モデル
置換言語モデルの目標は次のとおりです。

は、テキスト シーケンスのすべての可能な置換のセットです。 。
2 ストリーム セルフ アテンション メカニズム
- 2 ストリーム セルフ アテンション メカニズム (Two-stream Self-attention) の目的は次のとおりです。入力時に Transformer を変換することによって、通常のテキスト シーケンスの場合、順列言語モデルを実装します。
- コンテンツ表現: 含まれる情報
- クエリ表現: 含まれる情報のみ


この方法では、予測単語の位置情報を利用します。
ダウンストリーム アプリケーション
ダウンストリーム タスクを適用する場合、クエリ表現やマスクは必要ありません。
3.3 自己エンコーディング言語モデル
3.3.1 BERT
マスク言語モデル
マスク言語モデル (MLM)、ランダムな部分的にマスクされた単語、および次に、コンテキスト情報を使用して予測を行います。 MLM には問題があり、微調整中に [MASK] トークンが表示されないため、事前トレーニングと微調整の間に不一致が生じます。この問題を解決するために、BERT は必ずしも「マスクされた」単語部分トークンを実際の [MASK] トークンに置き換えるとは限りません。トレーニング データ ジェネレーターはトークンの 15% をランダムに選択し、
- 80% の確率でそれらを [MASK] トークンに置き換えます。
- 10% の確率: 語彙リストのランダムなトークンに置き換えます。
- 10% の確率: トークンは変化しません。
ネイティブ BERT では、トークンがマスクされ、単語またはフレーズ全体 (N-Gram) がマスクされることがあります。
次文予測
次文予測 (NSP): 文 A と B が事前トレーニング サンプルとして選択された場合、B が A の次の文である確率は 50% です。 50% の確率で、コーパスからのランダムな文である可能性があります。
入力層

モデル構造

古典的な「トレーニング前モデルの微調整」 「パラダイム」のテーマ構造はトランスフォーマーを多層に積み重ねたものです。
3.3.2 RoBERTa
RoBERTa (堅牢に最適化された BERT 事前トレーニング アプローチ) は、BERT を大幅に改善するものではなく、BERT のあらゆる設計詳細について詳細な実験を実行して、BERT の改善の余地を見つけるだけです。
- 動的マスク: 元の方法では、データ セットの構築時にマスクを設定して固定します。改良された方法では、トレーニングの各ラウンドでモデルにデータを入力するときにデータをランダムにマスクします。 、データの精度が向上します。
- NSP タスクを放棄する: NSP タスクを使用しないと、ほとんどのタスクのパフォーマンスが向上することが実験で証明されています。
- より多くのトレーニング データ、より大きなバッチ、より長い事前トレーニング ステップ。
- より大きな語彙: WordPiece の文字レベルの BPE 語彙ではなく、SentencePiece のバイトレベルの BPE 語彙を使用すると、未登録の単語はほとんどなくなります。
3.3.3 ALBERT
BERT には比較的多数のパラメータがあります。ALBERT (A Lite BERT) の主な目標は、パラメータの数を減らすことです。
##BERT の単語ベクトルの次元は隠れ層の次元と同じであり、単語ベクトルはコンテキストに依存しません。ただし、BERT のトランスフォーマー層は十分なコンテキスト情報を必要とし、学習できるため、隠れ層のベクトルの次元ははるかに大きくなるはずです。ワードベクトル次元よりも。パフォーマンスを向上させるためにサイズを増やす場合、埋め込む必要がある情報量に対してワード ベクトルのスペースが十分である可能性があるため、サイズを増やす必要はありません。- 解決策: 単語ベクトルは、全結合層を通じて H 次元に変換されます。
- ワード ベクトル パラメーター分解 (因数分解された埋め込みパラメーター化)。
- 層間パラメータ共有: 異なる層の Transformer ブロックはパラメータを共有します。
- 文順序予測 (SOP)、微妙な意味の違いと談話の一貫性を学習します。
- 3.4 生成的対立 - ELECTRA
ELECTRA (トークン置換を正確に分類するエンコーダーの効率的な学習) では、ジェネレーターとディスクリミネーターのモデルを導入し、生成的なマスク言語モデルを (MLM) に変換します。事前トレーニング タスクは、現在のトークンが言語モデルによって置き換えられているかどうかを判断する、GAN の考え方に似た、識別的な置き換えトークン検出 (RTD) タスクに変更されました。
 ジェネレーターは、入力テキストのマスク位置にあるトークンを予測します:
ジェネレーターは、入力テキストのマスク位置にあるトークンを予測します:

 ディスクリミネーターの入力はジェネレーターの出力であり、ディスクリミネーターは各位置の単語が置換されたかどうかを予測します。
ディスクリミネーターの入力はジェネレーターの出力であり、ディスクリミネーターは各位置の単語が置換されたかどうかを予測します。
 さらに、一部の最適化では、
さらに、一部の最適化では、
- ワード ベクトル パラメーターの分解。
- ジェネレーターとディスクリミネーターのパラメーター共有: ワード ベクトル行列と位置ベクトル行列を含む入力層パラメーターの共有。
- ダウンストリーム タスクでは、ジェネレーターではなく、ディスクリミネーターのみを使用してください。
3.5 長いテキストの処理 - Transformer-XL
Transformer 長いテキストを処理するための一般的な戦略は、テキストを固定長のブロックに分割し、ブロック間を中断することなく各ブロックを独立してエンコードすることです。情報交換。
 長いテキストのモデリングを最適化するために、Transformer-XL は、状態再利用によるセグメントレベルの反復と相対位置エンコーディングという 2 つのテクノロジーを使用します。
長いテキストのモデリングを最適化するために、Transformer-XL は、状態再利用によるセグメントレベルの反復と相対位置エンコーディングという 2 つのテクノロジーを使用します。
3.5.1 状態多重化のブロックレベルのループ
Transformer-XL は、トレーニング中に固定長セグメントの形式でも入力されます。異なる点は、Transformer-XL の以前の状態がフラグメントはキャッシュされ、現在のセグメントを計算するときに前のタイム スライスの非表示状態が再利用され、Transformer-XL に長期的な依存関係をモデル化する機能が与えられます。
長さ L の 2 つの連続したセグメント。隠れ層ノードの状態は次のように表されます。ここで d は隠れ層ノードの次元です。隠れ層ノードのステータスの計算プロセスは次のとおりです:
フラグメント再帰のもう 1 つの利点は、推論速度の向上です。一度に 1 つのタイム スライスしか進めることができない Transformer の自己回帰アーキテクチャと比較して、Transformer-XL の推論プロセスは、最初から計算するのではなく、前のフラグメントの表現を直接再利用します。推論プロセスを断片的な推論に改善します。

3.5.2 相対位置エンコーディング
Transformer では、セルフアテンション モデルは次のように表現できます。

の完全な式は次のとおりです:


Transformer の問題は、それがどのフラグメントであっても、その位置が異なることです。エンコーディングは同じです。つまり、Transformer の位置エンコーディングはフラグメントに対する絶対位置エンコーディングであり、元の文内の現在のコンテンツの相対位置とは関係ありません。
Transfomer-XL は、上記の式に基づいていくつかの変更を加え、次の計算方法を取得しました:

- 変更 1: 中、分割されていますこれは、入力シーケンスと位置エンコーディングが重みを共有しなくなることを意味します。
- 変更 2: では、絶対位置エンコーディングが相対位置エンコーディングに置き換えられます。
- 変更 3: Transformer のクエリ ベクトルを置き換えるために、2 つの新しい学習可能なパラメーターが導入されました。対応するクエリ位置ベクトルがすべてのクエリ位置で同じであることを示します。つまり、クエリの位置に関係なく、さまざまな単語に対する注意のバイアスは一貫したままになります。
- 改善後各部の意味:
- Content-based relevance(): クエリの内容とキーの相関情報を計算
- コンテンツ関連の位置オフセット(): クエリの内容とキーの位置コードとの関連情報を計算します。
- グローバルコンテンツオフセット(): クエリの位置コードとキーの内容との関連を計算します。情報
- グローバル位置オフセット (): クエリとキー位置コーディング間の関連情報を計算します
3.6 蒸留と圧縮 - DistillBert
知識蒸留技術 (知識蒸留) , KD): 通常、教師モデルと学生モデルで構成されます。学生モデルが教師モデルにできる限り近づくように、教師モデルから学生モデルに知識が伝達されます。実際のアプリケーションでは、学生モデルは次のようになります。多くの場合、教師モデルよりも小さく、より基本的なモデルが必要ですが、元のモデルの効果を維持します。
DistillBert のスチューデント モデル:
- トークン タイプの埋め込み (つまり、セグメントの埋め込み) を削除した 6 層 BERT。
- 教師モデルの最初の 6 つのレイヤーを初期化に使用します。
- マスク言語モデルはトレーニングにのみ使用し、NSP タスクは使用しないでください。
教師モデル: BERT ベース:
損失関数:
教師付き MLM 損失: マスク Cross を使用- コード言語モデルのトレーニングから得られるエントロピー損失:
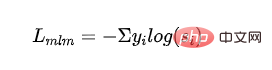
- は、 番目のカテゴリのラベルを表し、 番目のカテゴリの学生モデル出力の確率を表します。
- # 抽出された MLM 損失: 教師モデルの確率をガイダンス信号として使用し、学生モデルの確率でクロスエントロピー損失を計算します。
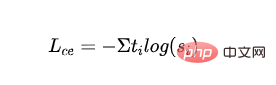
- は、教師モデルの最初のカテゴリのラベルを表します。
- ワードベクトルコサイン損失:教師モデルと生徒モデルの隠れ層ベクトルの方向を揃え、隠れ層から教師モデルと生徒モデルの距離を縮める寸法: #### ###########
- と は、それぞれ教師モデルと学生モデルの最後の層の隠れ層出力を表します。
- 最終負け:
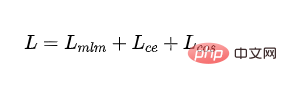
4.参考文献
https :/ /www.php.cn/link/6e2290dbf1e11f39d246e7ce5ac50a1e
https://www.php.cn/link/664c7298d2b73b3c7fe2d1e8d1781c06
https://www.php.cn/link/67b878df6cd42d142f2924f3ace85c78
## https://www.php.cn/link/f6a673f09493afcd8b129a0bcf1cd5bc
https://www.php.cn/link/82599a4ec94aca066873c99b4c741ed8
# https://www.php. cn/link/2e64da0bae6a7533021c760d4ba5d621
## https://www.php.cn/link/56d33021e640f5d64a611a71b5dc30a3
https ://www.php.cn/link/4e38d30e656da5ae9d3a425109ce9e04
https://www.php.cn/link/c055dcc749c2632fd4dd806301f05ba6
https://www.php.cn/link/a749e38f556d5eb1dc13b9221d1f994f
https://www.php.cn/link /8ab9bb97ce35080338be74dc6375e0ed
## https://www.php.cn/link/4f0bf7b7b1aca9ad15317a0b4efdca14 https://www.php .cn/link/b81132591828d622fc335860bffec150https://www.php.cn/link/fca758e52635df5a640f7063ddb9cdcb
https://www.php.cn/link/5112277ea658f7138694f079042cc3bb
https://www.php.cn/link/257deb66f5366aab34a23d5fd0571da4
https://www.php.cn/link/b18e8fb514012229891cf024b6436526
# https://www.php.cn/link/836a0dcbf5d22652569dc3a708274c16
## https://www.php.cn/link/a3de03cb426b5e36f5c7167b21395323
https://www. php.cn/link/831b342d8a83408e5960e9b0c5f31f0c
https://www.php.cn/link/6b27e88fdd7269394bca4968b48d8df4
https://www.php.cn/link/9739efc4f01292e764c86caa59af353e https://www.php.cn/link/b93e78c67fd4ae3ee626d8ec0c412dec # https://www.php.cn/link /c8cc6e90ccbff44c9cee23611711cdc4以上が自然言語の事前トレーニング技術の進化に関する予備調査の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。