
ホームページ >テクノロジー周辺機器 >AI >エッジ生体認証を活用したAIセキュリティシステムの開発
エッジ生体認証を活用したAIセキュリティシステムの開発

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-11 20:55:141604ブラウズ
翻訳者 | Zhu Xianzhong
査読者 | Sun Shujuan
ワークスペースのセキュリティは、企業、特に機密情報を扱ったり、データを保有したりする企業にとって、手間と時間がかかる金銭的損失の経路となる可能性があります。 . 複数のオフィスと数千人の従業員を抱える企業向け。電子キーはセキュリティ システムを自動化するための標準的なオプションの 1 つですが、実際には、キーの紛失、忘れ、または偽造など、依然として多くの欠点があります。
生体認証は、「ありのままの本人」認証の概念を表すため、従来のセキュリティ対策の信頼できる代替手段です。これは、ユーザーが指紋、虹彩、声、顔などの独自の特徴を使用して、スペースにアクセスできることを証明できることを意味します。認証方法として生体認証を使用すると、キーの紛失、忘れ、偽造が防止されます。したがって、この記事では、エッジ バイオメトリクスの開発経験について説明します。エッジ バイオメトリクスは、エッジ デバイス、人工知能、生体認証を組み合わせて、人工知能技術に基づくセキュリティ監視システムを実装します。
エッジバイオメトリクスとは何ですか?
まず、エッジ AI とは何なのかを明確にしましょう。従来の AI アーキテクチャでは、モデルとデータをオペレーティング デバイスやハードウェア センサーから分離してクラウドにデプロイするのが一般的でした。そのため、クラウド サーバーを適切な状態に保ち、安定したインターネット接続を維持し、クラウド サービスの料金を支払う必要があります。インターネット接続が失われた場合にリモート ストレージにアクセスできなくなると、AI アプリケーション全体が役に立たなくなります。
「対照的に、エッジ AI の考え方は、ユーザーに近いデバイス上に人工知能アプリケーションを展開することです。エッジ デバイスには独自の GPU が搭載されている場合があり、デバイス上でローカルに入力を処理できるようになります。 .
これにより、すべての操作がデバイス上でローカルに実行され、全体的なコストと消費電力も低下するため、遅延の短縮などの多くの利点が得られます。また、デバイスをある場所から別の場所に簡単に移動できるため、
大規模なエコシステムが必要ないことを考えると、安定したインターネット接続に依存する従来のセキュリティ システムに比べて帯域幅要件も低くなります。データはデバイスの内部メモリに保存できるため、接続は閉じられます。これにより、システム全体の設計の信頼性と堅牢性が向上します。」
- Daniel Lyadov (MobiDev の Python エンジニア)
唯一の注目すべき点欠点は、すべての処理をデバイス上で短時間内に実行する必要があることと、この機能を有効にするにはハードウェア コンポーネントが十分強力で最新である必要があることです。
顔や音声認識などの生体認証タスクでは、セキュリティ システムの迅速な応答と信頼性が非常に重要です。シームレスなユーザー エクスペリエンスと適切なセキュリティを確保したいため、エッジ デバイスに依存することでこれらの利点が得られます。
従業員の顔や声などの生体情報は、ニューラル ネットワークが認識できる固有のパターンを表すため、十分に安全であるように見えます。さらに、ほとんどの企業ではすでに CRM または ERP に従業員の写真が含まれているため、この種のデータは収集が容易です。このようにして、従業員の指紋サンプルを収集することで、プライバシーの問題を回避することもできます。
エッジテクノロジーと組み合わせることで、ワークスペース入口用の柔軟な AI セキュリティ カメラ システムを構築できます。以下では、当社の開発経験に基づいて、エッジ生体認証の助けを借りて、そのようなシステムを実装する方法について説明します。
人工知能監視システムの設計
このプロジェクトの主な目的は、オフィスの入り口でカメラを一目見ただけで従業員を認証することです。コンピューター ビジョン モデルは人の顔を認識し、以前に取得した写真と比較して、ドアの自動開閉を制御できます。追加の対策として、いかなる形であれシステムの不正行為を避けるために、音声認証のサポートも追加されます。パイプライン全体は 4 つのモデルで構成されており、顔検出から音声認識までさまざまなタスクの実行を担当します。
これらすべての対策は、ビデオ/オーディオ入力センサーとして機能する単一のデバイスと、ロック/ロック解除コマンドを送信するコントローラーによって実現されます。エッジ デバイスとして、NVIDIA の Jetson Xavier を使用することを選択しました。この選択は主に、デバイスでの GPU メモリ (ディープ ラーニング プロジェクトの推論の高速化に不可欠) の使用と、Python 3 環境に基づくデバイスをサポートする NVIDIA の可用性の高い Jetpack-SDK の使用により行われました。したがって、DS モデルを別の形式に変換する厳密な必要性はなく、DS エンジニアはほぼすべてのコード ベースをデバイスに適合させることができ、さらに、あるプログラミング言語から別のプログラミング言語に書き直す必要もありません。
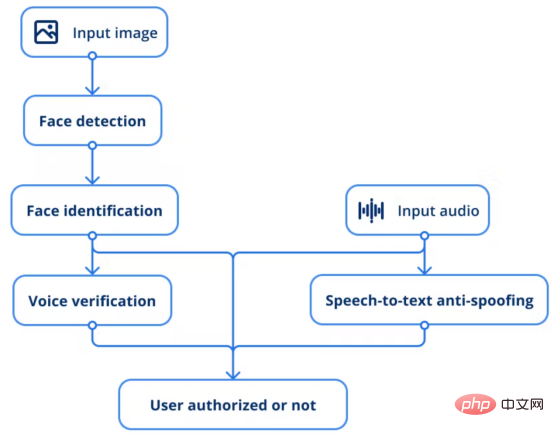 AI セキュリティ システムのワークフロー
AI セキュリティ システムのワークフロー
上記の説明によると、プロセス全体は次のフローに従います:
1. 入力を提供します。画像を顔検出モデルに変換してユーザーを検索します。
2. 顔認識モデルは、ベクトルを抽出し、既存の従業員の写真と比較することで同一人物であるかどうかを判断することで推論を実行します。
3. もう 1 つのモデルは、音声サンプルを通じて特定の人の音声を検証することです。
4. さらに、あらゆるタイプのなりすまし技術を防ぐために、音声からテキストへのなりすまし防止ソリューションが採用されています。
次に、各実装リンクについて説明し、トレーニングとデータ収集のプロセスについて詳しく説明します。
データ収集
システム モジュールを詳しく説明する前に、使用されるデータベースに必ず注意してください。私たちのシステムは、いわゆる参照データまたはグラウンド トゥルース データをユーザーに提供することに依存しています。現在、データには各ユーザーの事前に計算された顔と音声のベクトルが含まれており、これらは数値の配列のように見えます。システムは、将来の再トレーニングのために成功したログイン データも保存します。これを考慮して、最も軽量なソリューションである SQLite DB を選択しました。このデータベースを使用すると、すべてのデータが 1 つのファイルに保存され、参照やバックアップが簡単になり、データ サイエンス エンジニアの学習曲線が短縮されます。
顔認識にはオフィスに来る可能性のあるすべての従業員の写真が必要であるため、会社のデータベースに保存されている顔写真を使用します。オフィスの出入り口に設置された Jetson デバイスは、人々が顔認証を使用してドアを開けるときに顔データのサンプルも収集します。
当初は音声データが利用できなかったため、データ収集を整理し、20 秒のクリップを録音するよう依頼しました。次に、音声検証モデルを使用して各人のベクトルを取得し、データベースに保存します。任意のオーディオ入力デバイスを使用して音声サンプルをキャプチャできます。私たちのプロジェクトでは、携帯電話とマイク内蔵の Web カメラを使用して音声を録音します。
顔検出
顔検出では、特定のシーンに人間の顔が存在するかどうかを判断できます。その場合、モデルは各顔の座標を提供して、顔のランドマークを含め、画像上の各顔の位置を把握できるようにする必要があります。次のステップで顔認識を実行するには、境界ボックスで顔を受け取る必要があるため、この情報は重要です。
顔検出には、InsightFace プロジェクトの RetinaFace モデルと MobileNet 主要コンポーネントを使用しました。モデルは、画像上で検出された顔ごとに 4 つの座標を 5 つの顔ラベルとともに出力します。実際、異なる角度で撮影したり、異なる光学系を使用して撮影した画像は、歪みにより顔のプロポーションが変化する場合があります。これにより、モデルが人物を識別することが困難になる可能性があります。
このニーズを満たすために、顔のランドマークはモーフィングに使用されます。これは、同じ人物のこれらの画像間に存在する可能性のある違いを減らす技術です。したがって、取得された切り取られて歪んだ表面はより類似して見え、抽出された顔ベクトルはより正確になります。 顔認識
次のステップは顔認識です。この段階では、モデルは与えられた画像 (つまり、取得した画像) から人物を認識する必要があります。識別は、参照 (グラウンド トゥルース データ) を利用して行われます。したがって、ここでは、モデルは 2 つのベクトル間の差の距離スコアを測定することによって 2 つのベクトルを比較し、カメラの前に立っているのが同一人物であるかどうかを判断します。評価アルゴリズムは、それを従業員の最初の写真と比較します。
顔認識は、SE-ResNet-50 アーキテクチャのモデルを使用して完了します。モデルの結果をより堅牢にするために、顔ベクトル入力を取得する前に画像が反転され、平均化されます。この時点でのユーザー識別プロセスは次のとおりです。
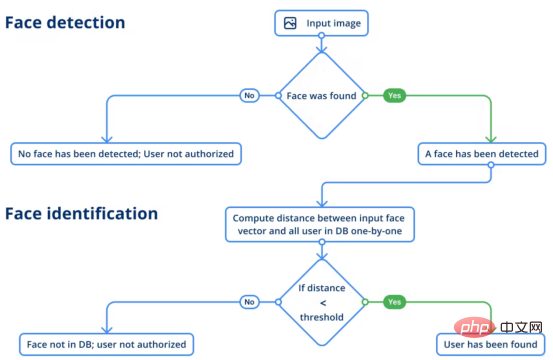 顔と音声の認証プロセス
顔と音声の認証プロセス
音声認証
次に進みます。音声認証リンクへ。この手順は、両方の音声に同じ人の声が含まれていることを確認するために実行する必要があります。なぜ音声認識を検討しないのかと疑問に思われるかもしれません。その答えは、現在、顔認識は音声認識よりもはるかに優れており、画像はユーザーを識別するために音声よりも多くの情報を提供できるということです。ユーザー A を顔で識別し、ユーザー B を音声で識別することを避けるために、システムは顔認識ソリューションのみを使用します。
基本的なロジックは顔認識段階とほぼ同じで、類似したベクトルが見つからない限り、2 つのベクトルをそれらの間の距離によって比較します。唯一の違いは、前の顔認識モジュールから追い越そうとしている人物が誰であるかについての仮説がすでに存在していることです。
音声検証モジュールの積極的な開発中に、多くの問題が発生しました。
Jasper アーキテクチャを使用した以前のモデルでは、同じ人が異なるマイクから録音したものを検証できませんでした。したがって、従業員の検証をより適切に行う SpeechBrain フレームワークの VoxCeleb2 データセットでトレーニングされた ECAPA-TDNN アーキテクチャを使用して、この問題を解決しました。
ただし、オーディオ クリップにはまだ前処理が必要です。目的は、サウンドを維持し、現在のバックグラウンドノイズを低減することにより、オーディオ録音の品質を向上させることです。ただし、すべてのテスト手法は音声検証モデルの品質に重大な影響を与えます。おそらく、わずかなノイズ低減でも録音内の音声の音声特性が変化するため、モデルは人物を正しく認証できなくなります。 さらに、音声録音の長さと、ユーザーが発音すべき単語の数についても調査しました。この調査の結果、私たちはいくつかの推奨事項を作成しました。結論は、このような録音の長さは少なくとも 3 秒で、約 8 単語を読み上げる必要があるということです。 音声からテキストへのスプーフィング防止
最後のセキュリティ対策は、システムが
QuartzNetに基づいて音声からテキストへのスプーフィング防止を適用することです。 Nemo フレームワーク内。このモデルは優れたユーザー エクスペリエンスを提供し、リアルタイム シナリオに適しています。ユーザーの発言がシステムの期待にどれだけ近いかを測定するには、ユーザー間のレーベンシュタイン距離を計算する必要があります。
顔認証モジュールを欺くために従業員の写真を入手することは、音声サンプルを録音することと同様に、達成可能なタスクです。 Speech-to-Text のなりすまし防止は、侵入者が許可された職員の写真や音声を使用してオフィスへの侵入を試みるシナリオをカバーしません。アイデアは単純です。各人は自分自身を認証するときに、システムによって与えられたフレーズを話します。フレーズは、ランダムに選択された単語のセットで構成されます。フレーズ内の単語の数はそれほど多くありませんが、実際に可能な組み合わせの数は非常に膨大です。ランダムに生成されたフレーズを適用することで、許可されたユーザーが多数の録音されたフレーズを話す必要があるシステムのなりすましの可能性が排除されます。ユーザーの写真があるだけでは、この保護機能を備えた AI セキュリティ システムを欺くには十分ではありません。
エッジ生体認証システムの利点現時点では、エッジ生体認証システムを使用すると、ユーザーはドアのロックを解除するためにランダムに生成されたフレーズを話す必要がある簡単なプロセスに従うことができます。さらに、顔検出によるオフィスエントランスのAI監視サービスも提供しています。
音声検証および音声からテキストへのなりすまし防止モジュール「複数のエッジ デバイスを追加することで、システムを簡単に変更してさまざまなシナリオに拡張できます」中。通常のコンピューターと比較して、ネットワーク上で Jetson を直接構成し、GPIO インターフェイスを介して低レベルのデバイスとの接続を確立し、新しいハードウェアで簡単にアップグレードできます。また、Web API を備えたデジタル セキュリティ システムと統合することもできます。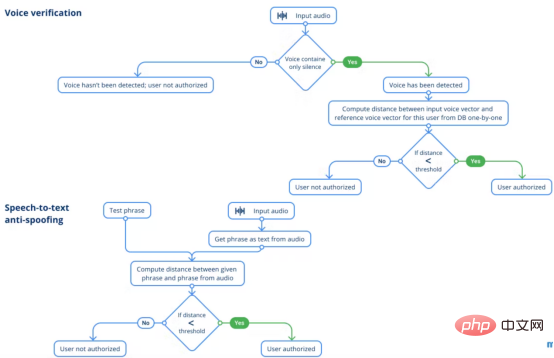 しかし、このソリューションの主な利点は、特に中断することなく入口でデータを収集できるため、デバイスから直接データを収集することでシステムを改善できることです。」
しかし、このソリューションの主な利点は、特に中断することなく入口でデータを収集できるため、デバイスから直接データを収集することでシステムを改善できることです。」
——ダニエル リャドフ (MobiDev の Python エンジニア)
翻訳者紹介
Zhu Xianzhong、51CTO コミュニティ編集者、51CTO エキスパートブロガー、講師、濰坊の大学のコンピューター教師、ベテランフリーランスプログラミングの世界では。
元のタイトル: エッジ バイオメトリクスを使用した AI セキュリティ システムの開発 、著者: ドミトリー・キシル
以上がエッジ生体認証を活用したAIセキュリティシステムの開発の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。