



コンピューター ビジョンや自然言語処理など、機械学習 (ML) 研究の複数のサブフィールドにおける最近の進歩の多くは、すべてのデータを効率的に吸収できる大規模で多様なデータ セットと表現を活用することに基づいて構築されています。 。
ただし、この高性能モデル手法は、ロボット工学の分野ではあまり応用されていません。
理由は簡単で、第一に、大規模かつ多様なロボット データが不足しているため、モデルがロボットの幅広い経験を吸収する能力が制限されます。
第 2 に、このようなデータセットから学習して効果的に一般化できる、表現力が高く、スケーラブルで、十分に高速なリアルタイム推論モデルが不足しています。
今回、Google の Robotics Transformer 1 (略して RT-1) は、ロボットの入出力アクション (カメラ画像、タスクの指示、モーターなど) をラベル付けできるマルチタスク モデルです。コマンド) を使用して、実行時の効率的な推論を可能にし、リアルタイム制御を可能にします。

#RT-1 は、ロボットがさまざまな環境でさまざまなタスクを実行できるようにするために大量のデータを吸収し、それによって機械を改善しますパフォーマンスと汎用性 能力
簡単に言えば、ロボットに複数の仕事を同時に実行させることを意味します。
モデルは、Everyday Robots (EDR) の 13 台のマシンを使用して、700 以上のタスクをカバーする 130,000 のエピソードを含む大規模な現実世界のロボット データセットでトレーニングされました。ロボットは一定の期間にわたって収集されました。 17か月の。
結果は、RT-1 が既存の手法と比較して、新しいタスク、環境、オブジェクトに対するゼロショットの一般化を大幅に改善できることを示しています。
編集者は慎重に以下に Github リンクを設置しましたので、ご興味がございましたら、ぜひご覧ください。

https://github.com/google-research/robotics_transformer# # RT-1 モデル固有の原理
RT-1 は Transformer アーキテクチャに基づいて構築されており、ロボットのカメラから画像履歴を取得し、自然言語で表現されたタスクの説明を入力として受け取り、出力することができます。トークン化されたアクション。RT-1 のアーキテクチャは、因果マスキングを使用した標準的なカテゴリカルクロスエントロピー目標に対してトレーニングされたデコーダのみのシーケンス モデルのアーキテクチャと似ています。
 モデルは入力テキスト命令と一連の画像を受け取り、事前トレーニングされた FiLM EfficientNet モデルを通じてトークンにエンコードします。 TokenLearner を介して圧縮し、Transformer を介してアクション タグを出力します。
モデルは入力テキスト命令と一連の画像を受け取り、事前トレーニングされた FiLM EfficientNet モデルを通じてトークンにエンコードします。 TokenLearner を介して圧縮し、Transformer を介してアクション タグを出力します。
その主な機能には、画像トークン化、アクショントークン化、トークン圧縮が含まれます。
- 画像のトークン化: ImageNet で事前トレーニングされた EfficientNet-B3 モデルに画像を渡し、結果の 9×9×512 の空間特徴マップを 81 個のトークンに平坦化します。画像トークナイザーは、自然言語のタスク命令に基づいて条件付けされ、ID に初期化された FiLM レイヤーを使用して、タスクに関連する画像の特徴を早期に抽出します。
- アクションのトークン化: ロボットのアクションの次元は、アームの動きの 7 つの変数 (x、y、z、ロール、ピッチ、ヨー、クランプ オープン) です。 3 つの基本的なモーション変数 (x、y、yaw)、および 3 つのモード間を切り替えるための追加の離散変数。
- トークン圧縮: モデルは、要素アテンション モジュール TokenLearner 圧縮を使用した学習への影響に基づいて、画像トークンのソフトな組み合わせを適応的に選択します。その結果、2.4 以上の圧縮が得られます。 x 推論が速くなります。

人間による遠隔操作によるデモンストレーションと、各ロボットの実行命令のテキストによる説明を使用します。 1つのエピソードに注釈を付けます。
このロボットは、「7 自由度のアーム、2 本指のグリッパー、および可動ベース」に依存してタスクを実行します。
データセットで表現されている一連の高度なスキルには、アイテムの選択と配置、引き出しの開閉、引き出しへのアイテムの出し入れ、長くて薄いアイテムを直立させて保持すること、および裏返して操作を待ちます。
異種データ ソースの統合
RT-1 をさらに進化させるために、別のロボットから収集したデータを使用して RT-1 をトレーニングし、(1) モデルがロボット上でパフォーマンスを発揮するかどうかをテストしました。新しいデータ ソースが提示されたときに元のタスクが維持されるかどうか、(2) 新しい異なるデータによる一般化においてモデルが改善されるかどうか。
EDR を使用して収集した元のデータセットのアクション仕様と境界に一致するように収集したデータを変換し、各データセットにタスクの指示をラベル付けします。
Kuka データは、各トレーニング バッチで 1:2 の比率で EDR データと混合され、元の EDR スキルの退行を制御します。

#写真は複数のロボットからデータを収集する場合の学習方法を示しています
# #結果は、RT-1が他のロボットを観察する経験を通じて新しいスキルを習得できることを示しています。
Kuka のビンピッキング データとロボット教室からの既存の EDR データで RT-1 がトレーニングされたとき、EDR データのみを使用してトレーニングされた場合、精度が 22% 向上しました。「ほぼ 2 倍」 39%まで。

Kuka からのピッキング データのみを使用して RT-1 をトレーニングし、EDR ロボットからのピッキング データを使用して評価した場合の精度は 0% です。
実験結果RT-1 の汎化能力をより深く理解するために、Gato、BC-Z、BC-Z XL の 3 つのベースラインに対するパフォーマンスを調査しました (つまり、RT-1 と同じ数のパラメーターを持つ BC-Z)。
そしてそれを 4 つのカテゴリに分けます:

写真はテスト環境を示しています パフォーマンスRT-1 と対照群の #
- 見たタスクのパフォーマンス (見たタスクのパフォーマンス): トレーニング中に観察されたタスクのパフォーマンス;
-
目に見えないタスクのパフォーマンス (目に見えないタスクのパフォーマンス): トレーニング中に観察されたパフォーマンストレーニング セット内でスキルとオブジェクトが分離されている目に見えないタスク;
- ロバスト性: 邪魔者の介入中 パフォーマンスと背景変化のパフォーマンス (新しいキッチン) 、照明、背景シーン)
- 長期シナリオ: 実際のキッチンでの SayCan のような自然言語命令の実行
RT-1 の高いパフォーマンスと汎用化機能により、SayCan を介した長距離のモバイル操作タスクが可能になります。
SayCan は、ロボットのアフォーダンス内に言語モデルを配置し、少数のプロンプトを使用して、自然言語を表現するという長期的なタスクを一連の低レベルのスキルに分解することで機能します。 。
RT-1 と他の 2 つのベースライン (Gato を使用した SayCan および BC-Z を使用した SayCan) を使用して、2 つの実際のキッチンで SayCan を評価しました。
以下の「キッチン 2」は、「キッチン 1」よりも困難な一般化シナリオを示しています。ほとんどのトレーニング データの収集に使用されるシミュレートされたキッチンは、Kitchen1 をモデルにしています。

Kitchen1 の RT-1 を使用した SayCan の実行成功率は 67% であり、他のベースラインよりも優れていることがわかります。
SayCan with Gato および SayCan with BCZ のパフォーマンスは、新しい目に見えないキッチンによって引き起こされる汎化の困難により低下しましたが、それに応じて RT-1 の成功率は低下しませんでした。
以上がGoogle RT-1 モデルはロボットに複数のジョブを依頼し、700 件の命令の成功率は 97% でしたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 AIエージェントを使用してパーソナライズされたニュースダイジェストを作成しますApr 12, 2025 am 11:18 AM
AIエージェントを使用してパーソナライズされたニュースダイジェストを作成しますApr 12, 2025 am 11:18 AM導入 大規模な言語モデル(LLM)の機能は迅速に進んでいます。これらにより、さまざまなLLMアプリケーションを構築できます。これらは、タスクの自動化からワークフローの最適化にまで及びます。 1つのエキサイティングなアプリケーションはです
 米国のAIポリシーは、「安全」から「セキュリティ」に急激にピボットしますApr 12, 2025 am 11:15 AM
米国のAIポリシーは、「安全」から「セキュリティ」に急激にピボットしますApr 12, 2025 am 11:15 AMドナルド・トランプ大統領は、彼の任期の1日目にジョー・バイデン前大統領のAIの大統領命令を取り消しました(開示:私はバイデン政権中に国土安全保障省でAIの上級カウンセラーを務めました)、およびJD VA副大統領
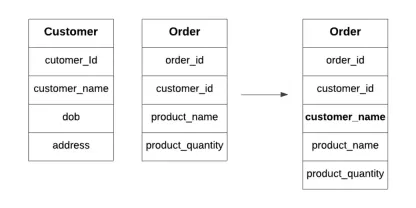 データベースの非正規化とは何ですか?Apr 12, 2025 am 11:10 AM
データベースの非正規化とは何ですか?Apr 12, 2025 am 11:10 AM導入 毎秒数が重要な忙しいカフェを走らせることを想像してみてください。個別の在庫リストと注文リストを常にチェックする代わりに、すべての重要な詳細を1つの読みやすいボードに統合します。これはデノマリザに似ています
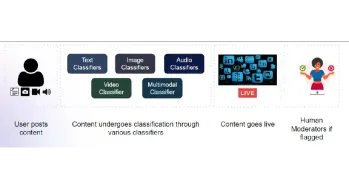 コンテンツモデレートのためのマルチモーダルモデルの構築Apr 12, 2025 am 10:51 AM
コンテンツモデレートのためのマルチモーダルモデルの構築Apr 12, 2025 am 10:51 AM導入 攻撃的な投稿がポップアップ表示されないときに、お気に入りのソーシャルメディアプラットフォームをスクロールしていると想像してください。レポートボタンを押す前に、それはなくなりました。それはコンテンツモデラティです
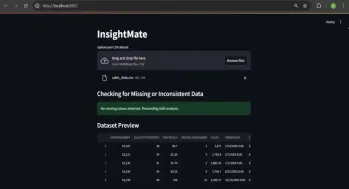 Insightmateでデータの洞察を自動化しますApr 12, 2025 am 10:44 AM
Insightmateでデータの洞察を自動化しますApr 12, 2025 am 10:44 AM導入 今日のデータが多い世界では、巨大なデータセットの処理はかなり圧倒される可能性があります。それが洞察客の出番です。それはあなたのデータを簡単にするように設計されています。データセットをアップロードするだけで、Instanが表示されます
 ベクトルストリーミング:錆を使用したメモリ効率の高いインデックスApr 12, 2025 am 10:42 AM
ベクトルストリーミング:錆を使用したメモリ効率の高いインデックスApr 12, 2025 am 10:42 AM導入 埋め込みのベクトルストリーミングが導入されています。これは、大規模なドキュメントの埋め込みを最適化するように設計されています。 Rustの並行性を使用して非同期チャンクと埋め込みを可能にすると、メモリの使用が減少し、
 レプリットエージェントとは何ですか? |入門ガイド - 分析VidhyaApr 12, 2025 am 10:40 AM
レプリットエージェントとは何ですか? |入門ガイド - 分析VidhyaApr 12, 2025 am 10:40 AM導入 会話と同じように簡単にアプリを開発することを想像してください。セットアップする複雑な開発環境はなく、構成ファイルを調べる必要はありません。コンセプトを貴重なアプリに変換する
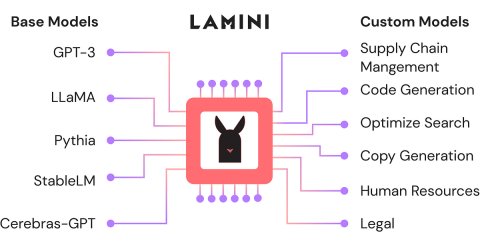 ラミニを使用してオープンソースLLMを微調整します。分析vidhyaApr 12, 2025 am 10:20 AM
ラミニを使用してオープンソースLLMを微調整します。分析vidhyaApr 12, 2025 am 10:20 AM最近、大規模な言語モデルとAIの台頭により、自然言語処理における無数の進歩が見られました。テキスト、コード、画像/ビデオ生成などのドメインのモデルは、人間のような推論とPをアーカイブしています


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

SublimeText3 中国語版
中国語版、とても使いやすい

