| #モデル
|
#リリース時期
|
層数
|
ヘッド数
|
# #ワードベクトル長
|
パラメータ量
|
事前学習データ量
|
| GPT-1
|
2018 年 6 月
|
12
|
#12
|
768 |
1 億 1700 万 |
約 5GB |
GPT-2 |
##2019 年 2 月
|
48
|
-
|
1600
|
15 億
|
40GB
|
| GPT-3
|
2020 年 5 月
|
96
| 96
|
12888
|
1750 億
| #45TB |
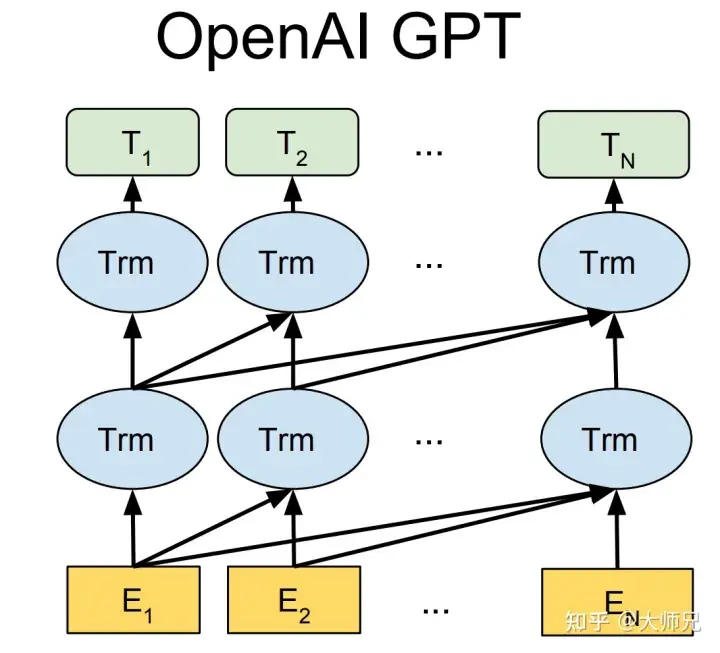
GPT-1 は BERT より数か月早く誕生しました。これらはすべて、コア構造として Transformer を使用します。違いは、GPT-1 が事前トレーニング タスクを左から右へ生成的に構築し、その後、一般的な事前トレーニング モデルを取得することです。このモデルは、BERT などの下流タスクに使用できます。微調整。 GPT-1 は当時 9 つの NLP タスクで SOTA 結果を達成しましたが、GPT-1 で使用されるモデル サイズとデータ量が比較的小さかったため、GPT-2 が誕生しました。
GPT-1 と比較して、GPT-2 はモデル構造については大騒ぎせず、より多くのパラメーターとより多くのトレーニング データを持つモデルを使用しただけです (表 1)。 GPT-2の最も重要な考え方は「すべての教師あり学習は教師なし言語モデルのサブセットである」という考え方であり、この考え方はプロンプト学習の前身でもあります。 GPT-2 は、初めて誕生したときも大きなセンセーションを巻き起こし、それが生み出したニュースは、ほとんどの人間を欺き、本物であるかのように見せかける効果を得るのに十分でした。当時は「AI界で最も危険な兵器」とさえ呼ばれ、多くのポータルがGPT-2によって生成されたニュースの使用禁止を命じた。
GPT-3 が提案されたとき、GPT-2 をはるかに上回る効果に加えて、さらなる議論を引き起こしたのは、その 1,750 億個のパラメータでした。 GPT-3 が一般的な NLP タスクを完了できることに加えて、研究者らは予期せず、GPT-3 が SQL や JavaScript などの言語でコードを記述し、単純な数学演算を実行する際にも優れたパフォーマンスを発揮することを発見しました。 GPT-3 のトレーニングでは、メタ学習の一種であるインコンテキスト学習が使用されます。メタ学習の中心的な考え方は、モデルが高速に実行できるように、少量のデータを通じて適切な初期化範囲を見つけることです。限られたデータセットに当てはめると良好な結果が得られます。
上記の分析を通じて、パフォーマンスの観点から、GPT には 2 つの目標があることがわかります:
- 一般的な NLP タスクにおけるモデルのパフォーマンスを向上させる;
- 他の非典型的な NLP タスク (コード作成、数学的演算など) におけるモデルの汎化能力を向上させます。
さらに、事前トレーニング モデルの誕生以来、批判されてきた問題は、事前トレーニング モデルのバイアスです。事前学習モデルは膨大なデータを通じて非常に大きなパラメータレベルのモデルを学習させるため、人為的なルールで完全に制御されるエキスパートシステムに比べて、事前学習モデルはブラックボックスのようなものです。数十ギガバイト、場合によっては数十テラバイトのトレーニング データには、ほぼ確実に同様のトレーニング サンプルが含まれているため、事前トレーニングされたモデルが人種差別や性差別などを含む危険なコンテンツを生成しないことを保証する人は誰もいません。これが InstructGPT と ChatGPT の動機です。この論文では 3H を使用して最適化目標を要約しています:
- Useful (役に立つ);
- Trusted (Honest);
- 無害です。
OpenAI の GPT シリーズ モデルはオープン ソースではありませんが、モデルの試用 Web サイトが提供されており、資格のある学生は自分で試すことができます。
1.2 Instruct Learning (Instruct Learning) と Prompt Learning (Prompt Learning) Learning
Instructed learning は、Google Deepmind の Quoc V.Le チームによる 2021 年の記事「Finetuned Language Models Are」です。 「ゼロショット学習者」の記事で提案されたアイデア [5]。指導学習と即時学習の目的は、言語モデル自体の知識を利用することです。違いは、Prompt が文の前半に基づいて文の後半を生成したり、空白を埋めたりするなど、言語モデルの完成能力を刺激することです。 Instruct は言語モデルの理解能力を刺激し、より明確な指示を与えることでモデルが正しいアクションを実行できるようにします。次の例を通して、これら 2 つの異なる学習方法を理解することができます:
- 学習のヒント: 私はガールフレンドのためにこのネックレスを買いました。彼女はとても気に入っています。このネックレスはとても ____ です。
- 学習手順: この文の感情を判断してください: 私はガールフレンドのためにこのネックレスを買いました、そして彼女はそれをとても気に入っています。オプション: A= 良好、B= 平均、C= 不良。
命令学習の利点は、複数のタスクを微調整した後、他のタスクでもゼロショットを実行できることですが、命令学習はすべて 1 つのタスクを目的としています。一般化能力は指示された学習ほど優れていません。図 2 を見ると、微調整、手がかり学習、指示あり学習を理解できます。
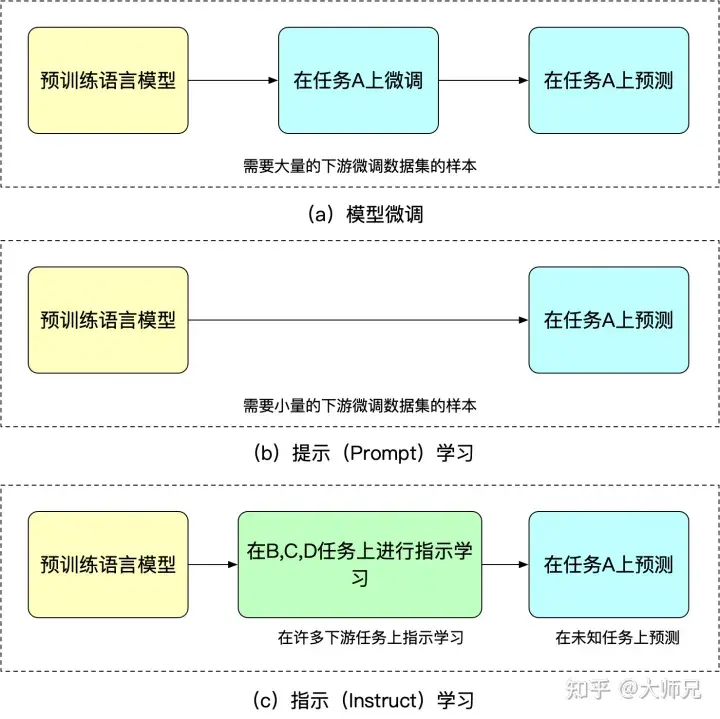
図 2: モデルの微調整、即時学習、指示付き学習の類似点と相違点
1.3 人工フィードバックによる強化学習
トレーニングされたモデルはあまり制御可能ではないため、モデルはトレーニング セットの分布に適合しているとみなすことができます。次に、生成モデルにフィードバックされると、トレーニング データの分布が、生成されるコンテンツの品質に影響を与える最も重要な要素になります。場合によっては、生成されたデータの有用性、信頼性、無害性を確保するために、モデルがトレーニング データの影響を受けるだけでなく、人為的に制御可能であることを望むことがあります。論文の中で何度も言及されているアライメントの問題は、モデルの出力内容と人間が好む出力コンテンツとのアライメントとして理解できます。人間が好むとは、生成されたコンテンツの流暢さや文法的な正しさだけではなく、生成されたコンテンツの品質、有用性、信頼性、無害性も重要です。
強化学習は、報酬 (Reward) メカニズムを通じてモデル トレーニングをガイドすることがわかっています。報酬メカニズムは、従来のモデル トレーニング メカニズムの損失関数とみなすことができます。報酬の計算は損失関数よりも柔軟かつ多様です (AlphaGO の報酬はゲームの結果です)。その代償として、報酬の計算は微分可能ではないため、逆伝播に直接使用することはできません。強化学習の考え方は、モデルのトレーニングを達成するために、報酬の多数のサンプルを通じて損失関数を適合させることです。同様に、人間のフィードバックも導出不可能であるため、強化学習の報酬として人為的なフィードバックを利用することもでき、時代の要請に応じて人為的なフィードバックに基づく強化学習が登場しました。
RLHF は、2017 年に Google によって公開された「Deep Reinforcement Learning from Human Preferences」[6] に遡ることができます。これは、手動のアノテーションをフィードバックとして使用して、シミュレートされたロボットや Atari ゲームにおける強化学習のパフォーマンスを向上させます。効果。
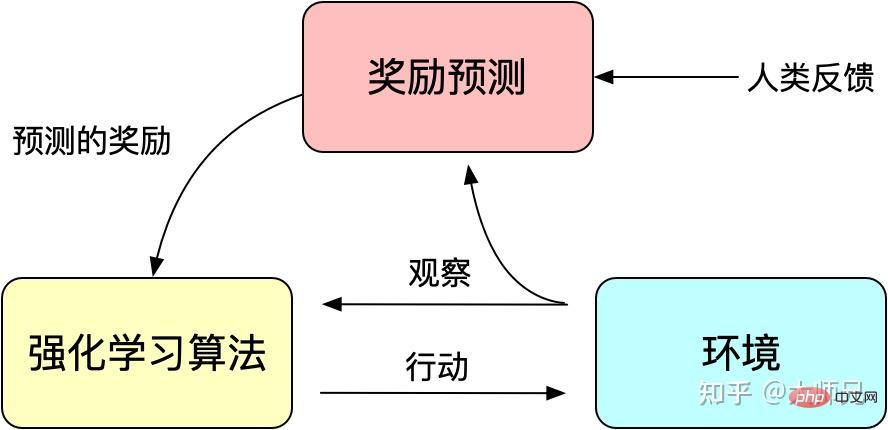
図 3: 人工フィードバックによる強化学習の基本原理
InstructGPT/ChatGPT は、強化学習で古典的なアルゴリズム、つまり OpenAI Proximal によって提案されたアルゴリズムも使用します。ポリシー最適化 (PPO) [7]。 PPO アルゴリズムは新しいタイプのポリシー グラデーション アルゴリズムです。ポリシー グラデーション アルゴリズムはステップ サイズに非常に敏感ですが、適切なステップ サイズを選択するのは困難です。トレーニング プロセス中に、古いポリシーと新しいポリシーの違いが変化した場合、大きすぎると学習に悪影響を及ぼします。 PPO は、複数のトレーニング ステップで小さなバッチ更新を達成できる新しい目的関数を提案し、ポリシー勾配アルゴリズムにおけるステップ サイズの決定が難しいという問題を解決しました。実際、TRPO もこのアイデアを解決するように設計されていますが、TRPO アルゴリズムと比較すると、PPO アルゴリズムの方が解決しやすいです。
2. InstructGPT/ChatGPT 原則の解釈
上記の基本知識があれば、InstructGPT と ChatGPT を理解するのがはるかに簡単になります。簡単に言うと、InstructGPT/ChatGPT はどちらも GPT-3 のネットワーク構造を採用し、命令学習によってトレーニング サンプルを構築し、予測コンテンツの効果を反映した報酬モデル (RM) をトレーニングします。強化学習モデルのガイドに使用されます。 InstructGPT/ChatGPT のトレーニング プロセスを図 4 に示します。
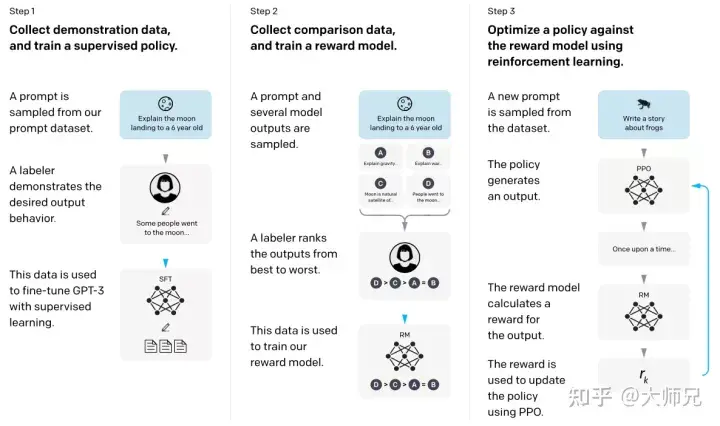
図 4: InstructGPT の計算プロセス: (1) 教師あり微調整 (SFT); (2) 報酬モデル (RM) トレーニング; (3) 報酬に基づくPPO を通じてモデルは強化学習を実行します。
図 4 から、InstructGPT/ChatGPT のトレーニングは 3 つのステップに分割でき、ステップ 2 と 3 で報酬モデルと強化学習 SFT モデルを繰り返し最適化できることがわかります。
- 収集された SFT データセットに基づいて GPT-3 の教師あり微調整 (Supervised FineTune、SFT) を実行します;
- 手動でラベル付けされた比較データを収集し、報酬モデルをトレーニングします (Reword) Model) , RM);
- RM を強化学習の最適化目標として使用し、PPO アルゴリズムを使用して SFT モデルを微調整します。
図 4 に従って、InstructGPT/ChatGPT のデータセット収集とモデル トレーニングの 2 つの側面をそれぞれ紹介します。
2.1 データセットの収集
図 4 に示すように、InstructGPT/ChatGPT の学習は 3 つのステップに分かれており、各ステップで必要なデータが少し異なりますので、分けて紹介します。下に。
2.1.1 SFT データ セット
SFT データ セットは、最初のステップで教師ありモデルをトレーニングするために使用されます。つまり、収集された新しいデータを使用して、GPT-3 は以下に従ってトレーニングされます。 GPT-3 トレーニング メソッドを使用する 3 微調整を行います。 GPT-3 はプロンプト学習に基づく生成モデルであるため、SFT データセットもプロンプトと応答のペアで構成されるサンプルです。 SFT データの一部は OpenAI の PlayGround ユーザーから提供され、もう 1 つの部分は OpenAI が雇用する 40 人のラベラーから提供されます。そして彼らはラベラーを訓練しました。このデータセットでは、アノテーターの仕事は内容に基づいて指示を記述することですが、その指示は次の 3 点を満たす必要があります。
- 単純なタスク: ラベラーは、タスクの多様性を確保しながら、任意の単純なタスクを与えます。
- 少数ショット タスク: ラベラーは、指示と、その指示に対する複数のクエリを与えます。
- ユーザー関連: インターフェースからユースケースを取得し、ラベル作成者にこれらのユースケースに基づいて指示を作成させます。
2.1.2 RM データ セット
RM データ セットは、ステップ 2 で報酬モデルをトレーニングするために使用されます。また、InstructGPT/ のトレーニングの報酬ターゲットを設定する必要があります。チャットGPT。この報酬目標は微分可能である必要はありませんが、モデルが生成する必要があるものとできるだけ包括的かつ現実的に一致している必要があります。もちろん、この報酬は手動のアノテーションによって提供することもできますし、人為的なペアリングを通じて、バイアスを含む生成されたコンテンツに低いスコアを与え、人間が好まないコンテンツを生成しないようにモデルを促すことができます。 InstructGPT/ChatGPT のアプローチは、最初にモデルに候補テキストのバッチを生成させ、次にラベラーを使用して、生成されたデータの品質に従って生成されたコンテンツを並べ替えることです。
2.1.3 PPO データ セット
InstructGPT の PPO データには注釈が付けられておらず、GPT-3 API ユーザーから取得されます。さまざまなユーザーによって提供される生成タスクにはさまざまな種類があり、その割合が最も高いのは生成タスク (45.6%)、QA (12.4%)、ブレインストーミング (11.2%)、対話 (8.4%) などです。
2.1.4 データ分析
InstructGPT/ChatGPT は GPT-3 に基づいて微調整されており、手動のアノテーションが含まれるため、図に示すように総データ量は大きくありません。表 2 に 3 つのデータのソースとそのデータ量を示します。
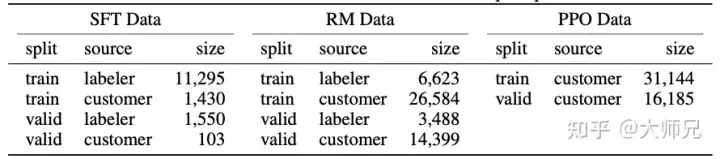
表 2: InstructGPT のデータ分布
この論文の付録 A では、データの分布について詳しく説明しています。ここでは、いくつかの可能性を列挙します。モデル効果に影響を与えるもの:
- データの 96% 以上が英語であり、中国語、フランス語、スペイン語などの他の 20 言語を合計すると 4% 未満になります, これにより InstructGPT/ChatGPT が失敗する可能性があります。他の言語を生成しますが、その効果は英語よりはるかに劣るはずです。
- プロンプトには 9 種類あり、そのほとんどが生成タスクであり、タスクにつながる可能性があります。モデルでカバーされていないタイプ;
- 40 人のアウトソーシング従業員は米国と東南アジア出身です。彼らは比較的集中しており、数は少ないです。InstructGPT/ChatGPT の目標は、事前に訓練を受けることです。正しい値を使用したトレーニング モデルその値は、これら 40 人のアウトソーシング従業員の値を組み合わせたものです。そして、この比較的狭い分布は、他の地域がより懸念している差別や偏見の問題を引き起こす可能性があります。
また、ChatGPT のブログでは、ChatGPT と InstructGPT の学習方法は同じであると述べられていましたが、唯一の違いはデータを収集することですが、データ収集に関する詳細な情報はありませんでした。 。 ChatGPT が対話の分野でのみ使用されることを考慮すると、ChatGPT にはデータ収集の 2 つの違いがあると考えられます: 1. 対話タスクの割合が増加する、2. プロンプト方式を Q&A 方式に変換する。もちろん、これは単なる推測であり、より正確な説明は、ChatGPT の論文やソースコードなどの詳細な情報が公開されるまでわかりません。
2.2 トレーニング タスク
InstructGPT/ChatGPT には 3 ステップのトレーニング方法があることを紹介しました。これら 3 つのトレーニング ステップには、SFT、RM、PPO の 3 つのモデルが含まれますが、これらについては以下で詳しく紹介します。
2.2.1 教師あり微調整 (SFT)
このステップのトレーニングは GPT-3 と一致しており、著者はモデルを適切にオーバーフィットさせることが次のステップで役立つことを発見しました。トレーニングの2ステップ。
2.2.2 報酬モデル (RM)
RM をトレーニングするためのデータは、生成された結果に従ってソートされたラベラーの形式であるため、回帰モデルとみなすことができます。 RM 構造は、SFT でトレーニングされたモデルの最後の埋め込み層を削除したモデルです。入力はプロンプトと応答であり、出力は報酬値です。具体的には、プロンプトごとに、InstructGPT/ChatGPT は K 個の出力 (4≤K≤9) をランダムに生成し、出力結果をペアで各ラベラーに表示します、つまり、各プロンプトには合計 CK2 の結果が表示されます。その中からより良い出力を選択します。トレーニング中、InstructGPT/ChatGPT は各プロンプトの CK2 応答ペアをバッチとして扱います。プロンプトごとにバッチ処理するこのトレーニング方法は、各プロンプトがモデルに入力されるため、サンプルごとにバッチ処理する従来の方法よりもオーバーフィットする可能性が低くなります。 1回だけ。
報酬モデルの損失関数は式(1)で表されます。この損失関数の目標は、ラベル付け者が好む応答と嫌いな応答の差を最大化することです。
(1)損失(θ)=−1(K2)E(x,yw,yl)∼D[log(σ(rθ(x,yw)−rθ(x,yl)) )]
ここで、rθ(x,y) はパラメータ θ をもつ報酬モデルにおけるプロンプト x と応答 y の報酬値、yw はラベラーが好む応答結果、yl はラベラーが好まない応答結果です。 。 D はトレーニング データ セット全体です。
2.2.3 強化学習モデル (PPO)
強化学習モデルと事前トレーニング モデルは、過去 2 年間で最も注目されている AI の方向性の 2 つです。多くの科学研究者は以前、強化学習について次のように述べています。 is not One は、モデルの出力コンテンツから報酬メカニズムを構築するのが難しいため、事前トレーニングされたモデルに適用するのに適しています。 InstructGPT/ChatGPT はこれを直観に反して実現しており、このアルゴリズムの最大の革新である手動アノテーションを組み合わせることで、事前トレーニングされた言語モデルに強化学習を導入します。
表 2 に示すように、PPO のトレーニング セットはすべて API から提供されます。ステップ 2 で取得した報酬モデルを使用して、SFT モデルの継続的なトレーニングをガイドします。多くの場合、強化学習はトレーニングが非常に困難です。InstructGPT/ChatGPT はトレーニング プロセス中に 2 つの問題に遭遇しました:
- 質問 1: モデルが更新されると、強化学習モデルによって生成されたデータとトレーニング報酬モデルのデータの差はますます大きくなるでしょう。著者の解決策は、KL ペナルティ項 βlog(πϕRL(y∣x)/πSFT(y∣x)) を損失関数に追加して、PPO モデルの出力と SFT の出力が大きく変わらないようにすることです。
- 問題 2: トレーニングに PPO モデルのみを使用すると、一般的な NLP タスクにおけるモデルのパフォーマンスが大幅に低下します。著者の解決策は、一般的な言語モデルのターゲット γEx∼Dpretrain [ log(πϕRL) を追加することです。 (x))]、この変数は論文では PPO-ptx と呼ばれます。
まとめると、PPO のトレーニング目標は式 (2) です。 (2) 目的 (ϕ)=E(x,y)∼DπϕRL[rθ(x,y)−βlog(πϕRL(y∣x)/πSFT(y∣x))] γEx∼Dpretrain [log(πϕRL) (x))]
3. InstructGPT/ChatGPT のパフォーマンス分析
InstructGPT/ChatGPT の効果が、特に手動アノテーションの導入後、非常に優れていることは否定できません。人間の行動パターンの「価値」、正しさ、「信憑性」が大幅に向上しました。では、InstructGPT/ChatGPT の技術ソリューションとトレーニング方法に基づいて、それがどのような改善効果をもたらすかを分析できますか?
3.1 利点
- InstructGPT/ChatGPT の効果は GPT-3 よりも現実的です。GPT-3 自体には非常に強力な一般化機能と生成機能があり、さらに On InstructGPT があるため、これは理解しやすいです。 /ChatGPT では、結果の並べ替えを迅速に作成して生成するためにさまざまなラベラーが導入されており、GPT-3 に基づいて微調整されているため、報酬モデルのトレーニング時に、より現実的なデータに対してより高い報酬を得ることができます。著者はまた、TruthfulQA データセットで GPT-3 とのパフォーマンスを比較しましたが、実験結果では、13 億の小型 PPO-ptx でも GPT-3 よりも優れたパフォーマンスを示しています。
- InstructGPT/ChatGPT は、モデルの無害性の点で GPT-3 よりもわずかに無害です。原理は上記と同じです。しかし、著者は、InstructGPT が差別、偏見、その他のデータセットを大幅に改善しないことを発見しました。これは、GPT-3 自体が非常に有効なモデルであり、有害、差別的、偏った条件などの問題のあるサンプルが生成される確率が非常に低いためです。わずか 40 人のラベル作成者によって収集され、注釈が付けられたデータでは、これらの側面でモデルを完全に最適化できない可能性が高いため、モデルのパフォーマンスの向上はほとんど、または目立たないものになります。
- InstructGPT/ChatGPT は強力なコーディング機能を備えています: まず、GPT-3 は強力なコーディング機能を備えており、GPT-3 に基づく API にも大量のコーディング コードが蓄積されています。また、OpenAI の社内従業員の一部もデータ収集作業に参加しました。コーディングと手動アノテーションに関連する大量のデータを考慮すると、トレーニングされた InstructGPT/ChatGPT が非常に強力なコーディング能力を備えていることは驚くべきことではありません。
3.2 欠点
- InstructGPT/ChatGPT は、一般的な NLP タスクに対するモデルの影響を軽減します。これについては、PPO のトレーニング中に説明しましたが、損失関数は変更されます。軽減することはできますが、問題が完全に解決されたわけではありません。
- InstructGPT/ChatGPT は、ばかげた出力を与えることがあります。InstructGPT/ChatGPT は人間のフィードバックを使用しますが、人的リソースが限られているため制限されます。モデルに最も影響を与えるのは教師あり言語モデルのタスクであり、人間は修正の役割のみを果たします。したがって、限られた補正データ、または教師ありタスクの誤解 (人間が望むものではなく、モデルの出力のみを考慮する) によって制限され、非現実的なコンテンツが生成される可能性が非常に高くなります。学生と同じように、指導してくれる教師はいますが、学生がすべての知識を習得できるかどうかはわかりません。
- モデルは命令に非常に敏感です: 命令がモデルが出力を生成するための唯一の手がかりであるため、これはラベラーによって注釈が付けられたデータの量が不十分であることも原因である可能性があります。十分にトレーニングされていないため、モデルにこの問題が発生する可能性があります。
- モデルは単純な概念を過剰に解釈しています。これは、ラベラーが生成されたコンテンツを比較するときに、より長い出力コンテンツに高い報酬を与える傾向があることが原因である可能性があります。
- 有害な指示は有害な応答を出力する可能性があります。たとえば、InstructGPT/ChatGPT は、ユーザーが提案した「AI による人類破壊計画」の行動計画も提供します (図 5)。これは、InstructGPT/ChatGPT がラベラーによって書かれた命令が合理的で正しい値であると仮定しており、ユーザーによって与えられた命令についてより詳細な判断を行わないため、モデルは入力に対して応答を返します。後の報酬モデルは、このタイプの出力に対してより低い報酬値を与える可能性がありますが、モデルがテキストを生成する場合、モデルの値を考慮するだけでなく、生成されたコンテンツと指示のマッチングも考慮する必要があります。一部の値の生成に問題が発生する場合がありますが、出力することも可能です。

#図 5: ChatGPT によって作成された人類滅亡計画。
3.3 今後の課題
InstrcutGPT/ChatGPT の技術的解決策とその問題点を分析し、InstrcutGPT/ChatGPT の最適化の角度もわかりました。
- 手動アノテーションのコスト削減と効率向上: InstrcutGPT/ChatGPT は 40 人のアノテーション チームを採用していますが、モデルのパフォーマンスから判断すると、この 40 人のチームでは十分ではありません。人間がより効果的なフィードバック方法を提供し、人間のパフォーマンスとモデルのパフォーマンスを有機的かつ巧みに組み合わせられるようにする方法は非常に重要です。
- モデルの正しい命令の一般化/エラーの能力: 命令はモデルが出力を生成するための唯一の手がかりであり、モデルは命令に大きく依存しています 命令とエラー命令のモデルの一般化能力を向上させる方法 エラーの表示修正機能は、モデルのエクスペリエンスを向上させるための非常に重要なタスクです。これにより、モデルの幅広いアプリケーション シナリオが可能になるだけでなく、モデルがより「スマート」になります。
- 一般的なタスクのパフォーマンスの低下を回避する: 人間のフィードバックを使用するより合理的な方法、またはより最先端のモデル構造を設計する必要がある場合があります。 InstrcutGPT/ChatGPT の多くの問題は、より多くのラベラーラベル付きデータを提供することで解決できることを説明しましたが、これは一般的な NLP タスクのパフォーマンスのより深刻な低下につながるため、3H および一般的な NLP タスクのパフォーマンスを向上させるソリューションが必要です。結果を生み出し、バランスを達成します。
3.4 InstrcutGPT/ChatGPT の注目のトピックへの回答
- ChatGPT の出現により、低レベルのプログラマは職を失うことになるでしょうか? ChatGPT の原理と、インターネット上に流出した生成されたコンテンツから判断すると、ChatGPT によって生成されたコードの多くは正しく実行できます。しかし、プログラマーの仕事はコードを書くことだけではなく、より重要なのは問題の解決策を見つけることです。したがって、ChatGPT はプログラマ、特に高レベルのプログラマに取って代わるものではありません。それどころか、今日の多くのコード生成ツールと同様に、プログラマーにとってコードを記述するための非常に便利なツールになるでしょう。
- スタック オーバーフローは一時的なルール: ChatGPT の禁止を発表しました。 ChatGPT は本質的にテキスト生成モデルであり、コードの生成と比較して、偽のテキストの生成に優れています。さらに、テキスト生成モデルによって生成されたコードやソリューションは、実行可能で問題を解決できるという保証はありませんが、実際のテキストを装ってこの問題を問い合わせる多くの人を混乱させることになります。フォーラムの品質を維持するために、Stack Overflow は ChatGPT を禁止し、クリーンアップも行っています。
- チャットボットChatGPTに「人類滅亡計画」を書かせてコードを提供させる AI開発で注意すべき点とは? ChatGPTの「人類破壊計画」は、予期せぬ指示により膨大なデータをもとに強制的に当てはめて生成されたコンテンツです。内容は非常にリアルに見え、表現は非常に流暢ですが、これはChatGPTが非常に強い生成効果を持っていることを示しているだけであり、ChatGPTが人類を滅ぼすという考えを持っていることを意味するものではありません。これは単なるテキスト生成モデルであり、意思決定モデルではないからです。
4. 概要
アルゴリズムが最初に誕生したときの多くの人々と同じように、ChatGPT は、その有用性、信頼性、無害な効果により、業界と人類の間で幅広い注目を集めています。 . AIについての考え。しかし、そのアルゴリズムの原理を調べたところ、業界で宣伝されているほど恐ろしいものではないことがわかりました。それどころか、私たちはその技術的ソリューションから多くの貴重なことを学ぶことができます。 AI の世界における InstrcutGPT/ChatGPT の最も重要な貢献は、強化学習と事前トレーニング モデルの巧みな組み合わせです。さらに、人工的なフィードバックにより、モデルの有用性、信頼性、無害性が向上します。 ChatGPT は大規模なモデルのコストもさらに上昇させており、以前はデータ量とモデルの規模を競うだけでしたが、今ではアウトソーシングを雇う費用まで導入されており、個々の作業者の負担はさらに高額になっています。
参考文献
- ^Ouyang、Long 他「人間のフィードバックを使用した指示に従う言語モデルのトレーニング」 *arXiv プレプリント arXiv:2203.02155* (2022). https:/ /arxiv.org/pdf/2203.02155.pdf
- ^Radford, A.、Narasimhan, K.、Salimans, T.、Sutskever, I.、2018 年。生成的事前トレーニングによる言語理解の向上。https: //www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
- ^Radford, A.、Wu, J.、Child, R.、Luan, D.、Amodei, D. . and Sutskever, I., 2019. 言語モデルは教師なしマルチタスク学習者です. *OpenAI ブログ*、*1*(8)、p.9. https://life-extension.github.io/2020/05/27/ GPT テクノロジー/言語モデルに関する予備研究.pdf
- ^Brown、Tom B.、Benjamin Mann、Nick Ryder、Melanie Subbiah、Jared Kaplan、Prafulla Dhariwal、Arvind Neelakantan 他「言語モデルはほとんどありません」 -ショット学習者。" *arXiv プレプリント arXiv:2005.14165* (2020)。https://proceedings.neurips.cc/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf
- ^Wei、Jason、他.「微調整された言語モデルはゼロショット学習者です。」 *arXiv プレプリント arXiv:2109.01652* (2021). https://arxiv.org/pdf/2109.01652.pdf
- ^Christiano、Paul F.、他al.「人間の好みからの深層強化学習」 *神経情報処理システムの進歩* 30 (2017). https://arxiv.org/pdf/1706.03741.pdf
- ^Schulman、John、他.「近接ポリシー最適化アルゴリズム」 *arXiv プレプリント arXiv:1707.06347* (2017). https://arxiv.org/pdf/1707.06347.pdf