


新しい透視画像生成 (NVS) は、コンピュータ ビジョンの応用分野です。1998 年のスーパーボウル ゲームで、CMU の RI は、マルチカメラ ステレオ ビジョン (MVS) を備えた NVS をデモンストレーションしました。当時、この技術は米国に移転されました。スポーツテレビ局ですが、結局商業化されず、英国BBC放送が研究開発に投資しましたが、本格的な商業化には至りませんでした。
イメージベース レンダリング (IBR) の分野には、NVS アプリケーションの一分野、つまり深度イメージベース レンダリング (DBIR) があります。また、2010年に大流行した3Dテレビも単眼映像から両眼立体感を得る必要がありましたが、技術の未熟さから結局普及には至りませんでした。当時すでに機械学習をベースとした手法が研究され始めており、例えばYoutubeでは画像検索手法を用いてデプスマップを合成していました。
数年前、私は NVS での深層学習のアプリケーションを紹介しました: 深層学習に基づく新しい透視画像生成方法
最近の段落時間の経過とともに、Neural Radiation Fields (NeRF) はシーンを表現し、フォトリアリスティックな画像を合成するための効果的なパラダイムになりました。その最も直接的なアプリケーションは NVS です。従来の NeRF の主な制限は、トレーニングの視点とは大きく異なる新しい視点で高品質のレンダリングを生成できないことが多いことです。以下は NeRF の一般化方法について説明しますが、ここでは NeRF 原理の基本的な導入は無視されます。ご興味がございましたら、レビュー ペーパーを参照してください:
- # ニューラル レンダリングの進歩の概要
-
Neural Body Rendering: NeRF とその他の手法
#論文 [2] は普遍的な深さを提案していますニューラル ネットワーク MVSNeRF は、クロスシーンの汎化を実現し、近くの 3 つの入力ビューのみから再構成された放射線場を推測します。この方法は、ジオメトリを意識したシーン推論に平面スキャン ボリューム (多視点ステレオ ビジョンで広く使用されている) を利用し、それらを物理ベースのボリューム レンダリングと組み合わせて神経放射線野再構成を行います。
このメソッドは、ディープ MVS の成功を利用して、コスト ボリュームに 3D 畳み込みを適用し、3D 再構成タスク用の一般化可能なニューラル ネットワークをトレーニングします。このようなコスト エンティティに対して深度推論のみを実行する MVS 手法とは異なり、このネットワークはシーンのジオメトリと外観に対して推論を実行し、神経放射フィールドを出力するため、ビュー合成が可能になります。具体的には、3D CNN を使用して、ローカル シーンのジオメトリと外観情報をエンコードするボクセル単位のニューラル特徴から構成されるニューラル シーン エンコード ボリュームが (元のボリュームから) 再構築されます。次に、多層パーセプトロン (MLP) は、三重線形補間されたニューラル フィーチャを使用して、エンコードされたボリューム内の任意の連続した位置のボリューム密度と放射輝度をデコードします。基本的に、エンコード ボリュームは放射線場の局所的なニューラル表現であり、一度推定されると、最終レンダリングのための微分可能なレイ マーチングに (3D CNN を破棄して) 直接使用できます。
既存の MVS 手法と比較して、MVSNeRF は微分可能なニューラル レンダリングを可能にし、3D 監視なしでトレーニングし、推論時間を最適化して品質をさらに向上させます。既存のニューラル レンダリング手法と比較して、MVS のようなアーキテクチャは当然クロスビュー対応推論が可能であり、目に見えないテスト シーンへの一般化に役立ち、ニューラル シーンの再構築とレンダリングの向上につながります。
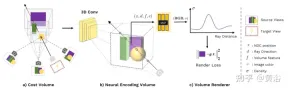
図 1 は、MVSNeRF の概要です: (a) カメラ パラメーターに基づいて、最初に 2D 画像特徴を平面スイープ (平面スイープ) にワープ (ホモグラフィー変換) して、オントロジーを構築します。これは、次のことに基づいています。分散コスト ボリュームは、シーンのジオメトリとビュー関連の明暗効果によって引き起こされる外観の変化を考慮して、異なる入力ビュー間の画像の外観の変化をエンコードします。(b) 次に、3D CNN を使用して、ボクセルごとのニューラル エンコーディング ボリュームを再構築します。ニューラル特徴; 3D CNN は、シーンの外観情報を効果的に推論および伝播し、意味のあるシーンのエンコーディング ボリュームを生成できる 3D UNet です; 注: このエンコーディング ボリュームは教師なし予測であり、エンドツーエンドのトレーニングでボリューム レンダリングを使用して推論されます。元の画像のピクセルは、次のボリューム回帰ステージにマージされ、ダウンサンプリングによって失われた高周波を復元できます (c) MLP を使用して、ボリューム補間の特性をエンコードすることにより、任意の位置でのボリューム密度と RGB 放射輝度を回帰します。プロパティは最終的に微分可能な光線の移動によってレンダリングされます。
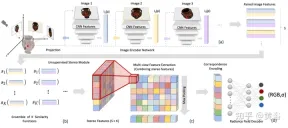
論文[3]は、新しいシーンに一般化でき、テスト中にスパースビューのみを必要とするエンドツーエンドのトレーニング済みニューラルビュー合成手法であるステレオ放射場(SRF)を提案しています。中心となるアイデアは、ステレオ画像内の類似した画像領域を見つけて表面点を推定する、古典的なマルチビュー ステレオ (MVS) 方法にインスピレーションを得たニューラル アーキテクチャです。 10 個のビューをエンコーダー ネットワークに入力し、マルチスケール フィーチャを抽出します。多層パーセプトロン (MLP) は、従来の画像パッチまたは特徴マッチングを置き換え、類似性スコアのアンサンブルを出力します。 SRF では、各 3D ポイントに入力画像内の対応する立体的なエンコードが与えられ、その色と濃度が事前に予測されます。このエンコーディングは、古典的な立体視をシミュレートするペアごとの類似性のアンサンブルを通じて暗黙的に学習されます。
既知のカメラ パラメーターを使用して、N 個の参照画像のセットが与えられると、SRF は 3D ポイントの色と密度を予測します。古典的なマルチビュー ステレオ ビジョン手法と同様に、SRF モデル f を構築します: (1) 点の位置をエンコードするには、それを各参照ビューに投影し、ローカル特徴記述子を構築します。(2)表面および写真整合性では、特徴記述子は互いに一致する必要があります。特徴のマッチングは、すべての参照ビューの特徴をエンコードする学習された関数を使用してシミュレートされます。(3) エンコードは、学習されたデコーダーによってデコードされ、NeRF 表現になります。図 2 は、SRF の概要を示しています: (a) 画像特徴を抽出する; (b) 学習された類似性関数を通じて写真の一貫性を見つけるプロセスをシミュレートして立体特徴行列 (SFM) を取得する; (c) 情報を集約してマルチビューを取得する特徴行列 (MFM); (d) 最大プーリングは、対応関係と色のコンパクトなエンコードを取得し、これをデコードして色とボリューム密度を取得します。
論文 [4] は、複数の画像から推定された 3D 神経シーン表現である DietNeRF を提案しています。これにより、新しいポーズのリアルなレンダリングを促進する補助的な意味上の一貫性の喪失が導入されます。
NeRF で使用できるビューが少数である場合、レンダリングの問題には制約がありません。厳密に正規化しない限り、NeRF は解決策の縮退に悩まされることがよくあります。図 3 に示すように: (A) 均一にサンプリングされたポーズからオブジェクトの 100 個の観測値を取得すると、NeRF は詳細かつ正確な表現を推定し、純粋にマルチビューの一貫性から高品質のビュー合成を可能にします; (B) のみの場合8 つのビュー、トレーニング カメラの近距離フィールドにターゲットを配置すると、同じ NeRF のオーバーフィッティングにより、ターゲットの位置ずれとトレーニング カメラ近くの姿勢の劣化が生じます; (C) 正則化、簡素化、手動で調整および再初期化した場合、 NeRF は収束できますが、細かい詳細は捕捉できません; (D) 類似のオブジェクトに関する事前知識がなければ、単一シーン ビューの合成では、観察されていない領域を合理的に完成させることができません。

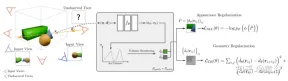
図 4 は、DietNeRF の動作の概略図です。「どの角度から見ても、その物体はその物体である」という原則に基づいて、DietNeRF は、放射線場を監視します。任意の姿勢 (DietNeRF カメラ)、セマンティック一貫性の損失は、ピクセル空間ではなく、高レベルのシーン属性をキャプチャする特徴空間で計算されます。そのため、ビジュアル トランスフォーマーである CLIP を使用して、レンダリングのセマンティック表現が抽出されます。次に、グラウンド トゥルース ビュー表現との類似性を最大化します。
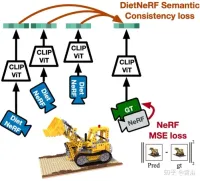
実際、シングルビュー 2D 画像エンコーダによって学習されたシーンのセマンティクスに関する事前知識によって、3D 表現が制約される可能性があります。 DietNeRF は、自然言語の監視の下、Web からマイニングされた数億枚のシングルビュー 2D 写真のコレクションからトレーニングされます。(1) 同じポーズからの特定の入力ビューを正しくレンダリングし、(2) 異なるデータ間で高レベルのセマンティクスを照合します。ランダムなポーズの属性。意味損失関数は、任意のポーズから DietNeRF モデルを監視できます。
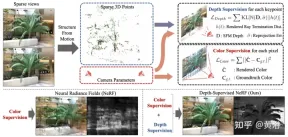
論文[5]は、図5に示すように、学習型放射線場損失を使用し、既製の深度マップ監視を使用するDS-NeRFを提案しています。現在の NeRF パイプラインには既知のカメラ ポーズの画像が必要であるという事実があり、これらの画像は通常、Structure from Motion (SFM) によって推定されます。重要なことに、SFM はトレーニング中に「無料」深度監視として使用されるまばらな 3D ポイントも生成します。つまり、深度の不確実性を含む特定の 3D キーポイントと一致するように光線の終端深度分布を促進する損失を追加します。
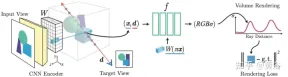
論文[6]は、1つまたは複数の入力画像に基づいて連続的なニューラルシーン表現を予測するための学習フレームワークであるpixelNeRFを提案しています。画像入力で NeRF アーキテクチャを調整する完全な畳み込み手法を導入し、ネットワークを複数のシーンにわたってトレーニングしてシーンの事前知識を学習できるようにし、まばらなビューのセット (少なくとも 1 つ) から作業を進めることができるようにします。フィードフォワード方式、新しいビュー構成。 NeRF のボリューム レンダリング メソッドを活用することで、追加の 3D 監視なしで、pixelNeRF を画像から直接トレーニングできます。
具体的には、pixelNeRF は、まず入力画像から完全畳み込み画像特徴グリッド (特徴グリッド) を計算し、入力画像上で NeRF を調整します。次に、ビュー座標系内の各 3D クエリ空間点 x および関心のあるビュー方向 d について、対応する画像特徴が投影および双一次補間によってサンプリングされます。クエリ仕様は画像特徴とともに NeRF ネットワークに送信され、密度と色が出力されます。ここで空間画像特徴が残差として各層に供給されます。複数の画像が利用可能な場合、入力はまず各カメラ座標系の潜在表現にエンコードされ、色と濃度を予測する前に中間層でマージされます。モデルのトレーニングは、グラウンド トゥルース イメージとボリューム レンダリングされたビューの間の再構成損失に基づいています。
pixelNeRF フレームワークを図 6 に示します。 ターゲット カメラ光線のビュー方向 d、 に沿った 3D クエリ ポイント x について、特徴ボリューム W## から投影と補間 #対応する画像特徴を抽出し、その特徴を空間座標とともに NeRF ネットワーク f に渡します;出力 RGB 値と密度値はボリューム レンダリングに使用され、ターゲット ピクセル値と比較されます; 入力ビューのカメラ座標系の座標 x および d。
イメージベースのレンダリング (IBR) 作業に戻ります。レンダリング用に各シーン関数を最適化するニューラル シーン表現とは異なり、IBRNet は新しいシーンに一般化する一般的なビュー補間関数を学習します。画像の合成には従来のボリューム レンダリングを引き続き使用しており、完全に微分可能であり、監視としてマルチビューのポーズ画像を使用してトレーニングされます。
ライト トランスフォーマーは、光線全体に沿ったこれらの密度特徴を考慮して各サンプルのスカラー密度値を計算し、より大きな空間スケールでの可視性推論を可能にします。これとは別に、カラー ブレンディング モジュールが 2D 特徴とソース ビューの視線ベクトルを使用して、各サンプルのビュー依存の色を導出します。最後に、ボリューム レンダリングによって各レイの最終的なカラー値が計算されます。 図 7 は、IBRNet の概要です。 1) ターゲット ビュー (「?」のマークが付いた画像) をレンダリングするには、まず隣接するソース ビューのセット (たとえば、A と B のマークが付いたビュー) を特定し、画像の特徴; 2) 次に、ターゲット ビューの各光線について、IBRNet (黄色の影付き領域) を使用して、光線に沿ったサンプルの色と密度のセットを計算します。具体的には、サンプルごとに、隣接するソースからの対応する値を集計します。ビュー情報 (画像の色、特徴、視線方向) を使用して色と密度の特徴を生成し、その後、レイ上のすべてのサンプルの密度特徴にレイ トランスフォーマを適用して、密度値を予測します。 3) 最後に、ボリューム レンダリングを使用して、レイに沿ってカラーと密度を蓄積します。再構成された画像の色に対して、エンドツーエンドの L2 損失トレーニングを実行できます。
図 8 は、連続 5D 位置に対する IBRNet のカラー ボリューム密度予測作業を示しています。まず、すべてのソース ビューから抽出された 2D 画像特徴が PointNet と同様の MLP に入力され、ローカルおよびグローバル情報が集約されてマルチ知覚特徴を表示し、重みをプールし、重みを使用して特徴を集中させ、マルチビュー可視性推論を実行し、密度特徴を取得します。単一の 5D サンプルの密度 σ を直接予測する代わりに、レイ トランスフォーマー モジュールを使用してすべてのサンプル情報を収集します。光線に沿って; 光線変換モジュールは、光線上のすべてのサンプルの密度特徴を取得し、その密度を予測します; 光線変換モジュールは、より長い範囲にわたる幾何学的な推論を可能にし、密度予測を改善します; 色予測では、多視点の知覚機能が、ソースを基準としたクエリ レイ ビューの視線方向は、一連の調和重みを予測するために小さなネットワークの入力に接続されます 出力色 c は、ソース ビューのイメージ カラーの加重平均です。
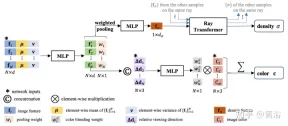
ここにもう 1 つ追加します。絶対的な表示方向を使用する NeRF とは異なり、IBRNet はソース ビューに対する相対的な表示方向、つまり d## を考慮します。 # と di、 Δd=d-di の違い。 Δd の方が小さいということは、通常、ターゲット ビューの色がソース ビュー i の対応する色に似ている可能性が高く、またその逆も同様であることを意味します。
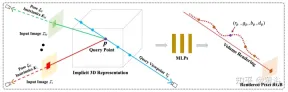
論文 [8] で提案されている一般放射線場 (GRF) は、2D 観測からの 3D ターゲットとシーンを特徴付けてレンダリングするだけです。このネットワークは、3D ジオメトリを普遍的な放射線フィールドとしてモデル化し、一連の 2D 画像、カメラの外部ポーズ、および内部パラメータを入力として受け取り、3D 空間内の各点の内部表現を構築して、任意の場所から見た対応する外観とジオメトリをレンダリングします。位置。重要なのは、2D 画像の各ピクセルの局所的な特徴を学習し、これらの特徴を 3D ポイントに投影することで、多用途でリッチなポイント表現を生成することです。さらに、アテンション メカニズムが統合され、複数の 2D ビューのピクセル特徴を集約して、視覚的なオクルージョンの問題を暗黙的に考慮します。 図 9 は GRF の概略図です。GRF は、各 3D 点p を MM 入力画像のそれぞれに投影し、それぞれを収集します。ピクセルの特徴が集約されます。これは MLP に供給され、p の色と体積密度が推測されます。
論文 [10] の洞察は、3D 表面の目に見える投影の固有の外観は一貫している必要があるということです。したがって、目に見えないビューを目に見えるビューでトレーニングできるようにするランダム レイ キャスティング戦略を提案します。さらに、外挿ビューのレンダリング品質は、観測光線の視線に沿った事前計算された光線アトラスに基づいてさらに向上させることができます。主な制限は、RapNeRF がマルチビューの一貫性を利用して、強いビュー相関の影響を排除することです。
ランダム レイ キャスティング戦略の直感的な説明を図 11 に示します。左の図では、3 次元点 v を観察する 2 本のレイがあり、r1 はトレーニング スペースに位置し、r2 は遠くにあります。トレーニング レイから離れる; NeRF への分布ドリフトとマッピング関数を考慮する Fc:(r,f)→c その r2 に沿ったサンプル放射輝度が不正確になる; ピクセル カラーと比較した r2 に沿った放射輝度累積演算 詳細v の逆カラー推定値が得られる可能性があります。中央の画像は、NeRF 式に従って関係するピクセル レイを計算し、トレーニング レイ プールから同じ 3D ポイントに当たる仮想レイに対応するレイを見つける単純な仮想ビューの再投影です。実際には非常に不便です。右側の図では、特定のトレーニング レイ (o から投影され、v を通過する) について、ランダム レイ キャスティング (RRC) 戦略により、円錐 A 仮想内に目に見えない光線がランダムに生成されます。次に、レイ (o' から v を通って投影) には、トレーニング レイに基づいてオンラインで疑似ラベルが割り当てられます。RRC は、目に見えないレイを可視レイでトレーニングすることをサポートします。
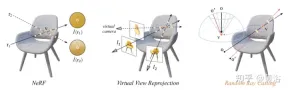
#RRC 戦略を使用すると、ランダムに生成された仮想レイにオンラインで擬似ラベルを割り当てることができます。具体的には、トレーニング画像 I 内の注目ピクセルについて、観察方向 d、カメラ原点 o、およびワールド座標系での深度が与えられます。値は次のとおりです。 tz 、および光線 r=o td 。ここで、 tz は、事前トレーニングされた NeRF を使用して事前計算され、保存されます。
v=o tzd が、r がヒットした最も近い 3D 表面点を表すとします。トレーニング フェーズでは、v が新しい原点とみなされ、円錐内の v から光線がランダムにキャストされ、その中心線はベクトル になります。 vo ̄=− tzd.これは、 vo ̄ を球空間に変換し、いくつかのランダムな摂動 Δφ と Δθ を φ と θ に導入することで簡単に実現できます。ここで、φ と θ はそれぞれ vo ̄ の方位角と仰角です。 Δφ と Δθ は、事前定義された間隔 [-η, η] から均一にサンプリングされます。これから、 θ′=θ Δθ と φ′=φ Δφ が得られます。したがって、仮想光線は、v も通過するランダムな原点 o' からキャストできます。このようにして、色の強度の真の値 I(r) を I~(r') の擬似トークンとみなすことができます。
Basic NeRF は、「指向性エンベディング」を利用してシーンの照明効果をエンコードします。シーン フィッティング プロセスにより、トレーニングされた色予測 MLP は視線方向に大きく依存します。新しいビューの補間では、これは問題になりません。ただし、トレーニングとテストの光分布の間にはいくつかの違いがあるため、これは新しいビューの外挿には適さない可能性があります。素朴なアイデアは、単に方向性埋め込み (「NeRF w/o dir」として示される) を削除することです。ただし、これにより、予期しない波紋や滑らかでない色などの画像アーチファクトが生じることがよくあります。これは、光の見る方向も表面の滑らかさに関係している可能性があることを意味します。
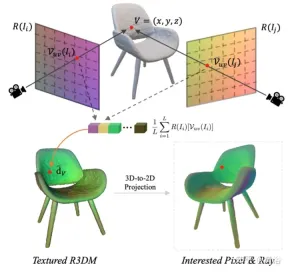
論文 [10] はレイ アトラスを計算し、補間ビューの問題を伴うことなく、外挿ビューのレンダリング品質をさらに向上できることを示しています。レイ アトラスはテクスチャ アトラスに似ていますが、各 3D 頂点のグローバル レイ方向を保存します。
特に、各画像 (例: 画像 I) について、その光線の視線方向がすべての空間位置について取得され、それによって光線マップが生成されます。事前トレーニングされた NeRF から大まかな 3D メッシュ (R3DM) を抽出し、光線の方向を 3D 頂点にマッピングします。頂点 V=(x,y,z) を例にとると、そのグローバルな光の方向 d ̄V は
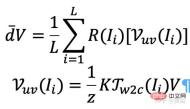
ここで、K はカメラの内部パラメータ、 Γw2c(Ii) は画像のカメラワールド座標系変換行列 Ii, Vuv(Ii) は画像 Ii 内の頂点 V の 2 次元投影位置であり、L は頂点 V 再構築におけるトレーニング画像の数です。任意のカメラ ポーズの各ピクセルについて、ライト マップ テクスチャ (R3DM) を使用して 3D メッシュを 2D に投影すると、 d ̄ より前のグローバル レイを取得できます。
図 12 は、ライト アトラスの概略図です。つまり、トレーニング ライトからライト アトラスをキャプチャし、それを使用して椅子の粗い 3D メッシュ (R3DM) にテクスチャを追加します。 R(Ii) はトレーニング画像 Ii のライトマップです。
d ̄ を使用して、その Fc # を置き換えます。 ##d で、色予測を実行します。この代替メカニズムが発生する確率は 0.5 です。テスト段階では、サンプル x の放射輝度 c はおよそ次のとおりです。
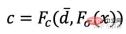 ここで、マッピング関数
ここで、マッピング関数
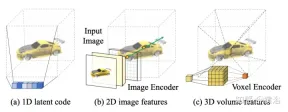
Fσ( x):x→(σ,f)。 オリジナルの NeRF は、シーン間の共有情報を探索する必要がなく、各シーンの表現を個別に最適化しますが、時間がかかります。この問題を解決するために、研究者らは PixelNeRF や MVSNeRF などのモデルを提案しました。これらのモデルは複数の観察者のビューを条件付き入力として受け取り、普遍的な神経放射場を学習します。分割統治設計原則に従い、単一画像用の CNN 特徴抽出器と NeRF ネットワークとしての MLP という 2 つの独立したコンポーネントで構成されます。これらのモデルでは、単一ビューのステレオ ビジョンの場合、CNN が画像を特徴グリッドにマッピングし、MLP がクエリ 5D 座標とそれに対応する CNN 特徴を単一のボリューム密度とビュー依存の RGB カラーにマッピングします。マルチビュー ステレオ ビジョンの場合、CNN と MLP は任意の数の入力ビューを処理できないため、各ビューの座標系の座標と対応する特徴が最初に独立して処理され、各ビューの画像条件付き中間表現が取得されます。次に、補助プーリング ベースのモデルを使用して、これらの NeRF ネットワーク内のビュー中間表現を集約します。 3D 理解タスクでは、複数のビューがシーンに関する追加情報を提供します。
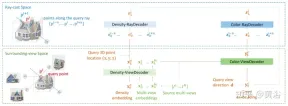
論文[11]は、神経放射線フィールドシーンを特徴付けるエンコーダ/デコーダTransformerフレームワークTransNeRFを提案しています。 TransNeRF は、単一の Transformer ベースの NeRF アテンション メカニズムを通じて、複数のビュー間の深い関係を探索し、マルチビュー情報を座標ベースのシーン表現に集約できます。さらに、TransNeRF は、レイキャスト空間と周辺ビュー空間の対応する情報を考慮して、シーン内の形状と外観の局所的な幾何学的一貫性を学習します。
図 13 に示すように、TransNeRF は、照会された 3D 点をターゲット表示光線内にレンダリングします。TransNeRF には次のものが含まれます: 1) 周辺空間では、密度ビュー デコーダ (Density-ViewDecoder) と Color-ViewDecoder ( Color-ViewDecoder) は、ソース ビューとクエリ空間情報
((x,y,z),d)を 3D クエリ ポイントの潜在密度と色表現に融合します。 2) レイ キャスティング空間では、密度レイ デコーダ (Density-RayDecoder) とカラー レイ デコーダ (Color-RayDecoder) は、ターゲット ビュー レイに沿った隣接点を考慮することでクエリの密度と色の表現を強化するために使用されます。最後に、ターゲット視線上のクエリ 3D 点の体積密度と方向色が TransNeRF から取得されます。
重要な洞察は、各入力ピクセルの深さを明示的に特徴付けることで、微分可能な点群レンダラーを使用して各入力ビューに順方向ワーピングを適用できるということです。これにより、NeRF のような手法の高価な大量サンプリングが回避され、高画質を維持しながらリアルタイム速度が実現されます。
SynSin[1] は、単一画像の新しいビュー合成 (NVS) に微分可能な点群レンダラーを使用します。論文 [12] では、SynSin を複数の入力に拡張し、マルチビュー情報を融合する効果的な方法を検討しています。
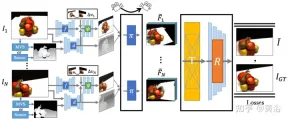
FWD は、各入力ビューの深度を推定し、潜在フィーチャの点群を構築し、点群レンダラーを通じて新しいビューを合成します。異なる視点からの観測間の不一致の問題を軽減するために、視点関連の結果をモデル化するために視点関連の特徴 MLP が点群に導入されます。別の Transformer ベースの融合モジュールは、複数の入力からの機能を効果的に組み合わせます。欠落した領域を修復し、構成の品質をさらに向上させることができる調整モジュール。モデル全体がエンドツーエンドでトレーニングされ、測光損失と知覚損失を最小限に抑え、深度を学習し、合成品質を最適化する機能を備えています。
図 14 は、FWD の概要です。一連のスパース画像が与えられた場合、特徴ネットワーク f (BigGAN アーキテクチャに基づく) を使用し、ビュー関連の特徴 MLP ψ を使用します。ネットワーク d は、各画像 Ii Pi の点群 (ビューの幾何学的情報および意味情報を含む) を構築します。画像を除きます。 d MVS (PatchmatchNet に基づく) 推定深度またはセンサー深度を入力として取得し、画像特徴 Fi および相対的なビューの変化に基づいて洗練された深度を回帰します Δv (正規化ビュー方向 vi および vt、つまり、入力ビュー i とターゲット ビュー の点から中心までの方向に基づくt)、微分可能な点群レンダラー ## を使用した fand ψ回帰ピクセル単位の特徴 Fi' による#π (スプラッティング) は点群を投影し、ターゲット ビュー (つまり F~i ) にレンダリングします。レンダリング前にビュー点群を直接集約する代わりに、トランスフォーマー T を融合します。任意の数の入力からレンダリング結果を取得し、リファインメント モジュール R を適用します。デコードにより、最終的な画像結果が生成されます。つまり、入力の目に見えない領域が意味論的および幾何学的に修復され、不正確な深度によって引き起こされる局所的なエラーが修正され、改善されます。特徴マップに含まれるセマンティクスに基づく知覚品質。モデルのトレーニングでは測光損失とコンテンツ損失が使用されます。
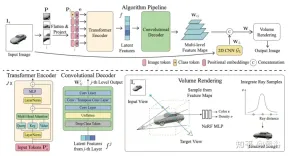
P; 各画像パッチは平坦化され、画像トークン (トークン) P1 に線形投影されます。トランスフォーマー エンコーダーは画像トークンと学習可能な位置埋め込み e を入力として受け取り、グローバル情報を潜在特徴のセット f; 次に、畳み込みデコーダーを使用して潜在特徴をマルチレベル特徴マップにデコードします WG; グローバル特徴に加えて、別の 2D CNN モデルを使用して、ローカル画像特徴を取得する; 最後に、NeRF MLP モデル サンプル特徴をボリューム レンダリングに使用します。
論文 [14] は、NeRF と MVS の利点を組み合わせ、ニューラル 3D 点群と関連するニューラル機能を使用して放射線野をモデル化する Point-NeRF を提案しています。 Point-NeRF は、レイ マーチング ベースのレンダリング パイプラインでシーン サーフェス近くのニューラル ポイント フィーチャを集約することによって効果的にレンダリングできます。さらに、事前トレーニングされたディープ ネットワークからの直接推論により、Point-NeRF が初期化されてニューラル点群が生成されます。点群は NeRF の視覚的品質を超えて 30 倍高速にトレーニングできるように微調整できます。 Point-NeRF は他の 3D 再構成手法と組み合わせて、再構成された点群データを最適化するために、成長および枝刈りメカニズム、つまり高体積密度領域で成長し、低体積密度領域で枝刈りを採用します。
Point-NeRF の概要を図 17 に示します。 (a) マルチビュー画像から、Point-NeRF はコストボリュームベースの 3D CNN と入力画像からの 2D CNN を使用して各ビューの深度を生成します。 2D 特徴を抽出します。深度マップを集約した後、各点に空間位置、信頼性、非投影画像特徴がある点ベースの放射線場を取得します。(b) 新しいビューを合成するには、微分可能な光線移動を実行し、計算のみを行います。ニューラル ポイント クラウド付近のシェーディング。各シェーディング位置で、Point-NeRF は K 個のニューラル ポイントの近傍から特徴を集約し、放射輝度とボリューム密度を計算し、放射輝度とボリューム密度の累積を合計します。プロセス全体はエンドツーエンドでトレーニング可能であり、レンダリング損失を通じてポイントベースの放射線フィールドを最適化できます。

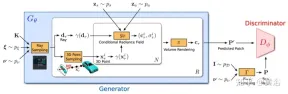
GRAF (Generative Radiance Field)[18] は、マルチスケールに基づく識別器を導入することで実現される放射線場の生成モデルです。モデルのトレーニングには、未知のポーズのカメラで撮影された 2D 画像のみが必要ですが、高解像度の 3D 対応画像を合成できます。
目標は、未処理の画像をトレーニングして新しいシーンを合成するモデルを学習することです。より具体的には、敵対的フレームワークを利用して放射線場の生成モデル (GRAF) をトレーニングします。
図 18 は GRAF モデルの概要を示しています。ジェネレーターはカメラ マトリックス K、カメラ ポーズ ξ、2D サンプリング モード ## を採用しています。 #ν と形状/外観コードを入力として使用し、画像パッチ P' を予測します。識別器はパッチ を合成します。 P ' は、推論中に実画像 I; から抽出されたパッチ P と比較されます。画像ピクセルごとにカラー値を予測します。ただし、この操作はトレーニング時に負荷が高すぎるため、サイズ K×K ピクセルの固定パッチがランダムなスケーリングと回転で予測されます。 、放射線フィールド全体に対して、勾配が提供されます。
xx と視線方向 をマッピングします。 d RGB カラー値 c と体積密度 σ:
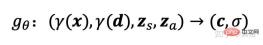
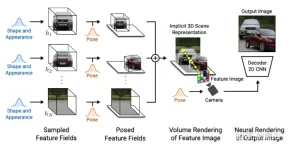
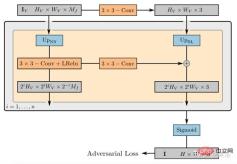
gθ は 2 つの追加の潜在コードに依存します。形状コード zs はターゲットの形状を決定し、外観コード za は外観を決定します。ここで gθ は条件付き放射場と呼ばれ、その構造は図 19 に示されています。 まず、## の位置コードと形状コードに基づいて形状コード # が計算されます。 #x ##h; 密度ヘッド σθこのエンコーディングを体積密度σに変換し、3D 位置での色を予測します x c、h と d の位置と見かけのコードをエンコードします。 za が連結され、結果のベクトルがカラー ヘッダー cθ に渡されます。σ は視点 d と外観とは独立して計算されます。コードにより、マルチビューの一貫性が促進され、同時に形状と外観が分離されます。これにより、ネットワークが 2 つの潜在コードを使用して形状と外観を別々にモデル化することが促進され、推論中にそれらを別々に処理できるようになります。 識別器は畳み込みニューラル ネットワークとして実装され、予測パッチ P' とスレーブ データ分布 を組み合わせます。 pD 実画像 I から抽出したパッチ P を比較します。実際のイメージ I から K×K パッチを抽出するには、まず、上記の抽出に使用したのと同じディストリビューションから pv を抽出します。ジェネレータ パッチ v=(u,s) を抽出し、双線形補間を通じて 2D 画像座標 P(u,s) で I をクエリし、実際のパッチ をサンプリングします。 P。 Γ(I,v) を使用して、この双線形サンプリング操作を表します。 実験の結果、たとえこれらのパッチが異なるスケールのランダムな位置でサンプリングされたとしても、重みを共有する単一の識別子ですべてのパッチに十分であることがわかりました。注: スケールはパッチの受容野を決定します。したがって、トレーニングを容易にするために、より大きな受容野パッチから始めて全体的なコンテキストをキャプチャします。次に、より小さい受容野を持つパッチが段階的にサンプリングされ、局所的な詳細が調整されます。 GIRAFFE[19] は、生の非構造化画像でトレーニングするときに、制御可能かつ現実的な方法でシーンを生成するために使用されます。主な貢献は 2 つの側面にあります。 1) 結合された 3D シーン表現が生成モデルに直接組み込まれ、より制御可能な画像合成が実現されます。 2) この明示的な 3D 表現をニューラル レンダリング パイプラインと組み合わせて、より高速な推論とより現実的な画像を可能にします。このため、図 20 に示すように、シーン表現が 結合されてニューラル特徴フィールド が生成されます。ランダムにサンプリングされたカメラの場合、シーンの特徴画像は別の特徴フィールドに基づいてボリューム レンダリングされます。 ; 2D ニューラル レンダリング ネットワークは、特徴画像が RGB 画像に変換されます。トレーニング中には元の画像のみが使用され、テスト中にカメラのポーズ、ターゲットのポーズ、形状や外観などの画像形成プロセスを制御できます。さらに、モデルはトレーニング データの範囲を超えて拡張され、たとえば、トレーニング画像よりも多くのオブジェクトを含むシーンを合成できます。 シーン ボリュームを比較的低解像度のフィーチャ イメージにレンダリングすると、時間と計算が節約されます。ニューラル レンダラーはこれらの特徴画像を処理し、最終的なレンダリングを出力します。このようにして、この方法は高品質の画像を取得し、実際のシーンに合わせて拡大縮小することができます。この方法を生の非構造化イメージのコレクションでトレーニングすると、単一および複数オブジェクトのシーンの制御可能な画像合成が可能になります。 シーンを結合するときは、2 つの状況を考慮する必要があります。N が固定され、N が変化します (最後の 1 つは背景です)。実際には、背景はターゲットと同じ表現を使用して表現されますが、スケールと移動パラメータがシーン全体にわたって固定され、シーン空間の原点を中心とする点が異なります。 2D レンダリング オペレーターの重みは、特徴画像を最終合成画像にマッピングします。これは、リーキー ReLU アクティベーションを備えた 2D CNN としてパラメーター化でき、3x 3 コンボリューションおよび最近傍アップサンプリングと組み合わせて空間解像度を向上できます。レート。最後の層はシグモイド演算を適用して、最終的な画像予測を取得します。その概略図を図 21 に示します。 識別子も、リーキー ReLU 活性化を備えた CNN です。 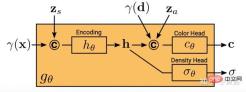
以上が画像生成に関する新しい視点: NeRF ベースの一般化手法についての議論の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 AIインデックス2025を読む:AIはあなたの友人、敵、または副操縦士ですか?Apr 11, 2025 pm 12:13 PM
AIインデックス2025を読む:AIはあなたの友人、敵、または副操縦士ですか?Apr 11, 2025 pm 12:13 PMスタンフォード大学ヒト指向の人工知能研究所によってリリースされた2025年の人工知能インデックスレポートは、進行中の人工知能革命の良い概要を提供します。 4つの単純な概念で解釈しましょう:認知(何が起こっているのかを理解する)、感謝(利益を見る)、受け入れ(顔の課題)、責任(責任を見つける)。 認知:人工知能はどこにでもあり、急速に発展しています 私たちは、人工知能がどれほど速く発展し、広がっているかを強く認識する必要があります。人工知能システムは絶えず改善されており、数学と複雑な思考テストで優れた結果を達成しており、わずか1年前にこれらのテストで惨めに失敗しました。 2023年以来、複雑なコーディングの問題や大学院レベルの科学的問題を解決することを想像してみてください
 Meta Llama 3.2を始めましょう - 分析VidhyaApr 11, 2025 pm 12:04 PM
Meta Llama 3.2を始めましょう - 分析VidhyaApr 11, 2025 pm 12:04 PMメタのラマ3.2:マルチモーダルとモバイルAIの前進 メタは最近、ラマ3.2を発表しました。これは、モバイルデバイス向けに最適化された強力なビジョン機能と軽量テキストモデルを特徴とするAIの大幅な進歩です。 成功に基づいてo
 AVバイト:Meta' s llama 3.2、GoogleのGemini 1.5などApr 11, 2025 pm 12:01 PM
AVバイト:Meta' s llama 3.2、GoogleのGemini 1.5などApr 11, 2025 pm 12:01 PM今週のAIの風景:進歩、倫理的考慮、規制の議論の旋風。 Openai、Google、Meta、Microsoftのような主要なプレーヤーは、画期的な新しいモデルからLEの重要な変化まで、アップデートの急流を解き放ちました
 マシンと話すための人的費用:チャットボットは本当に気にすることができますか?Apr 11, 2025 pm 12:00 PM
マシンと話すための人的費用:チャットボットは本当に気にすることができますか?Apr 11, 2025 pm 12:00 PMつながりの慰めの幻想:私たちはAIとの関係において本当に繁栄していますか? この質問は、MIT Media Labの「AI(AHA)で人間を進める」シンポジウムの楽観的なトーンに挑戦しました。イベントではCondedgを紹介している間
 PythonのScipy Libraryの理解Apr 11, 2025 am 11:57 AM
PythonのScipy Libraryの理解Apr 11, 2025 am 11:57 AM導入 あなたが科学者またはエンジニアで複雑な問題に取り組んでいると想像してください - 微分方程式、最適化の課題、またはフーリエ分析。 Pythonの使いやすさとグラフィックスの機能は魅力的ですが、これらのタスクは強力なツールを必要とします
 ラマ3.2を実行する3つの方法-Analytics VidhyaApr 11, 2025 am 11:56 AM
ラマ3.2を実行する3つの方法-Analytics VidhyaApr 11, 2025 am 11:56 AMメタのラマ3.2:マルチモーダルAIパワーハウス Metaの最新のマルチモーダルモデルであるLlama 3.2は、AIの大幅な進歩を表しており、言語理解の向上、精度の向上、および優れたテキスト生成機能を誇っています。 その能力t
 Dagsterでデータ品質チェックを自動化しますApr 11, 2025 am 11:44 AM
Dagsterでデータ品質チェックを自動化しますApr 11, 2025 am 11:44 AMデータ品質保証:ダグスターと大きな期待でチェックを自動化する データ駆動型のビジネスにとって、高いデータ品質を維持することが重要です。 データの量とソースが増加するにつれて、手動の品質管理は非効率的でエラーが発生しやすくなります。
 メインフレームはAI時代に役割を果たしていますか?Apr 11, 2025 am 11:42 AM
メインフレームはAI時代に役割を果たしていますか?Apr 11, 2025 am 11:42 AMMainFrames:AI革命のUnsung Heroes サーバーは汎用アプリケーションで優れており、複数のクライアントの処理を行いますが、メインフレームは大量のミッションクリティカルなタスク用に構築されています。 これらの強力なシステムは、頻繁にヘビルで見られます


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

WebStorm Mac版
便利なJavaScript開発ツール

