



1. 線形回帰の前提とは何ですか?
線形回帰には 4 つの仮定があります。
- 線形: 独立変数 (x) と従属変数 (y) の間には線形関係がある必要があります。 x 値も同じ方向に y 値を変更する必要があります。
- 独立性: 特徴は互いに独立している必要があります。これは、多重共線性が最小限であることを意味します。
- 正規性: 残差は正規分布する必要があります。
- 等分散性: 回帰直線の周囲のデータ ポイントの分散は、すべての値で同じである必要があります。
2.残差とは何ですか?回帰モデルの評価に残差はどのように使用されますか?
残差とは、予測値と観測値の間の誤差を指します。回帰直線からのデータ ポイントの距離を測定します。観測値から予測値を差し引くことで計算されます。
残差プロットは回帰モデルを評価する良い方法です。これは、縦軸にすべての残差、x 軸に特徴を示すグラフです。データ ポイントがパターンのない直線上にランダムに散在している場合は、線形回帰モデルがデータによく適合します。そうでない場合は、非線形モデルを使用する必要があります。

3. 線形回帰モデルと非線形回帰モデルを区別するにはどうすればよいですか?
どちらも回帰問題の一種です。 2 つの違いは、トレーニングに使用されるデータです。
線形回帰モデルは、フィーチャとラベルの間に線形関係があることを前提としています。つまり、すべてのデータ ポイントを取得して線形 (直線) にプロットすると、データが適合するはずです。
非線形回帰モデルは、変数間に線形関係がないことを前提としています。非線形 (曲線) 線はデータを分離し、正しくフィットさせる必要があります。
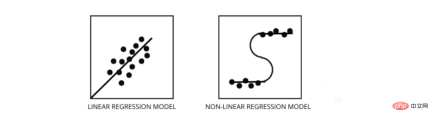
データが線形か非線形かを確認するための 3 つの最良の方法 -
- 残差プロット
- 散布点図
- データが線形であると仮定すると、線形モデルがトレーニングされ、精度によって評価されます。
4.多重共線性とは何ですか?それはモデルのパフォーマンスにどのような影響を与えますか?
多重共線性は、特定の特徴が相互に高度に相関している場合に発生します。相関とは、ある変数が別の変数の変化によってどのような影響を受けるかを示す尺度を指します。
特徴 a の増加が特徴 b の増加につながる場合、2 つの特徴には正の相関があります。 a の増加により特徴 b が減少する場合、2 つの特徴は負の相関関係にあります。トレーニング データに相関性の高い 2 つの変数があると、モデルがデータ内のパターンを見つけることができないため多重共線性が生じ、モデルのパフォーマンスが低下します。したがって、モデルをトレーニングする前に、まず多重共線性の除去を試みる必要があります。
5. 外れ値は線形回帰モデルのパフォーマンスにどのような影響を与えますか?
外れ値は、値がデータ ポイントの平均範囲と異なるデータ ポイントです。つまり、これらの点はデータと異なっているか、第 3 の基準から外れています。
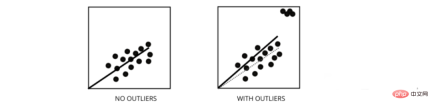
# 線形回帰モデルは、残差を減らす最適な直線を見つけようとします。データに外れ値が含まれている場合、最適な線は外れ値に向かって少しシフトし、エラー率が増加し、その結果、モデルの MSE が非常に高くなります。
6.MSE と MAE の違いは何ですか?
MSE は平均二乗誤差の略で、実際の値と予測値の二乗差です。 MAE は目標値と予測値の差の絶対値です。
MSE は大きなミスを罰しますが、MAE は罰しません。 MSE と MAE の両方の値が減少するにつれて、モデルはより良い適合線になる傾向があります。
7. L1 および L2 正則化とは何ですか?いつ使用する必要がありますか?
機械学習における主な目標は、トレーニング データとテスト データでより優れたパフォーマンスを発揮できる一般的なモデルを作成することですが、データが非常に少ない場合、基本的な線形回帰モデルは過剰適合する傾向があります。 l1 と l2 の正規化を使用します。
L1 正則化またはラッソ回帰は、コスト関数内にペナルティ項として傾きの絶対値を追加することで機能します。しきい値未満の傾き値を持つすべてのデータ ポイントを削除することで、外れ値を削除するのに役立ちます。
L2 正則化またはリッジ回帰では、係数サイズの 2 乗に等しいペナルティ項が追加されます。傾き値が高いフィーチャにペナルティを与えます。
l1 と l2 は、トレーニング データが小さく、分散が高く、予測された特徴が観測値より大きく、データに多重共線性が存在する場合に役立ちます。
8.不均一分散性とは何を意味しますか?
これは、最適な直線の周囲のデータ ポイントの分散が範囲内で異なる状況を指します。その結果、残留物が不均一に分散します。データ内にそれが存在する場合、モデルは無効な出力を予測する傾向があります。不均一分散性をテストする最良の方法の 1 つは、残差をプロットすることです。
データ内の不均一分散の最大の原因の 1 つは、範囲特徴間の大きな違いです。たとえば、1 から 100000 までの列がある場合、値を 10% 増やしても、低い値は変わりませんが、高い値では非常に大きな差が生じるため、大きな分散の差が生じます。 。
9. 分散インフレ係数の役割は何ですか?
分散インフレ係数 (vif) は、他の独立変数を使用して独立変数をどの程度正確に予測できるかを調べるために使用されます。
機能 v1、v2、v3、v4、v5、v6 を含むデータの例を見てみましょう。ここで、v1 の vif を計算するには、これを予測子変数とみなして、他のすべての予測子変数を使用して予測を試みます。
VIF の値が小さい場合は、データから変数を削除することをお勧めします。値が小さいほど変数間の相関が高いことを示すためです。
10. ステップワイズ回帰はどのように機能しますか?
ステップワイズ回帰は、仮説検定を利用して予測子変数を削除または追加することによって回帰モデルを作成する方法です。各独立変数の重要性を反復的にテストし、各反復後にいくつかの特徴を削除または追加することで、従属変数を予測します。これは n 回実行され、観測値と予測値の間の誤差が最小になるように従属変数を予測するパラメーターの最適な組み合わせを見つけようとします。
大量のデータを非常に効率的に管理し、高次元の問題を解決できます。
11. MSE と MAE に加えて、他に重要な回帰指標はありますか?

これらの指標を導入するために回帰問題を使用します。入力は職歴、出力は給与です。以下のグラフは、給与を予測するために引かれた線形回帰直線を示しています。

1. 平均絶対誤差 (MAE):

平均絶対誤差 (MAE) は最も単純な回帰測定です。 。各実際の値と予測値の差を加算し、それを観測値の数で割ります。回帰モデルが優れたモデルであるとみなされるためには、MAE が可能な限り小さい必要があります。
MAE の利点は次のとおりです。
シンプルで理解しやすい。結果の単位は出力と同じになります。例: 出力列の単位が LPA の場合、MAE が 1.2 であれば、結果を 1.2LPA または -1.2LPA として解釈できます。MAE は外れ値に対して比較的安定しています (他の回帰指標と比較すると、MAE は外れ値の影響は小さくなります)。
MAE の欠点は次のとおりです。
MAE はモジュラー関数を使用しますが、モジュラー関数はすべての点で微分可能ではないため、多くの場合損失関数として使用できません。
2. 平均二乗誤差 (MSE):

MSE は、各実際の値と予測値の差を取得し、その差を 2 乗して加算し、最後に観測値の数で割ります。回帰モデルが優れたモデルであるとみなされるためには、MSE が可能な限り小さい必要があります。
MSE の利点: 二乗関数はすべての点で微分可能であるため、損失関数として使用できます。
MSE の欠点: MSE は二乗関数を使用するため、結果の単位は出力の二乗になります。したがって、結果を解釈するのは困難です。二乗関数を使用するため、データに外れ値がある場合、差も二乗されるため、外れ値に対して MSE は安定しません。
3. 二乗平均平方根誤差 (RMSE):

二乗平均平方根誤差 (RMSE) は、各実際の値と予測値の差を計算します。次に、差を二乗して加算し、最後に観測値の数で割ります。次に、結果の平方根を求めます。したがって、RMSE は MSE の平方根です。回帰モデルが優れたモデルであるとみなされるためには、RMSE が可能な限り小さい必要があります。
RMSE は MSE の問題を解決します。単位は平方根を取るため出力の単位と同じになりますが、それでも外れ値に対して安定性が低くなります。
上記の指標は、解決している問題のコンテキストによって異なります。実際の問題を理解せずに、MAE、MSE、RMSE の値だけを見てモデルの品質を判断することはできません。
4、R2 スコア:

入力データはありませんが、この会社で彼がどれくらいの給与を得ることができるかを知りたい場合は、最善の方法は、全従業員の給与の平均を与えることです。

#R2 スコアは 0 から 1 までの値を示し、あらゆるコンテキストに対して解釈できます。それはフィット感の良さとして理解できます。
SSR は回帰直線の二乗誤差の合計、SSM は移動平均の二乗誤差の合計です。回帰直線を平均線と比較します。

- #R2 スコアが 0 の場合、モデルの結果が平均と同じであるため、モデルを改善する必要があることを意味します。
- R2 スコアが 1 の場合、方程式の右側は 0 になります。これは、モデルがエラーなく各データ ポイントに適合する場合にのみ発生します。
- R2 スコアが負の場合は、方程式の右側が 1 より大きいことを意味します。これは、SSR > SSM の場合に発生する可能性があります。これは、モデルが平均より最悪であることを意味します。つまり、モデルが平均を予測するよりも悪いということです。
モデルの R2 スコアが 0.8 の場合、これは次のように言えます。モデルが出力分散の 80% を説明できること。つまり、賃金変動の80%はインプット(勤務年数)で説明できるが、残りの20%は不明ということになる。
モデルに勤務年数と面接スコアという 2 つの特徴がある場合、モデルはこれら 2 つの入力特徴を使用して給与の変化の 80% を説明できます。
R2 の欠点:
入力特徴の数が増加すると、R2 はそれに応じて増加するか、変化しない傾向がありますが、入力特徴がモデルにとって役に立たない場合でも、減少することはありません。重要です (例: インタビュー当日の気温を例に追加すると、気温が出力にとって重要でない場合でも R2 は減少しません)。
5. 調整された R2 スコア:
上の式では、R2 は R2、n は観測値 (行) の数、p は独立した特徴の数です。調整されたR2はR2の問題を解決します。
賃金を予測するために気温を追加するなど、モデルにとってそれほど重要ではない機能を追加する場合....

給与を予測するために面接スコアを追加するなど、モデルに重要な機能を追加する場合...

上記は回帰問題 回帰問題を解く上での重要な知識と各種重要指標の紹介とそのメリット・デメリットについてご紹介しますので、ご参考になれば幸いです。
以上が機械学習回帰モデルに関連する重要な知識ポイントのまとめの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 AIインデックス2025を読む:AIはあなたの友人、敵、または副操縦士ですか?Apr 11, 2025 pm 12:13 PM
AIインデックス2025を読む:AIはあなたの友人、敵、または副操縦士ですか?Apr 11, 2025 pm 12:13 PMスタンフォード大学ヒト指向の人工知能研究所によってリリースされた2025年の人工知能インデックスレポートは、進行中の人工知能革命の良い概要を提供します。 4つの単純な概念で解釈しましょう:認知(何が起こっているのかを理解する)、感謝(利益を見る)、受け入れ(顔の課題)、責任(責任を見つける)。 認知:人工知能はどこにでもあり、急速に発展しています 私たちは、人工知能がどれほど速く発展し、広がっているかを強く認識する必要があります。人工知能システムは絶えず改善されており、数学と複雑な思考テストで優れた結果を達成しており、わずか1年前にこれらのテストで惨めに失敗しました。 2023年以来、複雑なコーディングの問題や大学院レベルの科学的問題を解決することを想像してみてください
 Meta Llama 3.2を始めましょう - 分析VidhyaApr 11, 2025 pm 12:04 PM
Meta Llama 3.2を始めましょう - 分析VidhyaApr 11, 2025 pm 12:04 PMメタのラマ3.2:マルチモーダルとモバイルAIの前進 メタは最近、ラマ3.2を発表しました。これは、モバイルデバイス向けに最適化された強力なビジョン機能と軽量テキストモデルを特徴とするAIの大幅な進歩です。 成功に基づいてo
 AVバイト:Meta' s llama 3.2、GoogleのGemini 1.5などApr 11, 2025 pm 12:01 PM
AVバイト:Meta' s llama 3.2、GoogleのGemini 1.5などApr 11, 2025 pm 12:01 PM今週のAIの風景:進歩、倫理的考慮、規制の議論の旋風。 Openai、Google、Meta、Microsoftのような主要なプレーヤーは、画期的な新しいモデルからLEの重要な変化まで、アップデートの急流を解き放ちました
 マシンと話すための人的費用:チャットボットは本当に気にすることができますか?Apr 11, 2025 pm 12:00 PM
マシンと話すための人的費用:チャットボットは本当に気にすることができますか?Apr 11, 2025 pm 12:00 PMつながりの慰めの幻想:私たちはAIとの関係において本当に繁栄していますか? この質問は、MIT Media Labの「AI(AHA)で人間を進める」シンポジウムの楽観的なトーンに挑戦しました。イベントではCondedgを紹介している間
 PythonのScipy Libraryの理解Apr 11, 2025 am 11:57 AM
PythonのScipy Libraryの理解Apr 11, 2025 am 11:57 AM導入 あなたが科学者またはエンジニアで複雑な問題に取り組んでいると想像してください - 微分方程式、最適化の課題、またはフーリエ分析。 Pythonの使いやすさとグラフィックスの機能は魅力的ですが、これらのタスクは強力なツールを必要とします
 ラマ3.2を実行する3つの方法-Analytics VidhyaApr 11, 2025 am 11:56 AM
ラマ3.2を実行する3つの方法-Analytics VidhyaApr 11, 2025 am 11:56 AMメタのラマ3.2:マルチモーダルAIパワーハウス Metaの最新のマルチモーダルモデルであるLlama 3.2は、AIの大幅な進歩を表しており、言語理解の向上、精度の向上、および優れたテキスト生成機能を誇っています。 その能力t
 Dagsterでデータ品質チェックを自動化しますApr 11, 2025 am 11:44 AM
Dagsterでデータ品質チェックを自動化しますApr 11, 2025 am 11:44 AMデータ品質保証:ダグスターと大きな期待でチェックを自動化する データ駆動型のビジネスにとって、高いデータ品質を維持することが重要です。 データの量とソースが増加するにつれて、手動の品質管理は非効率的でエラーが発生しやすくなります。
 メインフレームはAI時代に役割を果たしていますか?Apr 11, 2025 am 11:42 AM
メインフレームはAI時代に役割を果たしていますか?Apr 11, 2025 am 11:42 AMMainFrames:AI革命のUnsung Heroes サーバーは汎用アプリケーションで優れており、複数のクライアントの処理を行いますが、メインフレームは大量のミッションクリティカルなタスク用に構築されています。 これらの強力なシステムは、頻繁にヘビルで見られます


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

Dreamweaver Mac版
ビジュアル Web 開発ツール

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

