
ホームページ >テクノロジー周辺機器 >AI >人工知能を学びたいなら、このデータセットをマスターする必要があります。
人工知能を学びたいなら、このデータセットをマスターする必要があります。

- 王林転載
- 2023-04-08 11:11:062065ブラウズ
人工知能を学習するには、必然的にいくつかのデータセットが必要になります。たとえば、ポルノを識別するための人工知能には、いくつかの同様の写真が必要です。音声認識のための人工知能とコーパスは不可欠です。人工知能を初めて使用する学生は、データセットについて心配することがよくあります。今日は、非常にシンプルですが非常に便利なデータセット、MNIST を紹介します。このデータセットは、人工知能関連のアルゴリズムを学習および実践するのに非常に適しています。
MNIST データ セットは、国立標準技術研究所 (NIST) によって作成された非常に単純なデータ セットです。では、このデータセットは何についてのものなのでしょうか?これは実際には手書きのアラビア数字 (0 から 9 までの 10 個の数字) です。
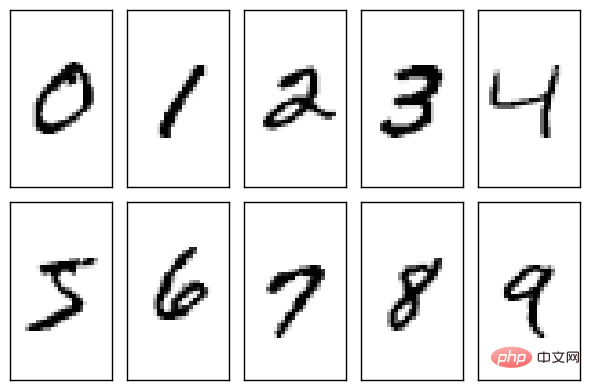
#NIST は、データセットの作成に今でも非常に真剣です。データセット内のトレーニング セットは、250 人の異なる人々からの手書きの数字で構成されており、そのうち 50% は高校生、50% は国勢調査局の職員です。テスト セットも同じ割合の手書き数字データです。
MNIST データ セットのダウンロード方法
MNIST データ セットは、公式 Web サイト (http://yann.lecun.com/exdb/mnist/) からダウンロードできます。海外のウェブサイトの場合、ダウンロードが難しい、遅い場合があります。これには 4 つの部分が含まれています:
- トレーニング セットのイメージ: train-images-idx3-ubyte.gz (9.9 MB、解凍後 47 MB、60,000 のサンプルが含まれます)
- トレーニング セットラベル: train-labels-idx1-ubyte.gz (29 KB、解凍後の 60 KB、60,000 のラベルを含む)
- テスト セット イメージ: t10k-images-idx3-ubyte.gz (1.6 MB、解凍後の 7.8 MB)解凍、10,000 サンプルを含む)
- テスト セット ラベル: t10k-labels-idx1-ubyte.gz (5KB、解凍後 10 KB、10,000 ラベルを含む)
上記には 2 つが含まれていますコンテンツの種類には、写真とラベルがあり、写真とラベルは 1 対 1 に対応します。ただし、ここで表示されている画像は、私たちがよく見る画像ファイルではなく、バイナリ ファイルです。このデータセットには、60,000 枚の画像がバイナリ形式で保存されています。ラベルは画像に対応する実数です。
下の図に示すように、この記事ではデータ セットをローカルにダウンロードし、結果を解凍します。比較しやすいように、元の圧縮パッケージと解凍されたファイルが含まれています。
データ セットの形式の簡単な分析
誰もが、解凍後の圧縮パッケージは画像ではなく、それぞれの圧縮パッケージであることを発見しました。独立した質問に対応します。このファイルには、数万枚の写真やタグに関する情報が保存されています。では、この情報はどのようにしてこのファイルに保存されるのでしょうか?
実はMNISTの公式サイトに詳しく解説されています。トレーニング セットの画像ファイルを例に挙げると、公式 Web サイトで提供されているファイル形式の説明は次のとおりです。
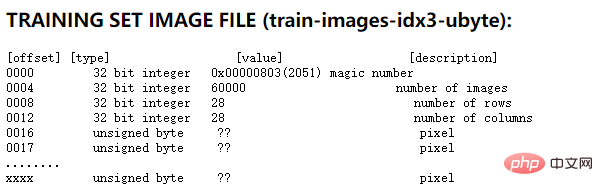
上の図からわかるように、最初の 4 つの 32 桁の数字は、トレーニング セットの説明情報です。最初はマジックナンバーで、固定値は 0x0803、2 番目は画像の数、0xea60、つまり 60000、3 番目と 4 番目は画像のサイズ、つまり画像は 28*28 ピクセルです。 。以下に 1 バイト内の各ピクセルについて説明します。このファイルでは 1 バイトがピクセルを記述するために使用されるため、ピクセルの値は 0 ~ 255 であることがわかります。ここで、0 は白を意味し、255 は黒を意味します。



データセットのファイル形式についてはわかったので、実際にやってみましょう。
データ セットの視覚的処理
上記のデータの保存形式がわかったら、データを解析できます。たとえば、次の記事では、画像コレクション内の画像を解析し、視覚的な結果を取得するための小さなプログラムを実装しています。もちろん、実際にはラベル セットの値に基づいて画像が何であるかを知ることができますが、これは単なる実験です。最終結果は、手書きを表す文字「Y」と背景色を表す文字「0」を使用してテキスト ファイルに保存されます。具体的なプログラム コードは非常に単純なので、この記事では詳しく説明しません。
# -*- coding: UTF-8 -*-
def trans_to_txt(train_file, txt_file, index):
with open(train_file, 'rb') as sf:
with open(txt_file, "w") as wf:
offset = 16 + (28*28*index)
cur_pos = offset
count = 28*28
strlen = 1
out_count = 1
while cur_pos < offset+count:
sf.seek(cur_pos)
data = sf.read(strlen)
res = int(data[0])
#虽然在数据集中像素是1-255表示颜色,这里简化为Y
if res > 0 :
wf.write(" Y ")
else:
wf.write(" 0 ")
#由于图片是28列,因此在此进行换行
if out_count % 28 == 0 :
wf.write("n")
cur_pos += strlen
out_count += 1
trans_to_txt("../data/train-images.idx3-ubyte", "image.txt", 0)上記のコードを実行すると、image.txt という名前のファイルを取得できます。ファイルの内容は次のようにして確認できます。赤い注記は、主に視認性を向上させるために後で追加されました。写真を見てわかるように、これは実際には手書きの「5」です。

# 前回は、ネイティブ Python インターフェイスを通じてデータセットを視覚的に分析しました。 Python にはすでに実装されたライブラリ関数が多数あるため、ライブラリ関数を使用して上記の関数を簡略化できます。
サードパーティ ライブラリに基づくデータの解析
ネイティブ Python インターフェイスを使用して実装するのは少し複雑です。 Python には多くのサードパーティ ライブラリがあることがわかっているので、サードパーティ ライブラリを使用してデータ セットを解析して表示できます。具体的なコードは次のとおりです。
# -*- coding: utf-8 -*-
import os
import struct
import numpy as np
# 读取数据集,以二维数组的方式返回图片信息和标签信息
def load_mnist(path, kind='train'):
# 从指定目录加载数据集
labels_path = os.path.join(path,
'%s-labels.idx1-ubyte'
% kind)
images_path = os.path.join(path,
'%s-images.idx3-ubyte'
% kind)
with open(labels_path, 'rb') as lbpath:
magic, n = struct.unpack('>II',
lbpath.read(8))
labels = np.fromfile(lbpath,
dtype=np.uint8)
with open(images_path, 'rb') as imgpath:
#解析图片信息,存储在images中
magic, num, rows, cols = struct.unpack('>IIII',
imgpath.read(16))
images = np.fromfile(imgpath,
dtype=np.uint8).reshape(len(labels), 784)
return images, labels
# 在终端打印某个图片的数据信息
def print_image(data, index):
idx = 0;
count = 0;
for item in data[index]:
if count % 28 == 0:
print("")
if item > 0:
print("33[7;31mY 33[0m", end="")
else:
print("0 ", end="")
count += 1
def main():
cur_path = os.getcwd()
cur_path = os.path.join(cur_path, "..data")
imgs, labels = load_mnist(cur_path)
print_image(imgs, 0)
if __name__ == "__main__":
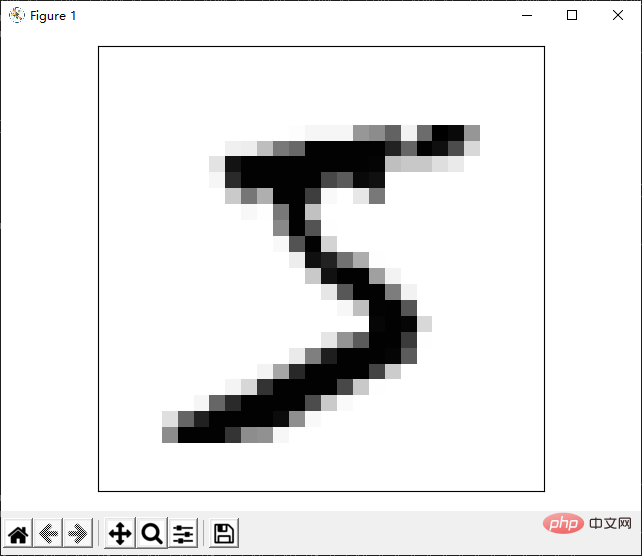
main()上記のコードは 2 つのステップに分かれており、最初のステップではデータ セットを解析して配列にし、次のステップでは配列内の特定の画像を表示します。ここでの表示もテキスト プログラムを介して行われますが、ファイルに保存されるのではなく、端末上で印刷されます。たとえば、最初の画像を印刷すると、その効果は次のようになります。

上記の結果の表示は、文字を介して画像をシミュレートするだけです。実際、サードパーティのライブラリを使用して、より完璧な画像プレゼンテーションを実現できます。次に、matplotlib ライブラリを使用して画像を表示する方法を紹介します。このライブラリは非常に便利なので、後でこのライブラリについて触れます。
我々は
def show_image(data, index): fig, ax = plt.subplots(nrows=1, ncols=1, sharex=True, sharey=True, ) img = data[0].reshape(28, 28) ax.imshow(img, cmap='Greys', interpolation='nearest') ax.set_xticks([]) ax.set_yticks([]) plt.tight_layout() plt.show()を実装します
この時点で、
実装時にいくつかのサードパーティ ライブラリが欠落している可能性があることがわかります。 matplotlib などの上記の関数。
pip install matplotlib -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
TensorFlowによるデータ解析
MNISTは非常に有名で、既にTensorFlowでサポートされています。したがって、TensorFlow を通じてロードして解析できます。以下に TensorFlow で実装されたコードを示します。
# -*- coding: utf-8 -*-
from tensorflow.examples.tutorials.mnist import input_data
import pylab
def show_mnist():
# 通过TensorFlow库解析数据
mnist = input_data.read_data_sets("../data", one_hot=True)
im = mnist.train.images[0]
im = im.reshape(28 ,28)
# 进行绘图
pylab.imshow(im, cmap='Greys', interpolation='nearest')
pylab.show()
if __name__ == "__main__":
show_mnist()このコードによって達成される最終的な効果は前の例と同じなので、ここでは詳しく説明しません。
以上が人工知能を学びたいなら、このデータセットをマスターする必要があります。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。