#GBK
| 2 |
中国語をサポートしますが、国際文字セットはサポートしません |
|
UTF -8
| 3 |
は中国語と英語の混合シナリオをサポートし、国際文字セットです |
|
latin1
| 1 | MySQL デフォルト文字セット |
|
utf8mb4
| 4 |
UTF-8 と完全互換、より多くの文字を格納するために 4 バイトを使用します | |
MySQL データベースの開発および運用における文字セットの選択ルールは次のとおりです。
- システムが海外ビジネス向けに開発されており、さまざまな国や言語に対応する必要がある場合は、次のようにする必要があります。 utf-8 または utf8mb4 を選択します;
- 中国語のサポートのみが必要で海外でのビジネスがない場合は、パフォーマンス上の理由から GBK を使用できます;
3 . カスタム変数
カスタム変数は、コンテンツを保存するために使用される一時コンテナであり、MySQL への接続プロセス全体にわたって存在します。 set を使用して定義できます。
SET @last_week := CURRENT_DATE-INTERVAL 1 WEEK;SELECT id,name from user where create_time > @last_week;
カスタム変数の使用に関する注意事項:
カスタム変数を使用したクエリではキャッシュを使用できません;
カスタム変数は使用できませんテーブル名、列名、limit 句などの定数または識別子が使用される場合;
カスタム変数のライフサイクルは接続内で有効であり、接続間の通信には使用できません。 ;
更新されたばかりのデータに対して繰り返しクエリを実行しないでください
行の更新中に行に関する情報を取得したい場合はどうすればよいですか?繰り返しのクエリを避けますか?
これは一般的に行われます:
update user set update_time = now() where id = 1;select update_time from user where id = 1;
カスタム変数を使用すると最適化できます:
update user set update_time = now() where id = 1 and @now := now();select @now;
まだ 2 つのクエリがあるようですが、2 番目のクエリはアクセスする必要はありません任意のデータテーブルを使用できるため、はるかに高速になります。
4. 最適化されたデータ型の選択
MySQL は多くのデータ型をサポートしており、高いパフォーマンスを得るには正しいデータ型を選択することが重要です。
(1) より小さい
一般に、より小さいデータ型を使用するようにしてください。通常、データ型が小さいほど、占有するスペースが少なくなるため高速になります。ディスク、メモリCPU キャッシュは、処理に必要な CPU サイクルを短縮します。
(2) より単純な
単純なデータ型は、通常必要な CPU サイクルが少なく、文字セットと調整のため、整形は文字列型よりも安価です。 検証ルールにより文字比較が行われます。整数比較よりも複雑です。
(3) NULL を避けるようにしてください
アプリケーションが NULL を保存する必要がない場合でも、NULL はデフォルトのプロパティであるため、多くのテーブルには NULL になる可能性のある列が含まれています。列の場合、通常は列を NOT NULL として指定するのが最善です。
クエリに NULL になる可能性のあるカラムが含まれている場合、NULL カラムによってインデックス、インデックス統計、および値の比較がより複雑になるため、MySQL の最適化がより困難になります。 NULL 対応カラムはより多くのストレージ スペースを使用し、MySQL での特別な処理が必要です。NULL 対応カラムがインデックス付けされると、各インデックス レコードに余分なバイトが必要になり、MyISAM ではサイズが固定される場合もあります。インデックスは可変サイズのインデックスになります。 。
5. ビュー
ビュー (ビュー) は仮想テーブルであり、論理テーブルであり、データそのものは含まれません。 select ステートメントとしてデータ ディクショナリに保存されます。複数のテーブルに対する複雑なクエリの場合、ビューを使用するとクエリを簡略化できます。ビューが一時テーブルを使用する場合、Where 条件は使用できず、インデックスも使用できません。
単一テーブル ビューは、通常、基本テーブルのデータを変更するクエリと変更に使用されます。複数テーブル ビューは、通常、クエリに使用され、基本テーブルのデータは変更されません。
ビューを使用する目的は、データのセキュリティを確保し、クエリの効率を向上させることです。
ビューの利点:
ビューを使用するユーザーは、後続の対応するオブジェクトの構造、関連付け条件、フィルタリング条件を気にする必要がありません。ユーザーにとって、それはすでにフィルタリングされた複合条件の結果セットです。
ビューを使用するユーザーは、クエリを許可されている結果セットにのみアクセスできます。テーブルの権限管理は、特定の行または列に制限することはできませんが、次の方法で簡単に行うことができます。ビューを達成します。
ビューの構造が決定されると、テーブル構造の変更によるユーザーへの影響を防ぐことができます。ソース テーブルに列を追加しても、ビューには影響しません。列を変更しても、ソーステーブル内の名前はビューを変更することで実行でき、訪問者に影響を与えることなく解決できます。
6. キャッシュ テーブルとサマリー テーブル
パフォーマンスを向上させる最善の方法は、派生した冗長データを同じテーブルに保存することです。また、完全に独立したサマリー テーブルまたはキャッシュ テーブルを作成する必要もあります。
- キャッシュ テーブルは、取得は簡単ですが時間がかかるデータを保存するために使用されます。
- サマリー テーブルは、group by ステートメントを使用して集計およびクエリされたデータを保存するために使用されます。
キャッシュ テーブルの場合、メイン テーブルが InnoDB を使用している場合、キャッシュ テーブルのエンジンとして MyISAM を使用すると、インデックスのフットプリントが小さくなり、フルテキストの取得が可能になります。
キャッシュ テーブルとサマリー テーブルを使用する場合、データをリアルタイムで維持するか、定期的に再構築するかを決定する必要があります。どちらが良いかはアプリケーションによって異なりますが、定期的な再構築はリソースを節約するだけでなく、テーブルの断片化を防ぎ、完全に順番に編成されたインデックスを維持します。
サマリー テーブルとキャッシュ テーブルを再構築する場合は、通常、操作中にデータが引き続き利用可能であることを確認する必要があります。これは、シャドウ テーブルを使用して実現する必要があります。シャドウ テーブルとは、テーブルの背後で作成されたテーブルを指します。実テーブル テーブル作成操作が完了した後、アトミックな名前変更操作を通じてシャドウ テーブルと元のテーブルを切り替えることができます。
読み取り速度を向上させるために、追加のインデックスを構築したり、冗長列を追加したり、キャッシュ テーブルや集計テーブルを作成したりすることがよくあります。これらの方法では、書き込みの負担が増加し、追加のメンテナンス作業が必要になります。パフォーマンス データベース これらは一般的な手法であり、書き込み操作は遅くなりますが、読み取りパフォーマンスは大幅に向上します。
7. パーティション化されたテーブル
通常、同じテーブルのデータは物理レベルで一緒に保存されます。ビジネスが成長するにつれて、同じテーブル内のデータ量が大きくなりすぎると、管理に不便が生じます。パーティション機能は、特定のルールに基づいてテーブルを複数のパーティションに物理的に分割することができ、複数のパーティションを個別に管理したり、効率を向上させるために異なるディスク/ファイル システムに保存したりすることもできます。
パーティション テーブルの利点:
データはディスク全体に保存できるため、大量のデータの保存に適しています;
データ管理は非常に便利で、パーティション内のデータを操作しても、他のパーティションの通常の操作には影響しません;
クエリを実行する場合、クエリの範囲を狭めることができ、パーティションの特性をロックすることでクエリを改善します。パフォーマンス;
8. 外部キー外部キーは通常、別のキーで追加の操作が必要です。クエリ操作の場合、InnoDB は外部キーにインデックスの使用を強制しますが、この制約チェックのオーバーヘッドを排除することはできません。外部キーの選択性が非常に低い場合、非常に選択的なインデックスが作成されます。 ただし、シナリオによっては、外部キーを使用するとパフォーマンスが向上します。たとえば、関連する 2 つのテーブルのデータが常に一貫していることを確認したい場合は、アプリケーションで一貫性をチェックするよりも外部キーを使用した方がパフォーマンスが高くなります。 . そのほかにも。外部キーは、アプリケーション内で関連データを維持するよりも、削除および更新の方が効率的ですが、外部キーの維持操作は行ごとに実行されるため、そのような更新はバッチの削除や更新よりも遅くなります。 外部キー制約では、クエリ中に他のテーブルへの追加アクセスが必要になり、追加のロックが必要になります。レコードが子テーブルに書き込まれる場合、外部キー制約により、InnoDB は親テーブルの対応するレコードをチェックします。つまり、このレコードが失われないように、親テーブルの対応するレコードをロックする必要があります。取引完了後、削除されました。これにより、追加のロック待機が発生したり、デッドロックが発生したりする可能性があります。これらのテーブルには直接アクセスできないため、このタイプのデッドロックのトラブルシューティングは困難です。 したがって、現在の多くのプロジェクトでは、パフォーマンス上の理由から外部キーは使用されなくなりました。
9. クエリ キャッシュ MySQL クエリ キャッシュは、クエリによって返された完全な結果を保存します。クエリがキャッシュにヒットすると、MySQL は解析をスキップして、すぐに結果を返します。 、最適化と実装プロセス。 
クエリ キャッシュ システムは、クエリに含まれる各テーブルを追跡します。これらのテーブルが変更されると、このテーブルに関連するキャッシュされたデータはすべて無効になります。これがメカニズムの効率です。データ テーブルが変更されてもクエリ結果が影響を受けない可能性があるため、このコストは比較的低いように見えますが、この単純な実装のコストは非常に小さいため、これは非常にビジーなシステムにとって非常に重要です。
(1) MySQL はキャッシュ ヒットをどのように判断しますか? に関する情報。スペースやコメントなどの文字の違いがあると、キャッシュ ミスが発生します。一般に、統一されたコーディング ルールを使用することは良い習慣であり、システムの実行速度が向上します。 クエリ ステートメントに不確実なデータがある場合、関数 now() などはキャッシュされません。実際、キャッシュにユーザー定義関数、ストアド関数、ユーザー変数、一時テーブル、MySQL システム テーブル、または列レベルの権限を含むテーブルが含まれている場合、それらはキャッシュされません。
# (2) クエリ キャッシュを使用するときは注意してくださいクエリ キャッシュを開くと、読み取り操作と書き込み操作の両方で追加の消費が発生します:
読み取りクエリを実行する前に、まずキャッシュにヒットするかどうかを確認する必要があります。
InnoDB ユーザーの場合、トランザクションの特性によってはクエリ キャッシュの使用が制限されます。トランザクション内のステートメントがテーブルを変更すると、MySQL はトランザクションが送信される前にテーブルに対応するクエリ キャッシュ設定を無効にするため、トランザクションが長時間実行されるとクエリ キャッシュのヒット率が大幅に低下します。
(3) クエリ キャッシュの分析と構成方法
10. ストアド プロシージャ
ストアド プロシージャはプロシージャのセットです。特定の機能を完了するように設計されており、SQL ステートメントのコレクションがコンパイルされてデータベースに保存され、ストアド プロシージャの名前を指定し、パラメーターの値を指定することで、結果を返すこともできます。
ストアド プロシージャの利点:
ネットワーク トラフィックの削減
-
実行速度の向上
- #データベース接続数の削減
- 高セキュリティ
- 高再利用性
トランザクション内のステートメントはすべて実行されるか、まったく実行されません。トランザクションには、原子性、一貫性、分離性、耐久性を表す ACID 特性があります。
トランザクションは分割できない最小の作業単位とみなされ、トランザクション全体のすべての操作が完全に実行され、コミットされる必要があります。成功、または失敗した場合はロールバック。
データベースは常に、ある整合性状態から別の整合性状態に遷移します。
あるトランザクションによって行われた変更は、最終的にコミットされるまで他のトランザクションには表示されません。
トランザクションが送信されると、加えられた変更はデータベースに永続的に保存されます。
インデックスは、ストレージ エンジンがレコードを迅速に検索するために使用するデータ構造です。データベースで最も重要な知識ポイントはインデックスだと思います。 ストレージ エンジンはさまざまな方法で B ツリー インデックスを使用し、そのパフォーマンスも異なり、それぞれに独自の長所と短所があります。たとえば、MyISAM はプレフィックス圧縮テクノロジーを使用してインデックスを小さくしますが、InnoDB はインデックスを元のデータ形式で保存します。 MyISAM インデックスはデータの物理的な場所によってインデックス付けされた行を参照しますが、InnoDB は主キーによってインデックス付けされた行を参照します。
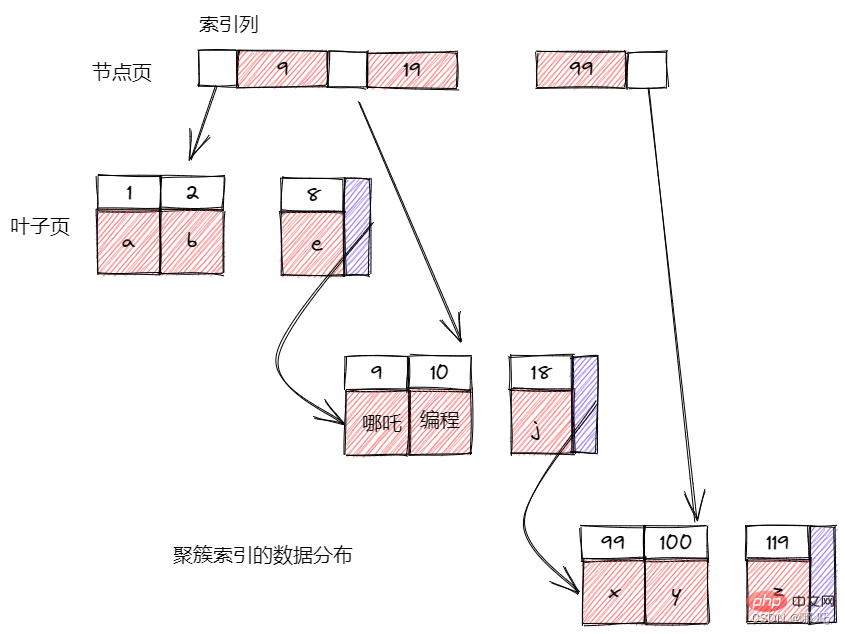
#B ツリーは通常、すべての値が順番に格納され、各リーフ ページがルートから同じ距離にあることを意味します。 B ツリー インデックスでは、ストレージ エンジンが必要なデータを取得するためにテーブル全体のスキャンを実行する必要がなくなり、代わりにインデックスのルート ノードから検索するため、データへのアクセスが高速化されます。ルート ノードのスロットには子ノードへのポインタが格納され、ストレージ エンジンはこれらのポインタに基づいて下方向に検索します。ノード ページの値と探している値を比較することで、下位の子ノードへの適切なポインターを見つけることができます。これらのポインターは、実際には子ノード ページの値の上限と下限を定義します。最終的に、ストレージ エンジンは対応する値を見つけるか、レコードが存在しません。 リーフ ノードは特別であり、そのポインタは他のノード ページではなく、インデックス付きデータを指します。 B ツリーはインデックス列を順番に編成して格納するため、範囲データの検索に非常に適しています。 B ツリーは、完全なキー値、キー値の範囲、またはキー プレフィックス検索に適しています。 インデックス ツリー内のノードは順序付けされているため、値による検索に加えて、クエリ内の順序による操作にもインデックスを使用できます。一般に、B ツリーが特定の方法で値を見つけることができれば、この方法でソートにも使用できます。
フルテキスト インデックスの目的は、正確なクエリではなく、類似性クエリに基づいたキーワード マッチングを通じてクエリ フィルタリングを実行することです。 全文インデックスは、単語分割テクノロジーを使用してテキスト内の特定のキーワードの頻度と重要性を分析し、特定のアルゴリズムに従って必要な結果をインテリジェントにフィルタリングします。 フルテキスト インデックスは、通常、char、varchar、text などの文字列内の特定のキーワードをクエリするために使用されます。また、自然言語フルテキスト インデックスとブール型フルテキスト インデックスもサポートされています。 推奨学習: mysql ビデオ チュートリアル


