MySQL の各テーブルにはどれくらいのデータを保存できますか?実際には、テーブルごとにフィールドやフィールドが占める領域が異なり、最適なパフォーマンスで格納できるデータ量も異なるため、手動で計算する必要があります。
内容は次のとおりです
以下は私の友人のインタビュー記録です:
インタビュアー: 教えてくださいインターンでは何をしていたんですか?
友人: インターンシップ中に、ユーザーの操作記録を保存する機能を構築しましたが、主に上流サービスから送られてくるユーザーの操作情報をMQから取得し、MySQLに保存してデータウェアハウスに提供する機能です。 . 同僚が使用します。
友人: データ量が比較的多く、毎日 4,000 ~ 5,000 万件のエントリがあるため、それに対してサブテーブル操作も実行しました。 3 つのテーブルが毎日定期的に生成され、テーブル内の過剰なデータによってクエリ速度が低下することを防ぐために、データがモデル化されてこれら 3 つのテーブルにそれぞれ格納されます。
このステートメントには何の問題もないようですよね? 心配しないで、読み続けましょう:
インタビュアー: では、なぜそれを 3 つの表に分割するのでしょうか。 ? 2 つのテーブルは機能しません。テーブルが 4 つあれば機能しないでしょうか? 友人: 各 MySQL テーブルのデータは 2,000 万個を超えてはなりません。そうしないと、クエリ速度が低下し、パフォーマンスに影響します。 1 日あたりのデータは約 5,000 万個であるため、3 つのテーブルに分割する方が安全です。 インタビュアー: 他に何かありますか? 友人: もうだめです...何してるの、痛い
インタビュアー: それなら戻って通知を待ちます。
話し終えましたが、何か見えましたか?私の友人の答えに何か問題があると思いますか?
序文
多くの人は、各 MySQL テーブルのデータが 2,000 万個を超えないようにするのが最善だと言います。そうしないと、パフォーマンスの低下につながります。 Alibaba の Java 開発マニュアルには、単一テーブルの行数が 500 万を超える場合、または単一テーブルの容量が 2GB を超える場合にのみ、データベースとテーブルを分割することをお勧めすると記載されています。
しかし、実際には、この 2,000 万または 500 万は単なる大まかな数字であり、すべてのシナリオに当てはまるわけではありません。テーブル データが 2,000 万を超えない限り、盲目的に考えると、問題ありませんが、システムのパフォーマンスが大幅に低下する可能性があります。
実際の状況では、各テーブルのフィールドとフィールドが占有する領域が異なるため、最適なパフォーマンスで格納できるデータの量も異なります。
それでは、各テーブルの適切なデータ量を計算するにはどうすればよいでしょうか?心配しないで、ゆっくりと下を見てください。
この記事は読者に適しています
この記事を読むには、特定の MySQL 基盤が必要です。 InnoDB と B-tree についてのある程度の理解、MySQL の学習経験が 1 年以上 (1 年くらい?)、「一般的に B-tree の高さを維持する方が良い」という理論的知識を知っている必要があるかもしれません。 InnoDB のツリーは 3 レベル以内にあります。」
この記事では「InnoDBの高さ3のBツリーにはどのくらいのデータを格納できるのか?」というテーマを中心に説明します。さらに、この記事のデータの計算は比較的厳密です (少なくとも、インターネット上の関連ブログ投稿の 95% 以上よりも厳密です)。これらの詳細が気になり、現時点ではよくわからない場合は、読み続けてください。
この記事を読むのにかかる時間は 10 ~ 20 分程度ですが、読みながらデータを確認すると 30 分ほどかかる場合があります。
#この記事のマインドマップ
##基礎知識の簡単な復習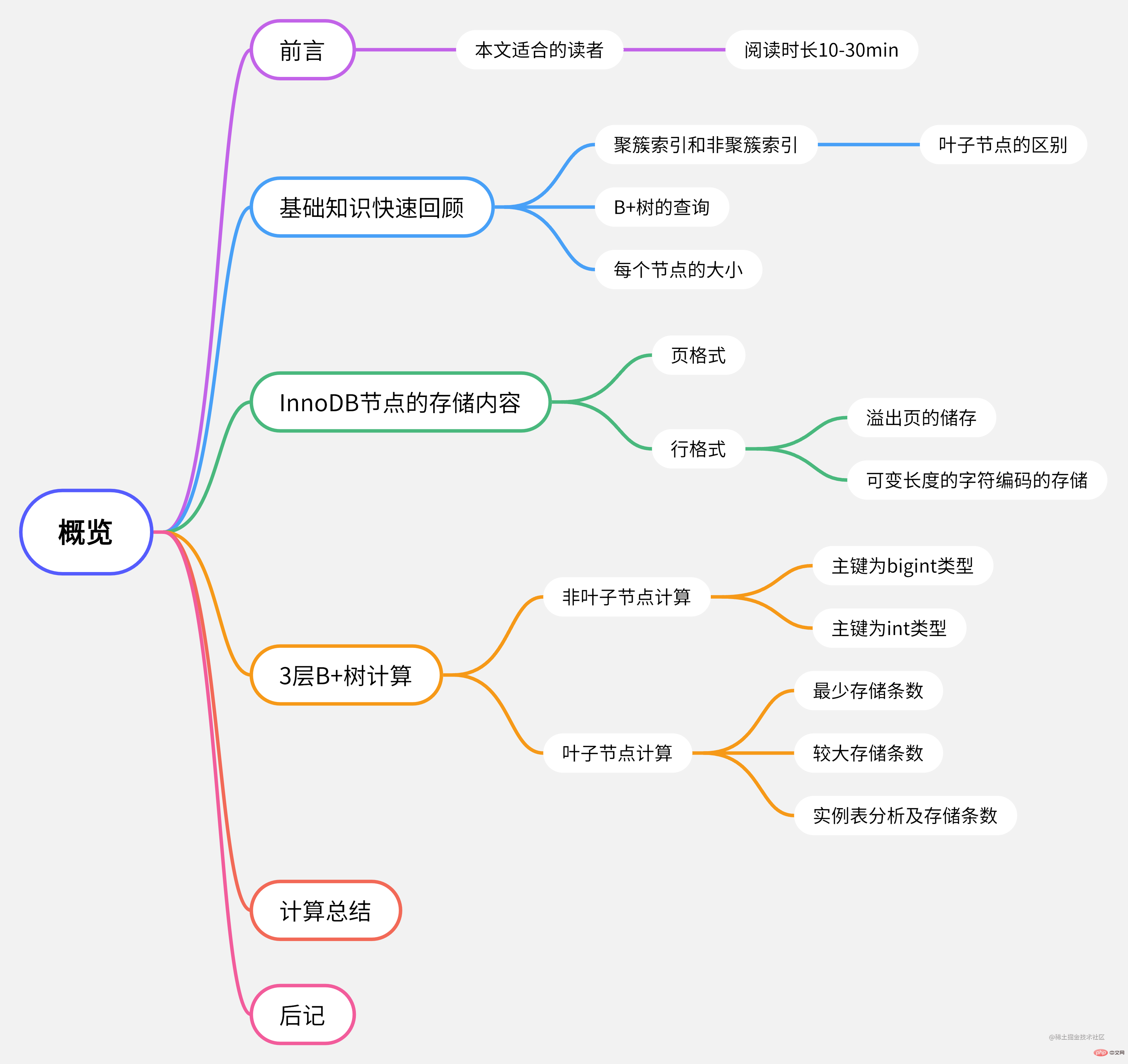
ご存知のとおり、MySQL における InnoDB のストレージ構造は B ツリーです。特徴は大まかに以下の通りなので、一緒に簡単におさらいしていきましょう!
注: 次の内容は本質です。読んだり理解できない学生は、まずこの記事を保存し、知識ベースを取得した後に戻って読むことをお勧めします。 ##。 ??
データ テーブルは通常、1 つ以上のツリーのストレージに対応します。ツリーの数はインデックスの数に関連します。各インデックスには個別のツリーがあります。
クラスター化インデックスと非クラスター化インデックス: -
主キー インデックスもクラスター化インデックスであり、非主キー インデックスは非クラスター化インデックスです。
形式情報を除き、両方のインデックスの非リーフ ノードはインデックス データのみを格納します たとえば、インデックスが id の場合、非リーフ ノードは id データを格納します。 -
リーフ ノード間の違いは次のとおりです:
- クラスター化インデックスのリーフ ノードには、通常、このデータの すべてのフィールド情報が格納されます。したがって、id = 1
のテーブルから select * を実行すると、常にリーフ ノードに移動してデータを取得します。
- 非クラスター化インデックスのリーフ ノードには、このデータに対応する 主キーとインデックス列の情報が格納されます。たとえば、この非クラスター化インデックスがユーザー名で、テーブルの主キーが id の場合、非クラスター化インデックスのリーフ ノードにはユーザー名と ID が格納されますが、他のフィールドは格納されません。
これは、まず非クラスター化インデックスから主キーの値を検索し、次に主キー インデックスに基づいてデータの内容をチェックすることと同じです。通常、(インデックスがカバーされていない限り) 2 回チェックする必要があります。 Back to the table とも呼ばれます。これは、データが保存されている実際のアドレスを指すポインターの保存に少し似ています。
-
B ツリーのクエリは上から下へ階層ごとにクエリされます。一般的に、B ツリーの高さは 3 階層以内に抑えるのがよいと考えられます。つまり、上の 2 つの層はインデックスであり、最後の層はデータを格納します。このようにして、テーブルを検索するときに必要なディスク IO は 3 回だけです (ルート ノードがメモリ内に常駐するため、実際には 1 回少なくなります)。 、保存できるデータ量も非常に印象的です。
データ量が多すぎてBの数が4レベルになると、各クエリに4回のディスクIOが必要となり、パフォーマンスが低下します。 だからこそ、InnoDB の 3 層 B ツリーが保存できるデータの最大数を計算します。
-
各 MySQL ノードのデフォルト サイズは 16 KB です。つまり、各ノードは最大 16 KB のデータを保存でき、そのデータは変更可能で、最大 64 KB で、最小 4KB。
拡張: 特定の行のデータが特に大きく、ノードのサイズを超えた場合はどうなりますか?
MySQL5.7 ドキュメントでは次のように説明されています:
4KB、8KB、16KB、および 32KB 設定の場合、最大行長はデータベース ページの半分よりわずかに小さくなります。たとえば、デフォルトの 16KB ページ サイズの場合、最大行長は 8KB よりわずかに小さくなり、デフォルトの 32KB ページ サイズの場合、最大行長は 16KB よりわずかに小さくなります。
64KB ページの場合、最大行長は 16KB よりわずかに小さくなります。
行が最大行長を超える場合、行が最大行長制限に達するまで、可変長列は外部ページに格納されます。 つまり、この行のデータ長を減らすために、可変長の varchar と text が外部ページに格納されます。

ドキュメント アドレス:
MySQL :: MySQL 5.7 リファレンス マニュアル :: 14.12.2 ファイル スペース管理
MySQL InnoDB ノード ストレージのコンテンツ
Innodb の B ツリーでは、私たちがよく参照するノードは ページ (ページ) と呼ばれます。 )、各ページにはユーザー データが保存され、すべてのページがまとめて B ツリーを形成します (もちろん、実際にはさらに複雑になりますが、保存できるデータの数を計算する必要があるだけなので、当面はこうなるかもしれません、わかりますか?)
Page は、InnoDB ストレージ エンジンがデータベースを管理するために使用する最小のディスク ユニットです。各ノードは 16 KB であるとよく言われますが、実際には各ページのサイズを意味します。は16KBです。
この 16KB のスペースには、ページ形式情報と 行形式情報を保存する必要があります。行形式情報には、メタデータとユーザー データも含まれています。したがって、計算するときは、これらすべてのデータを含める必要があります。
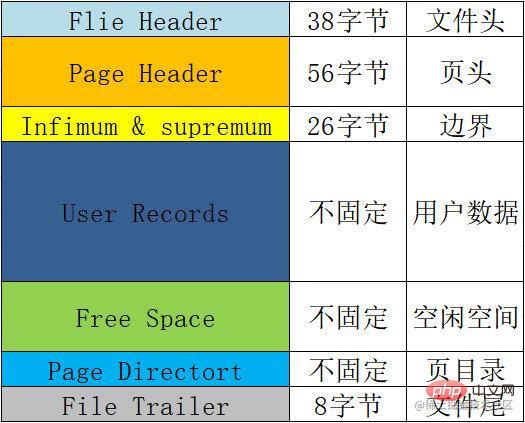
ページ形式
各ページの基本的な形式、つまり各ページに含まれる情報の概要表は次のとおりです。 :
| 名前 |
スペース |
意味や機能など |
ファイル ヘッダー |
38 バイト |
ファイル ヘッダー。ページのヘッダー情報を記録するために使用されます。
チェックサム、ページ番号、前後のノードへの 2 つのポインター、
ページ タイプ、テーブル スペースなどが含まれます。 |
ページ ヘッダー |
56 バイト |
ページ ヘッダー。ページのステータス情報を記録するために使用されます。
ページ ディレクトリ内のスロットの数、空き領域のアドレス、このページのレコード数、
削除されたレコードが占有しているバイト数などが含まれます。 |
上限と上限 |
26 バイト |
は、現在のページ レコードの境界値を制限するために使用されます。最小値と最大値。 |
ユーザー レコード |
未修正 |
ユーザー レコード、挿入したデータはここに保存されます。 |
#空きスペース | 未修正 | 空きスペース。ユーザー レコードが追加されるときにここからスペースを取得します。 |
ページ ディレクトリ | Unfixed | ページ ディレクトリは、ページ内のユーザー データの位置情報を保存するために使用されます。 各スロットには 4 ~ 8 個のユーザー データが格納され、1 スロットは 1 ~ 2 バイトを占有します。
1 スロットが 8 データを超えると、自動的に 2 つのスロットに分割されます。
|
ファイル トレーラー | 8 バイト | ファイルの終わりの情報。主にページの整合性を検証するために使用されます。 |
模式図:
公式サイトをずっと眺めていたのですが、ページ形式の内容が見つかりませんでした。 。 。 。私が書いていないからなのか、目が見えないからなのかわかりませんが、もし見つけた人がいたら、コメント欄に投稿するのを手伝っていただけないでしょうか。
したがって、上記のページの形式の表の内容は、主にいくつかのブログからの学習と要約に基づいています。
さらに、新しいレコードが InnoDB クラスター化インデックスに挿入されると、InnoDB は今後のインデックス レコードの挿入と更新のためにページの 1/16 を空き領域に残そうとします。インデックス レコードが順序どおり (昇順または降順) に挿入される場合、結果のページには使用可能なスペースの約 15/16 が含まれます。レコードがランダムな順序で挿入される場合、ページ領域の約 1/2 ~ 15/16 が使用可能になります。参考ドキュメント: MySQL :: MySQL 5.7 リファレンス マニュアル :: 14.6.2.2 InnoDB インデックスの物理構造
ユーザー レコード と 空き領域 を除く占有メモリは ##3 #8#56 26 8##=#128 ページごとのバイト数 ユーザー データ用に残されたスペースはわずか 16×1516##16 ##15#×1024−128 =##1523 2 バイト (1/16 予約済み)。 もちろん、ページのディレクトリは考慮していないため、これは最小値です。ページ ディレクトリは後で考慮する必要があり、テーブル フィールドに基づいて計算する必要があります。 行フォーマットまず、MySQL5.6 のデフォルトの行フォーマットは COMPACT (コンパクト) であることを述べておく必要があると思います。 ), 5.7 将来のデフォルトの行フォーマットは DYNAMIC (動的) です。異なる行フォーマットは異なる方法で保存されます。他にも 2 つの行フォーマットがあります。この記事の以下の内容は主に DYNAMIC (動的) に基づいて説明されています。
公式ドキュメント リンク: MySQL :: MySQL 5.7 リファレンス マニュアル:: 14.11 InnoDB 行形式 (次の行形式コンテンツのほとんどはこの中にあります)
レコードの各行には次の情報が含まれており、そのほとんどは公式文書に記載されています。ここに書いたことはあまり詳しくありません。スペースの計算に役立つ知識を書いただけです。より詳細な情報については、オンラインで「MySQL 行フォーマット」を検索してください。
| 名前 |
スペース |
意味や働きなど |
| 行レコードのヘッダー情報 |
5 バイト |
行レコードのヘッダー情報
いくつかのフラグ ビット、データ型、その他の情報が含まれます
削除フラグ、最小レコード フラグ、ソートなどレコード、データ型、
ページ内の次のレコードの位置など。 |
| 可変長フィールド リスト |
は固定されていません |
保存できるものを保存します varchar、text、blob などの可変長フィールドが占めるバイト数。
可変長フィールドの長さが 255 バイト未満の場合は、1 バイト で表され、
255 バイトを超える場合は、2 で表されます。バイト。
テーブルフィールドに複数の可変長フィールドがある場合、リストには複数の値が存在しますが、何もない場合は保存されません。 |
| null 値リスト |
未修正 |
null になり得るフィールドが null かどうかを格納するために使用されます。
ここでは、Null 許容フィールドはそれぞれ 1 ビットを占有します。これがビットマップの考え方です。
このリストが占めるスペースはバイト単位で増加します。たとえば、NULL にできる
列が 9 ~ 16 個ある場合、1.5 バイトではなく 2 バイトが使用されます。 |
| トランザクション ID とポインター フィールド |
6 7 バイト |
MVCC を知っている人は、データ行に 6 バイトのトランザクション ID が含まれていることを知っているはずです。および
は 7 バイトのポインター フィールドです。
主キーが定義されていない場合は、追加の 6 バイトの行 ID フィールドが存在します。
もちろん、誰もが主キーを持っているため、この行 ID は計算しません。 |
#実際のデータ | 未修正 | この部分は実際のデータです。 |
概略図:

また、注意すべき点がいくつかあります:
オーバーフロー ページ (外部ページ) のストレージ
注: これは DYNAMIC の機能です。
DYNAMIC を使用してテーブルを作成すると、InnoDB は長い可変長カラム (VARCHAR、VARBINARY、BLOB、TEXT 型など) の値を削除し、## に格納します。 #overflow page 、オーバーフロー ページを指す 20 バイトのポインターのみがこの列で予約されています。
COMPACT 行形式 (MySQL5.6 のデフォルト形式) では、最初の 768 バイトと 20 バイトのポインタが B ツリー ノードのレコードに保存され、残りはオーバーフロー ページに保存されます。 。
列がオフページに格納されるかどうかは、ページ サイズと行の合計サイズによって異なります。行が長すぎる場合は、クラスター化インデックスのレコードが B ツリー ページに収まるまで、最長の列がオフページ ストレージとして選択されます (文書にはその数が記載されていません)。 40 バイト以下の TEXT および BLOB は行内に直接格納され、ページングされません。
利点
DYNAMIC 行形式では、B ツリー ノードに大量のデータが詰め込まれて列が長くなってしまうという問題が回避されます。 DYNAMIC 行形式の背後にある考え方は、長いデータ値の一部がオフページに格納されている場合、通常は値全体をオフページに格納するのが最も効率的であるということです。 DYNAMIC 形式では、可能な限り短い列が B ツリー ノードに保持され、特定の行に必要なオーバーフロー ページの数が最小限に抑えられます。
異なる文字エンコーディングでのストレージ
Char、varchar、text などは、文字エンコーディング タイプを設定する必要があります。占有領域を計算するときは、異なるエンコーディングを設定する必要があります。占有スペースを考慮します。 varchar、text、およびその他の型には、それらが占める長さを記録するための長さフィールド リストがありますが、char は固定長型であり、これは特殊な状況です。フィールド名の型が char( であると仮定します。
- 固定長文字エンコーディング (ASCII コードなど) の場合、フィールド名は固定長形式で保存されます。 ASCII コードの は 1 バイトを占めるため、name は 10 バイトを占めます。
- 可変長文字エンコーディング (utf8mb4 など) の場合、名前用に少なくとも 10 バイトが予約されます。可能であれば、InnoDB は末尾の空白を削除して 10 バイトに保存します。 トリミング後にスペースを保存できない場合、末尾のスペースは
列値のバイト長 の最小値 (通常は 1 バイト) までトリミングされます。
列の最大長は次のとおりです: 文字記号##大字記号##長さ##度##×N、たとえば、名前フィールドのエンコードは utf8mb4、つまり 4×104 \times 10##10。 768 バイト以上の Char 列は (varchar と同様に) 可変長フィールドとして扱われ、複数のページにまたがって格納できます。たとえば、utf8mb4 文字セットの最大バイト長は 4 であるため、クロスページ ストレージの場合、char(255) 列は 768 バイトを超える可能性があります。
正直に言うと、char の設計はよくわかりません。公式ドキュメントやいくつかのブログを含めて長い間読んできましたが、理解できる学生であれば理解できると思いますコメント エリアで疑問を明らかにしてください:
可変長の文字エンコーディングについて、char は可変長型に似ていますか?一般的に使用される utf8mb4 は 1 ~ 4 バイトを占有するため、char(10) が占有するスペースは 10 ~ 40 バイトになります。この変更は非常に大きなものですが、十分なスペースを残しておらず、また、 char フィールドのスペース使用量を記録するための可変長フィールド リスト?
計算を開始します
各ページに何が保存されているかはすでにわかっており、計算能力も備わりました。
上記のページ形式でページの残りのスペースを計算済みなので、各ページに使用できるバイト数は 15232 バイトになります。すぐ下の行を計算してみましょう。
#非リーフ ノードの計算
単一ノードの計算
インデックス ページがノードですインデックスが格納される場所、つまり非リーフ ノード。 各インデックス レコードには、現在のインデックスの値、6 バイトのポインター情報、使用される 5 バイトの行ヘッダー が含まれます。データ ページの次の層へのポインタを指します。
公式ドキュメントのインデックス レコードでポインタが占めるスペースが見つかりませんでした?この 6 バイトについては他のブログ投稿を参照しました。ソースでは 6 バイトであるとのことです。コードですが、特にソースコードのどの部分が分からないのですか? もっと詳しい学生がコメント欄で疑問を解消できることを願っています。
主キー ID が bigint 型 (8 バイト) であると仮定すると、インデックス ページ内のデータの各行が占めるスペースは に等しくなります。 ##8 6 5=19 バイト。各ページで #15232##÷19≈801## インデックス データ。 ページ ディレクトリを含めて、スロットあたり 6 個のデータの平均を計算すると、少なくとも 801##÷ #6##≈ 134 スロット。268 バイトのスペースが必要です。 データ格納領域をスロットに割り当てた場合、約 787 個のインデックス データを格納できると計算しました。
主キーが int 型の場合、さらに多くのインデックスデータを約 993 個格納できます。
最初の 2 つの層の非リーフ ノードの計算
B ツリーで、ノード インデックス レコードが ##N # バー、##N## 子ノード。 3 レベルの B ツリーの最初の 2 レベルはインデックス レコードであるため、最初のレベルのルート ノードは N## インデックスレコードの場合、2 番目のレイヤーには #N ノード。各ノードのデータ型はルート ノードと同じであり、まだ保存できます#N#N レコードの場合、3 番目の層のノードの数は と等しくなります。 #N2##N^2##2# #################################################### その場合、次のようになります: #主キー bigint を持つテーブルには -
787 2#=619369# リーフ ノード #int の主キーを持つテーブルには # を格納できます
99- 33#2#=##986049# リーフ ノードOK計算を完了します。 データ レコード数の計算保存されるレコードの最小数
前述しました前に、行の最大長は、データベース ページ
の半分よりわずかに小さいです。半分よりわずかに小さい理由は、各ページが ページ形式 の他のコンテンツ用にスペースを残しておくためです。 , したがって、各ページには少なくとも 2 つのデータを保持でき、各データは 8KB よりわずかに小さいと考えることができます。行のデータ長がこの値を超える場合、InnoDB は確実に一部のデータを overflow page に分割するため、考慮しません。
各データが 8KB の場合、各リーフ ノードには 2 つのデータしか格納できません。このようなテーブルは、主キーが bigint の場合、##2× #61936 9=##12 38738 データ、つまり120万個以上、このデータ量は予想外ですよね?? 保存されるレコードの数が増える
テーブルが次のようになっているとします:-- 这是一张非常普通的课程安排表,除id外,仅包含了课程id和老师id两个字段
-- 且这几个字段均为 int 型(当然实际生产中不会这么设计表,这里只是举例)。
CREATE TABLE `course_schedule` (
`id` int NOT NULL,
`teacher_id` int NOT NULL,
`course_id` int NOT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
まず、このテーブルの行データを分析しましょう。NULL 値リスト、可変長フィールド リストはなく、トランザクション ID とポインター フィールドをカウントする必要があり、行レコード ヘッダーをカウントする必要があります。次に、各行が占めるスペースを分析します。データの量:#4 4 4 ## #####6#########6######################### 5=30 バイト、各リーフ ノードは格納できます15232÷30≈ 507 15232 \div 30 \約 50730##≈#507 データ。 算上页目录的槽位所占空间,每个叶子节点可以存放 502 条数据,那么三层B+树可以存放的最大数据量就是 502×986049=494,996,598,将近5亿条数据!没想到吧??。
常规表的存放记录数
大部分情况下我们的表字段都不是上面那样的,所以我选择了一场比较常规的表来进行分析,看看能存放多少数据。表情况如下:
CREATE TABLE `blog` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '博客id',
`author_id` bigint unsigned NOT NULL COMMENT '作者id',
`title` varchar(50) CHARACTER SET utf8mb4 NOT NULL COMMENT '标题',
`description` varchar(250) CHARACTER SET utf8mb4 NOT NULL COMMENT '描述',
`school_code` bigint unsigned DEFAULT NULL COMMENT '院校代码',
`cover_image` char(32) DEFAULT NULL COMMENT '封面图',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`release_time` datetime DEFAULT NULL COMMENT '首次发表时间',
`modified_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
`status` tinyint unsigned NOT NULL COMMENT '发表状态',
`is_delete` tinyint unsigned NOT NULL DEFAULT 0,
PRIMARY KEY (`id`),
KEY `author_id` (`author_id`),
KEY `school_code` (`school_code`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COLLATE=utf8_general_mysql500_ci ROW_FORMAT=DYNAMIC;
这是我的开源项目“校园博客”(GitHub地址:github.com/stick-i/scb…) 中的博客表,用于存放博客的基本数据。
分析一下这张表的行记录:
統計上面的所有分析,共佔用869 位元組,則每個葉子節點可以存放1#52#32÷8 69≈17
條,算上頁目錄,仍然可以放17 條。 則三層B 樹可以存放的最大資料量就是17 \times 619369 = 10,529,27317#×#619369= 10,#529,27#3
,約一千萬條數據,再次沒想到吧?。
資料計算總結根據上面三種不同情況下的計算,可以看出,InnoDB三層B 樹情況下的資料儲存量範圍為一百二十多萬條 到將近5億條
,這個跨度還是非常大的,同時我們也計算了一張博客資訊表,可以儲存
約一千萬條 數據。
所以啊,我們在做專案考慮分錶的時候還是得多關註表的實際情況,而不是盲目的認為兩千萬資料就是那個臨界點。
######如果面試時談到這塊的問題,我想面試官並不是想知道這個數字到底是多少,而是想看你如何分析這個問題,看你得出這個數字的過程。 ###

