
ホームページ >バックエンド開発 >Python チュートリアル >Python の複数のスレッドで同時に画像をダウンロードする方法
Python の複数のスレッドで同時に画像をダウンロードする方法

- 青灯夜游転載
- 2022-09-22 13:43:003689ブラウズ

大量の画像をダウンロードするのに数時間かかることがあります。問題は解決しましょう。
わかりました。プログラムが画像をダウンロードするのを待つのにうんざりしています。時々、何時間もかかる何千もの画像をダウンロードしなければならないことがありますが、プログラムがこれらのばかげた画像のダウンロードを完了するのを待ち続けることはできません。やるべき重要なことがたくさんあります。
テキスト ファイルを読み取り、フォルダー内にリストされているすべての画像を超高速でダウンロードする、単純な画像ダウンローダー スクリプトを構築しましょう。
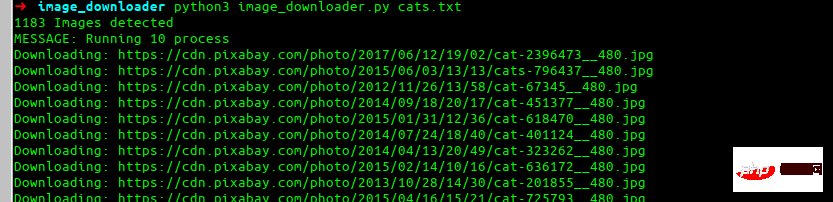
最終エフェクト
これが、構築する最後のエフェクトです。

#依存関係のインストール
みんなのお気に入りのリクエスト ライブラリをインストールしましょう。pip install requests次に、単一の URL をダウンロードし、イメージ名を自動的に検索するための基本的なコードと、再試行の使用方法を見ていきます。
import requests
res = requests.get(img_url, stream=True)
count = 1
while res.status_code != 200 and count ここでは、失敗した場合に備えて、イメージのダウンロードを 5 回再試行します。ここで、画像の名前を自動的に検索して保存してみましょう。 <p></p><pre class="brush:php;toolbar:false">import more required library
import io
from PIL import Image
# lets try to find the image name
image_name = str(img_url[(img_url.rfind('/')) + 1:])
if '?' in image_name:
image_name = image_name[:image_name.find('?')]説明
ダウンロードしたい URL がinstagram.fktm7-1.fna.fbcdn.net であると仮定します。 /vp ...
わかりました、これは混乱です。コードが URL に対して何を行うのかを詳しく見てみましょう。まずrfind を使用して最後のスラッシュ (/) を検索し、それ以降のすべてを選択します。結果は次のとおりです:
次は 2 番目の部分で、
を見つけます。 ? そして、その前にあるものをそのまま取ります。 これは最終的なイメージ名です:
この結果は非常に良好で、ほとんどのユースケースに適しています。
イメージ名とイメージをダウンロードしたので、保存します。
i = Image.open(io.BytesIO(res.content)) i.save(image_name)
「上記のコードは一体どうやって使えばいいの?」と思っているなら、その通りです。これは美しい関数であり、上で行ったことはすべてフラット化されています。ここでは、イメージ名が見つからない場合に備えて、ダウンロードされたタイプがイメージであるかどうかもテストします。
def image_downloader(img_url: str):
"""
Input:
param: img_url str (Image url)
Tries to download the image url and use name provided in headers. Else it randomly picks a name
"""
print(f'Downloading: {img_url}')
res = requests.get(img_url, stream=True)
count = 1
while res.status_code != 200 and count <p>ここで、「この人が話しているマルチプロセッシングとは何ですか?」と疑問に思うかもしれません。 </p><p>これはとても簡単です。プールを定義し、それに関数と画像の URL を渡すだけです。 </p><pre class="brush:php;toolbar:false">results = ThreadPool(process).imap_unordered(image_downloader, images_url)
for r in results:
print(r)これを関数に入れてみましょう:
def run_downloader(process:int, images_url:list):
"""
Inputs:
process: (int) number of process to run
images_url:(list) list of images url
"""
print(f'MESSAGE: Running {process} process')
results = ThreadPool(process).imap_unordered(image_downloader, images_url)
for r in results:
print(r)繰り返しますが、「これは十分に良いことですが、すぐに 1000 枚の画像リストのダウンロードを開始したいと思います。このコードをすべてコピーして貼り付けて、すべてをマージする方法を考え出す必要はありません。」
これは完全なスクリプトです。次の処理を実行します。
- イメージ リスト テキスト ファイルとプロセス番号を入力として受け取ります
- 必要な速度でそれらをダウンロードします
- ファイルのダウンロードにかかった合計時間を出力します
- ファイル名を読み取り、エラーなどを処理するのに役立つ便利な関数もいくつかあります。
# -*- coding: utf-8 -*-
import io
import random
import shutil
import sys
from multiprocessing.pool import ThreadPool
import pathlib
import requests
from PIL import Image
import time
start = time.time()
def get_download_location():
try:
url_input = sys.argv[1]
except IndexError:
print('ERROR: Please provide the txt file\n$python image_downloader.py cats.txt')
name = url_input.split('.')[0]
pathlib.Path(name).mkdir(parents=True, exist_ok=True)
return name
def get_urls():
"""
通过读取终端中作为参数提供的 txt 文件返回 url 列表
"""
try:
url_input = sys.argv[1]
except IndexError:
print('ERROR: Please provide the txt file\n Example \n\n$python image_downloader.py dogs.txt \n\n')
sys.exit()
with open(url_input, 'r') as f:
images_url = f.read().splitlines()
print('{} Images detected'.format(len(images_url)))
return images_url
def image_downloader(img_url: str):
"""
输入选项:
参数: img_url str (Image url)
尝试下载图像 url 并使用标题中提供的名称。否则它会随机选择一个名字
"""
print(f'Downloading: {img_url}')
res = requests.get(img_url, stream=True)
count = 1
while res.status_code != 200 and count これを Python の複数のスレッドで同時に画像をダウンロードする方法 の複数のスレッドで同時に画像をダウンロードする方法 ファイルに保存して実行します。
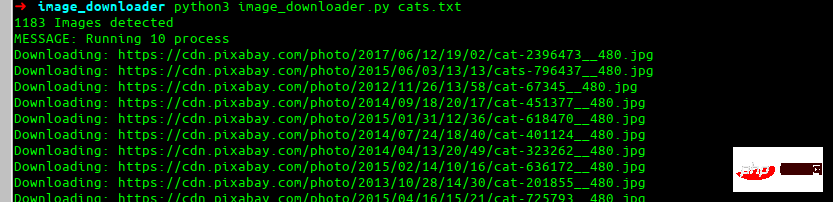
python3 image_downloader.py cats.txt
これは GitHub リポジトリへのリンクです。
使用方法
python3 image_downloader.py <filename_with_urls_seperated_by_newline.txt> <num_of_process></num_of_process></filename_with_urls_seperated_by_newline.txt>
これにより、テキスト ファイル内のすべての URL が読み取られ、ファイル名と同じ名前のフォルダーにダウンロードされます。
num_of_process はオプションです (デフォルトでは 10 プロセスが使用されます)。
python3 image_downloader.py cats.txt
##これを改善する方法についてのアドバイスを喜んで提供させていただきますさらに反応する。 
英語の元のアドレス: https://betterprogramming.pub/building-an-imagedownloader-with-multiprocessing-in-python-44aee36e0424
[関連する推奨事項:
Python の複数のスレッドで同時に画像をダウンロードする方法 の複数のスレッドで同時に画像をダウンロードする方法3 ビデオ チュートリアル ##]
以上がPython の複数のスレッドで同時に画像をダウンロードする方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。