
ホームページ >バックエンド開発 >Python チュートリアル >Python クローラーは Web ページのデータをクロールし、データを解析します
Python クローラーは Web ページのデータをクロールし、データを解析します

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2022-08-15 18:25:467991ブラウズ
この記事では、Python に関する関連知識をお届けします。主に、Python クローラーがどのように Web ページ データをクロールし、データを解析して、クローラーをより効果的に使用して Web ページを分析できるかを紹介します。一緒にやってみましょう。見てください、それが皆さんのお役に立てば幸いです。

Python3 ビデオ チュートリアル ]
1. Web クローラーの基本概念
Web クローラー (Web スパイダーおよびロボットとも呼ばれます) は、クライアントがネットワーク リクエストを送信し、リクエスト応答を受信することをシミュレートし、特定のルールに従ってインターネット情報を自動的に取得するプログラムです。ブラウザができることであれば、原理的にはクローラでもできます。
2. Web クローラーの機能
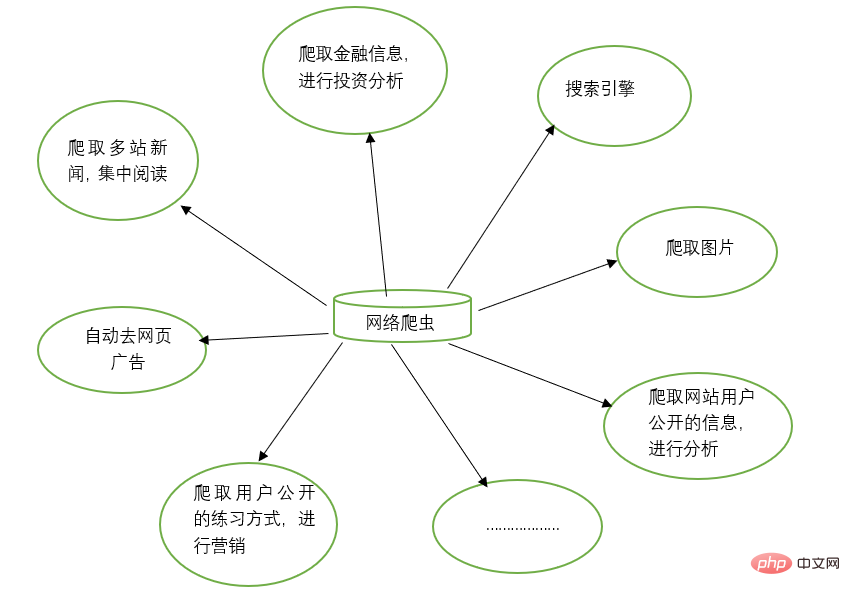
3. サードパーティ ライブラリのインストール
データをクロールしてデータを解析する前に、Python 実行環境にサードパーティ ライブラリ リクエストをダウンロードしてインストールする必要があります。 Windows システムでは、cmd (コマンド プロンプト) インターフェイスを開き、インターフェイスに pip install リクエストを入力し、Enter キーを押してインストールします。 (ネットワーク接続に注意してください) 以下に示すように
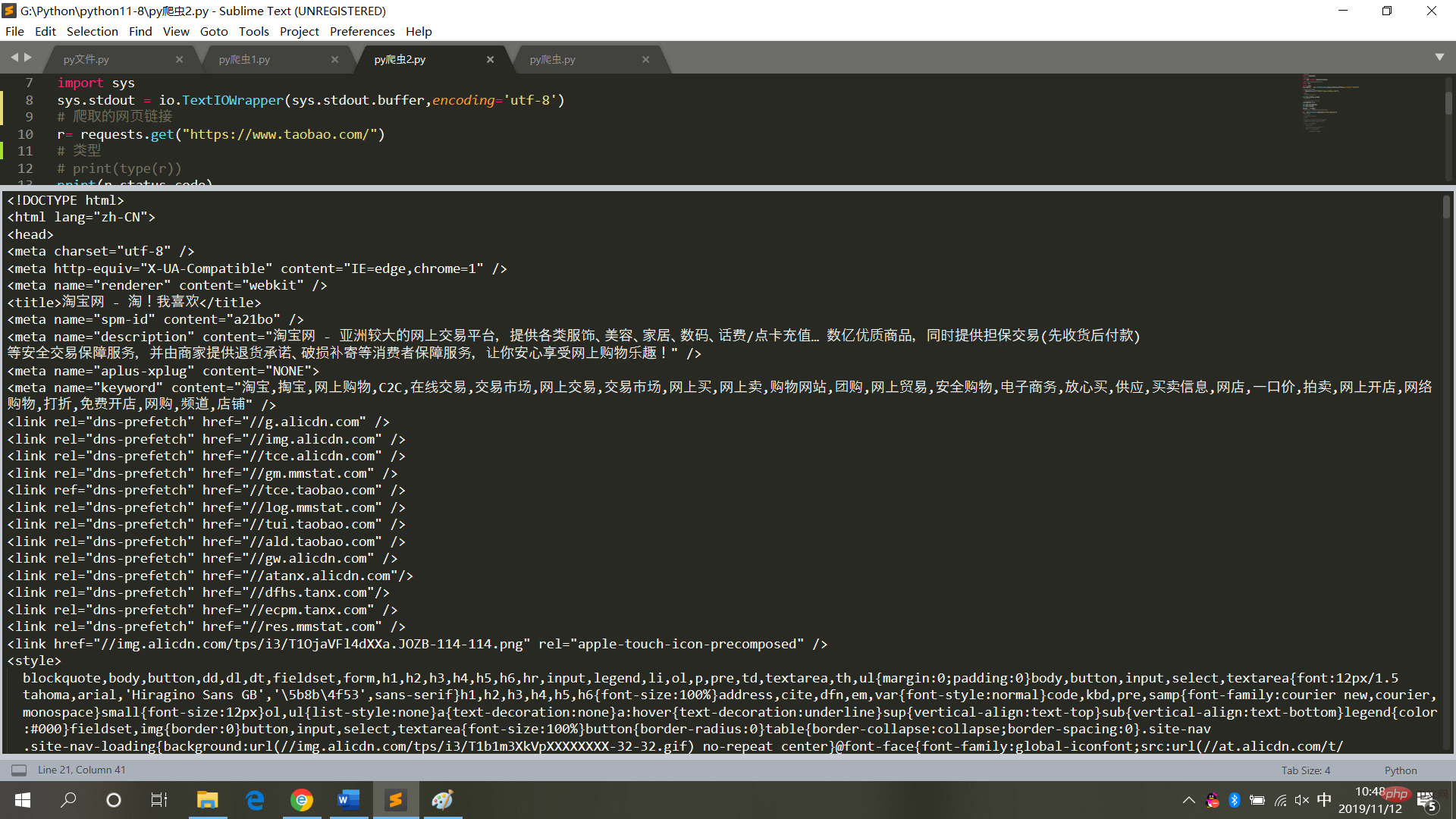
4. タオバオのホームページをクロールします# 请求库
import requests
# 用于解决爬取的数据格式化
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
# 爬取的网页链接
r= requests.get("https://www.taobao.com/")
# 类型
# print(type(r))
print(r.status_code)
# 中文显示
# r.encoding='utf-8'
r.encoding=None
print(r.encoding)
print(r.text)
result = r.text
実行結果は図に示すとおりです
5. クロールタオバオのホームページを解析します# 请求库
import requests
# 解析库
from bs4 import BeautifulSoup
# 用于解决爬取的数据格式化
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
# 爬取的网页链接
r= requests.get("https://www.taobao.com/")
# 类型
# print(type(r))
print(r.status_code)
# 中文显示
# r.encoding='utf-8'
r.encoding=None
print(r.encoding)
print(r.text)
result = r.text
# 再次封装,获取具体标签内的内容
bs = BeautifulSoup(result,'html.parser')
# 具体标签
print("解析后的数据")
print(bs.span)
a={}
# 获取已爬取内容中的script标签内容
data=bs.find_all('script')
# 获取已爬取内容中的td标签内容
data1=bs.find_all('td')
# 循环打印输出
for i in data:
a=i.text
print(i.text,end='')
for j in data1:
print(j.text)
図
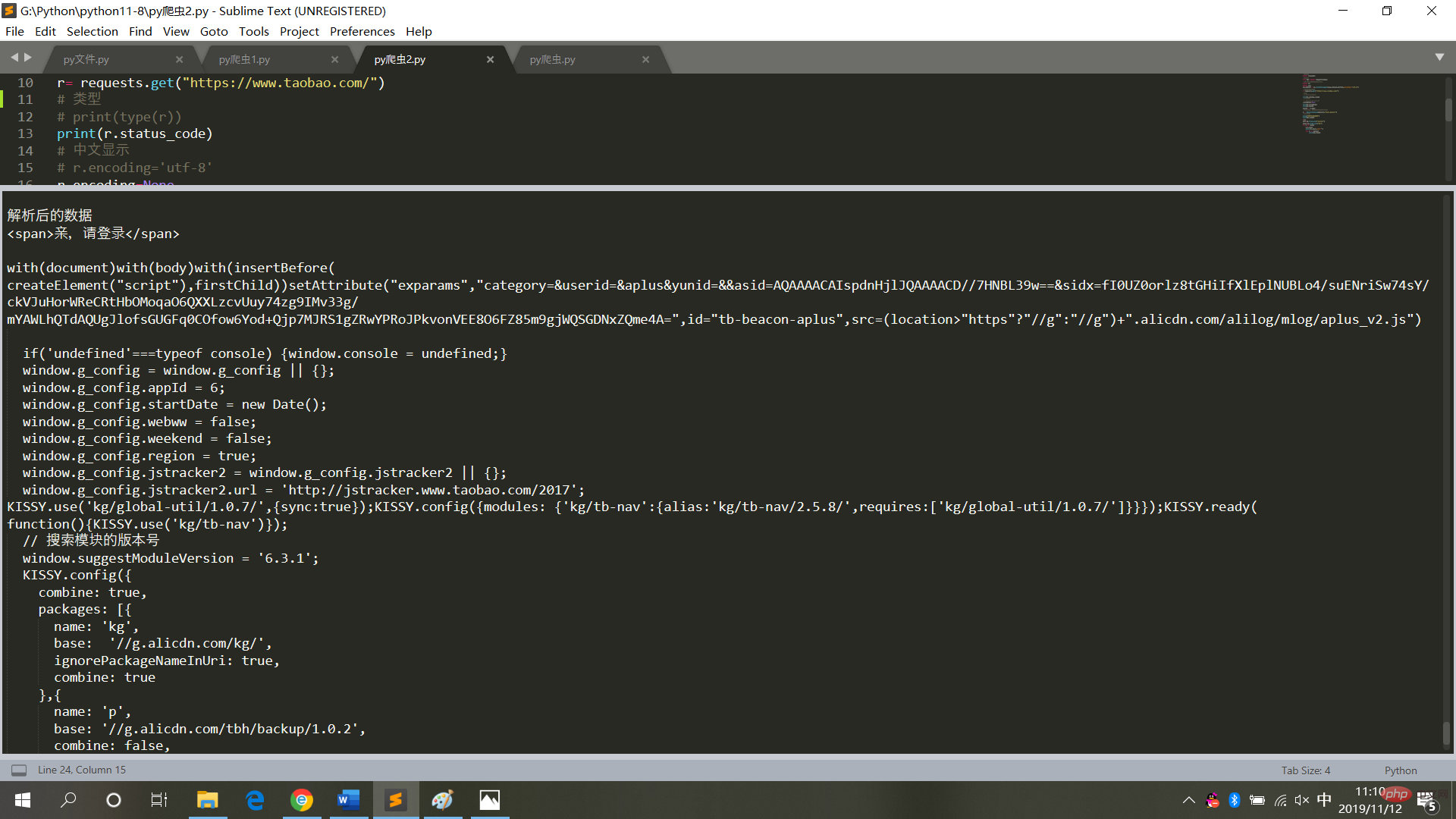
6に示すように、実行結果が表示されます。 Web ページのコードをクロールするときは、頻繁に操作を行わず、無限ループ モードに設定しないでください (各クロールは Web ページへのアクセスであり、頻繁に操作するとシステムがクラッシュし、法的責任が発生します)追求される)。
したがって、Web ページ データを取得した後、それをローカル テキスト モードで保存し、解析します (Web ページにアクセスする必要はなくなります)。 【関連する推奨事項:Python3 ビデオ チュートリアル
]以上がPython クローラーは Web ページのデータをクロールし、データを解析しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
声明:
この記事はjb51.netで複製されています。侵害がある場合は、admin@php.cn までご連絡ください。