
ホームページ >Java >&#&チュートリアル >Java ベースの複雑な関係式フィルターを実装する例の紹介
Java ベースの複雑な関係式フィルターを実装する例の紹介

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2022-08-01 14:56:321674ブラウズ
この記事では、java に関する関連知識を提供し、主に Java ベースの複雑な関係式フィルターを実装する方法を詳しく紹介します。記事内でサンプルコードを詳しく解説していますので、ぜひ参考にしてみてください。

おすすめの学習: 「java ビデオ チュートリアル 」
背景
最近、新たなニーズがあり、バックグラウンドで複雑な関係式を設定し、ユーザーが指定したIDに基づいてユーザーが条件を満たすかどうかを分析する バックグラウンドではZenTao

と同様の検索条件を設定しますが、異なるはい、Zen Tao には 2 つのグループしかなく、各グループには最大 3 つの条件があります
。ただし、ここでのグループと関係はより複雑になる可能性があります。グループの中にグループがあり、各条件は「はい」ですおよびまたは。関係。機密保持上の理由により、プロトタイプは公開されません。
この要件をバックエンドとして見ると、最初に思い浮かぶのは QLEpress のような式フレームワークです。式を構築する限り、式を解析することで対象ユーザーをすばやくフィルタリングできます。フロントエンドの同級生が辞めたのは残念ですが、VueやReactを使ったデータドリブンフレームワークとしては式を上記の形に変換するのは難しすぎるので、考えて自分でデータ構造を定義することにしました. 、式の解析を実装します。フロントエンドの学生が処理するのに便利です。
分析の準備
式はクラスを使用して実装されていますが、本質的には式です。簡単な式を列挙してみましょう: 条件を a, b, c, d とすると、自由に式を作成します:
boolean result=a>100 && b=10 || (c != 3 && d
式を実行すると、すべての式に共通の属性があることがわかります:
フィルター フィールド (a、b、c、d)、判定条件 (より大きい、より小さい)より大きい、等しくないなど)、比較値 (100 のうち a>100)。
さらに、関連関係(and、or)や計算優先度などの属性もいくつかあります。
そこで、式を簡略化します。
Let a>100 =>A,b=10 =>B,c!=3=>C ,d1f95226a8acdafab5dc28f716ab5c5e4 D なので、次のようになります:
result=A && B || (C && D)
ここで問題は、優先順位をどのように扱うかということです。
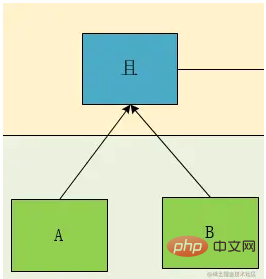
##上記の式は明らかに大学で学んだ標準的な順序式なので、その樹形図を描いてみましょう: 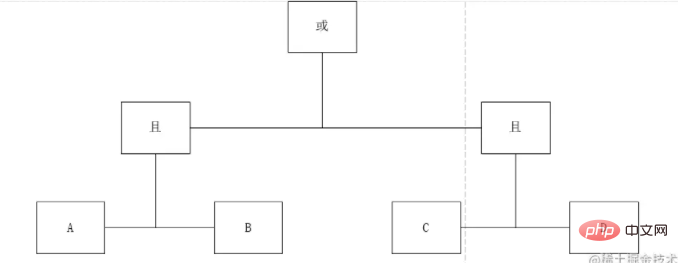 #この図によると、はっきりとわかります。 A と B、C と D は同じレベルにあります。したがって、この理論に従って階層概念 Deep を設計します。それをマークし、ノード タイプを実行します。区別後、次の結果が得られます:
#この図によると、はっきりとわかります。 A と B、C と D は同じレベルにあります。したがって、この理論に従って階層概念 Deep を設計します。それをマークし、ノード タイプを実行します。区別後、次の結果が得られます:
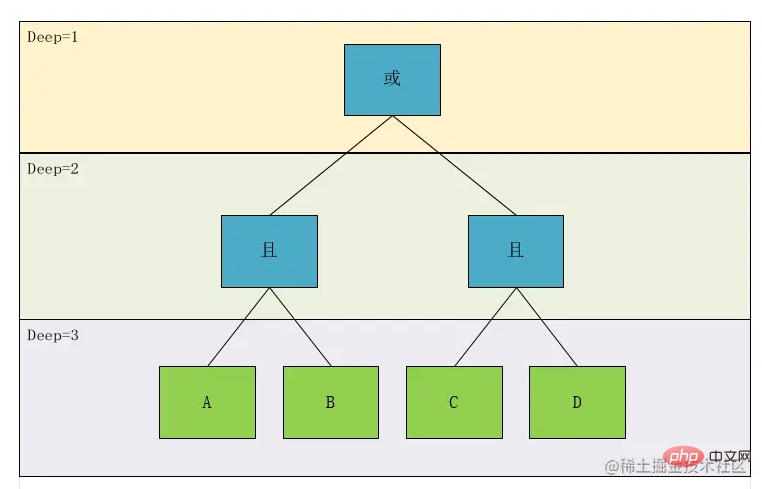 リーフ ノード (上図の緑色の部分) として、その計算計算関係に関連して、それに遭遇した場合、最初に計算する必要があることがわかります。では、非リーフ ノード、つまり上図の青いノード部分のみを考慮する必要があるため、
リーフ ノード (上図の緑色の部分) として、その計算計算関係に関連して、それに遭遇した場合、最初に計算する必要があることがわかります。では、非リーフ ノード、つまり上図の青いノード部分のみを考慮する必要があるため、
を計算する概念は式 Depth## に変換できることがわかります。 #。 上の図をもう一度見てみましょう。Deep1 間の関係は、Deep2 の 2 つの式 A と B および C と D で計算された結果の AND または関係です。A と B を G1 に設定します。 C と D は G2 であるため、リレーションシップ ノードの関連付けには 2 種類あることがわかります。1 つは Condition
Condition で、もう 1 つはGroupGroup## です。
#この時点で、このクラスのプロトタイプはほぼ決まります。このクラスには、関連関係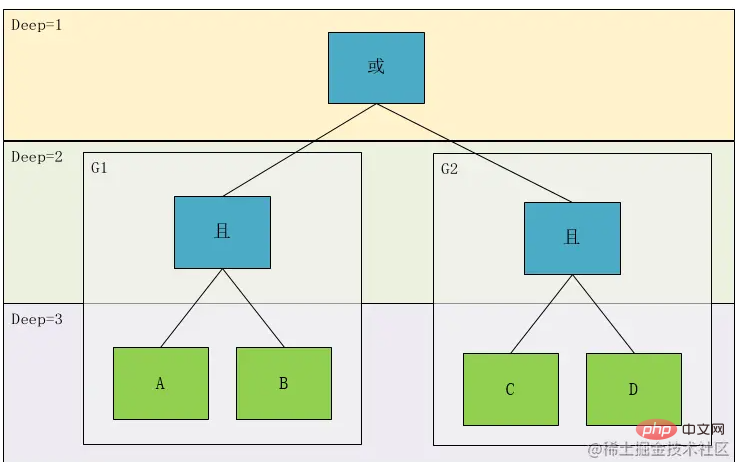 (Relation)、
(Relation)、
(Field)、Operator (Operator)、操作値(Values)、Type# #が含まれます。 #(Type), Depth(Deep)しかし、問題があります。上記の分析では、式をツリーに変換しています。次に、それを復元しようとします。式の 1 つを一目で取得できます: result=(A && B)||(C && D)
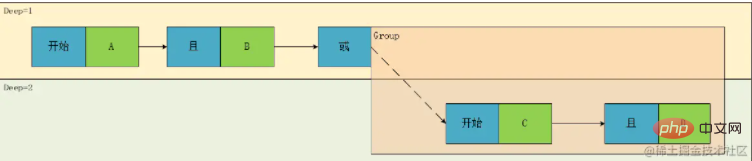
明らかに、これは元の式と一致しません。これは、上記の式の計算順序を記録することしかできず、この式を完全に正確に表現することはできないためです。これは、式 In を解析する過程で、は深さだけではなく、タイミングの関係、つまり左から右への連続表現も考慮されます このとき、G1 の内容は本来の表現では深さ 2 ではなく 1 になるはずです そこで、 の概念を導入します。シーケンス番号。元のツリーを有向グラフに変換します:
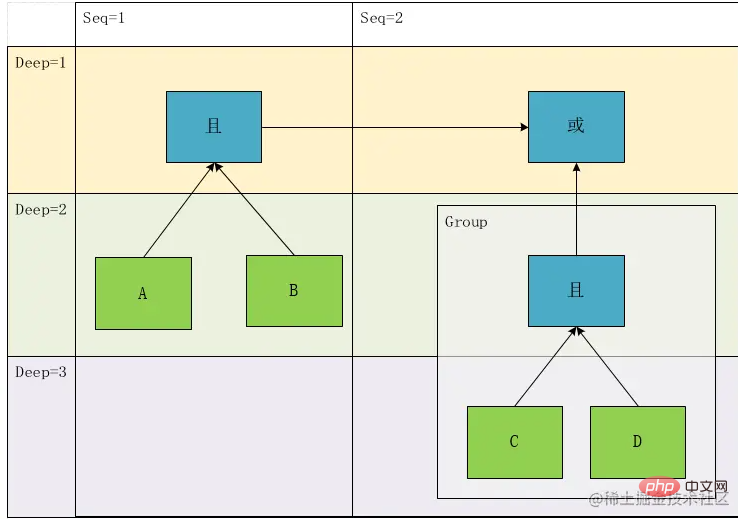
このグラフによれば、唯一の式を復元できます: result= A && B ||(C && D)。
さて、長い間分析してきましたが、原理の説明が終わったので、元の質問に戻りましょう: フロントエンドとバックエンドを実装する方法?上の写真を見ると、まだ構造が複雑すぎて扱いきれないように思えます。フロントエンドではデータの走査が容易である必要があり、バックエンドではデータの処理が容易である必要があるため、この時点では上記の図を配列に変換する必要があります。
実装方法
上記の通り、配列構造が必要なので、この部分を詳しく分析してみましょう
リーフ ノードは常に最初に評価できるため、これを圧縮して式の 1 つに関係を配置して ^A -> &&B または A&& -> B$ を形成できます。 , ここでは、通常の start(^) と end($) を使用して開始と終了の概念を表現しています。製品プロトタイプとの一貫性を保つために、最初の方法を使用します。つまり、関係記号は前の要素との関係を表すため、それを再分析します:
そして、シーケンス番号を変換します:
最終的なデータ構造を取得します:
@Data
@AllArgsConstructor
@NoArgsConstructor
@Accessors(chain = true)
public class ExpressDto {
/**
* 序号
*/
private Integer seq;
/**
* 深度(运算优先级)
*/
private Integer deep;
/**
* 关系运算符
*/
private String relation;
/**
* 类型
*/
private String type;
/**
* 运算条件
*/
private String field;
/**
* 逻辑运算符
*/
private String operator;
/**
* 运算值
*/
private String values;
/**
* 运算结果
*/
private Boolean result;
}これで、ストレージに便利で、フロントエンド表示にも (比較的) 便利なデータ構造が完成しました。もう少し複雑な式を作成します
A &&(( B || C )|| (D && E)) && F
配列オブジェクトに変更します。 BEGIN、式の種類は CONDITION で表され、グループは GROUP Express で表されます。
[
{"seq":1,"deep":1,relation:"BEGIN","type":"CONDITION","field"="A"...},
{"seq":2,"deep":1,relation:"AND","type":"GROUP","field":""...},
{"seq":3,"deep":2,relation:"BEGIN","type":"GROUP","field":""...},
{"seq":4,"deep":3,relation:"BEGIN","type":"CONDITION","field":"B"...},
{"seq":5,"deep":3,relation:"OR","type":"CONDITION","field":"C"...},
{"seq":6,"deep":2,relation:"OR","type":"GROUP","field":""...},
{"seq":7,"deep":3,relation:"BEGIN","type":"CONDITION","field":"D"...},
{"seq":8,"deep":3,relation:"AND","type":"CONDITION","field":"E"...},
{"seq":9,"deep":1,relation:"AND","type":"CONDITION","field":"F"...}
]最後の質問が残っています: この json を通じてデータをフィルタリングする方法
配列オブジェクトの本質は依然として中置式であるため、その本質は依然として中置式です 式の解析解析原理については、ここではあまり紹介しません。簡単に言うと、括弧 (この場合はグループと呼ばれます) に従ってデータ スタックとシンボル スタックを横断します。さらに詳しく知りたい場合は、次の方法で確認できます。
したがって、3 つの変数を定義します:
//关系 栈 Deque<String> relationStack=new LinkedList(); //结果栈 Deque<Boolean> resultStack=new LinkedList(); // 当前深度 Integer nowDeep=1;
配列を走査することにより、関係と結果がスタックにプッシュされます。優先順位の計算が必要であることが判明した場合、2値は結果スタックから取得され、関係は次のようになります。 関係演算子をスタックから取り出し、計算後に再度スタックにプッシュし、次の計算を待ちます。
for (ExpressDto expressDto:list) {
if(!StringUtils.equals(expressDto.getType(),"GROUP")){
//TODO 进行具体单个表达式计算并获取结果
resultStack.push(expressDto.getResult());
// 将关系放入栈中
relationStack.push(expressDto.getRelation());
if(deep==0 && resultStack.size()>1){ //由于已处理小于0的deep,当前deep理论上是>=0的,0表示同等级,需要立即运算
relationOperator(relationStack, resultStack);
}
}else{
// 将关系放入栈中
relationStack.push(expressDto.getRelation());
}
}
private void relationOperator(Deque<String> relationStack, Deque<Boolean> resultStack) {
Boolean lastResult= resultStack.pop();
Boolean firstResult= resultStack.pop();
String relation=relationStack.pop();
if(StringUtils.equals(relation,"AND")){
resultStack.push(firstResult&& lastResult) ;
return;
}
if(StringUtils.equals(relation,"OR")){
resultStack.push( firstResult|| lastResult);
return;
}else{
throw new RuntimeException("表达式解析异常:关系表达式错误");
}
}について話しましょう。境界に関する注意事項:
1. まず、同じレベルの関連関係は と またはその両方のみが存在し、両者の計算優先順位は同じです。したがって、同じ Deep の下で、左から右にトラバースして計算するだけです。
2. GROUP 型に遭遇した場合、それは "(" に遭遇したことと同等であり、その背後にある要素が Deep 1 から Deep -1 までであり、")" で終わることがわかります。また、括弧内の要素は計算、つまり "()" によって生成される優先度は Deep と Type=GROUP
3 によって共同で制御されます。Deep が減少するということは、")" に遭遇したことを意味します。終了したグループの数は Deep によって減らされた数に等しい。「)」の終わりについては、「)」に遭遇するたびに括弧のレベルをチェックして、同じレベルの要素が同じかどうかを確認する必要がある。計算されている。
/**
* 处理层级遗留元素
*
* @param relationStack
* @param resultStack
*/
private void computeBeforeEndGroup(Deque<String> relationStack, Deque<Boolean> resultStack) {
boolean isBeginSymbol=StringUtils.equals(relationStack.peek(),"BEGIN");//防止group中仅有一个判断条件
while(!isBeginSymbol){//上一个运算符非BEGIN,说明该group中还有运算需要优先处理,正常这里应该仅循环一次
relationOperator(relationStack, resultStack);
isBeginSymbol=StringUtils.equals(relationStack.peek(),"BEGIN");
}
if(isBeginSymbol){
relationStack.pop();//该优先级处理完毕,将BEGIN运算符弹出
}
}4. トラバースが終了し、最後の要素 Deep が 1 に等しくないことが判明した場合、それは括弧の終わりがあることを意味します。このとき、括弧の終わりも指定する必要があります。処理済み
最後に、完全なコード:
/**
* 表达式解析器
* 表达式规则:
* 关系relation属性有:BEGIN、AND、OR 三种
* 表达式类型 Type 属性有:GROUP、CONDITION 两种
* 深度 deep 属性 根节点为 1,每增加一个括号(GROUP)deep+1,括号结束deep-1
* 序号req:初始值为1,往后依次递增,用于防止表达式解析顺序错误
* exp1:表达式:A &&(( B || C )|| (D && E)) && F
* 分解对象:
* [
* {"seq":1,"deep":1,relation:"BEGIN","type":"CONDITION","field"="A"...},
* {"seq":2,"deep":1,relation:"AND","type":"GROUP","field":""...},
* {"seq":3,"deep":2,relation:"BEGIN","type":"GROUP","field":""...},
* {"seq":4,"deep":3,relation:"BEGIN","type":"CONDITION","field":"B"...},
* {"seq":5,"deep":3,relation:"OR","type":"CONDITION","field":"C"...},
* {"seq":6,"deep":2,relation:"OR","type":"GROUP","field":""...},
* {"seq":7,"deep":3,relation:"BEGIN","type":"CONDITION","field":"D"...},
* {"seq":8,"deep":3,relation:"AND","type":"CONDITION","field":"E"...},
* {"seq":9,"deep":1,relation:"AND","type":"CONDITION","field":"F"...}
* ]
*
* exp2:(A || B && C)||(D && E && F)
* [
* {"seq":1,"deep":1,relation:"BEGIN","type":"GROUP","field":""...},
* {"seq":2,"deep":2,relation:"BEGIN","type":"CONDITION","field":"A"...},
* {"seq":3,"deep":2,relation:"OR","type":"CONDITION","field":"B"...},
* {"seq":4,"deep":2,relation:"AND","type":"CONDITION","field":"C"...},
* {"seq":5,"deep":1,relation:"OR","type":"GROUP","field":""...},
* {"seq":6,"deep":2,relation:"BEGIN","type":"CONDITION","field":"D"...},
* {"seq":7,"deep":2,relation:"AND","type":"CONDITION","field":"E"...},
* {"seq":8,"deep":2,relation:"AND","type":"CONDITION","field":"F"...}
* ]
*
*
* @param list
* @return
*/
public boolean expressProcessor(Listlist){
//关系 栈
Deque relationStack=new LinkedList();
//结果栈
Deque resultStack=new LinkedList();
// 当前深度
Integer nowDeep=1;
Integer seq=0;
for (ExpressDto expressDto:list) {
// 顺序检测,防止顺序错误
int checkReq=expressDto.getSeq()-seq;
if(checkReq!=1){
throw new RuntimeException("表达式异常:解析顺序异常");
}
seq=expressDto.getSeq();
//计算深度(计算优先级),判断当前逻辑是否需要处理括号
int deep=expressDto.getDeep()-nowDeep;
// 赋予当前深度
nowDeep=expressDto.getDeep();
//deep 减小,说明有括号结束,需要处理括号到对应的层级,deep减少数量等于组(")")结束的数量
while(deep++ < 0){
computeBeforeEndGroup(relationStack, resultStack);
}
if(!StringUtils.equals(expressDto.getType(),"GROUP")){
//TODO 进行具体单个表达式计算并获取结果
resultStack.push(expressDto.getResult());
// 将关系放入栈中
relationStack.push(expressDto.getRelation());
if(deep==0 && resultStack.size()>1){ //由于已处理小于0的deep,当前deep理论上是>=0的,0表示同等级,需要立即运算
relationOperator(relationStack, resultStack);
}
}else{
// 将关系放入栈中
relationStack.push(expressDto.getRelation());
}
}
//遍历完毕,处理栈中未进行运算的节点
while(nowDeep-- > 0){ // 这里使用 nowdeep>0 的原因是最后deep=1的关系表达式也需要进行处理
computeBeforeEndGroup(relationStack, resultStack);
}
if(resultStack.size()!=1){
throw new RuntimeException("表达式解析异常:解析结果数量异常解析数量:"+resultStack.size());
}
return resultStack.pop();
}
/**
* 处理层级遗留元素
*
* @param relationStack
* @param resultStack
*/
private void computeBeforeEndGroup(Deque<String> relationStack, Deque<Boolean> resultStack) {
boolean isBeginSymbol=StringUtils.equals(relationStack.peek(),"BEGIN");//防止group中仅有一个判断条件
while(!isBeginSymbol){//上一个运算符非BEGIN,说明该group中还有运算需要优先处理,正常这里应该仅循环一次
relationOperator(relationStack, resultStack);
isBeginSymbol=StringUtils.equals(relationStack.peek(),"BEGIN");
}
if(isBeginSymbol){
relationStack.pop();//该优先级处理完毕,将BEGIN运算符弹出
}
}
/**
* 关系运算处理
* @param relationStack
* @param resultStack
*/
private void relationOperator(Deque relationStack, Deque resultStack) {
Boolean lastResult= resultStack.pop();
Boolean firstResult= resultStack.pop();
String relation=relationStack.pop();
if(StringUtils.equals(relation,"AND")){
resultStack.push(firstResult&& lastResult) ;
return;
}
if(StringUtils.equals(relation,"OR")){
resultStack.push( firstResult|| lastResult);
return;
}else{
throw new RuntimeException("表达式解析异常:关系表达式错误");
}
} いくつかのテスト ケースを単純に書きました:
/**
* 表达式:A
*/
@Test
public void expTest0(){
ExpressDto E1=new ExpressDto().setDeep(1).setResult(false).setSeq(1).setType("CONDITION").setField("A").setRelation("BEGIN");
List<ExpressDto> list = new ArrayList();
list.add(E1);
boolean re=expressProcessor(list);
Assertions.assertFalse(re);
}
/**
* 表达式:(A && B)||(C || D)
*/
@Test
public void expTest1(){
ExpressDto E1=new ExpressDto().setDeep(1).setSeq(1).setType("GROUP").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(2).setResult(true).setSeq(2).setType("Condition").setField("A").setRelation("BEGIN");
ExpressDto E3=new ExpressDto().setDeep(2).setResult(false).setSeq(3).setType("Condition").setField("B").setRelation("AND");
ExpressDto E4=new ExpressDto().setDeep(1).setSeq(4).setType("GROUP").setRelation("OR");
ExpressDto E5=new ExpressDto().setDeep(2).setResult(true).setSeq(5).setType("Condition").setField("C").setRelation("BEGIN");
ExpressDto E6=new ExpressDto().setDeep(2).setResult(false).setSeq(6).setType("Condition").setField("D").setRelation("OR");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
list.add(E3);
list.add(E4);
list.add(E5);
list.add(E6);
boolean re=expressProcessor(list);
Assertions.assertTrue(re);
}
/**
* 表达式:A && (B || C && D)
*/
@Test
public void expTest2(){
ExpressDto E1=new ExpressDto().setDeep(1).setResult(true).setSeq(1).setType("Condition").setField("A").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(1).setSeq(2).setType("GROUP").setRelation("AND");
ExpressDto E3=new ExpressDto().setDeep(2).setResult(false).setSeq(3).setType("Condition").setField("B").setRelation("BEGIN");
ExpressDto E4=new ExpressDto().setDeep(2).setResult(false).setSeq(4).setType("Condition").setField("C").setRelation("OR");
ExpressDto E5=new ExpressDto().setDeep(2).setResult(true).setSeq(5).setType("Condition").setField("D").setRelation("AND");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
list.add(E3);
list.add(E4);
list.add(E5);
boolean re=expressProcessor(list);
Assertions.assertFalse(re);
E4.setResult(true);
list.set(3,E4);
re=expressProcessor(list);
Assertions.assertTrue(re);
E1.setResult(false);
list.set(0,E1);
re=expressProcessor(list);
Assertions.assertFalse(re);
}
@Test
public void expTest3(){
ExpressDto E1=new ExpressDto().setDeep(1).setResult(true).setSeq(1).setType("Condition").setField("A").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(1).setSeq(2).setType("GROUP").setRelation("OR");
ExpressDto E3=new ExpressDto().setDeep(2).setResult(true).setSeq(3).setType("Condition").setField("B").setRelation("BEGIN");
ExpressDto E4=new ExpressDto().setDeep(2).setSeq(4).setType("GROUP").setRelation("AND");
ExpressDto E5=new ExpressDto().setDeep(3).setResult(true).setSeq(5).setType("Condition").setField("C").setRelation("BEGIN");
ExpressDto E6=new ExpressDto().setDeep(3).setResult(false).setSeq(6).setType("Condition").setField("D").setRelation("OR");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
list.add(E3);
list.add(E4);
list.add(E5);
list.add(E6);
boolean re=expressProcessor(list);
Assertions.assertTrue(re);
}
/**
* 表达式:A &&(( B || C )|| (D && E))
*/
@Test
public void expTest4(){
ExpressDto E1=new ExpressDto().setDeep(1).setSeq(1).setType("CONDITION").setResult(true).setField("A").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(1).setSeq(2).setType("GROUP").setRelation("AND");
ExpressDto E3=new ExpressDto().setDeep(2).setSeq(3).setType("GROUP").setRelation("BEGIN");
ExpressDto E4=new ExpressDto().setDeep(3).setSeq(4).setType("CONDITION").setResult(true).setField("B").setRelation("BEGIN");
ExpressDto E5=new ExpressDto().setDeep(3).setSeq(5).setType("CONDITION").setResult(true).setField("C").setRelation("OR");
ExpressDto E6=new ExpressDto().setDeep(2).setSeq(6).setType("GROUP").setRelation("OR");
ExpressDto E7=new ExpressDto().setDeep(3).setSeq(7).setType("CONDITION").setResult(false).setField("D").setRelation("BEGIN");
ExpressDto E8=new ExpressDto().setDeep(3).setSeq(8).setType("CONDITION").setResult(false).setField("E").setRelation("AND");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
list.add(E3);
list.add(E4);
list.add(E5);
list.add(E6);
list.add(E7);
list.add(E8);
boolean re=expressProcessor(list);
Assertions.assertTrue(re);
}
/**
* 表达式:(A)
*/
@Test
public void expTest5(){
ExpressDto E1=new ExpressDto().setDeep(1).setSeq(1).setType("GROUP").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(2).setResult(true).setSeq(2).setType("Condition").setField("A").setRelation("BEGIN");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
boolean re=expressProcessor(list);
Assertions.assertTrue(re);
E2.setResult(false);
list.set(1,E2);
Assertions.assertFalse(expressProcessor(list));
}テスト結果:
最後に記述します
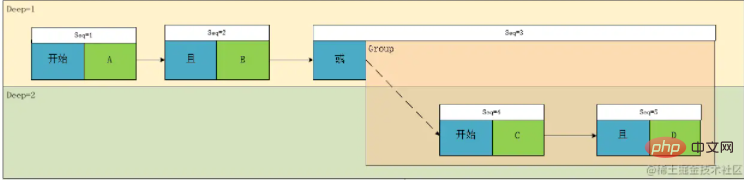
この時点で、1 つの式の解析が完了しました。戻ってこの図をもう一度見てみましょう:
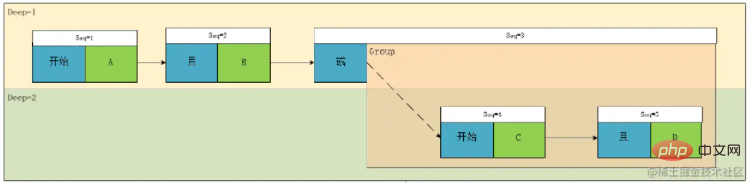
実際、Seq3 の機能は、グループの始まりを識別し、そのグループと同じレベルの他の要素との関連を記録することだけであることがわかります。実際、ここで最適化を実行できます。実際、このノードにグループの関連付けを配置し、Deep を増減することによってのみグループの関係を制御することを検討できます。 , we この型の式やグループのフィールドは不要になり、結果として配列の長さは短くなりますが、個人的には理解するのが少し面倒になると思います。変換の概要は次のとおりです。コードは公開されません。
- コード中の Type="GROUP" に関する判定を deep = の違いによる判定に変更します。 1
- 深さ判定プッシュロジックの修正
- 関係シンボルを格納する場合、この関係シンボルに対応する深さも格納する必要があります。
- 同じ深さのレガシー要素を処理する場合、
computeBeforeEndGroup( )このメソッドでは、元のメソッドでは、グループが処理されたかどうかを区別するために Begin 要素を使用していましたが、次のシンボルの深さが正しいかどうかを判断するために変更する必要があります。現在の深さと同じにし、BEGIN 要素のポップアップ ロジックを削除します
推奨学習: "Java ビデオ チュートリアル "
以上がJava ベースの複雑な関係式フィルターを実装する例の紹介の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。