
ホームページ >データベース >mysql チュートリアル >MySQL体系的分析のJOIN操作
MySQL体系的分析のJOIN操作

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2022-07-29 15:02:282017ブラウズ
この記事は、mysql に関する関連知識を提供します。主に、面倒な JOIN 操作について体系的に説明します。この記事では、JOIN 操作について体系的かつ詳細に説明します。実務経験と業界の古典的な事例への参照に基づいて、文法の簡素化とパフォーマンスの最適化のための方法論が的を絞って提案されており、皆様の参考になれば幸いです。

推奨学習: mysql ビデオ チュートリアル
序文
- ゼロから 1 まで経験しましたbefore スタートアップ プロジェクトや大規模データ プロジェクトもありますが、一般的に言えば、プロジェクトの発展に合わせて安全、信頼性、安定したデータ ストレージを構築する方法が常にプロジェクトの中核であり、最も重要で、最も重要な部分であり、そんなことはありません
- 次に、ストレージに関する一連の記事を体系的に出力します。この記事では、まず、データ内で最も面倒な接続操作の 1 つである JOIN
- JOIN について説明します。 SQL では常に長年の問題です。関連するテーブルが少しでも多くなると、コード記述は非常にエラーが発生しやすくなります。JOIN ステートメントの複雑さのため、関連するクエリは常に BI ソフトウェアの弱点でした。ビジネス ユーザーが複数のテーブルをスムーズに完了できる BI ソフトウェアはほとんどありません。 -テーブルの関連付け。お問い合わせください。パフォーマンスの最適化も同様で、関連するテーブルが多い場合やデータ量が多い場合、JOINのパフォーマンスを向上させるのは困難です
- 上記を踏まえ、本記事では体系的な最適化を実施していきます。 -私自身の実務経験と参考文献に基づいた JOIN 操作の詳細な説明。業界の古典的なケース、具体的には構文の簡素化とパフォーマンスの最適化のための方法論を提案しています。皆様のお役に立てば幸いです。
One画像の概要
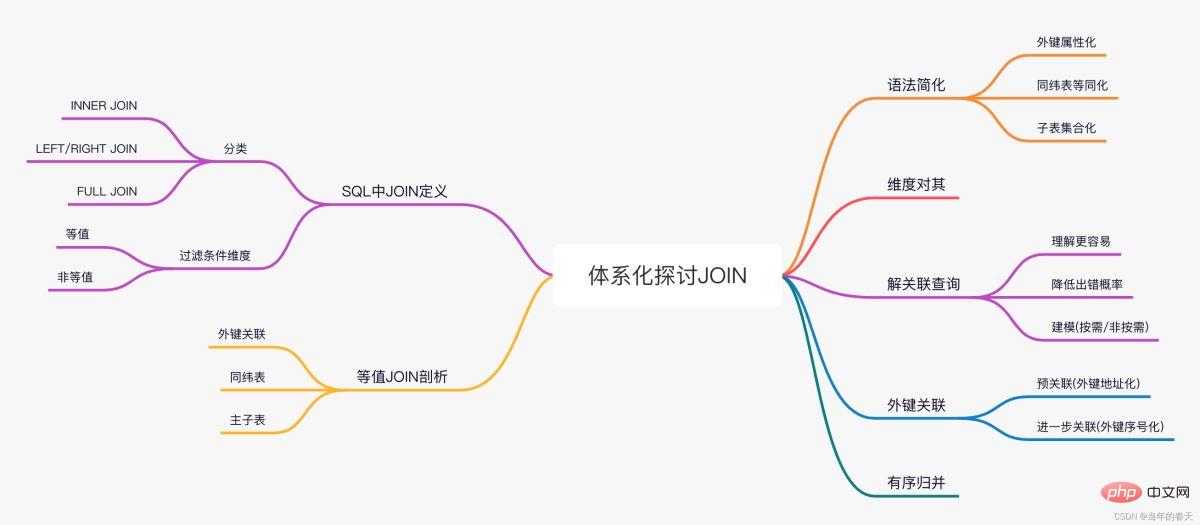
- 理論的には、デカルト積の結果セットは、2 つのセット メンバーで構成されるタプルである必要があります。ただし、SQL のセットはテーブルであるため、そのメンバーには常にフィールド レコードがあります。また、ジェネリック データ型は、メンバーがレコードであるタプルの記述がサポートされているため、結果セットは、2 つのテーブルのレコードのフィールドを結合することによって形成される新しいレコードのコレクションに単純に処理されます。
- これは英語の JOIN という言葉の本来の意味 (つまり、2 つのレコードのフィールドを結合する) であり、乗算 (デカルト積) を意味するものではありません。ただし、デカルト積メンバーがタプルとして理解されるか、マージされたフィールドのレコードとして理解されるかは、その後の議論に影響しません。
JOIN 定義
- JOIN の定義では、フィルター条件の形式は指定されません。理論的には、結果セットが次のデカルト積のサブセットである限り、 2 つのソース セットはすべて適切な JOIN 操作です。
- 例: セット A={1,2},B={1,2,3} の場合、A JOIN B ON A
JOIN の分類
- 等価のフィルタ条件を等価 JOIN と呼び、等価接続でない場合を非等価 JOIN と呼びます。これら 2 つの例のうち、前者は非等価 JOIN、後者は等価 JOIN です。
等しい値 JOIN
- 条件は AND 関係を持つ複数の方程式で構成されます。構文形式は A JOIN B ON A.ai=B.bi AND… です。ここで、ai と bi はそれぞれ A と B のフィールドです。
- 経験豊富なプログラマーは、実際には、JOIN の大部分が等価 JOIN であることを知っています。等価でない JOIN ははるかにまれで、ほとんどの場合は処理のために等価 JOIN に変換できます。そのため、ここでは等価 JOIN に焦点を当てます。以降の説明では、例としてセットやメンバーではなく、主にテーブルとレコードを使用します。
NULL 値処理ルールによる分類
- NULL 値処理ルールによると、厳密等価結合は INNER JOIN とも呼ばれ、LEFT JOIN から派生することもできます。 FULL JOIN を使用する 3 つの状況を示します (RIGHT JOIN は LEFT JOIN の逆の関連付けとして理解でき、別個のタイプではなくなりました)。
- JOIN について話すときは、一般的に、関連付けられたレコードの数に基づいて、1 対 1、1 対多、多対 1、多対多に分けられます (つまり、これらの一般的な用語は SQL やデータベースの資料で紹介されている場合があるため、ここでは繰り返しません。
JOIN の実装
愚かな方法
- 最も簡単に考えられる方法は、等しい JOIN を区別せずに、定義に従ってハードトラバーサルを行うことです。等しくない JOIN 値 JOIN。テーブル A に n レコード、テーブル B に m レコードがあるとすると、A JOIN B ON A.a=B.b を計算するには、ハードトラバーサルの計算量は nm となり、フィルタ条件の計算が nm 回行われることになります。
- 明らかに、このアルゴリズムは遅くなります。ただし、複数のデータ ソースをサポートするレポート ツールでは、この遅い方法を使用して関連付けを行うことがあります。これは、レポート内のデータ セットの関連付け (つまり、JOIN のフィルター条件) が分割され、次の計算式で定義されるためです。複数のデータ セット間の JOIN 操作であることはもはや分からないため、これらの関連する式を計算するにはトラバーサル メソッドのみを使用できます。
JOIN のデータベース最適化
- 同等の JOIN の場合、データベースは通常、HASH JOIN アルゴリズムを使用します。つまり、アソシエーション テーブル内のレコードは、アソシエーション キー (フィルタ条件の等しいフィールド、つまり A.a と B.b に対応) の HASH 値に従っていくつかのグループに分割され、レコードは同じ HASH 値は 1 つのグループにグループ化されます。 HASH 値の範囲が 1...k の場合、テーブル A と B は両方とも k 個のサブセット A1,...,Ak と B1,...,Bk に分割されます。 Aiに記録されている関連キーaのHASH値がi、Biに記録されている関連キーbのHASH値もiなので、それぞれAiとBiをトラバーサル接続するだけです。
- HASHが異なるとフィールド値も異なるはずなので、i!=jの場合、AiのレコードとBjのレコードを関連付けることはできません。 Aiのレコード数をni、Biのレコード数をmiとすると、フィルタ条件の計算回数はSUM(ni*mi)となり、最も平均的な場合、ni=n/k、mi=となります。 m/k、合計 複雑さは元のハード トラバーサル手法のわずか 1/k であり、コンピューティング パフォーマンスを効果的に向上させることができます。
- したがって、複数のデータ ソースの相関レポートを高速化したい場合は、データの準備段階でも相関を実行する必要があります。そうしないと、データ量が少し多くなったときにパフォーマンスが急激に低下します。
- ただし、HASH 関数は常に均等な分割を保証するものではなく、運が悪いと特定のグループが特に大きくなり、パフォーマンス向上効果が大幅に悪くなる可能性があります。また、複雑すぎる HASH 関数は使用できません。使用しないと、HASH の計算に時間がかかります。
- データ量がメモリを超えるほど大きい場合、データベースは HASH JOIN アルゴリズムを一般化した HASH ヒーピング方式を使用します。テーブル A と B を走査し、関連付けられたキーの HASH 値に従ってレコードをいくつかの小さなサブセットに分割し、Heaping と呼ばれる外部メモリにキャッシュします。次に、対応するヒープ間でメモリ JOIN 操作を実行します。同様に、HASH 値が異なる場合は、キー値も異なる必要があり、対応するヒープ間で関連付けが行われる必要があります。このようにして、大きなデータの JOIN が複数の小さなデータの JOIN に変換されます。
- しかし、同様に、HASH 関数にも運の問題があります。特定のヒープが大きすぎてメモリにロードできない場合があります。このとき、2 番目の HASH ヒープを実行する必要がある場合があります。大きすぎるヒープのグループに対して HASH ヒーピング アルゴリズムを再度実行します。したがって、外部メモリの JOIN 操作が複数回キャッシュされる可能性があり、その操作パフォーマンスはある程度制御できなくなります。
分散システムでの JOIN
- 分散システムでの JOIN も同様で、レコードは、関連付けられたキーの HASH 値に従って各ノード マシンに分散されます。 シャッフル アクション と呼ばれ、スタンドアロン JOIN を個別に実行します。
- ノード数が多い場合、ネットワーク伝送量による遅延が複数マシンのタスク共有のメリットを相殺してしまうため、分散データベースシステムでは通常、ノード数に制限が設けられています。 more ノードが増えてもパフォーマンスは向上しません。
等価 JOIN の分析
3 種類の等価 JOIN:
外部キー関連付け
- テーブル A の特定のフィールドは、テーブル B の主キー フィールドに関連付けられます (いわゆるフィールド関連付けとは、前のセクションで説明したように、等しいフィールドが等しい JOIN のフィルター条件に対応する必要があることを意味します)。テーブル A は ファクト テーブル と呼ばれ、テーブル B は ディメンション テーブル と呼ばれます。テーブル B の主キーに関連付けられているテーブル A のフィールドは、B を指す A の 外部キー と呼ばれます。B は、A の外部キー テーブルとも呼ばれます。
- ここで言う主キーとは、論理的な主キー、つまり、特定のレコードを一意に記録するために使用できる、テーブル内で一意の値を持つフィールド (グループ) を指します。データベーステーブルに主キーが確立されています。
- 外部キーテーブルは多対一の関係があり、JOINとLEFT JOINしかなく、FULL JOINは非常にまれです。
- 典型的なケース: 製品トランザクション テーブルと製品情報テーブル。
- 明らかに、外部キーの関連付けは非対称です。ファクト テーブルとディメンション テーブルの場所を交換することはできません。
同じディメンション テーブル
- テーブル A の主キーはテーブル B の主キーに関連付けられています。A と B は互いに呼ばれます。同じディメンション テーブル。同じディメンションのテーブルには 1 対 1 の関係があり、JOIN、LEFT JOIN、FULL JOIN がすべて存在しますが、ほとんどのデータ構造設計ソリューションでは FULL JOIN が使用されることは比較的まれです。
- 典型的なケース: 従業員テーブルとマネージャー テーブル。
- 同じディメンションのテーブルは対称であり、2 つのテーブルは同じステータスになります。同じディメンションを持つテーブルも等価関係を形成します。A と B は同じディメンションを持つテーブル、B と C は同じディメンションを持つテーブルです。すると、A と C も同じディメンションを持つテーブルになります。
マスターテーブルとサブテーブル
- テーブル A の主キーは、テーブル B の主キーの一部に関連付けられています。A は メイン テーブル#と呼ばれます。 ##、B は サブテーブル と呼ばれます。マスターと子テーブルは 1 対多の関係にあり、JOIN と LEFT JOIN のみがあり、FULL JOIN はありません。 典型的なケース: 注文と注文の詳細。
- メインテーブルとサブテーブルも非対称で方向性が明確です。
- SQL の概念体系では、外部キー テーブルとマスター子テーブルの区別はなく、多対 1 と 1 対多は SQL の観点からの関連付けの方向が異なるだけです。と本質的に同じものです。実際、注文は、注文の詳細の外部キー テーブルとして理解することもできます。ただし、ここではそれらを区別したいと思います。将来、構文を簡素化し、パフォーマンスを最適化するときに、別の手段が使用されます。
- これら 3 種類の JOIN は、等価 JOIN 状況の大部分をカバーしていると言えます。ビジネス上重要なほぼすべての等価 JOIN は、これら 3 つのカテゴリに属するとさえ言えます。等価 JOIN は、このうちに限定されます。 3 つの状況において、適応範囲はほとんど縮小されません。
- これら 3 種類の JOIN を注意深く調べた結果、すべての関連付けに主キーが含まれており、多対多の状況は存在しないことがわかりました。この状況は無視できますか? ######はい!多対多の同等の JOIN には、ビジネス上の意味はほとんどありません。
- 2 つのテーブルを結合するときに関連付けられたフィールドに主キーが含まれていない場合、多対多の状況が発生します。この場合、ほぼ確実に、これら 2 つのテーブルを結合したより大きなテーブルが存在します。ディメンションテーブルとして。たとえば、student テーブルと subject テーブルが JOIN されている場合、student テーブルと subject テーブルをディメンション テーブルとして使用する Grade テーブルが存在しますが、student テーブルと subject テーブルのみの JOIN にはビジネス上の意味はありません。
- SQL ステートメントを作成するときに多対多の状況が見つかった場合は、ステートメントが正しく記述されていない可能性が高くなります。または、データに問題があります。このルールは、JOIN エラーを排除するのに非常に効果的です。
- ただし、完全に確実なステートメントを使用せずに「ほぼ」と言ってきました。つまり、非常にまれなケースでは多対多もビジネス上意味があるということです。たとえば、SQL を使用して行列の乗算を実装する場合、多対多の等価な JOIN が発生しますが、具体的な記述方法は読者が補足できます。
- デカルト積の JOIN 定義とフィルタリングは実際に非常に単純であり、単純な意味合いはさらに拡張され、多対多の等価な JOIN や非等価な JOIN さえも含めることができます。ただし、あまりに単純な意味合いでは、最も一般的な同等の JOIN の操作特性を完全に反映することはできません。これにより、コードの作成や操作の実装時にこれらの機能を利用できなくなり、操作がより複雑になると (多数の関連テーブルやネストされた状況が含まれる)、作成や最適化が非常に困難になります。これらの機能を活用することで、よりシンプルな記述フォームを作成し、より効率的な計算パフォーマンスを得ることができます。これについては、次のコンテンツで徐々に説明します。
- まれなケースを含めるために、より一般的な形式で操作を定義するよりも、これらのケースを別の操作として定義する方が合理的です。
- JOIN 構文の簡素化
employee 员工表
id 员工编号
name 姓名
nationality 国籍
department 所属部门
department 部门表
id 部门编号
name 部门名称
manager 部门经理
- 従業員テーブルと部門テーブルの主キーは両方とも ID フィールドです。従業員テーブルの部門フィールドは部門テーブルを指す外部キーです。部門テーブルの管理者フィールドは外部キーです。従業員テーブルを指すキー (マネージャーも従業員であるため)。これは非常に従来型のテーブル構造設計です。
- ここで聞きたいのは、中国人のマネージャーがいる米国人の従業員は誰ですか? SQL で書かれたこれは 3 つのテーブルの JOIN ステートメントです。
SELECT A.*
FROM employee A
JOIN department B ON A.department=B.id
JOIN employee C ON B.manager=C.id
WHERE A.nationality='USA' AND C.nationality='CHN'
- まず、FROM 従業員を使用して従業員情報を取得し、次に従業員テーブルを部門と JOIN して従業員の情報を取得します。この部門テーブルと従業員テーブルをJOINして管理者の情報を取得する必要があるため、従業員テーブルは2回JOINする必要があります。区別するためにSQL文で別名を付ける必要があります。となり、文章全体が複雑になり、わかりにくくなります。
- 外部キー フィールドを、それに関連付けられたディメンション テーブル レコードとして直接理解する場合は、別の方法で記述することができます。
SELECT * FROM employee
WHERE nationality='USA' AND department.manager.nationality='CHN'
もちろん、これは標準の SQL ステートメントではありません。
- 2文目の太字部分は、現社員の「部門長の国籍」を示しています。外部キー フィールドをディメンション テーブルのレコードとして理解すると、ディメンション テーブルのフィールドは外部キーの属性として理解されます。Department.manager は「部門のマネージャー」であり、このフィールドは依然として外部キーです。部門のキー、次に対応するディメンション テーブルのレコード フィールドは引き続きその属性として理解でき、また、Department.manager.nationality、つまり「所属する部門のマネージャーの国籍」も存在します。 。
- 外部キー属性: このオブジェクトに似た理解方法は外部キー属性であり、明らかにデカルト積フィルタリングの理解方法よりもはるかに自然で直観的です。外部キー テーブルの JOIN には、2 つのテーブルの乗算は含まれません。外部キー フィールドは、ディメンション キー テーブル内の対応するレコードを検索するためにのみ使用されます。デカルト積などの乗算特性を持つ演算はまったく含まれません。
- 外部キー関連のディメンション テーブルの関連付けられたキーは主キーである必要があることに先ほど同意しました。このようにして、ファクト テーブルの各レコードの外部キー フィールドに関連付けられたディメンション テーブル レコードは一意になります。つまり、従業員テーブルでは、各レコードの部門フィールドは部門テーブルのレコードに一意に関連付けられ、部門テーブルの各レコードの管理者フィールドも従業員テーブルのレコードに一意に関連付けられます。これにより、employee テーブルの各レコードに対して、Department.manager.nationality が一意の値を持ち、明確に定義できるようになります。
- ただし、JOIN の SQL 定義には主キーの一致がありません。SQL ルールに基づいている場合、ファクト テーブル内の外部キーに関連付けられたディメンション テーブルのレコードが一意であると判断できません。従業員テーブルのレコードの関連付けは、部門.マネージャー.国籍が明確に定義されていない場合は使用できません。
- 実際、この種のオブジェクト スタイルの記述は、高級言語 (C、Java など) で非常に一般的であり、そのような言語では、データはオブジェクトの形式で保存されます。従業員テーブルの部門フィールドの値は、数値ではなく単なるオブジェクトです。実際、多くのテーブルの主キー値自体にはビジネス上の重要性はありません。これはレコードを区別するためだけであり、外部キー フィールドはディメンション テーブル内の対応するレコードを検索するためだけです。外部キー フィールドが直接オブジェクトの場合、番号を付ける必要はありません。ただし、SQL はこの記憶メカニズムをサポートできないため、数値の助けが必要です。
- 外部キーの関連付けは非対称であると述べました。つまり、ファクト テーブルとディメンション テーブルは等しくなく、ディメンション テーブルのフィールドはファクト テーブルに基づいてのみ検出され、他のフィールドには基づいて検出されません。道の周りに。
同じディメンションを持つテーブルの均等化
同じディメンションを持つテーブルの状況は比較的単純です。例から始めましょう。2 つのテーブルがあります:
employee 员工表
id 员工编号
name 姓名
salary 工资
...
manager 经理表
id 员工编号
allowance 岗位津贴
....- 2 両方のテーブルの主キーは ID であり、マネージャーも従業員です。2 つのテーブルは同じ従業員番号を共有します。マネージャーは通常の従業員よりも多くの属性を持ち、別のマネージャー テーブルは、それらを保管してください。
- 次に、全従業員 (マネージャーを含む) の合計収入 (プラス手当) を計算したいと思います。 SQL で記述するときは、引き続き JOIN が使用されます:
SELECT employee.id, employee.name, employy.salary+manager.allowance FROM employee LEFT JOIN manager ON employee.id=manager.id
しかし、2 つの 1 対 1 テーブルの場合、実際には単純にそれらを 1 つのテーブルとみなすことができます:
SELECT id,name,salary+allowance FROM employee
- 同様に、当社の取り決めによれば、同じディメンションテーブルをJOINする場合、2つのテーブルは主キーで関連付けられ、対応するレコードは一意に対応します。給与手当は従業員テーブルのレコードごとに一意に計算できません。曖昧さが生じます。この単純化は、同次元テーブル等化と呼ばれます。
- 同じディメンションのテーブル間の関係は同等であり、同じディメンションの他のテーブルのフィールドはどのテーブルからも参照できます。
サブテーブルのコレクション
Orders と注文の詳細は典型的なメイン サブテーブルです:
Orders 订单表
id 订单编号
customer 客户
date 日期
...
OrderDetail 订单明细
id 订单编号
no 序号
product 订购产品
price 价格
...Orders テーブルの主キーは id で、Orders テーブルの主キーは id です。 OrderDetail テーブルは ( id,no) で、前者の主キーは後者の一部です。
ここで、各注文の合計金額を計算したいと思います。 SQL で書くと次のようになります:
SELECT Orders.id, Orders.customer, SUM(OrderDetail.price) FROM Orders JOIN OrderDetail ON Orders.id=OrderDetail.id GROUP BY Orders.id, Orders.customer
- 要完成这个运算,不仅要用到JOIN,还需要做一次GROUP BY,否则选出来的记录数太多。
- 如果我们把子表中与主表相关的记录看成主表的一个字段,那么这个问题也可以不再使用JOIN以及GROUP BY:
SELECT id, customer, OrderDetail.SUM(price) FROM Orders
- 与普通字段不同,OrderDetail被看成Orders表的字段时,其取值将是一个集合,因为两个表是一对多的关系。所以要在这里使用聚合运算把集合值计算成单值。这种简化方式称为子表集合化。
- 这样看待主子表关联,不仅理解书写更为简单,而且不容易出错。
- 假如Orders表还有一个子表用于记录回款情况:
OrderPayment 订单回款表
id 订单编号
date 回款日期
amount 回款金额
....- 我们现在想知道那些订单还在欠钱,也就是累计回款金额小于订单总金额的订单。
- 简单地把这三个表JOIN起来是不对的,OrderDetail和OrderPayment会发生多对多的关系,这就错了(回忆前面提过的多对多大概率错误的说法)。这两个子表要分别先做GROUP,再一起与Orders表JOIN起来才能得到正确结果,会写成子查询的形式:
SELECT Orders.id, Orders.customer,A.x,B.y
FROM Orders
LEFT JOIN ( SELECT id,SUM(price) x FROM OrderDetail GROUP BY id ) A
ON Orders.id=A.id
LEFT JOIN ( SELECT id,SUM(amount) y FROM OrderPayment GROUP BY id ) B
ON Orders.id=B.id
WHERE A.x>B.y如果我们继续把子表看成主表的集合字段,那就很简单了:
SELECT id,customer,OrderDetail.SUM(price) x,OrderPayment.SUM(amount) y FROM Orders WHERE x>y
- 这种写法也不容易发生多对多的错误。
- 主子表关系是不对等的,不过两个方向的引用都有意义,上面谈了从主表引用子表的情况,从子表引用主表则和外键表类似。
- 我们改变对JOIN运算的看法,摒弃笛卡尔积的思路,把多表关联运算看成是稍复杂些的单表运算。这样,相当于把最常见的等值JOIN运算的关联消除了,甚至在语法中取消了JOIN关键字,书写和理解都要简单很多。
维度对齐语法
我们再回顾前面的双子表例子的SQL:
SELECT Orders.id, Orders.customer, A.x, B.y
FROM Orders
LEFT JOIN (SELECT id,SUM(price) x FROM OrderDetail GROUP BY id ) A
ON Orders.id=A.id
LEFT JOIN (SELECT id,SUM(amount) y FROM OrderPayment GROUP BY id ) B
ON Orders.id=B.id
WHERE A.x > B.y- 那么问题来了,这显然是个有业务意义的JOIN,它算是前面所说的哪一类呢?
- 这个JOIN涉及了表Orders和子查询A与B,仔细观察会发现,子查询带有GROUP BY id的子句,显然,其结果集将以id为主键。这样,JOIN涉及的三个表(子查询也算作是个临时表)的主键是相同的,它们是一对一的同维表,仍然在前述的范围内。
- 但是,这个同维表JOIN却不能用前面说的写法简化,子查询A,B都不能省略不写。
- 可以简化书写的原因:我们假定事先知道数据结构中这些表之间的关联关系。用技术术语的说法,就是知道数据库的元数据(metadata)。而对于临时产生的子查询,显然不可能事先定义在元数据中了,这时候就必须明确指定要JOIN的表(子查询)。
- 不过,虽然JOIN的表(子查询)不能省略,但关联字段总是主键。子查询的主键总是由GROUP BY产生,而GROUP BY的字段一定要被选出用于做外层JOIN;并且这几个子查询涉及的子表是互相独立的,它们之间不会再有关联计算了,我们就可以把GROUP动作以及聚合式直接放到主句中,从而消除一层子查询:
SELECT Orders.id, Orders.customer, OrderDetail.SUM(price) x, OrderParyment.SUM(amount) y FROM Orders LEFT JOIN OrderDetail GROUP BY id LEFT JOIN OrderPayment GROUP BY id WHERE A.x > B.y
- 这里的JOIN和SQL定义的JOIN运算已经差别很大,完全没有笛卡尔积的意思了。而且,也不同于SQL的JOIN运算将定义在任何两个表之间,这里的JOIN,OrderDetail和OrderPayment以及Orders都是向一个共同的主键id对齐,即所有表都向某一套基准维度对齐。而由于各表的维度(主键)不同,对齐时可能会有GROUP BY,在引用该表字段时就会相应地出现聚合运算。OrderDetail和OrderPayment甚至Orders之间都不直接发生关联,在书写运算时当然就不用关心它们之间的关系,甚至不必关心另一个表是否存在。而SQL那种笛卡尔积式的JOIN则总要找一个甚至多个表来定义关联,一旦减少或修改表时就要同时考虑关联表,增大理解难度。
- 维度对齐:这种JOIN称即为维度对齐,它并不超出我们前面说过的三种JOIN范围,但确实在语法描述上会有不同,这里的JOIN不象SQL中是个动词,却更象个连词。而且,和前面三种基本JOIN中不会或很少发生FULL JOIN的情况不同,维度对齐的场景下FULL JOIN并不是很罕见的情况。
- 虽然我们从主子表的例子抽象出维度对齐,但这种JOIN并不要求JOIN的表是主子表(事实上从前面的语法可知,主子表运算还不用写这么麻烦),任何多个表都可以这么关联,而且关联字段也完全不必要是主键或主键的部分。
- 设有合同表,回款表和发票表:
Contract 合同表
id 合同编号
date 签订日期
customer 客户
price 合同金额
...
Payment 回款表
seq 回款序号
date 回款日期
source 回款来源
amount 金额
...
Invoice 发票表
code 发票编号
date 开票日期
customer 客户
amount 开票金额
...现在想统计每一天的合同额、回款额以及发票额,就可以写成:
SELECT Contract.SUM(price), Payment.SUM(amount), Invoice.SUM(amount) ON date FROM Contract GROUP BY date FULL JOIN Payment GROUP BY date FULL JOIN Invoice GROUP BY date
- 这里需要把date在SELECT后单独列出来表示结果集按日期对齐。
- 这种写法,不必关心这三个表之间的关联关系,各自写各自有关的部分就行,似乎这几个表就没有关联关系,把它们连到一起的就是那个要共同对齐的维度(这里是date)。
- 这几种JOIN情况还可能混合出现。
- 继续举例,延用上面的合同表,再有客户表和销售员表
Customer 客户表
id 客户编号
name 客户名称
area 所在地区
...
Sales 销售员表
id 员工编号
name 姓名
area 负责地区
...- 其中Contract表中customer字段是指向Customer表的外键。
- 现在我们想统计每个地区的销售员数量及合同额:
SELECT Sales.COUNT(1), Contract.SUM(price) ON area FROM Sales GROUP BY area FULL JOIN Contract GROUP BY customer.area
- 维度对齐可以和外键属性化的写法配合合作。
- 这些例子中,最终的JOIN都是同维表。事实上,维度对齐还有主子表对齐的情况,不过相对罕见,我们这里就不深入讨论了。
- 另外,目前这些简化语法仍然是示意性,需要在严格定义维度概念之后才能相应地形式化,成为可以解释执行的句子。
- 我们把这种简化的语法称为DQL(Dimensional Query Languange),DQL是以维度为核心的查询语言。我们已经将DQL在工程上做了实现,并作为润乾报表的DQL服务器发布出来,它能将DQL语句翻译成SQL语句执行,也就是可以在任何关系数据库上运行。
- 对DQL理论和应用感兴趣的读者可以关注乾学院上发布的论文和相关文章。
解决关联查询
多表JOIN问题
- 我们知道,SQL允许用WHERE来写JOIN运算的过滤条件(回顾原始的笛卡尔积式的定义),很多程序员也习惯于这么写。
- 当JOIN表只有两三个的时候,那问题还不大,但如果JOIN表有七八个甚至十几个的时候,漏写一个JOIN条件是很有可能的。而漏写了JOIN条件意味着将发生多对多的完全叉乘,而这个SQL却可以正常执行,会有以下两点危害:
- 一方面计算结果会出错:回忆一下以前说过的,发生多对多JOIN时,大概率是语句写错了
- 另一方面,如果漏写条件的表很大,笛卡尔积的规模将是平方级的,这极有可能把数据库直接“跑死”!
简化JOIN运算好处:
- 一个直接的效果显然是让语句书写和理解更容易
- 外键属性化、同维表等同化和子表集合化方案直接消除了显式的关联运算,也更符合自然思维
- 维度对齐则可让程序员不再关心表间关系,降低语句的复杂度
- 简化JOIN语法的好处不仅在于此,还能够降低出错率,采用简化后的JOIN语法,就不可能发生漏写JOIN条件的情况了。因为对JOIN的理解不再是以笛卡尔积为基础,而且设计这些语法时已经假定了多对多关联没有业务意义,这个规则下写不出完全叉乘的运算。
- 对于多个子表分组后与主表对齐的运算,在SQL中要写成多个子查询的形式。但如果只有一个子表时,可以先JOIN再GROUP,这时不需要子查询。有些程序员没有仔细分析,会把这种写法推广到多个子表的情况,也先JOIN再GROUP,可以避免使用子查询,但计算结果是错误的。
- 使用维度对齐的写法就不容易发生这种错误了,无论多少个子表,都不需要子查询,一个子表和多个子表的写法完全相同。
关联查询
- 重新看待JOIN运算,最关键的作用在于实现关联查询。
- 当前BI产品是个热门,各家产品都宣称能够让业务人员拖拖拽拽就完成想要的查询报表。但实际应用效果会远不如人意,业务人员仍然要经常求助于IT部门。造成这个现象的主要原因在于大多数业务查询都是有过程的计算,本来也不可能拖拽完成。但是,也有一部分业务查询并不涉及多步过程,而业务人员仍然难以完成。
- 这就是关联查询,也是大多数BI产品的软肋。在之前的文章中已经讲过为什么关联查询很难做,其根本原因就在于SQL对JOIN的定义过于简单。
- 结果,BI产品的工作模式就变成先由技术人员构建模型,再由业务人员基于模型进行查询。而所谓建模,就是生成一个逻辑上或物理上的宽表。也就是说,建模要针对不同的关联需求分别实现,我们称之为按需建模,这时候的BI也就失去敏捷性了。
- 但是,如果我们改变了对JOIN运算的看法,关联查询可以从根本上得到解决。回忆前面讲过的三种JOIN及其简化手段,我们事实上把这几种情况的多表关联都转化成了单表查询,而业务用户对于单表查询并没有理解障碍。无非就是表的属性(字段)稍复杂了一些:可能有子属性(外键字段指向的维表并引用其字段),子属性可能还有子属性(多层的维表),有些字段取值是集合而非单值(子表看作为主表的字段)。发生互相关联甚至自我关联也不会影响理解(前面的中国经理的美国员工例子就是互关联),同表有相同维度当然更不碍事(各自有各自的子属性)。
- 在这种关联机制下,技术人员只要一次性把数据结构(元数据)定义好,在合适的界面下(把表的字段列成有层次的树状而不是常规的线状),就可以由业务人员自己实现JOIN运算,不再需要技术人员的参与。数据建模只发生于数据结构改变的时刻,而不需要为新的关联需求建模,这也就是非按需建模,在这种机制支持下的BI才能拥有足够的敏捷性。
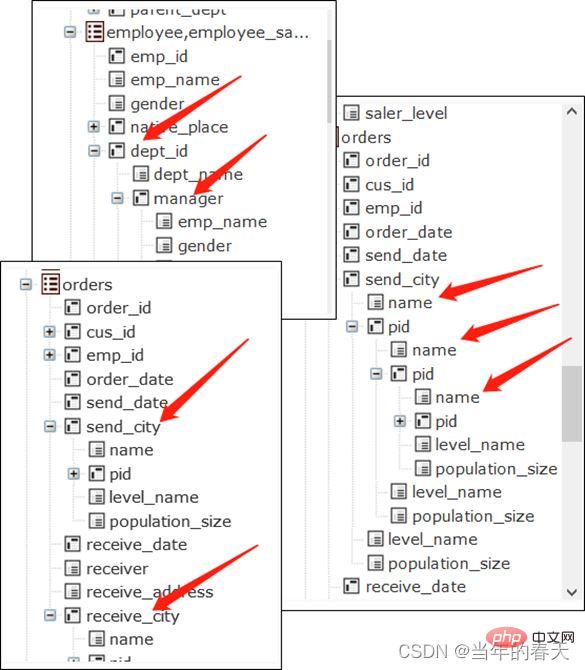
外键预关联
- 我们再来研究如何利用JOIN的特征实现性能优化,这些内容的细节较多,我们挑一些易于理解的情况来举例,更完善的连接提速算法可以参考乾学院上的《性能优化》图书和SPL学习资料中的性能优化专题文章。
全内存下外键关联情况
设有两个表:
customer 客户信息表
key 编号
name 名称
city 城市
...
orders 订单表
seq 序号
date 日期
custkey 客户编号
amount 金额
...- 其中orders表中的custkey是指向customer表中key字段的外键,key是customer表的主键。
- 现在我们各个城市的订单总额(为简化讨论,就不再设定条件了),用SQL写出来:
SELECT customer.city, SUM(orders.amount) FROM orders JOIN customer ON orders.custkey=customer.key GROUP BY customer.city
- 数据库一般会使用HASH JOIN算法,需要分别两个表中关联键的HASH值并比对。
- 我们用前述的简化的JOIN语法(DQL)写出这个运算:
SELECT custkey.city, SUM(amount) FROM orders GROUP BY custkey.city
- 这个写法其实也就预示了它还可以有更好的优化方案,下面来看看怎样实现。
- 如果所有数据都能够装入内存,我们可以实现外键地址化。
- 将事实表orders中的外键字段custkey,转换成维表customer中关联记录的地址,即orders表的custkey的取值已经是某个customer表中的记录,那么就可以直接引用记录的字段进行计算了。
- 用SQL无法描述这个运算的细节过程,我们使用SPL来描述、并用文件作为数据源来说明计算过程:
| A | |
|---|---|
| 1 | =file(“customer.btx”).import@b() |
| 2 | >A1.keys@i(key) |
| 3 | =file(“orders.btx”).import@b() |
| 4 | >A3.switch(custkey,A1) |
| 5 | =A3.groups(custkey.city;sum(amount)) |
- A1 は customer テーブルを読み取り、A2 は主キーを設定して customer テーブルのインデックスを作成します。
- A3 は注文テーブルを読み取り、A4 のアクションは A3 の外部キー フィールド custkey を A1 の対応するレコードに変換することです。実行後、注文テーブル フィールド custkey は顧客テーブルのレコードになります。通常、ファクト テーブルはディメンション テーブルよりもはるかに大きく、このインデックスは何度も再利用できるため、A2 は切り替えを高速化するためにインデックスを構築します。
- A5 はグループの集計を実行できます。注文テーブルをトラバースするとき、custkey フィールドの値がレコードになっているため、. 演算子を直接使用してそのフィールドを参照でき、custkey.city を通常どおり実行できます。 。
- A4 でのスイッチ アクションの完了後、メモリ内のファクト テーブル A3 の custkey フィールドに格納されている内容は、すでにディメンション テーブル A1 のレコードのアドレスになっています。このアクションは外部キーのアドレス指定と呼ばれます。このとき、ディメンション テーブルのフィールドを参照する場合、A1 で検索する外部キー値を使用せずに、ディメンション テーブルのフィールドを直接取得できます。これは、HASH 値の計算と比較を回避して、ディメンション テーブルのフィールドを定数時間で取得するのと同等です。
- ただし、A2 は通常、HASH メソッドを使用して主キー インデックスを構築し、キーの HASH 値を計算します。A4 がアドレスを変換するとき、custkey の HASH 値も計算し、HASH と比較します。 A2のインデックステーブル。相関演算が 1 回だけ実行される場合、アドレス方式と従来の HASH セグメンテーション方式の計算量は基本的に同じであり、根本的な利点はありません。
- しかし、違いは、データをメモリに配置できれば、このアドレスは変換後に再利用できるということです。つまり、A1 ~ A4 は 1 回だけ実行する必要があり、これらに対する関連する操作は必要ありません。次回は 2 つのフィールドが実行され、HASH 値を計算して比較する必要がなくなり、パフォーマンスが大幅に向上します。
- これは、ディメンション テーブルで前述した外部キーの関連付けの一意性を利用することで可能になります。外部キー フィールドの値は、1 つのディメンション テーブル レコードにのみ一意に対応します。各 custkey を、 A1のレコードのみに対応します。ただし、SQL で JOIN の定義を使用し続ける場合、外部キーがレコードの一意性を指していると想定できず、この表現は使用できません。また、SQL ではアドレスのデータ型が記録されないため、関連付けごとに HASH 値を計算して比較する必要があります。
- さらに、ファクト テーブルに複数のディメンション テーブルを指す複数の外部キーがある場合、従来の HASH セグメント化された JOIN ソリューションでは一度に 1 つしか解析できません。複数の JOIN がある場合は、複数のアクションを実行する必要があります。各関連付けの後、次の使用のために中間結果を保持する必要があります。計算プロセスははるかに複雑になり、データが複数回走査されます。複数の外部キーに直面する場合、外部キーのアドレス指定スキームは、中間結果を必要とせずにファクト テーブルを 1 回走査するだけで済み、計算プロセスがより明確になります。
- もう 1 つのポイントは、メモリはもともと並列計算に非常に適していますが、HASH セグメント化 JOIN アルゴリズムは並列化が容易ではないということです。データがセグメント化され、HASH 値が並行して計算される場合でも、次の比較のために同じ HASH 値を持つレコードをグループ化する必要があり、共有リソースのプリエンプションが発生し、並列コンピューティングの多くの利点が犠牲になります。外部キーJOINモデルでは、関連する2つのテーブルの状態は等しくないため、ディメンションテーブルとファクトテーブルを明確に区別した上で、ファクトテーブルを分割するだけで並列計算が可能になります。
- 外部キー属性スキームを参照して HASH セグメンテーション テクノロジを変換した後、複数の外部キーのワンタイム解析機能と並列機能もある程度向上させることができます。一部のデータベースは、この最適化を実行時に実装できます。エンジニアリングレベル。ただし、JOIN テーブルが 2 つだけの場合、この最適化は大きな問題にはなりませんが、多数のテーブルとさまざまな JOIN が混在している場合、データベースが並列トラバーサルのファクト テーブルとしてどのテーブルを使用すべきかを識別するのは容易ではありません。 HASH インデックスをディメンション テーブルとして作成する場合、最適化が常に効果的であるとは限りません。したがって、JOIN テーブルの数が増えると、パフォーマンスが急激に低下することがよくあります (テーブルが 4 つまたは 5 つある場合によく発生し、結果セットが大幅に増加しない)。 JOIN モデルから外部キーの概念が導入された後、この種の JOIN を特別に処理する場合、ファクト テーブルとディメンション テーブルは常に区別できるようになり、JOIN テーブルが増えてもパフォーマンスは直線的に低下するだけです。
- インメモリ データベースは現在注目のテクノロジーですが、上記の分析は、SQL モデルを使用したインメモリ データベースでは JOIN 操作を迅速に実行することが難しいことを示しています。
さらなる外部キーの関連付け
- 外部キー JOIN について引き続き説明し、前のセクションの例を引き続き使用します。
- データ量が大きすぎてメモリに収まらない場合、事前に計算されたアドレスを外部メモリに保存できないため、前述のアドレス指定方法は効果がありません。
- 一般的に、外部キーが指すディメンション テーブルの容量は小さくなりますが、増大するファクト テーブルの容量ははるかに大きくなります。メモリにディメンション テーブルを保持できる場合は、一時ポインティング メソッドを使用して外部キーを処理できます。
| A | |
|---|---|
| #1 | = ファイル(“customer.btx”).import@b() |
| 2 | =file(“orders.btx”).cursor@b() |
| 3 | >A2.switch(custkey,A1:#) |
| 4 | =A2 。 groups(custkey.city;sum(amount)) |
- 最初の 2 つのステップはフルメモリの場合と同じです。ステップ 4 のアドレス変換は読み取り中に実行され、変換結果は保持および再利用できません。HASH と比率は次回計算し直す必要があります。はい、パフォーマンスはフルメモリソリューションよりも劣ります。計算量的には、HASH JOIN アルゴリズムと比較して、ディメンション テーブルの HASH 値の計算が 1 回少なくなり、このディメンション テーブルを頻繁に再利用する場合には安くなりますが、ディメンション テーブルが比較的小さいため、全体的なアドバンテージは大きくありません。ただし、このアルゴリズムは、すべての外部キーを一度に解析でき、並列化が容易であるというフルメモリ アルゴリズムの特徴も備えており、実際のシナリオでは依然として HASH JOIN アルゴリズムよりもパフォーマンス上の利点があります。
外部キーのシリアル化
このアルゴリズムに基づいて、外部キーのシリアル化というバリアントを作成することもできます。
ディメンション テーブルの主キーを 1 から始まる自然数に変換できれば、HASH 値を計算して比較する必要がなく、シリアル番号を使用してディメンション テーブルのレコードを直接見つけることができます。フルメモリでのアドレス指定のパフォーマンスのようなものを得ることができるということです。
| A | |
|---|---|
| 1 | =ファイル(“customer.btx”)。 import@b() |
| 2 | =file(“orders.btx”).cursor@b() |
| 3 | >A2.switch(custkey,A1:#) |
| 4 | =A2.groups(custkey.city;sum(額))############
クラスターの力を利用して、大規模なディメンション テーブルの問題を解決します。
セグメント化された並列処理
推奨学習: mysql ビデオ チュートリアル |
以上がMySQL体系的分析のJOIN操作の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。