
ホームページ >Java >&#&チュートリアル >Java 仮想マシンの詳細な紹介: JVM ガベージ コレクター
Java 仮想マシンの詳細な紹介: JVM ガベージ コレクター

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2022-07-14 16:52:392091ブラウズ
この記事では、java に関する関連知識を提供します。主に、シリアルおよびシリアル オールド コレクター、ParNew コレクター、パラレルおよびパラレル オールド リサイクラー、その他の内容を含む、JVM ガベージ コレクターに関連する問題を整理します。ぜひご覧ください。皆さんのお役に立てば幸いです。

Java ビデオ チュートリアル 」
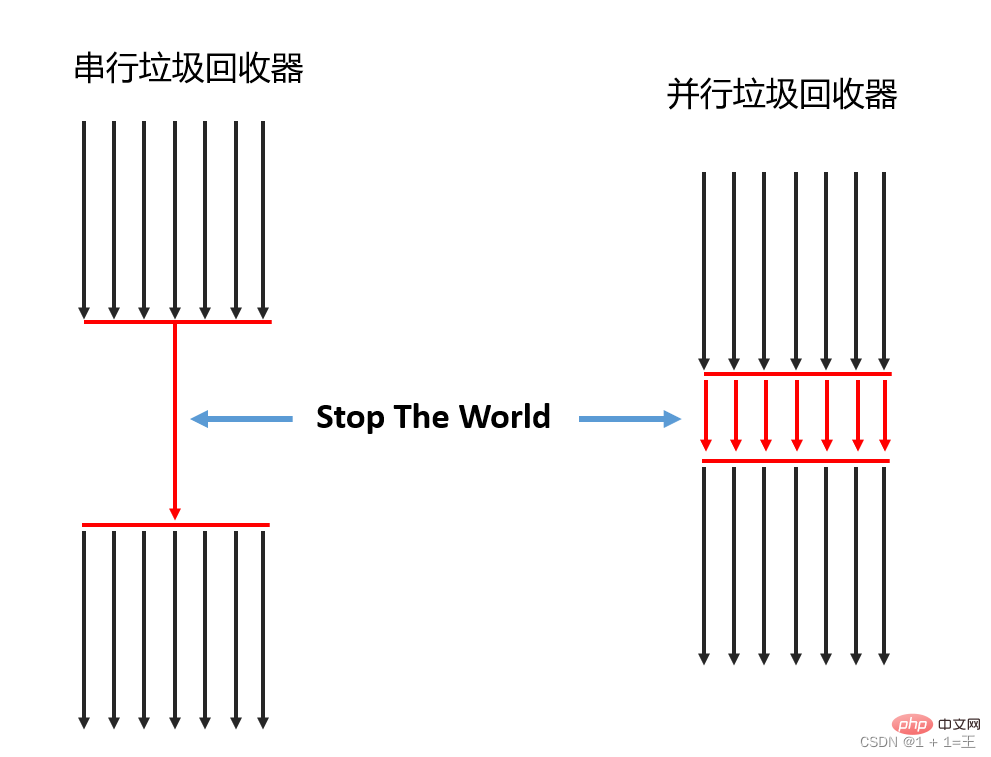
同時実行性と並列処理- Parallel ): Parallelは、複数のガベージ コレクター スレッド間の関係を示し、複数のそのようなスレッドが同時に動作していることを示します。通常、デフォルトでは、この時点でユーザー スレッドは待機状態になります。
- 同時実行性 (同時実行): 同時実行性は、ガベージ コレクター スレッドとユーザー スレッドの関係を表し、ガベージ コレクター スレッドとユーザー スレッドの両方が同時に実行されていることを示します。ユーザースレッドは凍結されていないため、プログラムは引き続きサービス要求に応答できますが、ガベージコレクタスレッドがシステムリソースの一部を占有するため、このときアプリケーションの処理スループットはある程度の影響を受けます。
1. スレッド数による (ガベージ コレクションに使用される) スレッドの数によると、
シリアル ガベージ コレクター と パラレル ガベージ コレクター に分けることができます。
- シリアル ガベージ コレクタ: ガベージ コレクション操作を同時に実行できるのは 1 つの CPU だけであり、このとき、ガベージ コレクション作業が完了するまで作業スレッドは一時停止されます。
- 並列ガベージ コレクター: 複数の CPU を使用してガベージ コレクションを同時に実行できます。
-

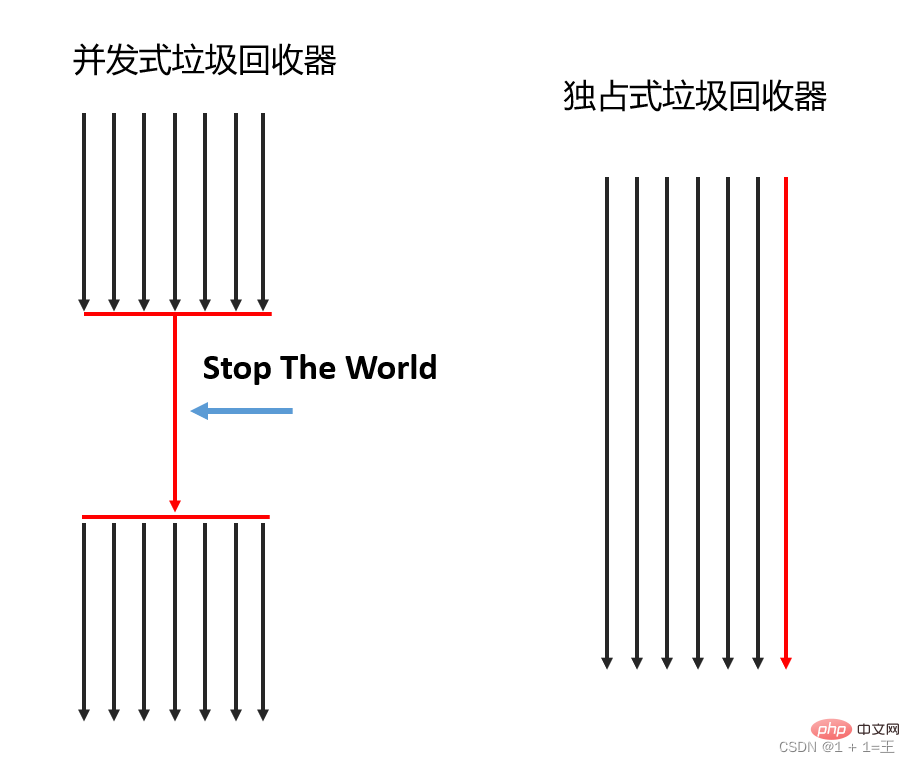
2. 動作モードによると、 動作モードによると、
同時ガベージ コレクタと排他的ガベージ コレクタに分けることができます。ガベージ コレクション デバイス 。 同時ガベージ コレクター: ガベージ コレクション操作を同時に実行できるのは 1 つの CPU だけです。このとき、ガベージ コレクション作業が完了するまで作業スレッドは一時停止されます。 - 排他的なガベージ コレクター: 複数の CPU を使用してガベージ コレクションを同時に実行できます。
 #3. 断片化処理方法によると、
#3. 断片化処理方法によると、
動作モードによると、圧縮ガベージ コレクター#に分類できます。 ## および
非圧縮ガベージ コレクター。 圧縮ガベージコレクターは、リサイクル完了後に残ったオブジェクトを圧縮して整理し、リサイクル後の破片を除去します。
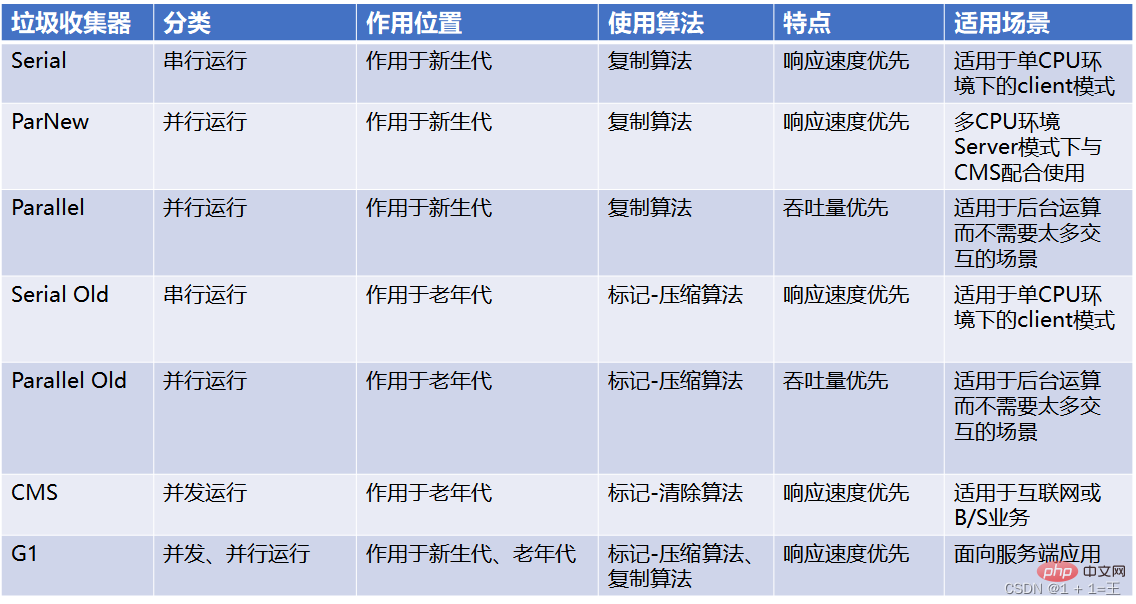
シリアル コレクター:
serial- 、
- serial oldパラレル リサイクラー: ParNew 、
- Parallel scavenge、Parallel old同時リサイクラー: CMS 、
- G1
#新世代コレクタ: シリアル、ParNew、パラレル スカベンジ;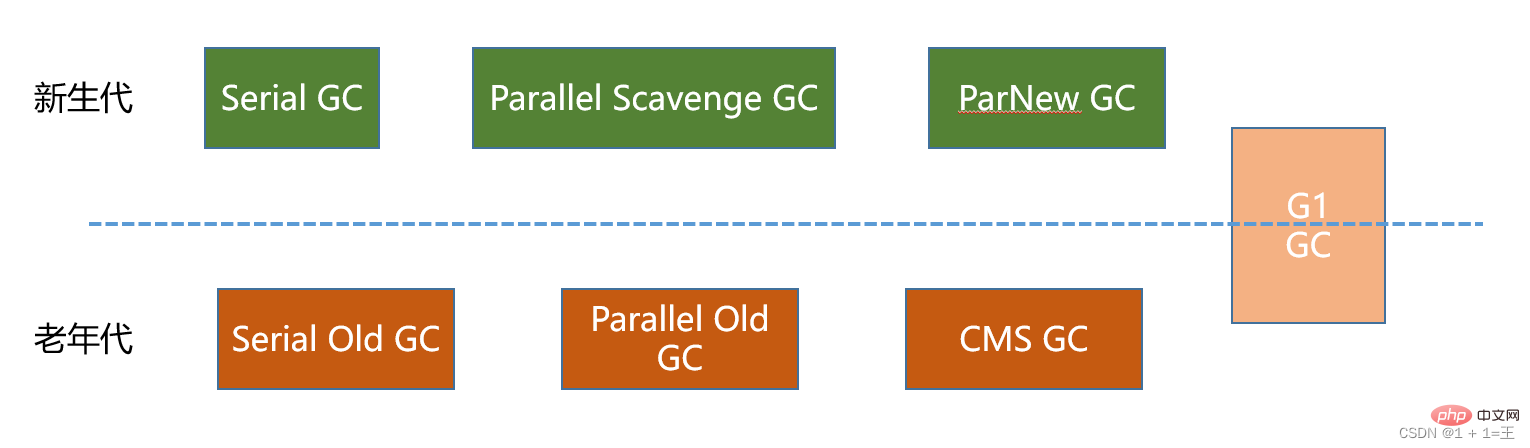
- ヒープ コレクタ全体: G1;
- ガベージ コレクタ
- シリアルおよびシリアル古いコレクタ
シリアル コレクションコレクタは、最も基本的で最も古いコレクタです。かつて (JDK 1.3.1 より前)、HotSpot 仮想マシンの新世代コレクターの唯一の選択肢でした。シリアル コレクターは
シングルスレッド作業コレクターです。ガベージ コレクションを実行するときは、コレクションが完了するまで他のすべての作業スレッドを一時停止する必要があります。
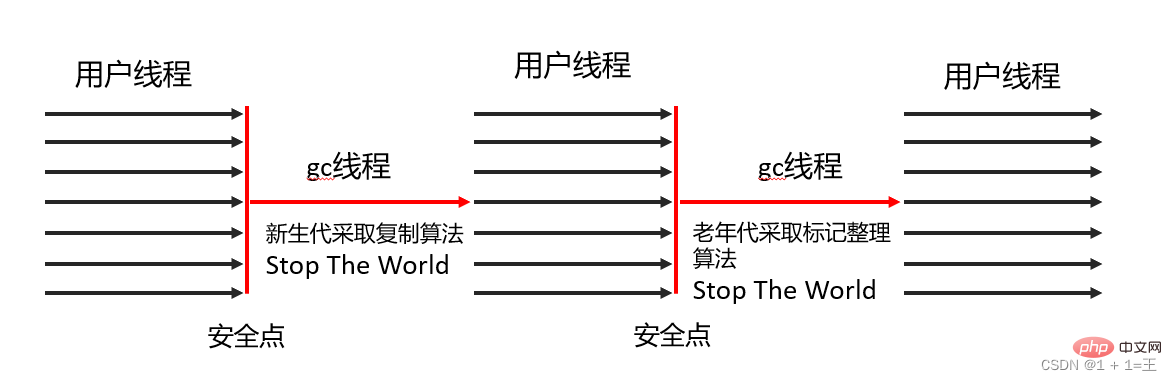
Serial Old は、シリアル コレクターの旧世代バージョンです。シリアル コレクターは、
コピー アルゴリズム、シリアル リサイクル、および「Stop The World」メカニズム
- Serial Old Collector タグ - 圧縮アルゴリズム、シリアル コレクション、および「Stop The World」メカニズムガベージ コレクションを実行します。
 ParNew コレクタは、ガベージのために複数のスレッドを使用する点を除いて、本質的にシリアル コレクタのマルチスレッド並列バージョンです。収集に加えて、シリアル コレクターで利用可能なすべての制御パラメータ、収集アルゴリズム、ストップ ザ ワールド、オブジェクト割り当てルール、リサイクル戦略などを含む残りの動作は、シリアル コレクターと完全に一致します。 。
ParNew コレクタは、ガベージのために複数のスレッドを使用する点を除いて、本質的にシリアル コレクタのマルチスレッド並列バージョンです。収集に加えて、シリアル コレクターで利用可能なすべての制御パラメータ、収集アルゴリズム、ストップ ザ ワールド、オブジェクト割り当てルール、リサイクル戦略などを含む残りの動作は、シリアル コレクターと完全に一致します。 。
Parallel および Parallel Old コレクタ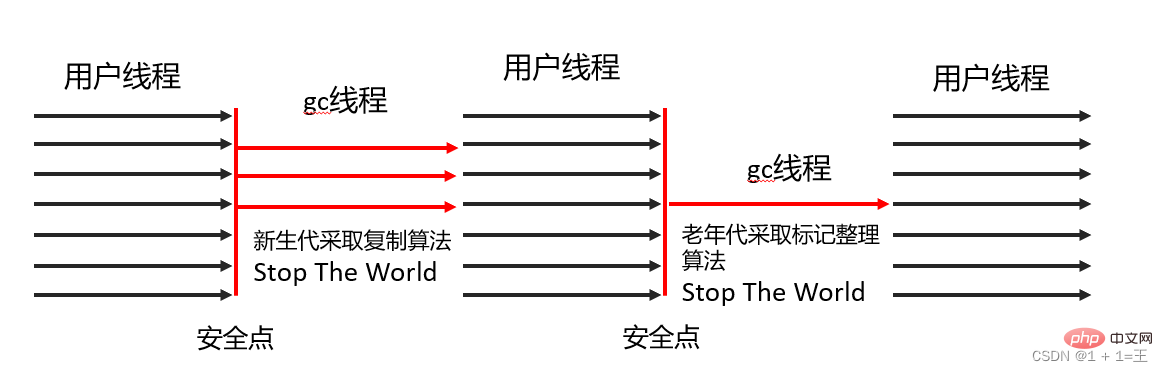 Parallel Scavenge コレクタは、新世代のコレクタでもあり、マークコピー アルゴリズムに基づいたコレクタでもあります。並行収集が可能なコレクター。
Parallel Scavenge コレクタは、新世代のコレクタでもあり、マークコピー アルゴリズムに基づいたコレクタでもあります。並行収集が可能なコレクター。
スループット
を達成することです。スループット優先のガベージ コレクターとも呼ばれます。スループット: 消費されたプロセッサ時間の合計に対する、プロセッサがユーザー コードの実行に費やした時間の比率。
高スループットにより、プロセッサ リソースが最も効率的に使用され、プログラムのコンピューティング タスクをできるだけ早く完了できます。主に、バックグラウンドで動作し、あまり多くの対話を必要としない分析タスクに適しています。
Parallel Old は、Parallel Scavenge コレクターの旧世代バージョンであり、マルチスレッドの同時収集をサポートし、マーク照合アルゴリズムに基づいて実装されています。
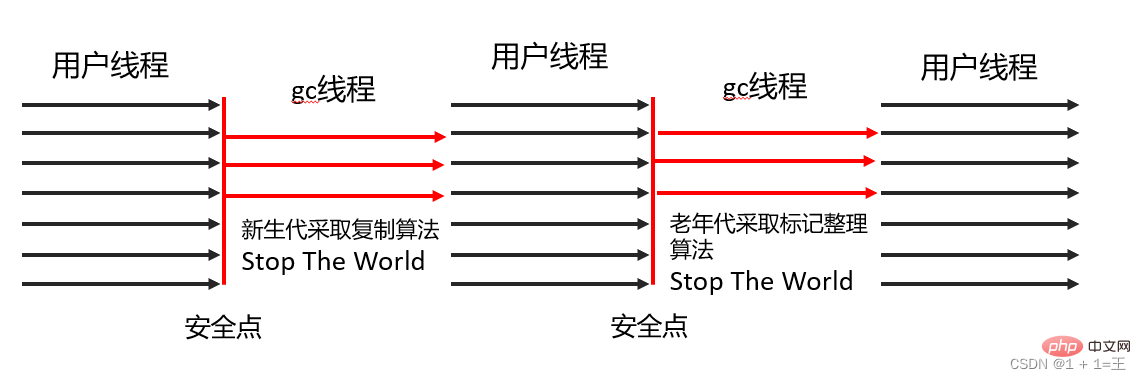
CMS コレクター
CMS (同時マーク スイープ) コレクターは、リサイクル一時停止時間を最短にすることを目的としたコレクターです。
CMS コレクターは mark-clearance アルゴリズムに基づいて実装されており、その操作は次の 4 つのステップに分けることができます。初期マークは、GC ルートが直接関連付けることができるオブジェクトのみをマークし、非常に高速です。
- 同時マーキング
- 同時マーキング フェーズは、GC ルートに直接関連付けられたオブジェクトから開始してオブジェクト グラフ全体を走査するプロセスです。 GC ルート。このプロセスには時間がかかりますが、ユーザー スレッドを一時停止する必要はなく、ガベージ コレクション スレッドと同時に実行できます。
リマーキング - リマーキング フェーズは、GC ルートによって引き起こされる問題を修正することです。ユーザー プログラムは、同時マーキング期間中も動作し続けます。変更されたオブジェクトの部分のレコードをマークします。このフェーズの一時停止時間は、通常、最初のマーキング フェーズよりわずかに長くなりますが、同時マーキング フェーズよりもはるかに短くなります。 ;
同時クリア - クリーンアップと削除 マーキング フェーズで判断された死んだオブジェクトは移動する必要がないため、このフェーズはユーザー スレッドと並行して実行することもできます。
」を処理できず、「同時モード障害」で失敗し、別の完全な「Stop The World」が発生する可能性があります。 「完全な GC 世代。 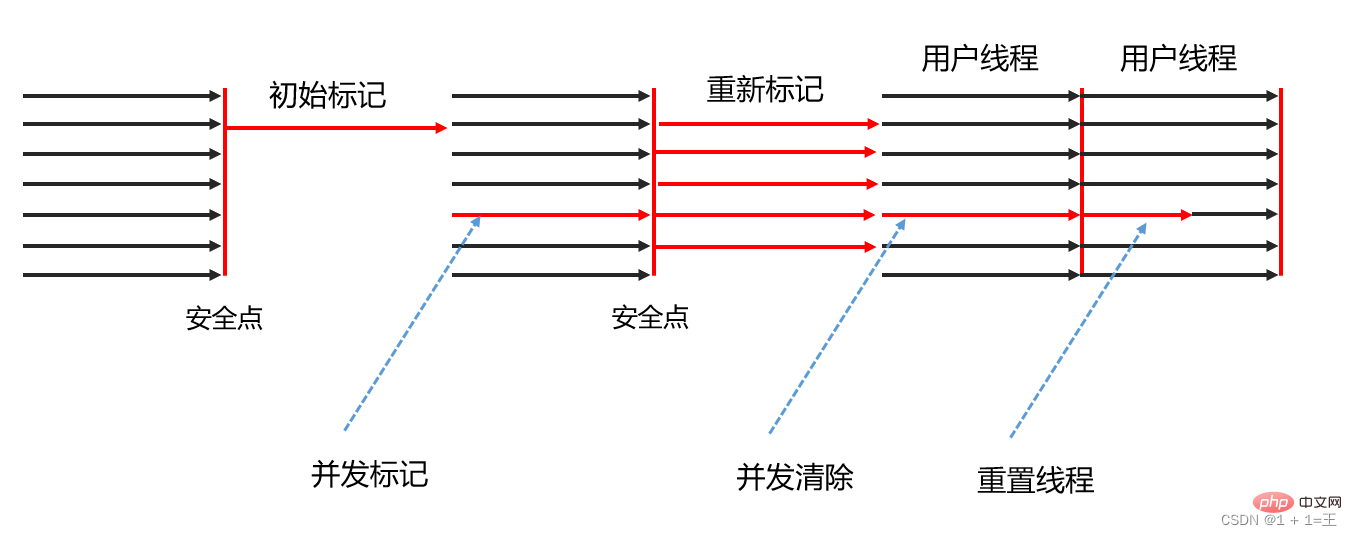 CMS の同時マーキングおよび同時クリーニング フェーズ中、ユーザー スレッドはまだ実行中です。当然のことながら、プログラムの実行中も新しいガベージ オブジェクトが生成され続けますが、ガベージ オブジェクトのこの部分はマーキング プロセスの後に表示されます。が完了しました。CMS は現在のコレクションではそれらを処理できないため、次のガベージ コレクションがそれらをクリーンアップするまで待つ必要があります。このゴミの部分を「浮遊ゴミ」といいます。
CMS の同時マーキングおよび同時クリーニング フェーズ中、ユーザー スレッドはまだ実行中です。当然のことながら、プログラムの実行中も新しいガベージ オブジェクトが生成され続けますが、ガベージ オブジェクトのこの部分はマーキング プロセスの後に表示されます。が完了しました。CMS は現在のコレクションではそれらを処理できないため、次のガベージ コレクションがそれらをクリーンアップするまで待つ必要があります。このゴミの部分を「浮遊ゴミ」といいます。
ユーザー スレッドはガベージ コレクション フェーズ中に実行し続ける必要があるため、ユーザー スレッドが使用するために十分なメモリ領域を予約する必要があるため、CMS コレクターは古い世代がほぼなくなるまで待つことができません。コレクションが完全にいっぱいになると、同時収集中のプログラム操作のためにある程度のスペースを予約する必要があります。
CMS は、「マーク アンド クリア」アルゴリズムに基づいて実装されたコレクターです。つまり、コレクションの最後に大量のスペース フラグメントが生成されます。スペース フラグメントが多すぎる場合、大きなオブジェクトの割り当てに大きな問題が発生します。
同時クリアを使用すると、メモリの整理にマーク圧縮が使用され、元のユーザー スレッドが使用していたメモリは使用できなくなるためです。ユーザー スレッドが実行を継続できるようにするには、スレッドが実行されるリソースが影響を受けないことが前提となります。フラグ圧縮は、「Stop The World」シナリオにより適しています。
G1 (Garbage First) コレクタGarbage First は、ローカルコレクション用のコレクタとリージョンに基づいたメモリレイアウト形式の設計思想を先駆けて開発した、主に用途に応じたコレクタです。適用されるガベージコレクタは、主にマルチコアCPUと大容量メモリを搭載したマシンを対象としており、非常に高い確率でGCの一時停止時間を満たし、スループットの高い性能特性を備えています。
G1 コレクターより前の他のすべてのコレクターでは、ガベージ コレクションのターゲット範囲は、新しい世代全体、古い世代全体、または Java ヒープ全体のいずれかでした。 G1 は、リサイクルのためにヒープ メモリの任意の部分のコレクション セットを形成できます。
測定基準は、もはやどの世代に属しているかではなく、どのメモリ部分が最大量のガベージを格納し、最大のリサイクル効果があるかということです## #。 G1 コレクターの特徴1. 並列性と同時実行性
並列性: G1 リサイクル中、複数の GC が存在する可能性があります。同時にユーザースレッドは Stops The World になります。 同時実行性: G1 はアプリケーションと交互に実行する機能を備えており、一部の作業はアプリケーションと同時に実行できるため、一般に、アプリケーション全体が完全にブロックされることはありません。リサイクル段階。
- 2. 世代別コレクション
-
- G1 は依然として世代別コレクション理論に従って設計されていますが、そのヒープ メモリ レイアウトは他のコレクタとは明らかに異なります。G1 は固定サイズと固定数の世代領域分割に準拠しなくなりましたが、 は、連続した Java ヒープを同じサイズの複数の独立した領域 (リージョン) に分割し、各リージョンは、必要に応じて、新世代の Eden スペース、Survivor スペース、または古い世代スペースの役割を果たすことができます。 コレクターは、さまざまな戦略を使用して、さまざまな役割を果たすリージョンを処理できるため、新しく作成されたオブジェクトであっても、一定期間存続し複数のコレクションを経た古いオブジェクトであっても、良好なコレクション効果を達成できます。
- Region には特別なタイプの Humongousregion もあり、これは特に大きなオブジェクトを格納するために使用されます。 G1 は、オブジェクトのサイズがリージョンの容量の半分を超える限り、それは大きなオブジェクトとして判断できると考えています。
3. 空間統合
- G1 はメモリをリサイクルするときに基本単位として領域を使用し、領域間のコピー アルゴリズムを使用しますが、全体的にはこれはマーク圧縮アルゴリズムと考えることができます。
4. 予測可能な休止時間モデル
- #G1 コレクターは、リージョンを単一のリージョンとして扱う、予測可能な休止時間モデルを確立できます。リサイクルの最小単位、つまり、毎回収集されるメモリ空間はリージョン サイズの整数倍であるため、Java ヒープ全体でのフルリージョン ガベージ コレクションを計画的に回避できます。
- G1コレクターは各地域のゴミ集積の「価値」を追跡します 価値とは、リサイクルによって得られるスペースの量と、リサイクルに要した時間の経験値ですその後、それをバックグラウンドの優先リストで維持します。毎回、ユーザー設定で許可されている収集一時停止時間に基づいて、最大の回復値を持つリージョンが最初に処理されます。
- リージョンを使用してメモリ空間を分割し、優先的にリージョンをリサイクルするこの方法により、G1 コレクターは限られた時間内で可能な限り最高の収集効率を得ることができます。
- 一時停止予測モデルは、減衰平均の理論的基礎に基づいて実装されており、ガベージ コレクション プロセス中に、G1 コレクターは各リージョンのリサイクル時間、各リージョンのメモリ セット内のダーティ カードの数、測定可能な各ステップのコストが分析され、平均値、標準偏差、信頼水準などの統計情報が取得されます。次に、この情報を使用して、リサイクルが今開始された場合にどのリージョンがリサイクル回収を構成するかを予測し、予想される一時停止時間を超過することなく最大の収益が得られるようにします。
リージョンに存在するクロスリージョン参照オブジェクトを解決するにはどうすればよいですか?
ヒープ全体を GC ルートとしてスキャンしないようにメモリ セットを使用します。各リージョンは独自のメモリ セットを維持します。これらのメモリ セットは、他のリージョンが指すポインタを記録し、これらのポインタがどこにあるかをマークします。カードページ。 G1 のメモリ セットは、ストレージ構造としては本質的にハッシュ テーブルであり、Key は他のリージョンの開始アドレス、Value はセット、そこに格納される要素はカード テーブルのインデックス番号です。
G1 コレクターの操作プロセス
- 初期マーキング (初期マーキング): GC ルートが直接関連付けることができるオブジェクトをマークし、TAMS を変更するだけです。ポインタの値により、ユーザー スレッドの次のフェーズが同時に実行されるときに、利用可能なリージョンに新しいオブジェクトを正しく割り当てることができます。この段階ではスレッドを一時停止する必要がありますが、所要時間は非常に短く、マイナー GC 中に同期的に完了するため、この段階では実際には G1 コレクターに追加の一時停止はありません。
- 同時マーキング (同時マーキング): GC ルートから開始して、ヒープ内のオブジェクトの到達可能性分析を実行し、ヒープ全体のオブジェクト グラフを再帰的にスキャンして、オブジェクトを見つけます。このステージは時間がかかりますが、ユーザープログラムと同時に実行できます。オブジェクト グラフ スキャンの完了後、同時実行中に参照変更があった SATB によって記録されたオブジェクトを再処理する必要があります。
- 最終マーキング (最終マーキング): 同時フェーズ後に残った最後の数個の SATB レコードを処理するために、ユーザー スレッドでもう一度短い一時停止を行います。
- フィルタリングとリサイクル (ライブデータのカウントと退避): リージョン統計の更新、各リージョンのリサイクル価値とコストの分類、および予測される一時停止時間に基づいたリサイクルの定式化を担当します。計画に従って、任意の数のリージョンを自由に選択してリサイクル コレクションを形成し、リサイクルすることが決定されたリージョンの残りのオブジェクトを空のリージョンにコピーし、古いリージョン全体のすべてのスペースをクリーンアップします。 。ここでの操作には生きているオブジェクトの移動が含まれるため、ユーザー スレッドを一時停止し、複数のコレクター スレッドによって並行して完了する必要があります。
#7 つの従来のガベージ コレクターの比較#ガベージ コレクターの組み合わせ低遅延ガベージ コレクター
Shenandoah コレクター
Shenandoah はリージョンベースのヒープ メモリ レイアウトも使用しており、大きなオブジェクトを格納するための巨大なリージョンもあり、デフォルトのリサイクル戦略はまずリサイクル価値が最も高いリージョンです...しかし、ヒープ メモリの管理という点では、G1 とは少なくとも 3 つの明らかな違いがあります。
- G1 のリサイクル フェーズは複数のスレッドで並列化できますが、ユーザー スレッドと同時実行することはできません。Shenandoah は同時ソート アルゴリズムをサポートしています。
- デフォルトでは、世代別コレクションは使用されません。つまり、特別な新世代リージョンまたは古い世代リージョンはありません。世代別コレクションは実装されていません。これは、シェナンドーにとって世代別コレクションに価値がないという意味ではありません費用対効果のトレードオフのため、ワークロードを考慮すると優先順位が低くなります。
- Shenandoah は、G1 で維持するために大量のメモリとコンピューティング リソースを消費するメモリ セットを放棄し、代わりに「接続マトリックス」と呼ばれるグローバル データ構造を使用してリージョン間の参照関係を記録し、処理時間を短縮しました。世代間ポインタ: 時間のかかるメモリ セットのメンテナンス消費により、擬似共有の問題が発生する可能性も低くなります。接続行列は単純に 2 次元のテーブルとして理解できます。領域 N に領域 M を指すオブジェクトがある場合、テーブルの N 行 M 列にマークが付けられます。リサイクル中に、このテーブルは次のようになります。どの領域に相互接続があるかを判断するために使用されます。
シェナンドーコレクターの作業工程は、大きく以下の9段階に分かれます。
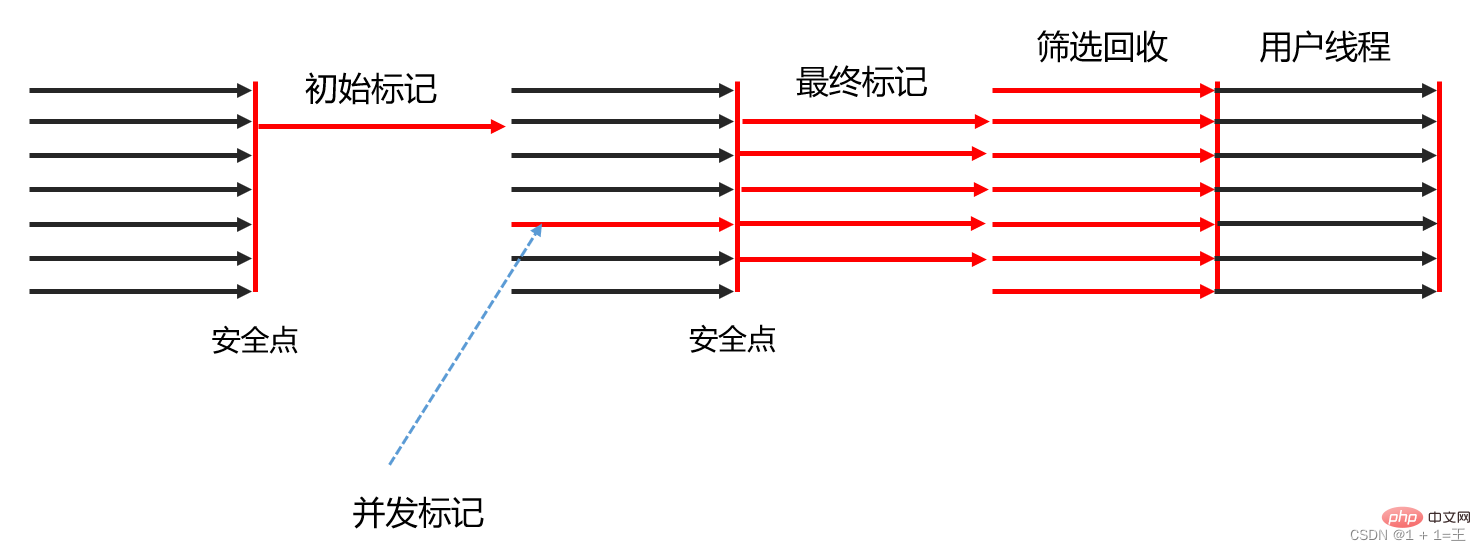
 #ガベージ コレクターの組み合わせ
#ガベージ コレクターの組み合わせ- 初期マーキング: G1と同様に、最初にマーキングします。 GC ルートに直接関連するオブジェクトの場合、この段階は依然として「Stop The World」ですが、一時停止時間はヒープ サイズとは関係なく、GC ルートの数のみに関係します。
- 同時マーキング: G1 と同様に、オブジェクト グラフを走査し、到達可能なすべてのオブジェクトをマークします。この段階はユーザー スレッドと並行して行われます。時間の長さは、ヒープ: オブジェクト グラフの数と構造の複雑さ。
- 最終マーク: G1 と同様に、残りの SATB スキャンを処理し、この段階でリサイクル価値が最も高い領域を数え、これらの領域をリサイクル コレクションのセットに形成します。最後の採点段階でも短い休憩が発生します。
- 同時クリーンアップ: このステージは、領域全体で生き残ったオブジェクトが 1 つも見つからなかった領域をクリーンアップするために使用されます。
- 同時リサイクル: この段階で、Shenandoah はコレクション内に残っているオブジェクトを他の未使用のリージョンにコピーします。同時収集フェーズの実行時間は、コレクションのサイズによって異なります。
- 最初の参照更新: オブジェクトのコピー時に同時リサイクル フェーズが終了した後、ヒープ内の古いオブジェクトへのすべての参照を、コピー後の新しいアドレスに修正する必要があります。この操作は参照と呼ばれます。アップデート。参照更新の初期化フェーズでは、実際には特定の処理は行われません。このフェーズは、スレッド ランデブー ポイントを確立して、同時リサイクル フェーズのすべてのコレクタ スレッドが割り当てられたオブジェクト移動タスクを確実に完了することを目的としてのみ確立されます。最初のリファレンス更新時間は非常に短いため、一時停止が非常に短くなります。
- 同時参照更新: 参照更新操作が実際に開始されます。この段階はユーザー スレッドと並行して行われます。時間の長さは、メモリに含まれる参照の数によって異なります。同時参照更新は同時マーキングとは異なり、オブジェクトグラフに沿って検索する必要がなく、メモリの物理アドレス順に参照型を線形に検索し、古い値を新しい値に変更するだけです。
- 最終参照更新: ヒープ内の参照更新を解決した後、GC ルートに存在する参照も修正する必要があります。このステージはシェナンドーの最後の一時停止であり、一時停止時間は GC ルートの数にのみ関係します。
- 同時実行クリーンアップ: 同時リサイクルと参照更新の後、リサイクル セット全体のすべてのリージョンに存続するオブジェクトがありません。これらのリージョンは即時ガベージ リージョンになります。最後に、もう一度 Concurrency を呼び出します。クリーンアッププロセスは、将来の新しいオブジェクトの割り当てのために、これらのリージョンのメモリ空間を再利用します。
ZGC Collector
ZGC と Shenandoah の目標は非常に似ており、どちらもスループットにできるだけ影響を与えずに任意のヒープ メモリ サイズを達成することを望んでいます。遅延は 10 ミリ秒未満に制限できます。
ZGC コレクターは、(一時的に) 生成のないリージョン メモリ レイアウトに基づいており、読み取りバリア、染色されたポインタ、メモリ複数マッピングなどのテクノロジを使用して同時マーキングを実現します - に基づくガベージ コレクター低レイテンシーを主な目標とする並べ替えアルゴリズム。
ZGC もリージョンベースのヒープ メモリ レイアウトを使用しますが、それらとは異なり、ZGC のリージョンは動的です。動的に作成および破棄され、リージョン容量サイズも動的に異なります。
ZGC の運用プロセスは 4 つの段階に分けることができます:
- 同時マーキング(: G1 や Shenandoah と同様、同時マーキングは、到達可能性分析のためにオブジェクト グラフを走査する段階です。また、G1 や Shenandoah と同様に、初期マーキングと最終マーキングも通過します。 . マーキングのための短い一時停止 (ZGC ではこれらとは呼ばれません)、これらの一時停止フェーズが行うことはターゲット上でも同様です。G1 やシェナンドーとは異なり、ZGC のマーキングはオブジェクトではなくポインター上にあります。上記で実行されます。マーキング フェーズでは、ダイイング ポインターの Marked 0 および Marked 1 フラグが更新されます。
- 同時準備再割り当て: このステージでは、特定のクエリ条件に基づいた統計が必要です。どのリージョンをクリーンアップ中にクリーンアップする必要がありますか?
- 同時再割り当て : 再割り当ては、ZGC 実行プロセスの中核段階です。このプロセスは再割り当てに重点を置く必要があります。生き残ったオブジェクトが新しいリージョンにコピーされ、古いオブジェクトから新しいオブジェクトへのステアリング関係を記録するために、再割り当てセット内の各リージョンに対して転送テーブルが維持されます。再マッピングは、再割り当てセット内の古いオブジェクトを指すヒープ全体のすべての参照を修正することです。ZGC は、同時再マッピング フェーズで実行される作業を、次のガベージ コレクション サイクルの同時マーキング フェーズに巧みにマージします。とにかく、それらは行う必要があります。すべてのオブジェクトをトラバースするため、マージによってオブジェクト グラフをトラバースするコストが節約されます。すべてのポインタが修正されると、古いオブジェクトと新しいオブジェクトの間の関係を記録する元の転送テーブルを解放できます。
- 正しいものを選択してくださいガベージ コレクター 次の 3 つの質問について考えてください:
アプリケーションの主な焦点は何ですか?
データ分析の場合、科学計算タスクの場合、目標は、結果をできるだけ早く計算することであるため、スループットが主な焦点となります。SLA アプリケーションの場合、一時停止時間はサービスの品質に直接影響し、深刻な場合には、トランザクション タイムアウトなどの遅延 これが主な焦点です。- そして、それがクライアント アプリケーションまたは組み込みアプリケーションの場合、ガベージ コレクションのメモリ フットプリントは無視できません。
- とはアプリケーションを実行するためのインフラストラクチャ?
- 選択されたオペレーティング システムは Linux、Solaris、Windows などです。
- JDK を使用している発行者は何ですか? バージョン番号は何ですか?
- ZingJDK/Zulu、OracleJDK、Open-JDK、OpenJ9、または他社のリリースですか? この JDK は「Java 仮想マシン仕様」のどのバージョンに対応していますか?
ガベージ コレクターの選択方法
JVM が適応できるようにヒープ サイズを調整することを優先します。 メモリが 100M 未満の場合は、シリアル コレクターを使用します。- シングルコアのスタンドアロン プログラムで、一時停止時間の要件がない場合は、シリアル コレクター
- マルチCPUの場合は高いスループットが求められ、一時停止時間は1秒を超えても許容されますので並列処理かJVMをご自身で選択してください
- マルチCPUの場合は低一時停止時間を追求し、高速な応答が必要です (たとえば、インターネット アプリケーションの場合、遅延は 1 秒を超えてはなりません)。同時コレクターの使用
- # 推奨学習: 「
- java ビデオ チュートリアル 」
以上がJava 仮想マシンの詳細な紹介: JVM ガベージ コレクターの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。