
ホームページ >Java >&#&チュートリアル >Javaで詳しく紹介されているコレクションについてのメモ
Javaで詳しく紹介されているコレクションについてのメモ

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2022-05-30 18:50:232070ブラウズ
この記事では、java に関する関連知識を提供します。主に、マップ インターフェイス、HashMap クラス、HashTable クラス、プロパティ クラス、コレクション ツール クラスなど、コレクションの考慮事項と基礎となる構造に関連する問題を紹介します。皆さんのお役に立てば幸いです。

Java ビデオ チュートリアル 」
1. マップ インターフェイス
1. 注意事項 (実践編)
- Map と Collection は隣り合って存在します。マッピング関係を含むデータの保存に使用されます: Key-Value (2 列要素)
- Map のキーと値は任意の参照型データにすることができ、HashMap$Node# # にカプセル化されます。 # オブジェクトでは
#HashSet と同じ理由でマップ内のキーを繰り返すことはできません
- ##マップ内の値
- マップ キーは null にすることができ、値も null にすることができます。ただし、キーが null の場合は 1 つだけ、値が null の場合は複数存在できることに注意してください。
- String クラスは、一般的にキーとして使用されます。 Map
- #キーと値の間には一方向の 1 対 1 の関係があります。つまり、対応する値は、指定されたキーを通じて常に見つけることができます
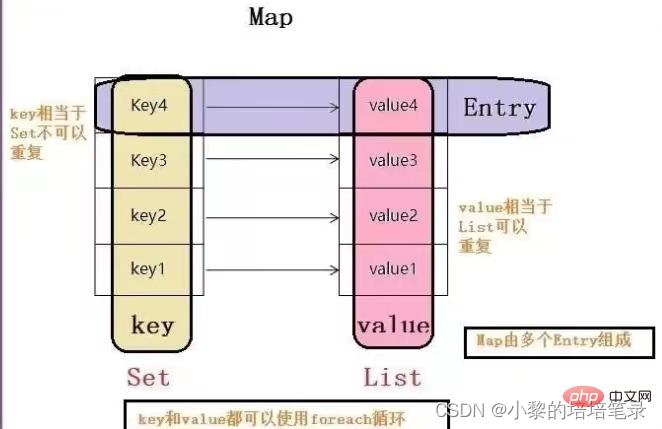
- 2. Key-Value ダイアグラム
##3. Map インターフェイスの一般的なメソッド
Map map = new HashMap(); map.put("第一", "节点1"); map.put("第二", "节点2"); map.put("第三", "节点3"); map.put("第四", "节点4");(1)remove: キーマッピング関係に基づいて削除
map.remove("第二");(2)get:値を取得キーに従ってObject val = map.get("第三");(3)size : 要素数を取得System.out.println("key-value=" + map.size());(4)は空です:番号が であるかどうかを判断します 0
System.out.println( map.isEmpty() ); //False(5)クリア : ###クリア ###key-value
map.clear();(6)containsKey: キーが存在するかどうかを確認するSystem.out.println(map.containsKey("第四")); //true4. マップの走査方法(1) 4 つの走査方法
#containsKey: キーが存在するかどうかを確認しますkeySet: すべてのキーを取得します
- entrySet :すべての関係を取得 K-V
- values : すべての値を取得
- (2) keySet トラバーサル メソッド
Map map = new HashMap();//先取出 所有的 Key , 通过 Key 取出对应的 Value Set keyset = map.keySet(); //(1)第一种方式: 增强 for循环 for (Object key : keyset) { System.out.println(key + "-" + map.get(key)); } //(2)第二种方式:迭代器 Iterator iterator = keyset.iterator(); while (iterator.hasNext()) { Object key = iterator.next(); System.out.println(key + "-" + map.get(key)); }(3) 値トラバーサルメソッド
//把所有的 values 取出 Collection values = map.values(); //注意:这里可以使用所有的 Collections 使用的遍历方法 //(1)取出所有的 value 使用增强 for 循环 for (Object value : values) { System.out.println(value); } //(2)取出所有的 value 使用迭代器 Iterator iterator2 = values.iterator(); while (iterator2.hasNext()) { Object value = iterator2.next(); System.out.println(value); }(4)entrySetトラバーサル メソッド
//通过 EntrySet 来获取 key-value Set entrySet = map.entrySet(); // EntrySet<Map.Entry<K,V>> //(1)使用 EntrySet 的 增强 for循环遍历方式 for (Object entry : entrySet) { //将 entry 转成 Map.Entry Map.Entry m = (Map.Entry) entry; System.out.println(m.getKey() + "-" + m.getValue()); } //(2)使用 EntrySet 的迭代器遍历方式 Iterator iterator3 = entrySet.iterator(); while (iterator3.hasNext()) { //HashMap$Node -实现-> Map.Entry (getKey,getValue) Object entry = iterator3.next(); //向下转型 Map.Entry Map.Entry m = (Map.Entry) entry; System.out.println(m.getKey() + "-" + m.getValue()); }
二、HashMap 类
1、注意事项
- Map接口的常用实现类:HashMap、Hashtable 和 Properties
- HashMap是 Map 接口使用频率最高的实现类(重点掌握)
- HashMap 是以key-value 一对的方式来存储数据(HashMap$Node类型)
- key 不能重复, 但是value值可以重复,二者都允许使用null键。
- 如果添加相同的key,则会覆盖原来的key-value,等同于修改(key不会替换,value会替换)
- 与HashSet一样, 不保证映射的顺序, 因为底层是以Hash表的方式来存储的(jdk8的HashMap 底层数组+链表+红黑树)
- HashMap没有实现同步,因此是线程不安全的,方法没有做同步互斥的操作,没有
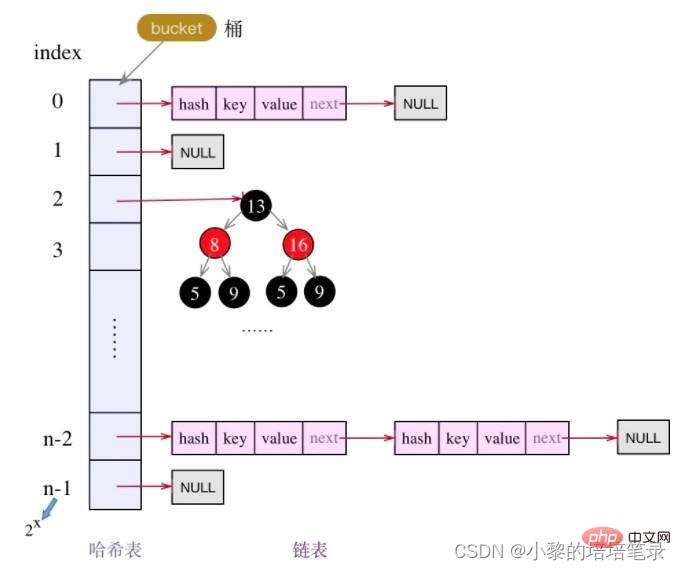
synchronized 关键字2、底层机制
- HashMap底层维护了Node类型的数组table,默认为null
- 当创建对象时, 将加载因子(loadfactor)初始化为0.75
- 当添加key-value时,通过key的哈希值得到在table的素引。 然后判断该索引处是否有元素,如果没有元素直接添加。 如果该索引处有元素, 继续判断该元素的key和准备加入的key是否相等, 如果相等,则直接替换value; 如果不相等需要判断是树结构还是链表结构,做出相应处理。 如果添加时发现容量不够, 则需要扩容。
- 第1次添加, 则需要扩容table容量为16, 临界值(threshold)为12 (16*0.75)
- 以后再扩容, 则需要扩容table容量为原来的2倍(32). 临界值为原来的2倍,即24(32*0.75),依次类推
- 在Java8中,如果一条链表的元素个数超过 TREEIFY_THRESHOLD(默认是8),并且 table的大小 >= MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树)
3、底层原理图
三、HashTable 类
1、基本介绍
- 存放的元素是键值对:即Key-Value
- HashTable 的键和值都不能为null
- HashTable 的使用方法基本上和HashMap一样
- HashTable 是线程安全的,HashMap 是线程不安全
- Hashtable 和 HashMap 的比较:
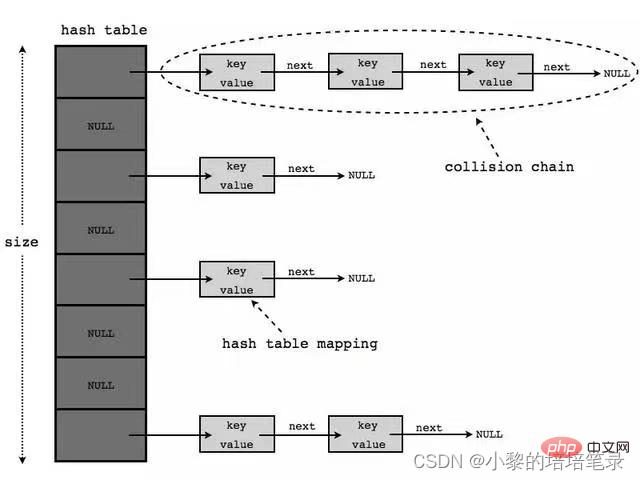
2、底层结构示意图
3、HashTable 常用方法
Map map = new HashTable(); map.put("第一", "节点1"); map.put("第二", "节点2"); map.put("第三", "节点3"); map.put("第四", "节点4");(1)remove : 根据键删除映射关系
map.remove("第二");(2)get :根据键获取值
Object val = map.get("第三");(3)size : 获取元素个数
System.out.println("key-value=" + map.size());(4)isEmpty : 判断个数是否为 0
System.out.println( map.isEmpty() ); //False(5)clear : 清除 key-value
map.clear();(6)containsKey : 查找键是否存在
System.out.println(map.containsKey("第四")); //true

四、Properties 类
1、基本介绍
- Properties 类继承自HashTable类并且实现了Map接口,也是使用一种键值对的形
式来保存数据。(可以通过 key-value 存放数据,当然 key 和 value 也不能为 null)- 它的使用特点和Hashtable类似
- Properties 还可以用于从xx.properties文件中,加载数据到Properties类对象,并进行读取和修改(在IO流中会详细介绍)
2、常用方法
Properties properties = new Properties();(1)put 方法
properties.put(null, "abc");//抛出 空指针异常 properties.put("abc", null); //抛出 空指针异常 properties.put("lic", 100); properties.put("lic", 88);//如果有相同的 key , value 被替换(2)get 方法
System.out.println(properties.get("lic"));(3)remove 方法
properties.remove("lic");
五、Collections 工具类
1、基本介绍
- Collections 是一个操作Set. List 和 Map等集合的工具类
- Collections中提供了一系列静态的方法对集合元素进行排序、查询和修改等操作排序
2、排序操作(均为static方法)
方法 作用 reverse(List) 反转 List 中元素的顺序 shuffle(List) 对 List集合元素进行随机排序 sort(List) 根据元素的自然顺序对指定List集合元素按升序排序 sort(List,Comparator) 根据指定的Comparator 产生的顺序对 List集合元素进行排序 swap(List, int i, int j) 将指定list 集合中的 i 处元素和 j 处元素进行交换 List list = new ArrayList(); list.add("第一个"); list.add("第二个"); list.add("第三个");(1)reverse(List): 反转 List 中元素的顺序
Collections.reverse(list);(2)shuffle(List):对 List 集合元素进行随机排序
for (int i = 0; i < 5; i++) { Collections.shuffle(list); System.out.println("list=" + list); }(3)sort(List): 根据元素的自然顺序对指定 List 集合元素按升序排序
Collections.sort(list);(4)sort(List,Comparator): 根据指定的 Comparator 产生的顺序对 List 集合元素进行排序
//匿名内部类 Collections.sort(list, new Comparator() { @Override public int compare(Object o1, Object o2) { return ((String) o2).length() - ((String) o1).length(); } });(5)swap(List,int, int): 将指定 list 集合中的 i 处元素和 j 处元素进行交换
Collections.swap(list, 0, 1);.......................................................
3、查找、替换操作
方法 作用 Object max(Collection) 根据元素的自然顺序,返回给定集合中的最大元素 Object max(Collection, Comparator) 根据 Comparator 指定的顺序,返回给定集合中的最大元素 Object min(Collection) 根据元素的自然顺序,返回给定集合中的最小元素 Object min(Collection, Comparator) 根据 Comparator 指定的顺序,返回给定集合中的最小元素 int frequency(Collection, Object) 返回指定集合中指定元素的出现的次数 void copy(List dest,List src) 将src中的内容复制到dest中 boolean replaceAll(List list, Object oldVal, Object newVal) 使用新值替换 List对象的所有旧值 (1)Object max(Collection): 根据元素的自然顺序,返回给定集合中的最大元素
System.out.println("自然顺序最大元素=" + Collections.max(list))(2)Object max(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最大元素
//匿名内部类 Object maxObject = Collections.max(list, new Comparator() { @Override public int compare(Object o1, Object o2) { return ((String)o1).length() - ((String)o2).length(); } })(3)int frequency(Collection,Object): 返回指定集合中指定元素的出现次数
System.out.println("第一个 出现的次数=" + Collections.frequency(list, "第一个"));(4)void copy(List dest,List src): 将 src 中的内容复制到 dest 中
ArrayList dest = new ArrayList(); //为了完成一个完整拷贝,我们需要先给 dest 赋值,大小和 list.size()一样 for(int i = 0; i < list.size(); i++) { dest.add(""); } //拷贝 Collections.copy(dest, list);(5)boolean replaceAll(List list,Object oldVal,Object newVal): 使用新值替换 List 对象的所有旧值
//如果 list 中,有 “第一个” 就替换成 “0” Collections.replaceAll(list, "第一个", "0");
六、总结 (必背)
1、开发中如何选择集合来使用?
(1)第一步:先判断存储的类型:是一组对象?还是一组键值对?
(2)一组对象: Collection接口
List允许重复:
增删多 : LinkedList [底层维护了一个双向链表]
改查多 : ArrayList 底层维护Object类型的可变数组]
Set不允许重复:
无序 : HashSet {底层是HashMap,维护了一个哈希表即(数组+链表+红黑树)}
排序 : TreeSet
插入和取出顺序一致 : LinkedHashSet , 维护数组+双向链表
(3)一组键值对: Map 接口
键无序 : HashMap [底层是:哈希表 jdk7:数组+链表,jdk8:数组+链表+红黑树]
键排序 : TreeMap
键插入和取出顺序一致 : LinkedHashMap读取文件 :Properties
2. HashSet と TreeSet はどのように重複排除を実現しますか?
HashSet の重複排除メカニズム: hashCode()equals()、最下層は最初にオブジェクトを保存し、ハッシュ値を取得する操作を実行し、対応する値を取得します。ハッシュ値Indexを調べて、テーブルのインデックスの位置にデータが無い場合はそのまま格納し、データがある場合は等値比較[横断比較]を行います。比較後に同じでない場合は追加し、異なる場合は追加しないでください。
TreeSet 重複排除メカニズム: Comparator 匿名オブジェクトを渡す場合は、実装された比較を使用して重複排除します。メソッド If 0 が返された場合、それは同じ要素またはデータであると見なされ、追加されません。Comparator 匿名オブジェクトを渡さない場合は、追加したオブジェクトによって実装された Compareable インターフェイスの CompareTo を使用して重複を削除します。
推奨学習: 「Java ビデオ チュートリアル 」
以上がJavaで詳しく紹介されているコレクションについてのメモの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。