
ホームページ >バックエンド開発 >Python チュートリアル >Python マルチスレッドの解釈を学びましょう
Python マルチスレッドの解釈を学びましょう

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2022-03-02 17:35:482593ブラウズ
この記事では、python に関する関連知識を紹介します。主にマルチスレッドに関する関連知識を紹介します。マルチスレッドは、複数の異なるプログラムを同時に実行することに似ており、多くの利点があります。以下をご覧ください。皆さんのお役に立てれば幸いです。

推奨学習: python チュートリアル
スレッドの説明
マルチスレッドは、複数の異なるプログラムを実行するのと似ています。同時に、マルチスレッド操作には次の利点があります。
- スレッドを使用すると、長期にわたるプログラム タスクをバックグラウンドで処理できます。
- ユーザー インターフェイスは、ユーザーがボタンをクリックして特定のイベントの処理をトリガーすると、進行状況バーがポップアップして処理の進行状況を表示できるように、より魅力的なものにすることができます。
- プログラムの実行速度が速くなる可能性があります。
- スレッドは、ユーザー入力、ファイルの読み取りと書き込み、ネットワークでのデータの送受信などの待機中のタスクを実装する場合に便利です。この場合、メモリ使用量などの貴重なリソースを解放できます。
スレッドは実行中のプロセスとはやはり異なります。それぞれの独立したスレッドには、プログラム実行のエントリ ポイント、順次実行シーケンス、およびプログラムの終了ポイントがあります。ただし、スレッドは独立して実行できず、アプリケーション プログラム内に存在する必要があり、アプリケーション プログラムは複数のスレッドの実行制御を提供します。
各スレッドには、スレッドのコンテキストと呼ばれる独自の CPU レジスタのセットがあり、スレッドが最後に実行した CPU レジスタの状態を反映します。
- 命令ポインタ と スタック ポインタ レジスタ は、スレッド コンテキストで最も重要な 2 つのレジスタです。スレッドは常にプロセスのコンテキストで実行されます。これらのアドレスは、メモリの所有権をマークするために使用されます。スレッドのプロセスのアドレス空間。 スレッドをプリエンプト(中断)することができます。
他のスレッドの実行中にスレッドを保留 (スリープとも言います) することができます。これをスレッド バックオフと呼びます。
スレッドは次のように分類できます。
- カーネルスレッド:オペレーティングシステムのカーネルによって作成および取り消されます。
- ユーザー スレッド: カーネル サポートなしでユーザー プログラムに実装されたスレッド。
- _thread
- threading (推奨)
機能: _thread モジュールの start_new_thread() 関数を呼び出して、新しいスレッドを生成します。構文は次のとおりです。
_thread.start_new_thread ( function, args[, kwargs] )- パラメータの説明:
- function - スレッド関数。
- args - スレッド関数に渡されるパラメータ。タプル型である必要があります。
- kwargs - オプションのパラメータ。
#!/usr/bin/python3 import _thread import time # 为线程定义一个函数 def print_time( threadName, delay): count = 0 while count 上記のプログラムを実行した出力は次のとおりです: <p><br><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/067/9e54370fdafb34f8739135c680e1aa53-0.png" class="lazy" alt="Python マルチスレッドの解釈を学びましょう"></p>Threading module<h2></h2> Python3 は 2 つの標準に合格しています。ライブラリ _thread と threading はスレッドのサポートを提供します。 <p></p>
- _thread は、低レベルのプリミティブ スレッドと単純なロックを提供しますが、その機能はスレッド モジュールに比べて比較的限定されています。
- _thread モジュールのすべてのメソッドに加えて、スレッド モジュールには他のメソッドも提供されます。
- threading.currentThread(): 現在のスレッド変数を返します。
- threading.enumerate():
- 実行中のスレッドを含むリストを返します。実行中とは、スレッドの開始後から終了までを指します。開始前と終了後のスレッドは除きます。
threading.activeCount(): - 実行中のスレッドの数を返します。これは、len(threading.enumerate()) と同じ結果になります。
- join([time]): スレッドが終了するまで待ちます。これにより、スレッドの join() メソッドが中止されるか、正常に終了するか、未処理の例外がスローされるか、またはオプションのタイムアウトが発生するまで、呼び出しスレッドがブロックされます。
- isAlive(): スレッドがアクティブかどうかを返します。
-
getName(): スレッド名を返します。 - setName(): スレッド名を設定します。
- スレッド モジュールを使用してスレッドを作成する
- threading.Thread から直接継承して新しいサブクラスを作成し、インスタンス化後に start() メソッドを呼び出して新しいスレッドを開始できます。 、つまり、スレッドの run() メソッドを呼び出します:
#!/usr/bin/python3
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("开始线程:" + self.name)
print_time(self.name, self.counter, 5)
print ("退出线程:" + self.name)
def print_time(threadName, delay, counter):
while counter:
if exitFlag:
threadName.exit()
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
# 创建新线程
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# 开启新线程
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print ("退出主线程")
上記のプログラムの実行結果は次のとおりです:
线程同步
如果多个线程共同对某个数据修改,则可能出现不可预料的结果,为了保证数据的正确性,需要对多个线程进行同步。
使用 Thread 对象的 Lock 和 Rlock 可以实现简单的线程同步,这两个对象都有 acquire 方法和 release 方法,对于那些需要每次只允许一个线程操作的数据,可以将其操作放到 acquire 和 release 方法之间。如下:
多线程的优势在于可以同时运行多个任务(至少感觉起来是这样)。但是当线程需要共享数据时,可能存在数据不同步的问题。
考虑这样一种情况:一个列表里所有元素都是0,线程"set"从后向前把所有元素改成1,而线程"print"负责从前往后读取列表并打印。
那么,可能线程"set"开始改的时候,线程"print"便来打印列表了,输出就成了一半0一半1,这就是数据的不同步。为了避免这种情况,引入了锁的概念。
锁有两种状态——锁定和未锁定。每当一个线程比如"set"要访问共享数据时,必须先获得锁定;如果已经有别的线程比如"print"获得锁定了,那么就让线程"set"暂停,也就是同步阻塞;等到线程"print"访问完毕,释放锁以后,再让线程"set"继续。
经过这样的处理,打印列表时要么全部输出0,要么全部输出1,不会再出现一半0一半1的尴尬场面。
实例:
#!/usr/bin/python3
import threading
import time
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("开启线程: " + self.name)
# 获取锁,用于线程同步
threadLock.acquire()
print_time(self.name, self.counter, 3)
# 释放锁,开启下一个线程
threadLock.release()
def print_time(threadName, delay, counter):
while counter:
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
threadLock = threading.Lock()
threads = []
# 创建新线程
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# 开启新线程
thread1.start()
thread2.start()
# 添加线程到线程列表
threads.append(thread1)
threads.append(thread2)
# 等待所有线程完成
for t in threads:
t.join()
print ("退出主线程")
执行以上程序,输出结果为: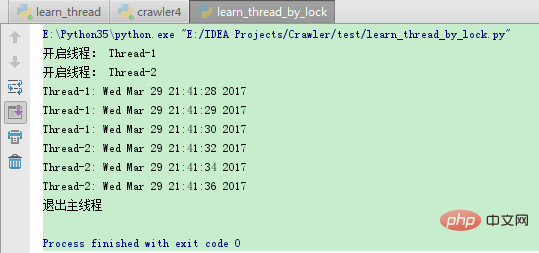
线程优先级队列(Queue)
Python 的 Queue 模块中提供了同步的、线程安全的队列类,包括FIFO(先入先出)队列Queue,LIFO(后入先出)队列LifoQueue,和优先级队列 PriorityQueue。
这些队列都实现了锁原语,能够在多线程中直接使用,可以使用队列来实现线程间的同步。
Queue 模块中的常用方法:
- Queue.qsize() 返回队列的大小
- Queue.empty() 如果队列为空,返回True,反之False
- Queue.full() 如果队列满了,返回True,反之False
- Queue.full 与 maxsize 大小对应
- Queue.get([block[, timeout]])获取队列,timeout等待时间
- Queue.get_nowait() 相当Queue.get(False)
- Queue.put(item) 写入队列,timeout等待时间
- Queue.put_nowait(item) 相当Queue.put(item, False)
- Queue.task_done() 在完成一项工作之后,Queue.task_done()函数向任务已经完成的队列发送一个信号
- Queue.join() 实际上意味着等到队列为空,再执行别的操作
实例:
#!/usr/bin/python3
import queue
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, q):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.q = q
def run(self):
print ("开启线程:" + self.name)
process_data(self.name, self.q)
print ("退出线程:" + self.name)
def process_data(threadName, q):
while not exitFlag:
queueLock.acquire()
if not workQueue.empty():
data = q.get()
queueLock.release()
print ("%s processing %s" % (threadName, data))
else:
queueLock.release()
time.sleep(1)
threadList = ["Thread-1", "Thread-2", "Thread-3"]
nameList = ["One", "Two", "Three", "Four", "Five"]
queueLock = threading.Lock()
workQueue = queue.Queue(10)
threads = []
threadID = 1
# 创建新线程
for tName in threadList:
thread = myThread(threadID, tName, workQueue)
thread.start()
threads.append(thread)
threadID += 1
# 填充队列
queueLock.acquire()
for word in nameList:
workQueue.put(word)
queueLock.release()
# 等待队列清空
while not workQueue.empty():
pass
# 通知线程是时候退出
exitFlag = 1
# 等待所有线程完成
for t in threads:
t.join()
print ("退出主线程")
以上程序执行结果: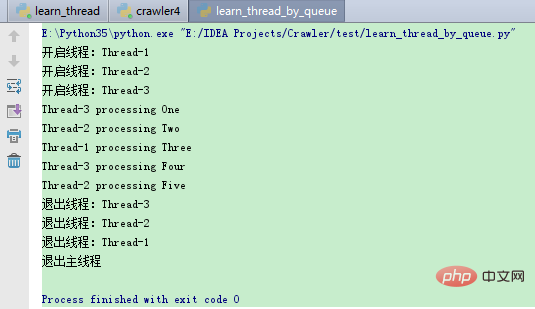
推荐学习:python学习教程
以上がPython マルチスレッドの解釈を学びましょうの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。