
ホームページ >データベース >mysql チュートリアル >リレーショナル データベース mysql 3: SQL のライフ サイクルから始める
リレーショナル データベース mysql 3: SQL のライフ サイクルから始める

- coldplay.xixi転載
- 2020-11-13 17:16:472987ブラウズ
mysql チュートリアル 列では、リレーショナル データベースにおける SQL のライフ サイクルを紹介します。
MYSQL クエリ処理
SQL の実行プロセスは基本的に mysql アーキテクチャと同じです
実行プロセス:
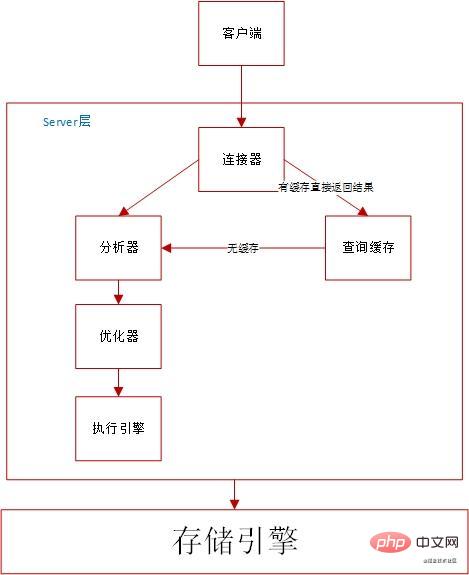
コネクター:
コネクター:
- # コネクタ:
- MySQL との接続を確立し、SQL ステートメントのクエリと権限の決定に使用されます。
クエリ キャッシュ:
ステートメントがクエリ キャッシュにない場合、後続の実行フェーズが続行されます。実行が完了すると、実行結果はクエリ キャッシュに保存されます。#クエリがキャッシュにヒットした場合、MySQL は後続の複雑な操作を実行せずに結果を直接返すことができるため、効率が向上します
# アナライザー:
SQL ステートメントに対してハード解析を実行します。アナライザーは最初に字句解析を実行します。 SQL ステートメントのコンポーネントを分析します。入力したSQL文が構文規則を満たしているかどうかを判定します。
- オプティマイザー:
- オプティマイザーは、テーブルに複数のインデックスがある場合、またはステートメントに複数のテーブルの関連付け (結合) がある場合に、どのインデックスを使用するかを決定し、各テーブルの接続シーケンスを決定します。異なる実行方法の論理結果は同じですが、実行効率は異なります。オプティマイザーの役割は、どのソリューションを使用するかを決定することです。
- 実行者:
#インデックスなし: InnoDB エンジン インターフェイスを呼び出してこのテーブルの最初の行を取得し、SQL クエリ条件を判断し、そうでない場合はスキップします。この行を結果セットに格納する; エンジン インターフェイスを呼び出す 次の行を取得し、テーブルの最後の行を取得するまで同じ判断ロジックを繰り返します。エグゼキューターは、上記の走査プロセス中に条件を満たすすべての行で構成されるレコード セットを結果セットとしてクライアントに返します。実行計画を理解する
何が行われるのかEXPLAIN コマンドの出力 MySQL SQL ステートメントを実行しますが、データは返されません
- 使用方法
[root@localhost][(none)]> explain select * from 表名 where project_id = 36; +----+-------------+--------------------------+------------+------+---------------+------------+---------+-------+--------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------------------------+------------+------+---------------+------------+---------+-------+--------+----------+-------+ | 1 | SIMPLE | 表名 | NULL | ref | project_id | project_id | 4 | const | 797964 | 100.00 | NULL | +----+-------------+--------------------------+------------+------+---------------+------------+---------+-------+--------+----------+-------+复制代码
id 上から同じ実行順序to一番下へ
- idが異なります。idの値が大きいほど優先度が高く、早く実行されます。
- select_type
- SIMPLE : 単純な選択クエリ。クエリにはサブタイトルは含まれません。 クエリまたはユニオン
- PRIMARY: クエリにはサブパートが含まれており、最も外側のクエリはプライマリとしてマークされます。
- DERIVED: これはサブクエリの一部です。
- DEPENDENT SUBQUERY: Sub クエリ内の最初の SELECT。サブクエリは外部クエリの結果に依存します。
- SUBQUERY は、サブクエリが select または where リストに含まれていることを意味します。
- MATERIALIZED: where サブクエリの後の in 条件を意味します
UNION: Union 内の 2 番目以降の select ステートメントを表します
- UNION RESULT: Union の結果
テーブル オブジェクト###type#########system > const > eq_ref > ref > range > Index > ALL (クエリ効率)###
- system:表中只有一条数据,这个类型是特殊的const类型
- const:针对于主键或唯一索引的等值查询扫描,最多只返回一个行数据。速度非常快,因为只读取一次即可。
- eq_ref:此类型通常出现在多表的join查询,表示对于前表的每一个结果,都只能匹配到后表的一行结果,并且查询的比较操作通常是=,查询效率较高
- ref:此类型通常出现在多表的join查询,针对于非唯一或非主键索引,或者是使用了最左前缀规则索引的查询
- range:范围扫描 这个类型通常出现在 <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, IN() 操作中
- index:索引树扫描
- ALL:全表扫描(full table scan)
possible_keys
- 可能使用的索引,注意不一定会使用
- 查询涉及到的字段上若存在索引,则该索引将被列出来
- 当该列为NULL时就要考虑当前的SQL是否需要优化了
key
- 显示MySQL在查询中实际使用的索引,若没有使用索引,显示NULL。
- 查询中若使用了覆盖索引(覆盖索引:索引的数据覆盖了需要查询的所有数据),则该索引仅出现在key列表中
key_length
- 索引长度
ref
- 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
rows
- 返回估算的结果集数目,并不是准确的值
filtered
- 示返回结果的行数占需读取行数的百分比, filtered 的值越大越好
extra
- Using where:表示优化器需要通过索引回表,之后到server层进行过滤查询数据
- Using index:表示直接访问索引就足够获取到所需要的数据,不需要回表
- Using index condition:在5.6版本后加入的新特性(Index Condition Pushdown)
- Using index for group-by:使用了索引来进行GROUP BY或者DISTINCT的查询
- Using filesort:当 Extra 中有 Using filesort 时, 表示 MySQL 需额外的排序操作, 不不能通过索引顺序达到排序效果. 一般有 Using filesort, 都建议优化去掉, 因为这样的查询 CPU 资源消耗大
- Using temporary 临时表被使用,时常出现在GROUP BY和ORDER BY子句情况下。(sort buffer或者磁盘被使用)
光看 filesort 字面意思,可能以为是要利用磁盘文件进行排序,实则不全然。 当MySQL不能使用索引进行排序时,就会利用自己的排序算法(快速排序算法)在内存(sort buffer)中对数据进行排序,如果内存装载不下,它会将磁盘上的数据进行分块,再对各个 数据块进行排序,然后将各个块合并成有序的结果集(实际上就是外排序)。
当对连接操作进行排序时,如果ORDER BY仅仅引用第一个表的列,MySQL对该表进行filesort操作,然后进行连接处理,此时,EXPLAIN输出“Using filesort”;否则,MySQL必 须将查询的结果集生成一个临时表,在连接完成之后行行filesort操作,此时,EXPLAIN输出“Using temporary;Using filesort”。
提高查询效率
正确使用索引
为解释方便,来一个demo:
DROP TABLE IF EXISTS user; CREATE TABLE user( id int AUTO_INCREMENT PRIMARY KEY, user_name varchar(30) NOT NULL, gender bit(1) NOT NULL DEFAULT b’1’, city varchar(50) NOT NULL, age int NOT NULL )ENGINE=InnoDB DEFAULT CHARSET=utf8; ALTER TABLE user ADD INDEX idx_user(user_name , city , age); 复制代码
什么样的索引可以被使用?
- **全匹配:**SELECT * FROM user WHERE user_name='JueJin'AND age='5' AND city='上海';(与where后查询条件的顺序无关)
- 匹配最左前缀:(user_name )、(user_name, city)、(user_name , city , age)(满足最左前缀查询条件的顺序与索引列的顺序无关,如:(city, user_name)、(age, city, user_name))
- **匹配列前缀:**SELECT * FROM user WHERE user_name LIKE 'W%'
- **匹配范围值:**SELECT * FROM user WHERE user_name BETWEEN 'W%' AND 'Z%'
什么样的索引无法被使用?
- **where查询条件中不包含索引列中的最左索引列,则无法使用到索引: **
SELECT * FROM user WHERE city='上海';
SELECT * FROM user WHERE age='26';
SELECT * FROM user WHERE age='26' AND city=‘上海';
- #**クエリ条件が where が一番左のインデックス列であっても、そのインデックスを使用してユーザー名が N で終わるユーザーをクエリすることはできません: **
SELECT * FROM user WHERE user_name LIKE '%N';
- **where クエリ条件に特定の列の範囲クエリがある場合、右側のすべての列はインデックス最適化クエリを使用できません: **
SELECT * FROM user WHERE user_name='JueJin' AND city LIKE '上%' AND age=31;
- **インデックス列を式の一部にすることはできません。これらは関数のパラメータとして使用できますか。そうでない場合は、インデックス クエリは使用できません。 **
SELECT * FROM user WHERE user_name=concat(user_name,'PLUS');
適切なインデックス列の順序を選択します
- インデックス列の順序は、複合インデックスの作成において非常に重要です。正しいインデックス順序は、インデックスを使用するクエリのクエリ方法によって異なります。
- 複合インデックスのインデックス順序については、最も選択的なインデックスは次のとおりです。列はインデックスの先頭に配置されます。このルールは、プレフィックス インデックスの選択方法と一致しています。これは、次の順序を意味するものではありません。このルールを使用して、すべての結合インデックスを決定できます。また、特定のクエリ シナリオに従って決定する必要もあります。インデックスの順序
- カバーするインデックス条件
- SELECT user_name, city, age FROM user WHERE user_name='Tony' AND age='28' AND city= '上海';
Using Indexであり、カバリング インデックスが使用されていることを証明します。カバリング インデックスにより、アクセス パフォーマンスが大幅に向上します。
ソートにインデックスを使用する
ソート操作中にインデックスをソートに使用できる場合、ソートの速度が大幅に向上します。ソートにインデックスを使用するには、次の手順を実行します。 2 つの点を満たしている必要があります。 以上です:
ORDER BY 句の後の列の順序は、結合インデックスの列の順序、およびすべての並べ替えの並べ替え方向 (順方向/逆方向) と一致している必要があります。列は一貫している必要があります- クエリされたフィールド値はインデックス列に含まれ、カバーインデックスを満たす必要があります
- 利用可能な並べ替えデモ:
- SELECT ユーザー名、都市、年齢 FROM ユーザーテスト ORDER BY ユーザー名,都市;
- SELECT ユーザー名、都市、年齢 FROM ユーザーテスト ORDER BY ユーザー名 DESC, city DESC;
- SELECT user_name , city, age FROM user_test WHERE user_name='Tony' ORDER BY city;
- 並べ替えは利用できませんdemo:
- 性別
- ; SELECT ユーザー名、都市、年齢、 性別
- FROM ユーザーテスト ORDER BY ユーザー名; SELECT ユーザー名、都市、年齢 FROM ユーザーテスト ORDER BY ユーザー名 ASC
- ,都市 DESC; SELECT ユーザー名、都市、年齢 FROM ユーザーテスト WHERE ユーザー名 LIKE 'W %'
- ORDER BY city; データ取得の提案
LIMIT
: MySQL は必要な量のデータを返すことができません。つまり、MySQL は常にすべてのデータをクエリします。LIMIT 句を使用するのは、実際にはネットワーク データ送信の圧力を軽減するためであり、ネットワーク データ転送の負荷が軽減されるわけではありません。読み取られたデータの行数。
不要な列の削除SELECT * ステートメントは、フィールド内のデータが呼び出し側アプリケーションにとって有用かどうかに関係なく、テーブル内のすべてのフィールドを削除します。これはサーバー リソースの無駄を引き起こし、サーバーのパフォーマンスに一定の影響を与えることもあります。
- ##将来テーブルの構造が変更された場合、SELECT * ステートメントは不正なデータを取得する可能性があります
- SELECT * ステートメントを実行するときは、最初にテーブル内の列を確認する必要があります。その後、SELECT * ステートメントの実行を開始できます。これにより、場合によってはパフォーマンスの問題が発生します。
- SELECT * ステートメントの使用上書きが発生しない インデックスはクエリのパフォーマンスの最適化に役立たない
- インデックスを正しく使用する利点
- フル テーブル スキャンを回避する
- 単一テーブルをクエリする場合、フル テーブル スキャンでは各行をクエリする必要があります
- 複数のテーブルをクエリする場合、フル テーブル スキャンはテーブル スキャンでは、少なくともすべてのテーブルのすべての行を取得する必要があります
- 速度の向上
- 結果セットの最初の行をすばやく見つけることができます
- 無関係な除外結果 ##各行の MIN() または MAX() 値をチェックする必要はありません
- 並べ替えとグループ化の効率を向上させます
- カバーリング インデックスを使用できます。行のループアップを回避できます。
- インデックスが多すぎると、データの変更が遅くなります
- 影響を受けるインデックスを更新する必要があります
- 書き込み集中型の環境では非常にストレスがかかります
- インデックスはディスクを大量に消費しますスペース
- InnoDB ストレージ エンジンはインデックスとデータを一緒に保存します
- ディスク スペースを監視する必要があります
- WHERE 句の列
- ORDER BY または GROUP BY 句の列
- テーブル結合条件列
- より高速な比較とループアップが可能になります
- ディスク I/O
- #全テーブル スキャンを回避することを検討してください。
- #インデックスを追加してみてください。
- テーブル接続条件
- ストレージ エンジン層の最適化を検討する
- テーブルの接続方法をチューニングする
- SELECT STRAIGHT_JOIN を使用してテーブルの接続順序を強制します。
- ORDER BY および GROUP BY の列にインデックスを追加します。
- 結合接続は必ずしもサブクエリより効率的であるとは限りません
関連する無料の学習に関する推奨事項:mysql チュートリアル ###### (ビデオ)#########
以上がリレーショナル データベース mysql 3: SQL のライフ サイクルから始めるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。