
ホームページ >ウェブフロントエンド >jsチュートリアル >最適化のヒント! !フロントエンドの新人がインターフェースを 60% 高速化
最適化のヒント! !フロントエンドの新人がインターフェースを 60% 高速化

- coldplay.xixi転載
- 2020-11-11 17:28:012264ブラウズ
javascriptこのコラムでは、フロントエンドの新人がインターフェースを 60% 高速化するために使用するテクニックを紹介します。

私は毎日叔父のところに来て、混乱と不安の中で毎日を過ごしています私は実際には無駄だと認めなければなりません低レベルのフロントエンド エンジニアとして、 私は最近、10 年以上受け継がれてきた古いインターフェイスを扱いました。それは、非常に複雑なロジックをすべて継承しています1 回の呼び出しで CPU 負荷が毎日 90% 増加する可能性があると言われています。さまざまな不満とアルツハイマー病の治療に特化したこのインターフェイスの時間のかかることに感謝しましょう
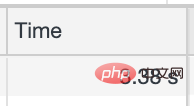 ##平均通話時間は 3 秒以上です
##平均通話時間は 3 秒以上です
ページ上で重大な逆転現象が発生しました
さまざまな詳細な分析と専門家との Q&A の結果
最終結論は医療の放棄です
魯迅「狂人の日記」「
私を倒せるのは女と酒だけで虫ではない 「私が暗闇にいるときはいつも
この文はいつも私に光を見ることを可能にします
だから今回はタフにならなければなりません
私は決めましたノード プロキシ レイヤーを作成するには
次の 3 つの方法を使用して最適化します:
- ロード オン デマンド ->graphQL
-
#コード アドレス: github
データ プール ルートの定義
- データ プール内のデータ構造スキーマの記述
- クエリ データ クエリのカスタマイズ
- データ プールの定義
// 数据池var root = { girls: [{ id: 1, name: '女神一', iphone: 12345678910, weixin: 'xixixixi', height: 175, school: '剑桥大学', wheel: [{ name: '备胎1号', money: '24万元' }, { name: '备胎2号', money: '26万元' }]
},
{ id: 2, name: '女神二', iphone: 12345678910, weixin: 'hahahahah', height: 168, school: '哈佛大学', wheel: [{ name: '备胎3号', money: '80万元' }, { name: '备胎4号', money: '200万元' }]
}]
}复制代码上記のコードは女神情報のスキーマです。 最初に、type Query
を使用して、女の子に関する多くの情報を含む女神情報のクエリを定義します。Info
。この情報は配列の束であるため、[情報]名前、携帯電話 (iphone)、WeChat (weixin) など、女の子に関するすべての情報の次元を type Info で説明します。 、身長(身長)、学校(学校)、スペアタイヤセット(ホイール)
女神の情報記述(スキーマ)を取得後、カスタマイズ可能 各種メッセージ女神からのものを組み合わせます。
const { buildSchema } = require('graphql');// 描述数据结构 schemavar schema = buildSchema(`
type Wheel {
name: String,
money: String
}
type Info {
id: Int
name: String
iphone: Int
weixin: String
height: Int
school: String
wheel: [Wheel]
}
type Query {
girls: [Info]
}
`);复制代码
フィルタリング結果は次のとおりです。
別の例は、女神とさらに発展させたい場合です。彼女のスペアタイヤの情報を入手し、彼女のスペアタイヤがどれだけのお金を持っているかを調べ、配偶者を選ぶ際にあなたが優先できるかどうかを分析する必要があります。クエリ ルール コードは次のとおりです:
const { graphql } = require('graphql');// 定义查询内容const query = `
{
girls {
name
weixin
}
}
`;// 查询数据const result = await graphql(schema, query, root)复制代码
フィルタ結果は次のとおりです: 
女神の例を使用して、データをロードする方法を示します。オンデマンドでgraphQLを介して。
当社のビジネスの特定のシナリオにマッピングすると、Tianxiu インターフェイスから返される各データには 100 個のフィールドが含まれます。フィールドのうち 10 個を取得するようにスキーマを構成し、残りの 90 個の不要なフィールドの送信を回避します。 
あなたの本当の気持ちは女性の前で言う価値はありません私たちは女性の好きなことをすることを学ばなければなりません出てきたら車のキーを見せて、もしそうならあなたの才能を誇示してくださいあなたは車を持っていません
#今夜、私はあなたと共有したい祖先の染色体を持っています。
大丈夫です。そうでない場合は、次の染色体に変更してください
単純かつ大雑把な本題に進みます
キャッシュ-> redis
2 番目の最適化方法は、redis キャッシュを使用することです
天秀老接口内部调用了另外三个老接口,而且是串行调用,极其耗时耗资源,秀到你头皮发麻
我们用redis来缓存天秀接口的聚合数据,下次再调用天秀接口,直接从缓存中获取数据即可,避免高耗时的复杂调用,简化后代码如下:
const redis = require("redis");const { promisify } = require("util");// 链接redis服务const client = redis.createClient(6379, '127.0.0.1');// promise化redis方法,以便用async/awaitconst getAsync = promisify(client.get).bind(client);const setAsync = promisify(client.set).bind(client);async function list() { // 先获取缓存中数据,没有缓存就去拉取天秀接口
let result = await getAsync("缓存"); if (!result) { // 拉接口
const data = await 天秀接口();
result = data; // 设置缓存数据
await setAsync("缓存", data)
} return result;
}
list();
复制代码
先通过getAsync来读取redis缓存中的数据,如果有数据,直接返回,绕过接口调用,如果没有数据,就会调用天秀接口,然后setAsync更新到缓存中,以便下次调用。因为redis存储的是字符串,所以在设置缓存的时候,需要加上JSON.stringify(data),为了便于大家理解,我就不加了,会把具体细节代码放在github中。
将数据放在redis缓存里有几个好处
可以实现多接口复用、多机共享缓存
这就是传说中的云备胎
追求一个女神的成功率是1%
同时追求100个女神,那你获取到一个女神的概率就是100%
鲁迅《狂人日记》里曾说过:“舔一个是舔狗,舔一百个你就是战狼”
你是想当舔狗还是当战狼?
来吧,缓存用起来,redis用起来
轮询更新 -> schedule
最后一个优化手段:轮询更新 -> schedule
女神的备胎用久了,会定时换一批备胎,让新鲜血液进来,发现新的快乐
缓存也一样,需要定时更新,保持与数据源的一致性,代码如下:
const schedule = require('node-schedule');// 每个小时更新一次缓存schedule.scheduleJob('* * 0 * * *', async () => { const data = await 天秀接口(); // 设置redis缓存数据
await setAsync("缓存", data)
});复制代码
天秀接口不是一个强实时性接口,数据源一周可能才会变一次
所以我们根据实际情况用轮询来设置更新缓存频率
我们用node-schedule这个库来轮询更新缓存,* * 0 * * *这个的意思就是设置每个小时的第0分钟就开始执行缓存更新逻辑,将获取到的数据更新到缓存中,这样其他接口和机器在调用缓存的时候,就能获取到最新数据,这就是共享缓存和轮询更新的好处。
早年我在当舔狗的时候,就将轮询机制发挥到淋漓尽致
每天向白名单里的女神,定时轮询发消息
无限循环云跪舔三件套:
- “啊宝贝,最近有没有想我”
- “啊宝贝早安安”
- “宝贝晚安,么么哒”
虽然女神依然看不上我
但仍然时刻准备着为女神服务
结尾
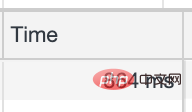
经过以上三个方法优化后
接口请求耗时从3s降到了860ms
这些代码都是从业务中简化后的逻辑
真实的业务场景远比这要复杂:分段式数据存储、主从同步 读写分离、高并发同步策略等等
每一个模块都晦涩难懂
就好像每一个女神都高不可攀
屌丝战胜了所有bug,唯独战胜不了她的心
受伤了只能在深夜里独自买醉
但每当梦到女神打开我做的页面
被极致流畅的体验惊艳到
在精神高潮中享受灵魂升华
那一刻
我觉得我又行了
(完)
相关免费学习推荐:JavaScript(视频)
以上が最適化のヒント! !フロントエンドの新人がインターフェースを 60% 高速化の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。