
ホームページ >バックエンド開発 >Python チュートリアル >Python は Douban ムービー データをクロールし、値 xpath および lxml モジュール (コード) を抽出します。
Python は Douban ムービー データをクロールし、値 xpath および lxml モジュール (コード) を抽出します。

- 不言転載
- 2018-09-28 14:45:343960ブラウズ
この記事で紹介する内容は、Python が Douban の動画データをクローリングし、値の xpath および lxml モジュール (コード) を抽出するものです。一定の参考値があります。困っている友人は参考にしてください。お役に立てば幸いです。 。 ヘルプ。
ツール: Python 3.6.5、PyCharm 開発ツール、Windows 10 オペレーティング システム、Google Chrome
目的: Douban 映画ランキング内の映画のタイトル、リンク アドレスをクロールする、写真、レビュアー数、評価など。
ウェブサイト: https://movie.douban.com/chart
文法ポイント:
xパス構文:
Google Chrome は xpath ヘルパー プラグインをインストールします: 要素からのデータの検索にご協力ください
1. ノード (ラベル) を選択します
(1 ),/html/ head/meta: html のすべてのメタ タグを選択できます
(2), //li: 現在のページのすべての li タグ
(3), /html/head//link: head 下のすべてのリンクタグ
##2, //: 任意のノードから選択可能
(1)、//li:現在のページ上のすべての li タグ
##(2)、/html/head//link:head すべてのリンク3. @ シンボルの目的
(1) 特定の要素を選択します: //p[ @class=' feed']/ul/li、
class='feed'
(2) の p の下の ul の下で li を選択、a/ @href: a
4 の href 値を選択します。テキストを取得## ( 1), /a/text (): a
の下のテキストを取得します。(2)、/a//text(): Text
の下のすべてのテキストを取得します。 ############例###:######################### ######## ##lxml 構文:
1. インストール: pip install lxml2.
## を使用します。 # from lxml import etree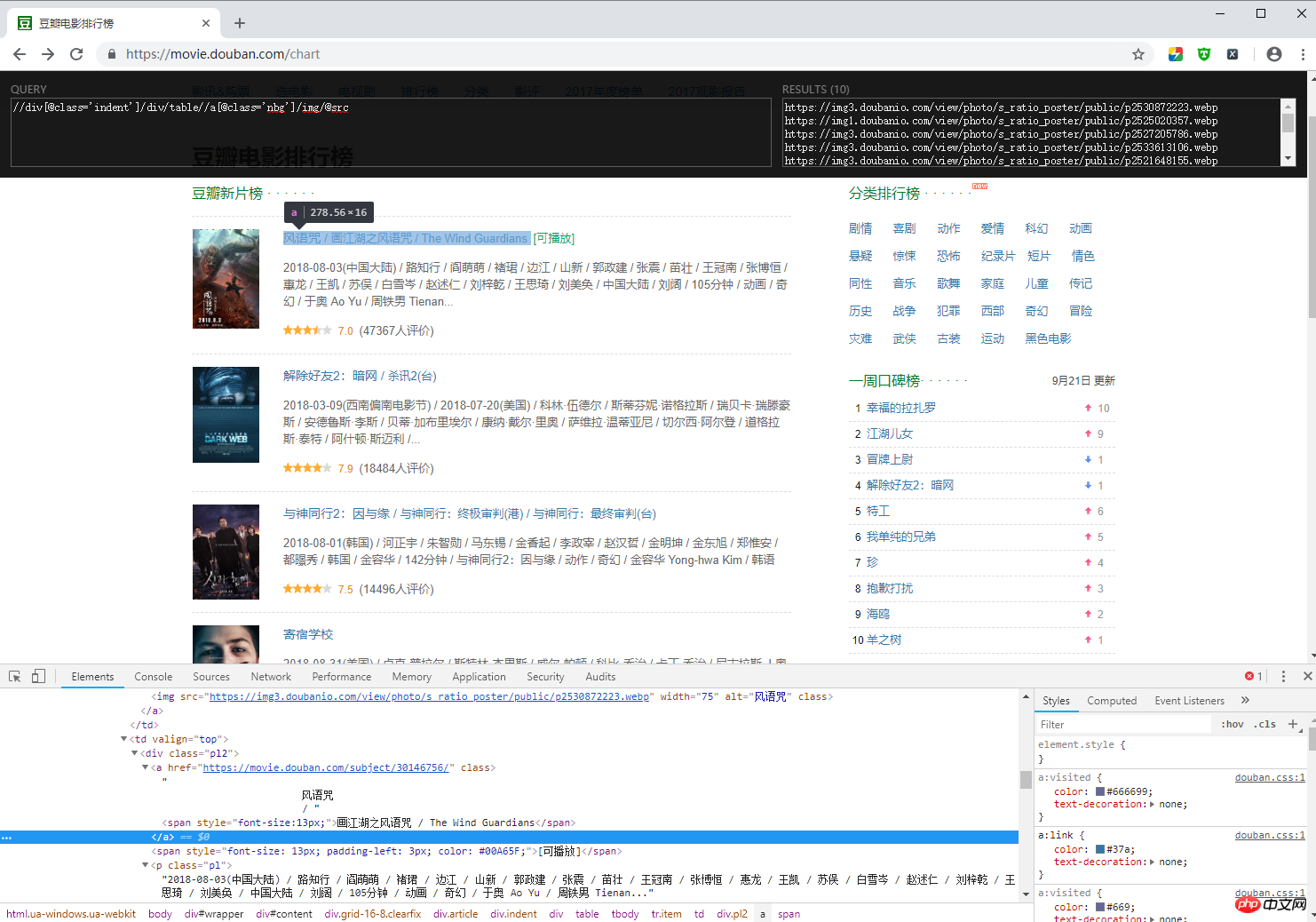
## element = etree.HTML("html string ")
element.xpath("")
コード:
from lxml import etree
import requests
url = "https://movie.douban.com/chart"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"
}
response = requests.get(url,headers=headers)
html_str = response.content.decode()
#print(html_str)
html = etree.HTML(html_str)
print(html)
#1.获取所有的电影的URL地址
#url_list = html.xpath("//div[@class='indent']/div/table//div[@class='pl2']/a/@href")
#print(url_list)
#2.所有图片的地址
#img_list = html.xpath("//div[@class='indent']/div/table//a[@class='nbg']/img/@src")
#print(img_list)
ret1 = html.xpath("//div[@class='indent']/div/table")
print(ret1)
for table in ret1:
item = {}
item["title"] = table.xpath(".//div[@class='pl2']/a/text()")[0].replace("/","").strip()
item["href"] = table.xpath(".//div[@class='pl2']/a/@href")[0]
item["img"] = table.xpath(".//a[@class='nbg']/img/@src")[0]
item["comment_num"] = table.xpath(".//span[@class='pl']/text()")[0]
item["rating_num"] = table.xpath(".//span[@class='rating_nums']/text()")[0]
print(item)
ランニング効果:
以上がPython は Douban ムービー データをクロールし、値 xpath および lxml モジュール (コード) を抽出します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。