
ホームページ >バックエンド開発 >Python チュートリアル >Python クロール記事のサンプル チュートリアル
Python クロール記事のサンプル チュートリアル
- 巴扎黑オリジナル
- 2017-08-07 17:37:451967ブラウズ
この記事では、主に Python を使用して散文 Web サイトの記事をクロールするための関連情報を紹介します。記事内の紹介は非常に詳細であり、必要な友人は以下を参照してください。
この記事では、主に Python クローリング散文ネットワーク記事に関する関連コンテンツを紹介します。参考と学習のために共有されています。詳細な紹介を見てみましょう:
レンダリングは次のとおりです。
 Configure python 2.7
Configure python 2.7
bs4 requestsインストール Use pip to install
sudo pip install bs4sudo pip install requests
sudo pip install bs4
<html> <head> </head> <body> <p id="one"><a></a></p> <p id="two"><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >abc</a></p> <p id="three"><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >three a</a><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >three a</a><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >three a</a></p> <p id="four"><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >four<p>four p</p><p>four p</p><p>four p</p> a</a></p> </body> </html>
简要说明一下bs4的使用因为是爬取网页 所以就介绍find 跟find_all
find跟find_all的不同在于返回的东西不同 find返回的是匹配到的第一个标签及标签里的内容
find_all返回的是一个列表
比如我们写一个test.html 用来测试find跟find_all的区别。
内容是:
from bs4 import BeautifulSoup import lxml if __name__=='__main__': s = BeautifulSoup(open('test.html'),'lxml') print s.prettify() print "------------------------------" print s.find('p') print s.find_all('p') print "------------------------------" print s.find('p',id='one') print s.find_all('p',id='one') print "------------------------------" print s.find('p',id="two") print s.find_all('p',id="two") print "------------------------------" print s.find('p',id="three") print s.find_all('p',id="three") print "------------------------------" print s.find('p',id="four") print s.find_all('p',id="four") print "------------------------------"
然后test.py的代码为:
def get_html():
url = "https://www.sanwen.net/"
two_html = ['sanwen','shige','zawen','suibi','rizhi','novel']
for doc in two_html:
i=1
if doc=='sanwen':
print "running sanwen -----------------------------"
if doc=='shige':
print "running shige ------------------------------"
if doc=='zawen':
print 'running zawen -------------------------------'
if doc=='suibi':
print 'running suibi -------------------------------'
if doc=='rizhi':
print 'running ruzhi -------------------------------'
if doc=='nove':
print 'running xiaoxiaoshuo -------------------------'
while(i<10):
par = {'p':i}
res = requests.get(url+doc+'/',params=par)
if res.status_code==200:
soup(res.text)
i+=i运行以后我们可以看到结果当获取指定标签时候两者区别不大当获取一组标签的时候两者的区别就会显示出来
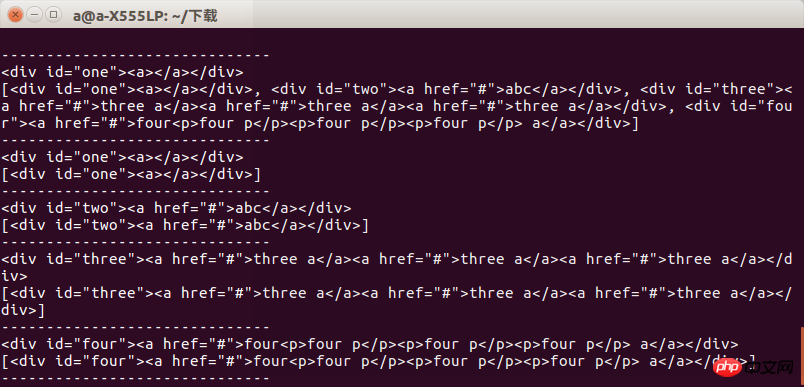
所以我们在使用时候要注意到底要的是什么,否则会出现报错
接下来就是通过requests 获取网页信息了,我不太懂别人为什么要写heard跟其他的东西
我直接进行网页访问,通过get方式获取散文网几个分类的二级网页然后通过一个组的测试,把所有的网页爬取一遍
def soup(html_text): s = BeautifulSoup(html_text,'lxml') link = s.find('p',class_='categorylist').find_all('li') for i in link: if i!=s.find('li',class_='page'): title = i.find_all('a')[1] author = i.find_all('a')[2].text url = title.attrs['href'] sign = re.compile(r'(//)|/') match = sign.search(title.text) file_name = title.text if match: file_name = sign.sub('a',str(title.text))
这部分的代码中我没有对res.status_code bs4の使い方を簡単に説明します。 find_all
find_all はリストを返します
内容は次のとおりです:
def get_content(url): res = requests.get('https://www.sanwen.net'+url) if res.status_code==200: soup = BeautifulSoup(res.text,'lxml') contents = soup.find('p',class_='content').find_all('p') content = '' for i in contents: content+=i.text+'\n' return content
その後、test.pyのコードは次のようになります:
f = open(file_name+'.txt','w') print 'running w txt'+file_name+'.txt' f.write(title.text+'\n') f.write(author+'\n') content=get_content(url) f.write(content) f.close()
実行後、指定されたタグを取得すると、結果が表示されます。タグのセットを取得すると、その 2 つの違いが表示されます
したがって、これを使用するときは、必要なことに注意する必要があります。そうでないと、エラーが発生します
次のステップは、リクエストを通じて Web ページの情報を取得することです。他の人が聞いたことやその他のことを書いている理由をよく理解しています
f = open(file_name+'.txt','w') print 'running w txt'+file_name+'.txt' f.write(title.text+'\n') f.write(author+'\n') content=get_content(url) f.write(content) f.close()
コードのこの部分では、res.status_code を修正していません。200 でない場合、エラーが表示されず、クロールされたコンテンツが失われるという問題が発生します。次に Sanwen.net/rizhi/&p=1 の Web ページを分析しました
以上がPython クロール記事のサンプル チュートリアルの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。