
ホームページ >バックエンド開発 >Python チュートリアル >Python 検証コード認識チュートリアル: 投影法と接続ドメイン法を使用した画像のセグメント化
Python 検証コード認識チュートリアル: 投影法と接続ドメイン法を使用した画像のセグメント化

- 不言オリジナル
- 2018-06-04 16:21:202886ブラウズ
この記事では主に Python 検証コード認識チュートリアルを紹介し、投影法と接続ドメイン法を使用して画像をセグメント化します。必要な友人に参照してもらいます。
今日の記事は主にLinux上で使用するPillowと画像処理ツールGIMPの検証コードの分割方法を記録します。まず、位置と幅が固定され、接着や干渉がない例を想定して、Pillow を使用して写真をカットする方法を学びます。
GIMP で画像を開いた後、プラス記号を押して画像を拡大し、[表示] -> [グリッドの表示] をクリックしてグリッド線を表示します:それらの正方形の各辺の長さは 10 ピクセルです、したがって、番号 1 のカットです。座標は、左 20、上 20、右 40、下 70 です。類推により、残りの 3 つの数字のカット位置がわかります。 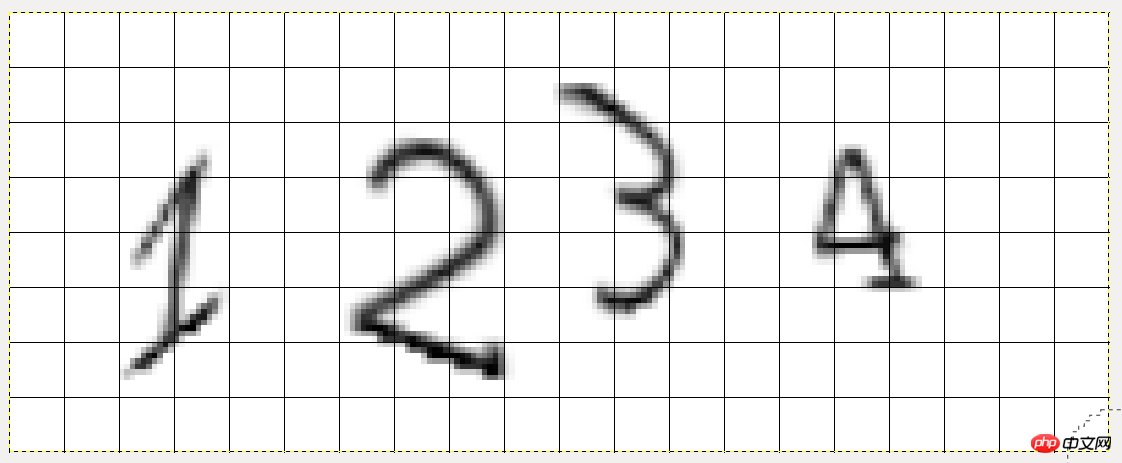
コードは次のとおりです:
from PIL import Image
p = Image.open("1.png")
# 注意位置顺序为左、上、右、下
cuts = [(20,20,40,70),(60,20,90,70),(100,10,130,60),(140,20,170,50)]
for i,n in enumerate(cuts,1):
temp = p.crop(n) # 调用crop函数进行切割
temp.save("cut%s.png" % i)
切り取った後、4つの写真が得られます:
それでは、文字の位置が固定されていない場合はどうなるでしょうか?ここで、位置幅がランダムで、接着がなく、干渉線がない場合を想定します。 
def vertical(img): """传入二值化后的图片进行垂直投影""" pixdata = img.load() w,h = img.size ver_list = [] # 开始投影 for x in range(w): black = 0 for y in range(h): if pixdata[x,y] == 0: black += 1 ver_list.append(black) # 判断边界 l,r = 0,0 flag = False cuts = [] for i,count in enumerate(ver_list): # 阈值这里为0 if flag is False and count > 0: l = i flag = True if flag and count == 0: r = i-1 flag = False cuts.append((l,r)) return cuts p = Image.open('1.png') b_img = binarizing(p,200) v = vertical(b_img)
垂直関数を通じて、X 軸に投影されたすべての黒ピクセルの左右の境界を含む位置を取得します。キャプチャは何の妨げにもならないため、しきい値は 0 に設定されます。 二値化関数については、前の記事を参照してください
出力は次のとおりです:[(21, 37), (62, 89), (100, 122), (146, 164)]
ご覧のとおり、射影法によって与えられた左右の境界は、我々ができるものに非常に近いです。手動検査で取得します。上下の境界については、めんどくさい場合は、0と画像の高さを直接使用することもできますし、ここに興味のある友人は自分で試してみることもできます。
ただし、文字間に癒着がある場合、投影法により分割エラーが発生します。たとえば、前の記事では、 しきい値を 5 に変更した後、投影法は:
[(5, 27), (33, 53), (59, 108)]
明らかに、最後の6と9の数字はカットされません。
しきい値を 7 に変更すると、結果は次のようになります:[(5, 27), (33, 53), (60, 79), (83, 108)]
したがって、単純な癒着状況の場合は、しきい値を調整することで解決することもできます。
2 番目の方法は、CFS 接続ドメイン セグメンテーション方法と呼ばれます。原理は、各文字が別々の接続されたドメインで構成されていると想定することです。つまり、接着は存在しないということです。黒ピクセルを見つけて、すべての接続された黒ピクセルが走査されマークされるまで判断を開始して、文字のセグメンテーション位置を決定します。 。アルゴリズムは次のとおりです。
2 値化された画像を左から右、上から下に走査し、黒いピクセルが見つかったが、このピクセルが訪問されていない場合は、そのピクセルをスタックにプッシュし、すでに訪問済みとしてマークします。 。
スタックが空でない場合は、周囲の 8 ピクセルの検出を続けてステップ 2 を実行します。スタックが空の場合は、1 つの文字ブロックが検出されたことを意味します。
検出が終わり、いくつかのキャラクターが決定されました。
コードは次のとおりです:
import queue
def cfs(img):
"""传入二值化后的图片进行连通域分割"""
pixdata = img.load()
w,h = img.size
visited = set()
q = queue.Queue()
offset = [(-1,-1),(0,-1),(1,-1),(-1,0),(1,0),(-1,1),(0,1),(1,1)]
cuts = []
for x in range(w):
for y in range(h):
x_axis = []
#y_axis = []
if pixdata[x,y] == 0 and (x,y) not in visited:
q.put((x,y))
visited.add((x,y))
while not q.empty():
x_p,y_p = q.get()
for x_offset,y_offset in offset:
x_c,y_c = x_p+x_offset,y_p+y_offset
if (x_c,y_c) in visited:
continue
visited.add((x_c,y_c))
try:
if pixdata[x_c,y_c] == 0:
q.put((x_c,y_c))
x_axis.append(x_c)
#y_axis.append(y_c)
except:
pass
if x_axis:
min_x,max_x = min(x_axis),max(x_axis)
if max_x - min_x > 3:
# 宽度小于3的认为是噪点,根据需要修改
cuts.append((min_x,max_x))
return cuts
呼び出し後の出力結果は、射影メソッドを使用した場合と同じです。また、インターネット上で「Flood Fill」という方法があるのを見ましたが、これも接続されたドメインと同じようです。
関連する推奨事項:
Python 検証コード認識チュートリアル - グレースケール処理、二値化、ノイズ低減、および tesserocr 認識以上がPython 検証コード認識チュートリアル: 投影法と接続ドメイン法を使用した画像のセグメント化の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。