
ホームページ >バックエンド開発 >Python チュートリアル >Pythonソケットネットワークプログラミングにおけるスティッキーパケット問題の詳細な説明
Pythonソケットネットワークプログラミングにおけるスティッキーパケット問題の詳細な説明

- 不言オリジナル
- 2018-04-28 13:36:002614ブラウズ
この記事では、Pythonソケットネットワークプログラミングの厄介な問題の詳細な説明を主に紹介し、参考にさせていただきます。一緒に見てみましょう
1. スティッキー問題の詳細
1. パケットがスティッキングするのは TCP だけであり、UDP は決してスティッキングしません。
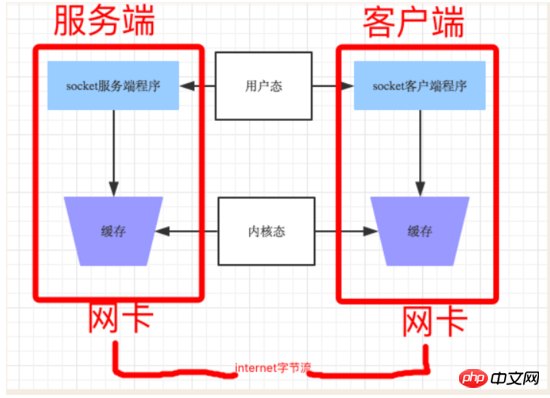
実際には、あなたのプログラムにはその権利がありません。直接操作する ネットワーク カードの場合、ネットワーク カードを操作するときは、オペレーティング システムを使用してインターフェイスをユーザー プログラムに公開するため、プログラムがデータを遠隔地に送信するたびに、実際にユーザーからデータがコピーされます。この操作はリソースと時間の点で、カーネル状態とユーザー状態の間でデータを頻繁に交換するため、送信効率の低下につながります。ソケットの効率を高めるため、送信者は多くの場合、相手にデータを送信する前に十分なデータを収集する必要があります。連続して数回送信する必要があるデータが非常に小さい場合、通常、TCP ソケットは最適化アルゴリズムに従ってデータを TCP セグメントに結合し、一度に送信するため、受信側はスティッキー パケット データを受信します。 。
2. まず、ソケットを介したメッセージの送受信の原理をマスターする必要があります。もちろん、送信者は 1k または 1k のデータを送信でき、受信側アプリケーションは 2k または 2k のデータを抽出できます。 3k 以上のデータを抽出することも可能です。つまり、アプリケーションは目に見えないため、TCP プロトコルはそのストリーム用のプロトコルであり、これが UDP に対してスティッキー パケットが発生しやすい理由でもあります。はコネクションレス型プロトコルであり、各 UDP セグメントはメッセージです。 アプリケーション プログラムはデータをメッセージ単位で抽出する必要があり、一度にデータを抽出することはできません。これは TCP とよく似ています。メッセージをどのように定義するか?相手が一度に書き込んだ/送信したデータはメッセージであると考えられます。知っておく必要があるのは、相手がメッセージを送信するとき、Dingcheng がそれをどのように断片化しても、TCP プロトコル層がデータを分類するということです。カーネル バッファに表示される前にメッセージ全体を構成するセグメント。
たとえば、TCP ベースのソケット クライアントがファイルをサーバーにアップロードする場合、ファイルの内容はバイト ストリームで 1 つずつ送信されます。バイト ストリームがどこにあるかわからない受信者にとってはさらに愚かに見えます。ファイルの開始点、終了点。3. スティッキー パケットの理由
3-1 直接的な理由
いわゆるスティッキー パケットの問題は、主に受信者がメッセージ間の境界を認識しておらず、一度に何バイトのデータを抽出すべきかが分からないことが原因で発生します。時間3-2 根本原因 送信者によって発生するスティッキー パケットは、TCP プロトコル自体によって引き起こされます。TCP の送信効率を向上させるために、送信者は TCP セグメントを送信する前に十分なデータを収集する必要があります。連続して数回送信する必要があるデータが非常に小さい場合、通常、TCP は
最適化アルゴリズム
に従ってデータを 1 つの TCP セグメントに結合し、一度に送信して、受信側がスティッキー データを受信できるようにします。3-3 まとめ
TCP (トランスポート制御プロトコル、Transmission Control Protocol) はコネクション指向かつストリーム指向であり、信頼性の高いサービスを提供します。したがって、送信側と受信側 (クライアントとサーバー) の両方に 1 組のソケットが必要であるため、複数のパケットをより効率的に受信側に送信するために、送信側では複数のデータを小さいデータと結合する最適化手法が使用されます。間隔と小さなデータ量を 1 つの大きなデータ ブロックにまとめてパッケージ化します。このようにすると、受信側で区別することが困難になるため、科学的な解凍メカニズムを提供する必要があります。 つまり、ストリーム指向の通信にはメッセージ保護の境界がありません。- UDP (ユーザー データグラム プロトコル) はコネクションレス型でメッセージ指向であり、高効率のサービスを提供します。ブロック マージ最適化アルゴリズムは使用されません。UDP は 1 対多モードをサポートするため、受信側の skbuff (ソケット バッファ) は、到着する各 UDP パケットを記録するためのチェーン構造を採用しています。メッセージの送信元アドレス、ポート、その他の情報)をパッケージに含めることで、受信側がメッセージを簡単に区別して処理できるようになります。 つまり、メッセージ指向のコミュニケーションにはメッセージ保護の境界があります。
-
tcp はデータ フローに基づいているため、送受信されるメッセージを空にすることはできません。これには、プログラムが停止するのを防ぐために、クライアントとサーバーの両方に空のメッセージ処理メカニズムを追加する必要があります。一方、udp はデータ フローに基づいています。データグラム。空のコンテンツを入力したとしても (Enter を直接押した)、それは空のメッセージではありません。 udp プロトコルはメッセージ ヘッダーをカプセル化するのに役立ちます。正しいです。sendinto(y) は、x バイトのデータを受信した後に完了します。y> の場合、パケットは受信されません。次回の受信時に、引き続き受信されます。 ack を受信すると常にバッファの内容をクリアします。データは信頼できますが、粘着性がある可能性があります。
- 2 番目に、粘着性バッグは 2 つの状況で発生します:
1. 送信側は、ローカル マシンのバッファがいっぱいになるまで送信を待つ必要があるため、スティッキー パケットが発生します (データ送信の時間間隔は非常に短く、データは非常に小さいです。Python は最適化アルゴリズムを使用して結合します)それらを一緒にしてスティッキー パケットを生成します)
クライアント
#_*_coding:utf-8_*_ import socket BUFSIZE=1024 ip_port=('127.0.0.1',8080) s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) res=s.connect_ex(ip_port) s.send('hello'.encode('utf-8')) s.send('feng'.encode('utf-8'))
サーバー
#_*_coding:utf-8_*_ from socket import * ip_port=('127.0.0.1',8080) tcp_socket_server=socket(AF_INET,SOCK_STREAM) tcp_socket_server.bind(ip_port) tcp_socket_server.listen(5) conn,addr=tcp_socket_server.accept() data1=conn.recv(10) data2=conn.recv(10) print('----->',data1.decode('utf-8')) print('----->',data2.decode('utf-8')) conn.close()
2、受信側はバッファ内のパケットを時間内に受け入れられず、その結果、複数のパケットが受け入れられます (クライアントはデータを送信し、サーバーはごく一部のみを受信し、サーバーは次回それを受信します。まだバッファーからデータが残っている場合、スティッキー パケットが生成されます) クライアント
#_*_coding:utf-8_*_ import socket BUFSIZE=1024 ip_port=('127.0.0.1',8080) s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) res=s.connect_ex(ip_port) s.send('hello feng'.encode('utf-8'))
サーバー
#_*_coding:utf-8_*_ from socket import * ip_port=('127.0.0.1',8080) tcp_socket_server=socket(AF_INET,SOCK_STREAM) tcp_socket_server.bind(ip_port) tcp_socket_server.listen(5) conn,addr=tcp_socket_server.accept() data1=conn.recv(2) #一次没有收完整 data2=conn.recv(10)#下次收的时候,会先取旧的数据,然后取新的 print('----->',data1.decode('utf-8')) print('----->',data2.decode('utf-8')) conn.close()
3 つのスティッキー パケット インスタンス:
サーバー
import socket import subprocess din=socket.socket(socket.AF_INET,socket.SOCK_STREAM) ip_port=('127.0.0.1',8080) din.bind(ip_port) din.listen(5) conn,deer=din.accept() data1=conn.recv(1024) data2=conn.recv(1024) print(data1) print(data2)
クライアント:
import socket import subprocess din=socket.socket(socket.AF_INET,socket.SOCK_STREAM) ip_port=('127.0.0.1',8080) din.connect(ip_port) din.send('helloworld'.encode('utf-8')) din.send('sb'.encode('utf-8'))
4、アンパッキングの発生
送信バッファの長さがネットワークカードのMTUより大きい場合、TCPは今回送信されたデータを分割しますいくつかのデータパケットを分割して送信します
補足質問 1: なぜ TCP は信頼できる送信であり、UDP は信頼できない送信なのか
TCP がデータを送信するとき、送信者はまずデータを自身のキャッシュに送信し、次にプロトコル制御キャッシュ内のデータを相手側に送信し、相手側は ack=1 を返します。送信側はキャッシュ内のデータをクリアし、相手側は ack=0 を返してデータを再送信するため、TCP は信頼できます。
そして、udpがデータを送信すると、相手は確認情報を返さないので信頼性がありません
補足質問2: send(バイトストリーム)、recv(1024)、sendallとは何を意味しますか?
recvで指定した1024は、一度に1024バイトのデータをキャッシュから取り出すことを意味します
sendのバイトストリームはまず自端のキャッシュに入れられ、その後キャッシュの内容が反対側に送信されますプロトコル制御下で、スロットル サイズが残りのキャッシュ スペースよりも大きい場合、データは失われますが、sendall をループ内で呼び出しても、データは失われません。
5. ベタつくバッグの問題を解決するにはどうすればよいですか?
問題の根本は、受信側が送信側によって送信されるバイトストリームの長さを知らないことです。したがって、スティッキーパケットの問題を解決する方法は、送信側がどのように送信するかに焦点を当てることです。データを送信する前にバイト ストリームを送信します。合計サイズは受信側にわかっているため、受信側はすべてのデータを受信するために無限ループを作成します。
5-1 簡単な解決策 (表面的な解決策):
パケットのスタックを避けるために、クライアントの送信時にスリープ時間を追加します。パケットのスタックを効果的に回避するために、サーバーが受信しているときにもタイム スリープが必要です。
クライアント:
#客户端 import socket import time import subprocess din=socket.socket(socket.AF_INET,socket.SOCK_STREAM) ip_port=('127.0.0.1',8080) din.connect(ip_port) din.send('helloworld'.encode('utf-8')) time.sleep(3) din.send('sb'.encode('utf-8'))
サーバー:
#服务端 import socket import time import subprocess din=socket.socket(socket.AF_INET,socket.SOCK_STREAM) ip_port=('127.0.0.1',8080) din.bind(ip_port) din.listen(5) conn,deer=din.accept() data1=conn.recv(1024) time.sleep(4) data2=conn.recv(1024) print(data1) print(data2)
上記の解決策では間違いなく多くの間違いが発生します。送信がいつ完了するかが分からず、一時停止時間が長いと問題が発生するためです。 , 短い場合は非効率になりますので、この方法は不適切です。
5-2 一般的な解決策 (問題を根本から見てみる):
問題の根本は、受信側が送信側によって送信されるバイトストリームの長さを知らないことです。スティッキー パケットの問題を解決する方法は、データを送信する前に、送信側が受信側に送信するバイト ストリームの合計サイズを通知し、受信側がすべてのデータを無限に受信する方法を中心に展開することです。ループ
カスタムの固定長ヘッダーをバイトストリームに追加します。ヘッダーにはバイトストリームの長さが含まれており、それを順番にピアに送信します。受信時に、ピアは最初に固定長ヘッダーを取り出します。キャッシュを取得してから実際のデータを取得します。
struct モジュールを使用して、4 バイトまたは 8 バイトの固定長をパックします。struct.pack.format パラメーターが「i」の場合、長さ 10 の数値のみをパックできます。その後、最初に長さを次のように変換できます。 json 文字列を作成してパッケージ化します。
通常のクライアント
# _*_ coding: utf-8 _*_ import socket import struct phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) phone.connect(('127.0.0.1',8880)) #连接服 while True: # 发收消息 cmd = input('请你输入命令>>:').strip() if not cmd:continue phone.send(cmd.encode('utf-8')) #发送 #先收报头 header_struct = phone.recv(4) #收四个 unpack_res = struct.unpack('i',header_struct) total_size = unpack_res[0] #总长度 #后收数据 recv_size = 0 total_data=b'' while recv_size<total_size: #循环的收 recv_data = phone.recv(1024) #1024只是一个最大的限制 recv_size+=len(recv_data) # total_data+=recv_data # print('返回的消息:%s'%total_data.decode('gbk')) phone.close()
通常のサーバー
# _*_ coding: utf-8 _*_
import socket
import subprocess
import struct
phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) #买手机
phone.bind(('127.0.0.1',8880)) #绑定手机卡
phone.listen(5) #阻塞的最大数
print('start runing.....')
while True: #链接循环
coon,addr = phone.accept()# 等待接电话
print(coon,addr)
while True: #通信循环
# 收发消息
cmd = coon.recv(1024) #接收的最大数
print('接收的是:%s'%cmd.decode('utf-8'))
#处理过程
res = subprocess.Popen(cmd.decode('utf-8'),shell = True,
stdout=subprocess.PIPE, #标准输出
stderr=subprocess.PIPE #标准错误
)
stdout = res.stdout.read()
stderr = res.stderr.read()
#先发报头(转成固定长度的bytes类型,那么怎么转呢?就用到了struct模块)
#len(stdout) + len(stderr)#统计数据的长度
header = struct.pack('i',len(stdout)+len(stderr))#制作报头
coon.send(header)
#再发命令的结果
coon.send(stdout)
coon.send(stderr)
coon.close()
phone.close()5-3 ソリューションの最適化バージョン (問題を根本から解決する)
厄介な問題を解決するための最適化されたアイデアは、サーバーがheader 情報を最適化し、送信するコンテンツを記述するために辞書を使用します。まず、辞書をネットワーク経由で直接送信することはできず、シリアル化して json 形式の文字列に変換し、その後バイト形式に変換する必要があります。バイト形式のjson文字は文字列の長さが固定されていないため、structモジュールを使用してバイト形式のjson文字列の長さを固定長に圧縮してクライアントに送信する必要があります。クライアントはそれを受け入れ、デコードして完全なデータ パケットを取得します。
クライアントの最終バージョン
# _*_ coding: utf-8 _*_ import socket import struct import json phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) phone.connect(('127.0.0.1',8080)) #连接服务器 while True: # 发收消息 cmd = input('请你输入命令>>:').strip() if not cmd:continue phone.send(cmd.encode('utf-8')) #发送 #先收报头的长度 header_len = struct.unpack('i',phone.recv(4))[0] #吧bytes类型的反解 #在收报头 header_bytes = phone.recv(header_len) #收过来的也是bytes类型 header_json = header_bytes.decode('utf-8') #拿到json格式的字典 header_dic = json.loads(header_json) #反序列化拿到字典了 total_size = header_dic['total_size'] #就拿到数据的总长度了 #最后收数据 recv_size = 0 total_data=b'' while recv_size<total_size: #循环的收 recv_data = phone.recv(1024) #1024只是一个最大的限制 recv_size+=len(recv_data) #有可能接收的不是1024个字节,或许比1024多呢, # 那么接收的时候就接收不全,所以还要加上接收的那个长度 total_data+=recv_data #最终的结果 print('返回的消息:%s'%total_data.decode('gbk')) phone.close()
サーバーの最終バージョン
# _*_ coding: utf-8 _*_
import socket
import subprocess
import struct
import json
phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) #买手机
phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
phone.bind(('127.0.0.1',8080)) #绑定手机卡
phone.listen(5) #阻塞的最大数
print('start runing.....')
while True: #链接循环
coon,addr = phone.accept()# 等待接电话
print(coon,addr)
while True: #通信循环
# 收发消息
cmd = coon.recv(1024) #接收的最大数
print('接收的是:%s'%cmd.decode('utf-8'))
#处理过程
res = subprocess.Popen(cmd.decode('utf-8'),shell = True,
stdout=subprocess.PIPE, #标准输出
stderr=subprocess.PIPE #标准错误
)
stdout = res.stdout.read()
stderr = res.stderr.read()
# 制作报头
header_dic = {
'total_size': len(stdout)+len(stderr), # 总共的大小
'filename': None,
'md5': None
}
header_json = json.dumps(header_dic) #字符串类型
header_bytes = header_json.encode('utf-8') #转成bytes类型(但是长度是可变的)
#先发报头的长度
coon.send(struct.pack('i',len(header_bytes))) #发送固定长度的报头
#再发报头
coon.send(header_bytes)
#最后发命令的结果
coon.send(stdout)
coon.send(stderr)
coon.close()
phone.close()Six、構造体モジュール
了解c语言的人,一定会知道struct结构体在c语言中的作用,它定义了一种结构,里面包含不同类型的数据(int,char,bool等等),方便对某一结构对象进行处理。而在网络通信当中,大多传递的数据是以二进制流(binary data)存在的。当传递字符串时,不必担心太多的问题,而当传递诸如int、char之类的基本数据的时候,就需要有一种机制将某些特定的结构体类型打包成二进制流的字符串然后再网络传输,而接收端也应该可以通过某种机制进行解包还原出原始的结构体数据。python中的struct模块就提供了这样的机制,该模块的主要作用就是对python基本类型值与用python字符串格式表示的C struct类型间的转化(This module performs conversions between Python values and C structs represented as Python strings.)。stuct模块提供了很简单的几个函数,下面写几个例子。
1,基本的pack和unpack
struct提供用format specifier方式对数据进行打包和解包(Packing and Unpacking)。例如:
#该模块可以把一个类型,如数字,转成固定长度的bytes类型 import struct # res = struct.pack('i',12345) # print(res,len(res),type(res)) #长度是4 res2 = struct.pack('i',12345111) print(res2,len(res2),type(res2)) #长度也是4 unpack_res =struct.unpack('i',res2) print(unpack_res) #(12345111,) # print(unpack_res[0]) #12345111
代码中,首先定义了一个元组数据,包含int、string、float三种数据类型,然后定义了struct对象,并制定了format‘I3sf',I 表示int,3s表示三个字符长度的字符串,f 表示 float。最后通过struct的pack和unpack进行打包和解包。通过输出结果可以发现,value被pack之后,转化为了一段二进制字节串,而unpack可以把该字节串再转换回一个元组,但是值得注意的是对于float的精度发生了改变,这是由一些比如操作系统等客观因素所决定的。打包之后的数据所占用的字节数与C语言中的struct十分相似。
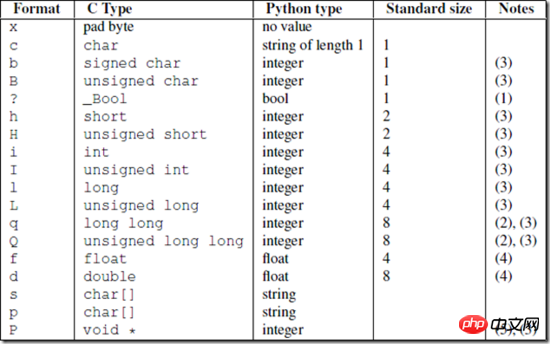
2,定义format可以参照官方api提供的对照表:
3,基本用法
import json,struct
#假设通过客户端上传1T:1073741824000的文件a.txt
#为避免粘包,必须自定制报头
header={'file_size':1073741824000,'file_name':'/a/b/c/d/e/a.txt','md5':'8f6fbf8347faa4924a76856701edb0f3'} #1T数据,文件路径和md5值
#为了该报头能传送,需要序列化并且转为bytes
head_bytes=bytes(json.dumps(header),encoding='utf-8') #序列化并转成bytes,用于传输
#为了让客户端知道报头的长度,用struck将报头长度这个数字转成固定长度:4个字节
head_len_bytes=struct.pack('i',len(head_bytes)) #这4个字节里只包含了一个数字,该数字是报头的长度
#客户端开始发送
conn.send(head_len_bytes) #先发报头的长度,4个bytes
conn.send(head_bytes) #再发报头的字节格式
conn.sendall(文件内容) #然后发真实内容的字节格式
#服务端开始接收
head_len_bytes=s.recv(4) #先收报头4个bytes,得到报头长度的字节格式
x=struct.unpack('i',head_len_bytes)[0] #提取报头的长度
head_bytes=s.recv(x) #按照报头长度x,收取报头的bytes格式
header=json.loads(json.dumps(header)) #提取报头
#最后根据报头的内容提取真实的数据,比如
real_data_len=s.recv(header['file_size'])
s.recv(real_data_len)以上がPythonソケットネットワークプログラミングにおけるスティッキーパケット問題の詳細な説明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。