
ホームページ >ウェブフロントエンド >jsチュートリアル >JSのデータ型の使い方を詳しく解説
JSのデータ型の使い方を詳しく解説
- php中世界最好的语言オリジナル
- 2018-03-28 13:31:151464ブラウズ
今回は、JSのデータ型の使い方と、JSのデータ型を使用する際の注意事項について詳しく説明します。実際のケースを見てみましょう。
私は野生のプログラマーなので、プログラミングを学び始めた当初はメモリの基礎知識に注意を払いませんでした。その結果、後から「スタックに格納されているのはだけです」などの言葉を口にしました。参照」がスタックにあります。いつも混乱しているようです。 。
その後、私は徐々に記憶についての知識を学びましたが、この部分はまだ理解する必要があります。
基本的なデータ構造
スタック
スタックは、セクション内での挿入または削除操作のみを許可する線形テーブルであり、先入れ後出しのデータ構造です。
Heap
Heapはハッシュアルゴリズムに基づいたデータ構造です。
Queue
Queue は先入れ先出し (FIFO) データ構造です。
JavaScript のデータ型は、基本データ型と参照データ型に分けられます。それらの違いの 1 つは、保存場所の違いです。
基本データ型
JavaScript の基本データ型は次のとおりであることは誰もが知っています:
String
Number
Boolean
Unknown
ヌル
シンボル (今は無視してください)
基本データ型は単純なデータセグメントであり、スタックメモリに格納されます。
参照データ型
JavaScript の参照データ型は次のとおりです:
Array
参照データ型はヒープメモリに格納され、その後スタックに格納されます。メモリ ヒープ メモリ内の実際のオブジェクトへの参照。したがって、JavaScript での参照データ型の操作は、実際のオブジェクトではなくオブジェクトへの参照に対して行われます。
スタックメモリにはアドレスが格納されており、このアドレスはヒープメモリ内の実際の値と関連付けられていることが分かります。
イラスト
それでは、いくつかの変数を宣言して試してみましょう:
var name="axuebin";
var age=25;
var job;
var arr=[1,2,3];
var obj={age:25};
次の図を使用して、メモリ内のデータ型の格納状況を表すことができます:
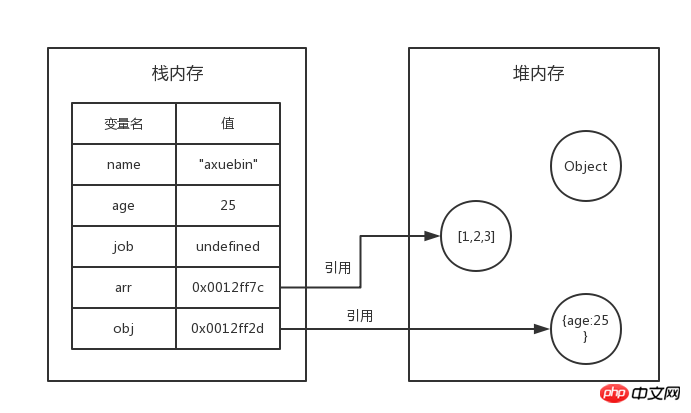
現時点ではname,age,job 3 つの基本データtype はスタック メモリに直接存在しますが、arr と obj はヒープ メモリへの参照を表すためにスタック メモリにアドレスを格納するだけです。
コピー
基本データ型
基本データ型の場合、コピーすると、システムはスタックメモリ内の新しい変数に新しい値を自動的に割り当てます。これは理解しやすいです。
参照データ型
配列やオブジェクトなどの参照データ型の場合、コピー時に違いが生じます。
システムはスタック メモリ内の新しい変数に値を自動的に割り当てますが、この値は単なる値です。アドレス。つまり、コピーされた変数は元の変数と同じアドレス値を持ち、ヒープ メモリ内の同じオブジェクトを指します。
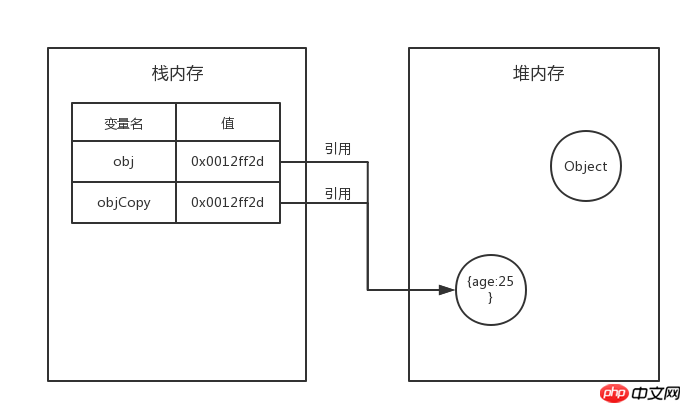
表示されている場合、var objCopy=obj を実行した後、obj と objCopy は同じアドレス値を持ち、ヒープ メモリ内の同じ実際のオブジェクトを実行します。
違いは何ですか?
obj または objCopy を変更すると、別の変数が変更されます。
なぜですか?
为什么基础数据类型存在栈中,而引用数据类型存在堆中呢?
堆比栈大,栈比对速度快。
基础数据类型比较稳定,而且相对来说占用的内存小。
引用数据类型大小是动态的,而且是无限的。
堆内存是无序存储,可以根据引用直接获取。
参考文章
理解js内存分配
原始值和引用值
在ECMAScript中,变量可以存放两种类型的值,即原始值和引用值。
原始值指的就是代表原始数据类型(基本数据类型)的值,即Undefined,Null,Number,String,Boolean类型所表示的值。
引用值指的就是复合数据类型的值,即Object,Function,Array,以及自定义对象,等等
栈和堆
与原始值与引用值对应存在两种结构的内存即栈和堆
栈是一种后进先出的数据结构,在javascript中可以通过Array来模拟栈的行为
原始值是存储在栈中的简单数据,也就是说,他们的值直接存储在变量访问的位置。
堆是基于散列算法的数据结构,在javascript中,引用值是存放在堆中的。
引用值是存储在堆中的对象,也就是说,存储在变量处的值(即指向对象的变量,存储在栈中)是一个指针,指向存储在堆中的实际对象.
例:var obj = new Object(); obj存储在栈中它指向于new Object()这个对象,而new Object()是存放在堆中的。
那为什么引用值要放在堆中,而原始值要放在栈中,不都是在内存中吗,为什么不放在一起呢?那接下来,让我们来探索问题的答案!
首先,我们来看一下代码:
function Person(id,name,age){
this.id = id;
this.name = name;
this.age = age;
}
var num = 10;
var bol = true;
var str = "abc";
var obj = new Object();
var arr = ['a','b','c'];
var person = new Person(100,"笨蛋的座右铭",25);
然后我们来看一下内存分析图:
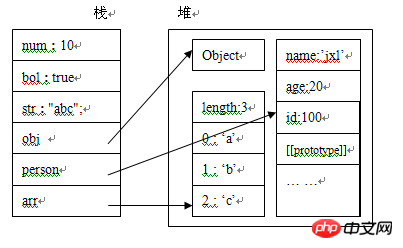
变量num,bol,str为基本数据类型,它们的值,直接存放在栈中,obj,person,arr为复合数据类型,他们的引用变量存储在栈中,指向于存储在堆中的实际对象。
由上图可知,我们无法直接操纵堆中的数据,也就是说我们无法直接操纵对象,但我们可以通过栈中对对象的引用来操作对象,就像我们通过遥控机操作电视机一样,区别在于这个电视机本身并没有控制按钮。
现在让我们来回答为什么引用值要放在堆中,而原始值要放在栈中的问题:
记住一句话:能量是守衡的,无非是时间换空间,空间换时间的问题
堆比栈大,栈比堆的运算速度快,对象是一个复杂的结构,并且可以自由扩展,如:数组可以无限扩充,对象可以自由添加属性。将他们放在堆中是为了不影响栈的效率。而是通过引用的方式查找到堆中的实际对象再进行操作。相对于简单数据类型而言,简单数据类型就比较稳定,并且它只占据很小的内存。不将简单数据类型放在堆是因为通过引用到堆中查找实际对象是要花费时间的,而这个综合成本远大于直接从栈中取得实际值的成本。所以简单数据类型的值直接存放在栈中。
相信看了本文案例你已经掌握了方法,更多精彩请关注php中文网其它相关文章!
推荐阅读:
以上がJSのデータ型の使い方を詳しく解説の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。