
ホームページ >バックエンド開発 >Python チュートリアル >Pythonのテキスト特徴抽出とベクトル化アルゴリズムの学習例を詳しく解説
Pythonのテキスト特徴抽出とベクトル化アルゴリズムの学習例を詳しく解説

- 小云云オリジナル
- 2017-12-23 17:05:575289ブラウズ
ノーラン監督の大ヒット作「インターステラー」を見たばかりだとします。映画に対する観客の評価が「肯定的」か「否定的」かを機械に自動的に分析させるにはどうすればよいでしょうか?このタイプの問題は感情分析問題です。このタイプの問題に対処する最初のステップは、テキストをフィーチャに変換することです。この記事では主に Python のテキスト特徴抽出とベクトル化アルゴリズムを詳しく紹介します。興味のある方はぜひ参考にしてください。
したがって、この章では、テキストから特徴を抽出してベクトル化する方法という最初のステップのみを学習します。
中国語の処理には単語の分割が含まれるため、この記事では簡単な例を使用して、Python の機械学習ライブラリを使用して英語から特徴を抽出する方法を説明します。
1. データの準備
Python の sklearn.datasets は、ディレクトリからのすべての分類されたテキストの読み取りをサポートします。ただし、ディレクトリは 1 フォルダ、1 ラベル名のルールに従って配置する必要があります。たとえば、この記事で使用されているデータセットには「net」と「pos」の合計 2 つのラベルがあり、各ディレクトリの下に 6 つのテキスト ファイルがあります。ディレクトリは次のとおりです:
neg
1.txt
2.txt
......
pos
1.txt
2.txt
....
12個のファイルの内容は次のとおりです。以下に要約します。 表示:
neg: shit. waste my money. waste of money. sb movie. waste of time. a shit movie. pos: nb! nb movie! nb! worth my money. I love this movie! a nb movie. worth it!
2. テキストの特徴
これらの英語の単語から感情的な態度を抽出し、分類する方法は?
最も直感的な方法は、単語を抽出することです。一般に、多くのキーワードが話者の態度を反映していると考えられています。たとえば、上記の単純なデータ セットでは、「クソ」と書かれたものはすべて否定カテゴリに属していることが簡単にわかります。
もちろん、上記のデータセットは説明の便宜のために設計されたものにすぎません。実際には、言葉には曖昧な態度が含まれることがよくあります。しかし、否定的なカテゴリーに含まれる単語が多ければ多いほど、その単語が否定的な態度を表している可能性が高まると信じる理由はまだあります。
また、感情分類には意味のない単語があることにも気づきました。たとえば、上記のデータの「of」や「I」などの単語です。このタイプの単語には、「Stop_Word」(ストップワード)と呼ばれる名前があります。このような単語は完全に無視でき、カウントされません。明らかに、これらの単語を無視することで、単語頻度レコードのストレージ スペースが最適化され、構築速度が速くなります。
各単語の単語頻度を重要な特徴として使用することにも問題があります。たとえば、上記データの「movie」は 12 サンプル中 5 回出現しますが、肯定的な出現数と否定的な出現数はほぼ同じであり、区別はありません。そして、「価値」が2回現れますが、それは明らかに強い強い色を持っており、つまり非常に区別されています。
そのため、各単語をさらに考慮するために、TF-IDF (用語頻度 - 逆文書頻度、用語頻度と逆文書頻度) を導入する必要があります。
TF (単語頻度) の計算は非常に簡単で、文書 t の文書内に出現する特定の単語 Nt の頻度です。たとえば、「この映画が大好きです」という文書では、「愛」という単語の TF は 1/4 です。ストップワード「I」と「it」を除くと 1/2 になります。
IDF(Inverse Document Frequency)の意味は、ある単語tについて、その単語が出現する文書数Dtがテスト文書D全体に占める割合を占め、自然対数を求めることです。
たとえば、「movie」という単語が合計 5 回出現し、ドキュメントの総数は 12 であるため、IDF は ln(5/12) となります。
明らかに、IDF はめったに出現しないが感情的な色彩が強い単語を強調表示します。たとえば、「movie」のような単語の IDF は ln(12/5)=0.88 で、これは「love」=ln(12/1)=2.48 の IDF よりもはるかに小さくなります。
TF-IDF は、単純に 2 つを掛け合わせたものです。このようにして、各文書内の各単語の TF-IDF を求めることで、抽出したテキスト特徴量が得られます。
3. ベクトル化
上記の基礎により、ドキュメントをベクトル化できます。まずコードを見てから、ベクトル化の意味を分析しましょう:
# -*- coding: utf-8 -*-
import scipy as sp
import numpy as np
from sklearn.datasets import load_files
from sklearn.cross_validation import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
'''''加载数据集,切分数据集80%训练,20%测试'''
movie_reviews = load_files('endata')
doc_terms_train, doc_terms_test, y_train, y_test\
= train_test_split(movie_reviews.data, movie_reviews.target, test_size = 0.3)
'''''BOOL型特征下的向量空间模型,注意,测试样本调用的是transform接口'''
count_vec = TfidfVectorizer(binary = False, decode_error = 'ignore',\
stop_words = 'english')
x_train = count_vec.fit_transform(doc_terms_train)
x_test = count_vec.transform(doc_terms_test)
x = count_vec.transform(movie_reviews.data)
y = movie_reviews.target
print(doc_terms_train)
print(count_vec.get_feature_names())
print(x_train.toarray())
print(movie_reviews.target)运行结果如下:
[b'waste of time.', b'a shit movie.', b'a nb movie.', b'I love this movie!', b'shit.', b'worth my money.', b'sb movie.', b'worth it!']
['love', 'money', 'movie', 'nb', 'sb', 'shit', 'time', 'waste', 'worth']
[[ 0. 0. 0. 0. 0. 0. 0.70710678 0.70710678 0. ]
[ 0. 0. 0.60335753 0. 0. 0.79747081 0. 0. 0. ]
[ 0. 0. 0.53550237 0.84453372 0. 0. 0. 0. 0. ]
[ 0.84453372 0. 0.53550237 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 1. 0. 0. 0. ]
[ 0. 0.76642984 0. 0. 0. 0. 0. 0. 0.64232803]
[ 0. 0. 0.53550237 0. 0.84453372 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 1. ]]
[1 1 0 1 0 1 0 1 1 0 0 0]
python输出的比较混乱。我这里做了一个表格如下:
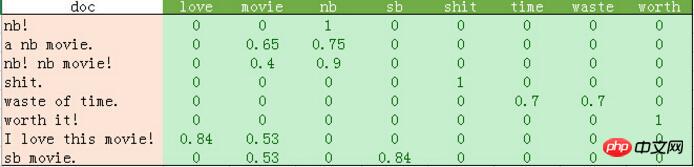
从上表可以发现如下几点:
1、停用词的过滤。
初始化count_vec的时候,我们在count_vec构造时传递了stop_words = 'english',表示使用默认的英文停用词。可以使用count_vec.get_stop_words()查看TfidfVectorizer内置的所有停用词。当然,在这里可以传递你自己的停用词list(比如这里的“movie”)
2、TF-IDF的计算。
这里词频的计算使用的是sklearn的TfidfVectorizer。这个类继承于CountVectorizer,在后者基本的词频统计基础上增加了如TF-IDF之类的功能。
我们会发现这里计算的结果跟我们之前计算不太一样。因为这里count_vec构造时默认传递了max_df=1,因此TF-IDF都做了规格化处理,以便将所有值约束在[0,1]之间。
3. count_vec.fit_transform の結果は巨大な行列です。上の表には 0 がたくさんあることがわかります。そのため、sklearn は内部実装に疎行列を使用しています。この例のデータは小さいです。読者に興味があれば、コーネル大学の機械学習研究者が使用した実際のデータを試すことができます: http://www.cs.cornell.edu/people/pabo/movie-review-data/。この Web サイトは、約 700 の肯定的な例と否定的な例を含む、約 200 万のいくつかのデータベースを含む多くのデータ セットを提供します。この種のデータの規模は大きくないので、1 分以内に完了できると思います。ただし、これらのデータ セットには不正な文字の問題がある可能性があることに注意してください。したがって、count_vec を構築するときに、これらの不正な文字を無視するために decode_error = 'ignore' が渡されます。
上の表の結果は、8 つのサンプルで 8 つの特徴をトレーニングした結果です。この結果は、さまざまな分類アルゴリズムを使用して分類できます。
関連する推奨事項:
例の詳細な説明 Python は簡単な Web ページの画像取得を実装します
以上がPythonのテキスト特徴抽出とベクトル化アルゴリズムの学習例を詳しく解説の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。