
ホームページ >バックエンド開発 >Python チュートリアル >Python3 がリクエスト モジュールを使用してページ コンテンツをクロールする方法の詳細な例
Python3 がリクエスト モジュールを使用してページ コンテンツをクロールする方法の詳細な例

- 黄舟オリジナル
- 2017-09-25 11:23:565161ブラウズ
この記事では主に、request モジュールを使用して python3 を使用してページ コンテンツをクロールする実際の方法を紹介します。興味のある方は学習してください。1. 私の個人用デスクトップ システムに pip
をインストールします。システムはデフォルトでは pip をインストールしません。後で request モジュールをインストールするために pip が使用されることを考慮して、ここでの最初のステップは pip をインストールすることです。
$ sudo apt install python-pip
インストールが成功しました。PIP バージョンを確認します:
$ pip -V
2. リクエストモジュールをインストールします
ここでは、pip を通じてインストールしました:
$ pip install requests
インポートを実行するエラーがない場合は、インストールが成功したことを意味します。 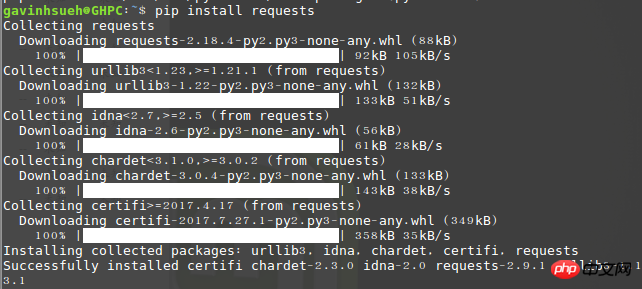
インストールが成功したかどうかを確認してください
3. beautifulsoup4をインストールします
Beautiful Soupは、HTMLまたはXMLファイルからデータを抽出できるPythonライブラリです。これにより、慣例的なドキュメント ナビゲーション、お気に入りのコンバーターを使用してドキュメントを検索および変更する方法が可能になります。 Beautiful Soup を使用すると、数時間、あるいは数日間の作業を節約できます。
$ sudo apt-get install python3-bs4
注: ここでは python3 のインストール方法を使用しています。python2 を使用している場合は、次のコマンドを使用してインストールできます。
$ sudo pip install beautifulsoup4
4.リクエストモジュールの簡単な分析
1) リクエストを送信します
まず第一に、もちろん、リクエストモジュールをインポートする必要があります:>>> import requests
次に、クロールされた対象の Web ページ。ここでは例として以下を取り上げます:
>>> r = requests.get('http://www.jb51.net/article/124421.htm')
ここでは、r という名前の応答オブジェクトが返されます。このオブジェクトから必要な情報はすべて取得できます。ここのgetはhttpのレスポンスメソッドなので、類推でput、delete、post、headに置き換えることもできます。
>>> payload = {'newwindow': '1', 'q': 'python爬虫', 'oq': 'python爬虫'}
>>> r = requests.get("https://www.google.com/search", params=payload)3) 応答コンテンツ
>>> import requests
>>> r = requests.get('https://github.com/timeline.json')
>>> r.textリクエストはサーバーからのコンテンツを自動的にデコードします。ほとんどの Unicode 文字セットはシームレスにデコードできます。 r.text と r.content の違いについて少し追加します。簡単に言うと、
>>> r = requests.get('http://www.cnblogs.com/') >>> r.encoding 'utf-8'
5) 応答ステータス コードを取得します
応答ステータス コードを検出できます:
>>> r = requests.get('http://www.cnblogs.com/') >>> r.status_code 2005。最近 OA システムを導入しました。ここではその公式ドキュメント ページを例として、ページ内の記事タイトルやコンテンツなどの有用な情報のみをキャプチャします。 デモ環境
オペレーティングシステム: linuxmint
Python バージョン: python 3.5.2使用モジュール:requests、Beautifulsoup4
コードは次のとおりです:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
_author_ = 'GavinHsueh'
import requests
import bs4
#要抓取的目标页码地址
url = 'http://www.ranzhi.org/book/ranzhi/about-ranzhi-4.html'
#抓取页码内容,返回响应对象
response = requests.get(url)
#查看响应状态码
status_code = response.status_code
#使用BeautifulSoup解析代码,并锁定页码指定标签内容
content = bs4.BeautifulSoup(response.content.decode("utf-8"), "lxml")
element = content.find_all(id='book')
print(status_code)
print(element)プログラムが実行され、クロール結果が返されます。
クロールは成功しました
クロール結果が文字化けする問題について
以上がPython3 がリクエスト モジュールを使用してページ コンテンツをクロールする方法の詳細な例の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。