
ホームページ >バックエンド開発 >Python チュートリアル >Python3 の基本的なクローラーの概要
Python3 の基本的なクローラーの概要
- 一个新手オリジナル
- 2017-09-25 10:53:482468ブラウズ
Python3基本クローラーの始め方
初めてブログを書くので少し緊張しているので、嫌な方はコメントしないでください。
不備がございましたら、読者の皆様にご指摘いただければ必ず修正させていただきます。
学习爬虫之前你需要了解(个人建议,铁头娃可以无视): - **少许网页制作知识,起码要明白什么标签...** - **相关语言基础知识。比如用java做爬虫起码会用Java语言,用python做爬虫起码要会用python语言...** - **一些网络相关知识。比如TCP/IP、cookie之类的知识,明白网页打开的原理。** - **国家法律。知道哪些能爬,哪些不能爬,别瞎爬。**
タイトルにあるように、この記事のコードはすべて python3.6.X を使用しています。
まず、インストールする必要があります(pip3 install xxxx、ワンクリックでOKです)
requestsモジュール
BeautifulSoupモジュール(またはlxmlモジュール)
これら2つのライブラリは非常に強力です、リクエストはWebページを送信するために使用され、Webページをリクエストして開きます。Beautifulsoupとlxmlはコンテンツを解析して必要なものを抽出するために使用されます。 BeautifulSoup は正規表現を優先し、lxml は XPath を優先します。私は beautifulsoup ライブラリの使用に慣れているため、この記事では主に beautifulsoup ライブラリを使用し、lxml についてはあまり詳しく説明しません。 (使用する前にドキュメントを読むことをお勧めします)
クローラーの主な構造:
マネージャー: クロールするアドレスを管理します。
ダウンローダー: Web ページの情報をダウンロードします。
フィルター: ダウンロードした Web ページ情報から必要なコンテンツをフィルターで除外します。
ストレージ: ダウンロードしたものを保存したい場所に保存します。 (実際の状況に応じて、これはオプションです。)
sracpy から urllib に至るまで、私が接触したすべての Web クローラーは、基本的にこの構造から逃れることはできません。この構造を知っていれば、暗記する必要はありません。知っておくと、少なくとも書くときに何を書いているかがわかるようになり、バグが発生したときにどこをデバッグすればよいかがわかるようになります。
前にはナンセンスがたくさんあります...テキストは次のとおりです:
この記事では、https://baike.baidu.com/item/Python (Python の Baidu エントリを例として) のクローリングを使用します。
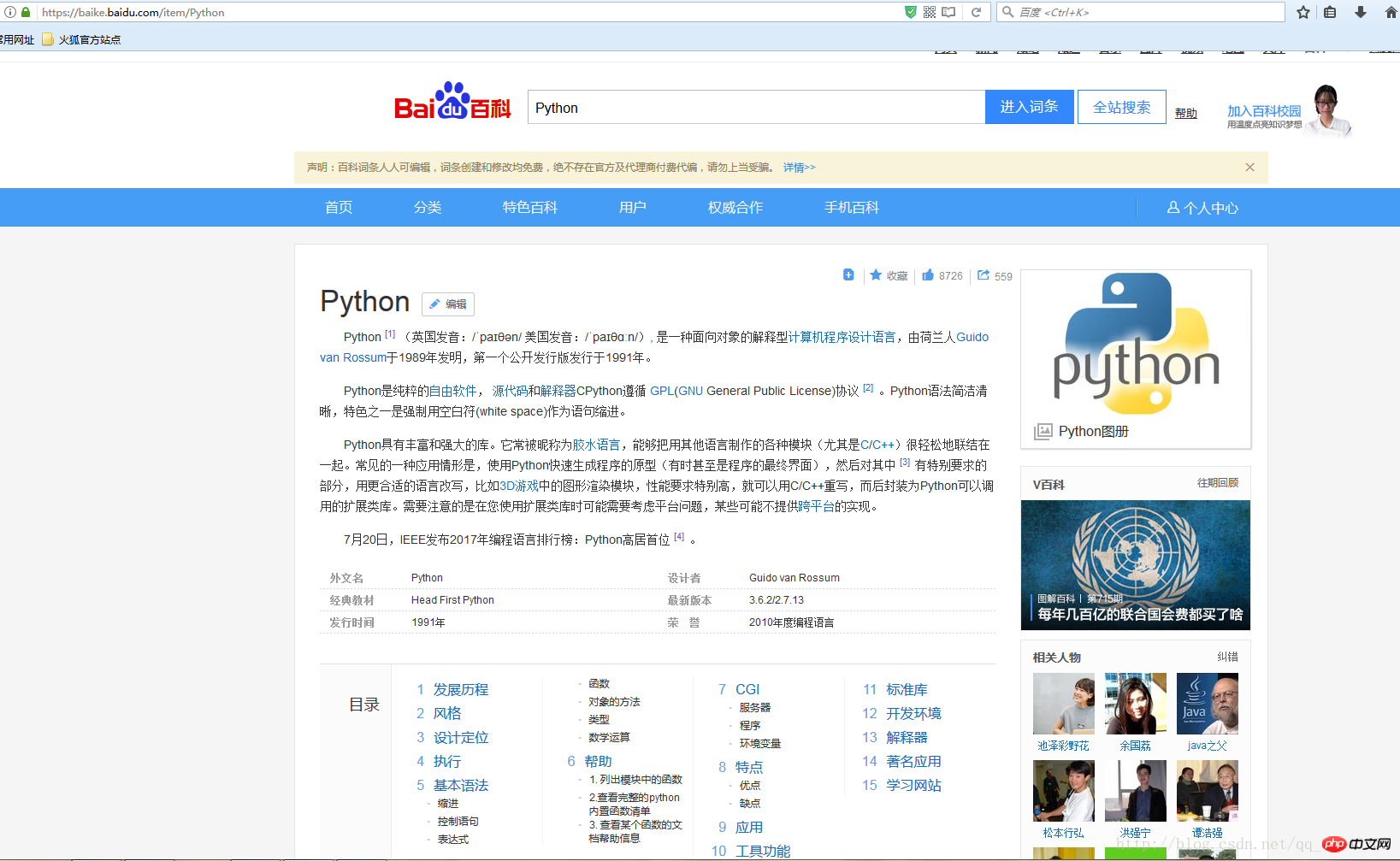
(スクリーンショットを撮るのが面倒なので…この記事の写真はこれだけになります)
Python エントリのコンテンツをクロールしたい場合は、まず、クロールしたい URL を知る必要があります:
url = 'https://baike.baidu.com/item/Python'
このページをクロールするだけなので管理人はOKです。
html = request.urlopen(url)
urlopen() 関数を呼び出します。ダウンローダーは OK です
Soup = BeautifulSoup(html,"html.parser")
baike = Soup.find_all("p",class_='lemma-summary') Beautifulsoup ライブラリの beautifulsoup 関数を find_all 関数と一緒に使用してください、パーサーは OK です
ここで、find_all 関数の戻り値はリスト。したがって、出力をループで出力する必要があります。
この例は保存する必要がなく、直接印刷できるため、次のようになります:
for content in baike: print (content.get_text())
get_text() はラベル内のテキストを抽出するために使用されます。
上記のコードを整理します:
import requestsfrom bs4 import BeautifulSoupfrom urllib import requestimport reif __name__ == '__main__':
url = 'https://baike.baidu.com/item/Python'
html = request.urlopen(url)
Soup = BeautifulSoup(html,"html.parser")
baike = Soup.find_all("p",class_='lemma-summary') for content in baike: print (content.get_text())Baidu百科事典のエントリが表示されます。
同様の方法で一部の小説、写真、見出しなどもクロールできますが、エントリに限定されるものではありません。
この記事を閉じた後にこのプログラムを作成できた場合は、おめでとうございます。開始されました。コードを決して暗記しないでください。
手順省略…全体の工程がちょっと雑です…すいません…滑りました( ̄ー ̄)…
以上がPython3 の基本的なクローラーの概要の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。