
ホームページ >バックエンド開発 >Python チュートリアル >Python クローラー: HTTP プロトコル、リクエスト ライブラリ
Python クローラー: HTTP プロトコル、リクエスト ライブラリ
- 巴扎黑オリジナル
- 2017-06-23 16:25:041580ブラウズ
HTTP プロトコル:
HTTP (ハイパーテキスト転送プロトコル): ハイパーテキスト転送プロトコル。 URL は、HTTP プロトコルを通じてリソースにアクセスするためのインターネット パスです。1 つの URL が 1 つのデータ リソースに対応します。
HTTP プロトコルによるリソースの操作:

Requests ライブラリは、HTTP のすべての基本的なリクエスト メソッドを提供します。公式紹介:
Requests ライブラリの 6 つの主要なメソッド:

Requests ライブラリの例外:

Requests ライブラリの 2 つの重要なオブジェクト: Request (リクエスト) 、応答(対応)。 Request オブジェクトは複数のリクエスト メソッドをサポートしており、Response オブジェクトには、要求されたリクエスト情報だけでなく、サーバーから返されたすべての情報が含まれています。
Response オブジェクトの属性:

その中で、r.encoding は以下を指します: ヘッダーに charset が存在しない場合、エンコーディングは ISO-8859-1 とみなされます。
r.raise_for_status() は、r.status_code が 200 に等しいかどうかを直接知ることができます。
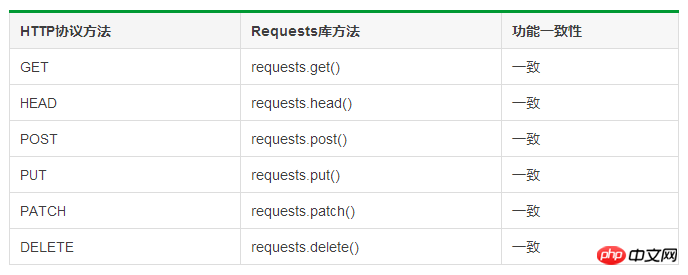
HTTP プロトコルとリクエスト ライブラリの比較:
Web ページをクローリングするための共通コード フレームワーク:
1 try:2 r = requests.get(url,timeout = 30)3 r.raise_for_status()4 # 如果状态不是200,引发HTTPError异常5 r.encoding = r.apparent_encoding6 return r.text7 except:8 return '产生异常'
たとえば、PMCAFF ホームページの情報を取得します:
Climb Webページの一般的なコードフレームワークを取得します: 動作環境: Mac、Python 3.6、PyCharm 2016.2
参考: 中国大学MOOCコース「Python Web Crawler and Information Extraction」
----- 以上---- -
著者: Du Wangdan、WeChat パブリック アカウント: Du Wangdan、インターネット プロダクト マネージャー。

以上がPython クローラー: HTTP プロトコル、リクエスト ライブラリの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。