
ホームページ >Java >&#&チュートリアル >Java 仮想マシン アーキテクチャの詳細な紹介
Java 仮想マシン アーキテクチャの詳細な紹介

- 零下一度オリジナル
- 2017-06-25 13:33:571344ブラウズ
JAVA 仮想マシンのライフサイクル
ランタイム Java 仮想マシン インスタンスの義務は次のとおりです: Java プログラムを実行する責任があります。 Java プログラムが開始されると、仮想マシン インスタンスが生成されます。プログラムが閉じられて終了すると、仮想マシン インスタンスも停止します。 3 つの Java プログラムを同じコンピュータ上で同時に実行すると、3 つの Java 仮想マシン インスタンスが取得されます。各 Java プログラムは、独自の Java 仮想マシン インスタンスで実行されます。
Java仮想マシンインスタンスは、初期クラスのmain()メソッドを呼び出すことでJavaプログラムを実行します。 main() メソッドはパブリック、静的であり、void を返し、パラメータとして文字列配列を受け入れる必要があります。このような main() メソッドを持つクラスは、Java プログラムを実行するための開始点として使用できます。
public class Test {public static void main(String[] args) {// TODO Auto-generated method stub
System.out.println("Hello World");
}
}上記の例では、Java プログラムの初期クラスの main() メソッドがプログラムの初期スレッドの開始点として使用され、他のスレッドはこの初期スレッドによって開始されます。
Java 仮想マシン内には、デーモン スレッドと非デーモン スレッドの 2 種類のスレッドがあります。デーモン スレッドは通常、ガベージ コレクション タスクを実行するスレッドなど、仮想マシン自体によって使用されます。ただし、Java プログラムは、作成したスレッドをデーモン スレッドとしてマークすることもできます。 Java プログラムの初期スレッド、つまり main() で開始されるスレッドは、非デーモン スレッドです。
デーモン以外のスレッドが実行されている限り、Java プログラムは実行され続けます。プログラム内のすべての非デーモン スレッドが終了すると、仮想マシン インスタンスは自動的に終了します。セキュリティ マネージャーが許可する場合は、Runtime クラスまたは System クラスの exit() メソッドを呼び出してプログラム自体を終了することもできます。
JAVA 仮想マシンのアーキテクチャ
次の図は、JAVA 仮想マシンの構造図です。各 Java 仮想マシンは、指定された完全修飾名に基づいて型 (クラスまたはインターフェイス) をロードします。同様に、各 Java 仮想マシンには実行エンジンがあり、ロードされたクラスのメソッドに含まれる命令を実行します。
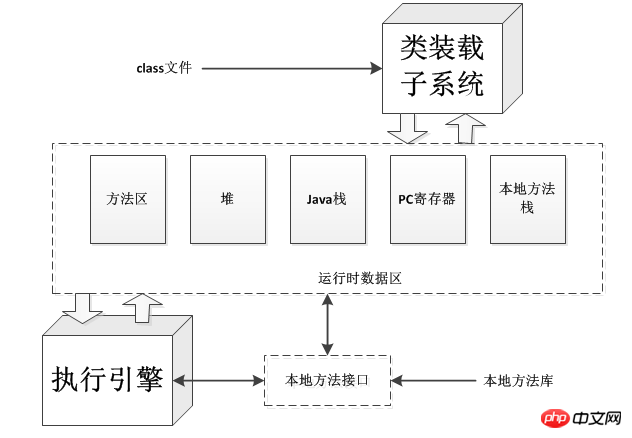
JAVA仮想マシンがプログラムを実行するとき、バイトコード、ロードされたクラスファイルから取得されるその他の情報、プログラムによって作成されたオブジェクト、メソッドに渡されるパラメータ、戻り値など、多くのものを保存するためのメモリが必要です。 、ローカル変数など。 Java 仮想マシンは、管理を容易にするために、これらをいくつかの「ランタイム データ領域」に編成します。
実行時データ領域には、プログラム内のすべてのスレッドで共有されるものと、1 つのスレッドのみが所有できるものがあります。各 Java 仮想マシン インスタンスにはメソッド領域とヒープがあり、これらは仮想マシン インスタンス内のすべてのスレッドで共有されます。仮想マシンはクラス ファイルをロードするときに、クラス ファイルに含まれるバイナリ データからタイプ情報を解析します。次に、この型情報をメソッド領域に配置します。プログラムの実行中、仮想マシンはプログラムの実行中に作成されたすべてのオブジェクトをヒープに置きます。

各新しいスレッドが作成されると、独自の PC レジスタ (プログラム カウンタ) と Java スタックを取得します。スレッドが Java メソッド (非ネイティブ メソッド) を実行している場合は、PC レジスタの値が取得されます。は常に次に実行される命令を指し、その Java スタックは常にスレッド内の Java メソッド呼び出しのステータス (ローカル変数、呼び出し時に渡されるパラメーター、および操作の中間結果を含む) を格納します。等ローカル メソッド呼び出しのステータスは、特定の実装に依存するメソッドのローカル メソッド スタックに格納されるか、特定の実装に関連するレジスタまたはその他のメモリ領域に格納される場合があります。
Javaスタックは多数のスタックフレームで構成されており、1つのスタックフレームにはJavaメソッド呼び出しのステータスが含まれます。スレッドが Java メソッドを呼び出すと、仮想マシンは新しいスタック フレームをスレッドの Java スタックにプッシュし、メソッドが戻ると、スタック フレームが Java スタックからポップされて破棄されます。
Java仮想マシンにはレジスタがなく、その命令セットはJavaスタックを使用して中間データを保存します。この設計の理由は、Java 仮想マシンの命令セットを可能な限りコンパクトに保ち、汎用レジスタがほとんどないプラットフォームでの Java 仮想マシンの実装を容易にするためです。さらに、Java 仮想マシンのスタックベースのアーキテクチャは、実行時に一部の仮想マシンに実装される動的コンパイラやジャストインタイム コンパイラのコードの最適化にも役立ちます。
次の図は、Java 仮想マシンによってスレッドごとに作成されるメモリ領域を示しています。これらのメモリ領域はプライベートであり、どのスレッドも別のスレッドの PC レジスタや Java スタックにアクセスできません。

上の図は、3 つのスレッドが実行されている仮想マシン インスタンスのスナップショットを示しています。スレッド 1 とスレッド 2 は両方とも Java メソッドを実行しており、スレッド 3 はネイティブ メソッドを実行しています。
Java栈都是向下生长的,而栈顶都显示在图的底部。当前正在执行的方法的栈帧则以浅色表示,对于一个正在运行Java方法的线程而言,它的PC寄存器总是指向下一条将被执行的指令。比如线程1和线程2都是以浅色显示的,由于线程3当前正在执行一个本地方法,因此,它的PC寄存器——以深色显示的那个,其值是不确定的。
数据类型
Java虚拟机是通过某些数据类型来执行计算的,数据类型可以分为两种:基本类型和引用类型,基本类型的变量持有原始值,而引用类型的变量持有引用值。

Java语言中的所有基本类型同样也都是Java虚拟机中的基本类型。但是boolean有点特别,虽然Java虚拟机也把boolean看做基本类型,但是指令集对boolean只有很有限的支持,当编译器把Java源代码编译为字节码时,它会用int或者byte来表示boolean。在Java虚拟机中,false是由整数零来表示的,所有非零整数都表示true,涉及boolean值的操作则会使用int。另外,boolean数组是当做byte数组来访问的,但是在“堆”区,它也可以被表示为位域。
Java虚拟机还有一个只在内部使用的基本类型:returnAddress,Java程序员不能使用这个类型,这个基本类型被用来实现Java程序中的finally子句。该类型是jsr, ret以及jsr_w指令需要使用到的,它的值是JVM指令的操作码的指针。returnAddress类型不是简单意义上的数值,不属于任何一种基本类型,并且它的值是不能被运行中的程序所修改的。
Java虚拟机的引用类型被统称为“引用(reference)”,有三种引用类型:类类型、接口类型、以及数组类型,它们的值都是对动态创建对象的引用。类类型的值是对类实例的引用;数组类型的值是对数组对象的引用,在Java虚拟机中,数组是个真正的对象;而接口类型的值,则是对实现了该接口的某个类实例的引用。还有一种特殊的引用值是null,它表示该引用变量没有引用任何对象。
JAVA中方法参数的引用传递
java中参数的传递有两种,分别是按值传递和按引用传递。按值传递不必多说,下面就说一下按引用传递。
“当一个对象被当作参数传递到一个方法”,这就是所谓的按引用传递。
public class User { private String name;public String getName() {return name;
}public void setName(String name) {this.name = name;
}
}public class Test { public void set(User user){
user.setName("hello world");
} public static void main(String[] args) {
Test test = new Test();
User user = new User();
test.set(user);
System.out.println(user.getName());
}
}上面代码的输出结果是“hello world”,这不必多说,那如果将set方法改为如下,结果会是多少呢?
public void set(User user){
user.setName("hello world");
user = new User();
user.setName("change");
}答案依然是“hello world”,下面就让我们来分析一下如上代码。
首先
User user = new User();
是在堆中创建了一个对象,并在栈中创建了一个引用,此引用指向该对象,如下图:

test.set(user);
是将引用user作为参数传递到set方法,注意:这里传递的并不是引用本身,而是一个引用的拷贝。也就是说这时有两个引用(引用和引用的拷贝)同时指向堆中的对象,如下图:

user.setName("hello world");在set()方法中,“user引用的拷贝”操作堆中的User对象,给name属性设置字符串"hello world"。如下图:

user = new User();
在set()方法中,又创建了一个User对象,并将“user引用的拷贝”指向这个在堆中新创建的对象,如下图:

user.setName("change");在set()方法中,“user引用的拷贝”操作的是堆中新创建的User对象。

set()方法执行完毕,目光再回到mian()方法
System.out.println(user.getName());
因为之前,"user引用的拷贝"已经将堆中的User对象的name属性设置为了"hello world",所以当main()方法中的user调用getName()时,打印的结果就是"hello world"。如下图:

クラスローディングサブシステム
JAVA仮想マシンにおいて、型の検索と読み込みを担当する部分はクラスローディングサブシステムと呼ばれます。
JAVA仮想マシンには起動クラスローダーとユーザー定義クラスローダーの2種類のクラスローダーがあります。前者は JAVA 仮想マシン実装の一部であり、後者は Java プログラムの一部です。異なるクラス ローダーによってロードされたクラスは、仮想マシン内の異なる名前空間に配置されます。
クラスローダーサブシステムには、Java 仮想マシンの他のいくつかのコンポーネントと、java.lang ライブラリのいくつかのクラスが含まれます。たとえば、ユーザー定義のクラス ローダーは通常の Java オブジェクトであり、そのクラスは java.lang.ClassLoader クラスから派生する必要があります。 ClassLoader で定義されたメソッドは、プログラムがクラス ローダー メカニズムにアクセスするためのインターフェイスを提供します。さらに、ロードされた型ごとに、JAVA 仮想マシンはその型を表す java.lang.Class クラスのインスタンスを作成します。他のすべてのオブジェクトと同様に、ユーザー定義のクラス ローダーと Class クラスのインスタンスはメモリ内のヒープ領域に配置され、ロードされた型情報はメソッド領域に配置されます。
クラスローダーサブシステムは、バイナリクラスファイルを見つけてインポートすることに加えて、インポートされたクラスの正確性を検証し、クラス変数にメモリを割り当てて初期化し、シンボル参照の解決を支援する責任も負わなければなりません。これらのアクションは厳密に次の順序で実行する必要があります:
(1) ロード - タイプのバイナリ データを検索してロードします。
(2) 接続 - 検証、準備、解析を指します (オプション)。
● 検証 インポートされた型が正しいことを確認します。
● 準備 クラス変数にメモリを確保し、デフォルト値に初期化します。
● 解析 型内のシンボリック参照を直接参照に変換します。
(3) 初期化 - クラス変数を正しい初期値に初期化します。
すべての JAVA 仮想マシン実装には、信頼できるクラスをロードする方法を知っている起動クラス ローダーが必要です。
各クラスローダーには独自の名前空間があり、それによってロードされた型が維持されます。したがって、Java プログラムは、同じ完全修飾名を持つ複数の型を複数回ロードできます。このような型の完全修飾名は、Java 仮想マシン内での一意性を判断するのに十分ではありません。したがって、複数のクラス ローダーが同じ名前の型をロードする場合、型を一意に識別するために、型をロードするクラス ローダー ID (型が配置されている名前空間を示す) の前に型名を付ける必要があります。
メソッド領域
Java仮想マシンでは、ロードされた型に関する情報は、論理的にメソッド領域と呼ばれるメモリに格納されます。仮想マシンが特定のタイプをロードするとき、クラス ローダーを使用して対応するクラス ファイルを見つけ、クラス ファイル (リニア バイナリ データ ストリーム) を読み取り、それを仮想マシンに送信し、仮想マシンはタイプを抽出します。情報を取得し、この情報をメソッド領域に保存します。この型のクラス (静的) 変数もメソッド領域に格納されます。
JAVA仮想マシンが型情報を内部的にどのように保存するかは、特定の実装の設計者によって決定されます。
仮想マシンが Java プログラムを実行するとき、メソッド領域に格納されている型情報を検索して使用します。すべてのスレッドはメソッド領域を共有するため、メソッド領域データへのアクセスはスレッドセーフになるように設計する必要があります。たとえば、2 つのスレッドが Lava という名前のクラスに同時にアクセスしようとしていて、このクラスが仮想マシンにロードされていないと仮定すると、この時点では 1 つのスレッドだけがそれをロードする必要があり、もう 1 つのスレッドは待機することしかできません。 。
ロードされた型ごとに、仮想マシンは次の型情報をメソッド領域に保存します:
● この型の完全修飾名
● この型の直接スーパークラスの完全修飾名 (そうでない場合を除く)この型は java.lang.Object であり、スーパークラスはありません)
● この型はクラス型なのかインターフェイス型なのか
● この型のアクセス修飾子 (public、abstract、final のサブセット)
●任意の直接スーパーインターフェイスの完全修飾名の順序付きリスト
上記の基本的なタイプ情報に加えて、仮想マシンはロードされたタイプごとに次の情報も保存する必要があります:
●定数その型のプール
●フィールド情報
●メソッド情報
●定数を除くすべてのクラス(静的)変数
●クラスへの参照 ClassLoader
●クラスに1つclass
のリファレンス Constant pool
仮想マシンはロードされた型ごとに定数プールを維持する必要があります。定数プールは、直接定数や他の型、フィールド、メソッドへのシンボリック参照など、型によって使用される定数の順序付けされたコレクションです。プール内のデータ項目には、配列と同様にインデックスによってアクセスします。定数プールには、対応する型で使用されるすべての型、フィールド、およびメソッドへのシンボリック参照が格納されるため、Java プログラムの動的リンクにおいて中心的な役割を果たします。
字段信息
对于类型中声明的每一个字段。方法区中必须保存下面的信息。除此之外,这些字段在类或者接口中的声明顺序也必须保存。
○ 字段名
○ 字段的类型
○ 字段的修饰符(public、private、protected、static、final、volatile、transient的某个子集)
方法信息
对于类型中声明的每一个方法,方法区中必须保存下面的信息。和字段一样,这些方法在类或者接口中的声明顺序也必须保存。
○ 方法名
○ 方法的返回类型(或void)
○ 方法参数的数量和类型(按声明顺序)
○ 方法的修饰符(public、private、protected、static、final、synchronized、native、abstract的某个子集)
除了上面清单中列出的条目之外,如果某个方法不是抽象的和本地的,它还必须保存下列信息:
○ 方法的字节码(bytecodes)
○ 操作数栈和该方法的栈帧中的局部变量区的大小
○ 异常表
类(静态)变量
类变量是由所有类实例共享的,但是即使没有任何类实例,它也可以被访问。这些变量只与类有关——而非类的实例,因此它们总是作为类型信息的一部分而存储在方法区。除了在类中声明的编译时常量外,虚拟机在使用某个类之前,必须在方法区中为这些类变量分配空间。
而编译时常量(就是那些用final声明以及用编译时已知的值初始化的类变量)则和一般的类变量处理方式不同,每个使用编译时常量的类型都会复制它的所有常量到自己的常量池中,或嵌入到它的字节码流中。作为常量池或字节码流的一部分,编译时常量保存在方法区中——就和一般的类变量一样。但是当一般的类变量作为声明它们的类型的一部分数据面保存的时候,编译时常量作为使用它们的类型的一部分而保存。
指向ClassLoader类的引用
每个类型被装载的时候,虚拟机必须跟踪它是由启动类装载器还是由用户自定义类装载器装载的。如果是用户自定义类装载器装载的,那么虚拟机必须在类型信息中存储对该装载器的引用。这是作为方法表中的类型数据的一部分保存的。
虚拟机会在动态连接期间使用这个信息。当某个类型引用另一个类型的时候,虚拟机会请求装载发起引用类型的类装载器来装载被引用的类型。这个动态连接的过程,对于虚拟机分离命名空间的方式也是至关重要的。为了能够正确地执行动态连接以及维护多个命名空间,虚拟机需要在方法表中得知每个类都是由哪个类装载器装载的。
指向Class类的引用
对于每一个被装载的类型(不管是类还是接口),虚拟机都会相应地为它创建一个java.lang.Class类的实例,而且虚拟机还必须以某种方式把这个实例和存储在方法区中的类型数据关联起来。
在Java程序中,你可以得到并使用指向Class对象的引用。Class类中的一个静态方法可以让用户得到任何已装载的类的Class实例的引用。
public static Class<?> forName(String className)
比如,如果调用forName("java.lang.Object"),那么将得到一个代表java.lang.Object的Class对象的引用。可以使用forName()来得到代表任何包中任何类型的Class对象的引用,只要这个类型可以被(或者已经被)装载到当前命名空间中。如果虚拟机无法把请求的类型装载到当前命名空间,那么会抛出ClassNotFoundException异常。
另一个得到Class对象引用的方法是,可以调用任何对象引用的getClass()方法。这个方法被来自Object类本身的所有对象继承:
public final native Class<?> getClass();
比如,如果你有一个到java.lang.Integer类的对象的引用,那么你只需简单地调用Integer对象引用的getClass()方法,就可以得到表示java.lang.Integer类的Class对象。
方法区使用实例
为了展示虚拟机如何使用方法区中的信息,下面来举例说明:
class Lava {private int speed = 5;void flow(){
}
}public class Volcano { public static void main(String[] args){
Lava lava = new Lava();
lava.flow();
}
}不同的虚拟机实现可能会用完全不同的方法来操作,下面描述的只是其中一种可能——但并不是仅有的一种。
Volcano プログラムを実行するには、まず「実装に依存する」方法で仮想マシンに「Volcano」という名前を伝える必要があります。その後、仮想マシンは対応するクラス ファイル「Volcano.class」を検索して読み取り、インポートされたクラス ファイル内のバイナリ データから型情報を抽出してメソッド領域に配置します。メソッド領域に保存されたバイトコードを実行すると、仮想マシンは main() メソッドの実行を開始し、実行中は常に現在のクラス (Volcano クラス) を指す定数プール (メソッド領域内のデータ構造) を保持します。ポインタ。
注: 仮想マシンが Volcano クラスの main() メソッドのバイトコードの実行を開始するとき、Lava クラスはまだロードされていませんが、ほとんどの (おそらくすべての) 仮想マシン実装と同様に、プログラムがロードされるまで待機しません。使用されるすべてのクラスが実行前にロードされます。逆に、必要な場合にのみ対応するクラスをロードします。
main() の最初の命令は、仮想マシンに定数プールの最初の項目にリストされているクラスに十分なメモリを割り当てるように指示します。したがって、仮想マシンは Volcano 定数プールへのポインタを使用して最初の項目を検索し、それが Lava クラスへのシンボリック参照であることを確認してから、メソッド領域をチェックして Lava クラスがロードされているかどうかを確認します。
このシンボリック参照は、Lava クラスの完全修飾名「Lava」を与える単なる文字列です。仮想マシンが名前からクラスをできるだけ早く見つけるために、仮想マシンの設計者は最適なデータ構造とアルゴリズムを選択する必要があります。
仮想マシンは、「Lava」という名前のクラスがロードされていないことを検出すると、ファイル「Lava.class」の検索とロードを開始し、読み取ったバイナリデータから抽出した型情報をメソッド領域に配置します。
その直後、仮想マシンは定数プールの最初の項目 (つまり、文字列「Lava」) を、メソッド領域内の Lava クラス データを直接指すポインターに置き換えます。このポインターは、メソッド領域にすばやくアクセスするために使用できます。未来の溶岩クラス。この置換プロセスは定数プール解決と呼ばれ、定数プール内のシンボル参照を直接参照に置き換えます。
最後に、仮想マシンは新しい Lava オブジェクトにメモリを割り当てる準備ができました。この時点で、メソッド領域の情報が再度必要になります。 Volcano クラス定数プールの最初の項目に入力したポインターを覚えていますか?現在、仮想マシンはこれを使用して Lava タイプ情報にアクセスし、そこに記録されている情報 (Lava オブジェクトに割り当てる必要のあるヒープ領域の量) を見つけます。
JAVA仮想マシンは、ストレージとメソッド領域の型情報を通じて、オブジェクトが必要とするメモリの量を常に決定できます。JAVA仮想マシンは、Lavaオブジェクトのサイズを決定するときに、そのような大きなスペースをヒープ上に割り当て、配置します。このオブジェクト インスタンスの可変速度は、デフォルトの初期値 0 に初期化されます。
新しく生成された Lava オブジェクトの参照がスタックにプッシュされると、main() メソッドの最初の命令も完了します。次の命令は、この参照を通じて Java コード (速度変数を正しい初期値 5 に初期化します) を呼び出します。別の命令は、この参照を使用して、Lava オブジェクト参照の flow() メソッドを呼び出します。
ヒープ
実行時にJavaプログラムによって作成されたすべてのクラスインスタンスまたは配列は、同じヒープに配置されます。 JAVA 仮想マシン インスタンスにはヒープ スペースが 1 つだけあるため、すべてのスレッドがこのヒープを共有します。また、Java プログラムは JAVA 仮想マシン インスタンスを占有するため、各 Java プログラムは独自のヒープ領域を持ち、互いに干渉することはありません。ただし、同じ Java プログラムの複数のスレッドが同じヒープ領域を共有する場合、オブジェクト (ヒープ データ) へのマルチスレッド アクセスの同期の問題を考慮する必要があります。
JAVA仮想マシンにはヒープに新しいオブジェクトを割り当てる命令はありますが、Javaコード領域のオブジェクトを明示的に解放できないのと同じように、メモリを解放する命令はありません。仮想マシン自体は、実行中のプログラムによって参照されなくなったオブジェクトによって占有されているメモリを解放する方法とタイミングを決定する責任があります。通常、仮想マシンはこのタスクをガベージ コレクターに任せます。
配列の内部表現
Javaでは、配列は実オブジェクトです。他のオブジェクトと同様、配列は常にヒープに格納されます。同様に、配列にはそのクラスに関連付けられた Class インスタンスがあり、配列の長さ (多次元配列の各次元の長さ) に関係なく、同じ次元と型を持つすべての配列は同じクラスのインスタンスになります。たとえば、3 つの整数を含む配列と 300 の整数を含む配列は同じクラスを持ちます。配列の長さはインスタンス データにのみ関係します。
配列クラスの名前は 2 つの部分で構成されます。各次元は角括弧「[」で表され、文字または文字列は要素の型を表すために使用されます。例えば、要素型が整数の1次元配列のクラス名は「[I」、要素型がバイトの3次元配列のクラス名は「[[[B」、要素型が Object の 2 次元配列は "[[Ljava/lang/Object" です。
多次元配列は配列の配列として表現されます。たとえば、以下に示すように、int 型の 2 次元配列は 1 次元配列として表現され、各要素は 1 次元 int 配列への参照になります。
ヒープ内の各配列オブジェクトは、配列の長さ、配列データ、および配列のようなデータへの参照も格納する必要があります。仮想マシンは、配列オブジェクトへの参照を通じて配列の長さを取得し、インデックスを通じてその要素にアクセスし (その間、配列の境界が範囲外かどうかをチェックする必要があります)、 によって宣言されたメソッドを呼び出すことができなければなりません。すべての配列の直接スーパークラス オブジェクトなど。
プログラム カウンタ
実行中の Java プログラムの場合、その中の各スレッドには独自の PC (プログラム カウンタ) レジスタがあり、スレッドの開始時に作成されます。PC レジスタのサイズは 1 ワードであるため、保持できます。ローカル ポインターと returnAddress の両方。スレッドが Java メソッドを実行する場合、PC レジスタの内容は常に、次に実行される命令の「アドレス」になります。ここでの「アドレス」は、ローカル ポインタである場合もあれば、メソッド内のメソッドに対する相対値である場合もあります。バイトコード。開始命令のオフセット。スレッドがネイティブメソッドを実行している場合、この時のPCレジスタの値は「未定義」となります。
Java Stack
新しいスレッドが開始されるたびに、Java 仮想マシンはそのスレッドに Java スタックを割り当てます。 Java スタックは、スレッドの実行ステータスをフレーム単位で保存します。仮想マシンは、Java スタック上で 2 つの操作 (フレームのプッシュとポップ) のみを直接実行します。
スレッドによって実行されているメソッドをそのスレッドのカレントメソッドといい、カレントメソッドが使用するスタックフレームをカレントフレームといい、カレントメソッドが属するクラスをカレントクラスといいます。現在のクラスは現在の定数プールと呼ばれます。スレッドがメソッドを実行すると、現在のクラスと現在の定数プールが追跡されます。さらに、仮想マシンがスタック内操作命令に遭遇すると、現在のフレーム内のデータに対して操作を実行します。
スレッドが Java メソッドを呼び出すたびに、仮想マシンは新しいフレームをスレッドの Java スタックにプッシュします。そして、この新しいフレームが当然、現在のフレームになります。このメソッドを実行すると、このフレームを使用してパラメータ、ローカル変数、中間演算結果、その他のデータが保存されます。
Javaメソッドは2つの方法で実行できます。 1 つは通常の復帰と呼ばれる return によって返され、もう 1 つは例外をスローして異常終了します。どのメソッドが返されたとしても、仮想マシンは現在のフレームを Java スタックから取り出して解放し、前のメソッドのフレームが現在のフレームになります。
Java フレーム上のすべてのデータはこのスレッドのプライベートです。どのスレッドも別のスレッドのスタック データにアクセスできないため、マルチスレッド状況でのスタック データ アクセスの同期を考慮する必要はありません。スレッドがメソッドを呼び出すと、メソッドのローカル変数が呼び出しスレッドの Java スタック フレームに保存されます。これらのローカル変数にアクセスできるのは常に 1 つのスレッド (メソッドを呼び出すスレッド) だけです。
ローカル メソッド スタック
前述のランタイム データ領域はすべて Java 仮想マシン仕様で明確に定義されています。さらに、実行中の Java プログラムでは、ローカル メソッドに関連するデータ領域も使用される場合があります。スレッドがネイティブ メソッドを呼び出すと、仮想マシンによる制限がなくなった新しい世界に入ります。ネイティブ メソッドは、ネイティブ メソッド インターフェイスを通じて仮想マシンのランタイム データ領域にアクセスできますが、それ以上に、必要なことは何でも実行できます。
ネイティブメソッドは本質的に実装に依存します。仮想マシン実装の設計者は、Java プログラムがローカルメソッドを呼び出すためにどのようなメカニズムを使用するかを自由に決定できます。
ネイティブ メソッド インターフェイスは、何らかのネイティブ メソッド スタックを使用します。スレッドが Java メソッドを呼び出すと、仮想マシンは新しいスタック フレームを作成し、それを Java スタックにプッシュします。ただし、ローカル メソッドを呼び出す場合、仮想マシンは Java スタックを変更せずに維持し、新しいフレームをスレッドの Java スタックにプッシュしなくなり、単に動的に接続して、指定されたローカル メソッドを直接呼び出します。
仮想マシンによって実装されるローカル メソッド インターフェイスが C 接続モデルを使用する場合、そのローカル メソッド スタックは C スタックになります。 C プログラムが C 関数を呼び出すと、そのスタック操作が決定されます。関数に渡されるパラメータは特定の順序でスタックにプッシュされ、その戻り値は特定の方法で呼び出し元に渡されます。繰り返しますが、これは仮想マシン実装におけるネイティブ メソッド スタックの動作です。
ネイティブ メソッド インターフェイスは Java 仮想マシンの Java メソッドをコールバックする必要がある可能性が非常に高く、この場合、スレッドはローカル メソッド スタックの状態を保存し、別の Java スタックに入ります。
次の図は、スレッドがローカル メソッドを呼び出すと、ローカル メソッドが仮想マシン内の別の Java メソッドをコールバックするシナリオを示しています。この図は、JAVA 仮想マシン内で実行されているスレッドのパノラマ ビューを示しています。スレッドは Java メソッドを実行し、そのライフサイクル全体にわたってその Java スタックを操作することもできます。あるいは、何の障害もなく Java スタックとネイティブ メソッド スタックの間をジャンプすることもできます。 
スレッドは最初に 2 つの Java メソッドを呼び出し、2 番目の Java メソッドはローカル メソッドを呼び出しました。これにより、仮想マシンはローカル メソッド スタックを使用するようになりました。これは、間に 2 つの C 関数がある C 言語スタックであるとします。最初の C 関数は 2 番目の Java メソッドによってネイティブ メソッドとして呼び出され、この C 関数は 2 番目の C 関数を呼び出します。次に、2 番目の C 関数がローカル メソッド インターフェイスを介して Java メソッド (3 番目の Java メソッド) をコールバックし、最後にこの Java メソッドが Java メソッドを呼び出します (図では現在のメソッドになります)。
Javaを学習中の学生の皆様、ご注意ください! ! !
学習プロセス中に問題が発生した場合、または学習リソースを入手したい場合は、Java 学習交換グループ (299541275) に参加してください。一緒に Java を学びましょう!
以上がJava 仮想マシン アーキテクチャの詳細な紹介の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。