
ホームページ >データベース >mysql チュートリアル >MySQL のインデックスと構造の詳細な説明
MySQL のインデックスと構造の詳細な説明

- 黄舟オリジナル
- 2017-03-01 13:32:561206ブラウズ
B ツリー
B ツリーは、バランス型マルチパス検索ツリー (バイナリではありません) とも呼ばれます。B ツリー構造を使用すると、レコードを検索する際の中間プロセスが大幅に削減され、アクセスが高速化されます。
左の子ノードのキー値 B ツリーでキーによってデータを取得するアルゴリズムは非常に直感的です。まずルート ノードから二分検索を実行し、見つかった場合は対応するデータを返します。それ以外の場合、対応する区間のポインタが指すノードは、ノードが見つかるか null ポインタが見つかるまで再帰的に検索されます。前者の検索は成功し、後者の検索は失敗します。 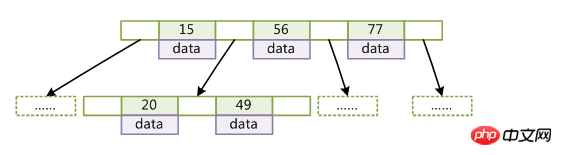
(キーはレコードのキー値です。データレコードが異なると、キーは互いに異なります。データは、データレコード内のキーを除くデータです)
B+tree
B+Tree は改良されましたB ツリー。 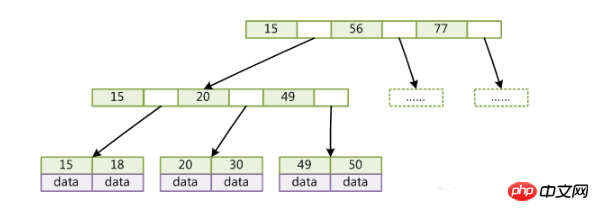
(キーはレコードのキー値です。データレコードが異なると、キーは互いに異なります。データは、キーを除いたデータレコード内のデータです)
B-Tree と比較すると、B+Tree には次の特徴があります。以下の違いがあります:
各ノードのポインタの上限は 2d+1 ではなく 2d です。
内部ノードはデータを保存せず、キーのみがポインターを保存しません。
それでは、なぜデータベースはB-tree
を使用するのでしょうか?機械的な動作の待ち時間を償却するために、ディスクは1つの情報単位ではなく、一度に複数のデータ項目にアクセスします。一度に読み取るページ数は、総ディスクアクセス時間の主な近似値として使用できます。Bツリーアルゴリズムは、特定のページ数を維持するだけで済みます。記憶の中で。 B ツリーの設計では、ディスクの事前読み取りが考慮されています。通常、B ツリー ノードは完全なディスク ページ (ページ) と同じ大きさであり、ディスク ページのサイズによって B の子 (ブランチ) の数が制限されます。 -tree ノードには要素を含めることができます)。もちろん、これはページに対するキーワードのサイズにも依存します。 I/O 操作を最小限に抑えるために、ディスクの読み取りは毎回先読みされ、サイズは通常ページの整数倍になります。 1 バイトだけを読み取る必要がある場合でも、ディスクは 1 ページのデータ (通常は 4K) を読み取り、それをメモリに置きます。メモリとディスクはページ単位でデータを交換します。局所性の原理により、通常、1 つのデータが使用されると、すぐに近くのデータも使用されるためです。
B ツリー: 取得に 4 つのノードへのアクセスが必要な場合、データベース システム設計者はディスク先読みの原理を使用してノードのサイズを 1 ページとして設計し、1 つのノードの読み取りに必要な I/O 操作は 1 つだけです。今度は完了します。 取得操作には最大 3 つの I/O が必要です (ルート ノードはメモリ内に常駐します)。データレコードが小さいほど、各ノードに保存されるデータが多くなり、ツリーの高さが低くなり、I/O操作が減り、検索効率が向上します
。B+ツリー: 非リーフ ノードはキーのみを格納するため、非リーフ ノードのサイズが大幅に削減され、各ノードはより多くのレコードを格納できるようになり、ツリーが短くなり、I/O 操作が少なくなります
。したがって、B+Tree の方がパフォーマンスが優れています。インデックスとは何ですか?
インデックスは単なるデータ構造です。 インデックスのコスト インデックスにもコストがかかります。インデックス ファイル自体がストレージ スペースを消費し、インデックスによってレコードの挿入、削除、変更の負担が増加します。さらに、MySQL はインデックスを維持するためにリソースも消費します。したがって、インデックス More が常に優れているとは限りません。一般に、次の 2 つの状況では、インデックスを構築することはお勧めできません。1 つ目のケースは、テーブル レコードが比較的小さい場合です。
インデックスを構築することが推奨されないもう 1 つのケースは、インデックスの選択性が低い場合です。いわゆるインデックス選択性 (Selectivity) とは、テーブル レコード (#T) の数に対する一意のインデックス値 (カーディナリティとも呼ばれる) の比率を指します。
インデックスのカテゴリ
2. 一意のインデックス
3. 主キーインデックス 4. 複合インデックス
MySQL で使用されるインデックス
クラスター化インデックスと非クラスター化インデックス
いわゆるクラスター化インデックスは、メインのインデックス ファイルとデータ ファイルが同じファイルであることを意味し、主に Innodb ストレージ エンジンで使用されます。このインデックスの実装では、B+Tree のリーフ ノード上のデータがデータそのものであり、キーが主キーになります。以下に示すように: 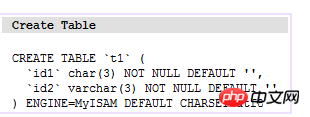
(t1 テーブル) 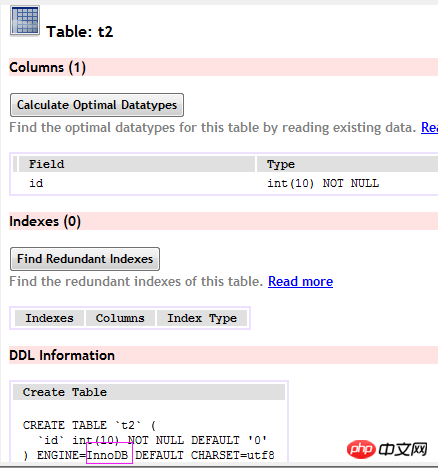
(t2 テーブル) 
(データベース対応ファイル)
InnoDB のデータ ファイル自体は主キーによって集約されるため、InnoDB ではテーブルに主キー (MyISAM) が必要です。必要ありません)、明示的に指定されていない場合、MySQL システムはデータ レコードを一意に識別できるカラムを主キーとして自動的に選択します。そのようなカラムが存在しない場合、MySQL は暗黙的なフィールドを主キーとして自動的に生成します。 InnoDB テーブルの場合、このフィールドの長さは 6 バイトで、型は長整数です。
MySQL データベースの MyISAM と InnoDB データ ストレージ エンジンの主な違い
:
MyISAM は非トランザクション的に安全ですが、InnoDB はトランザクション的に安全です。
MyISAM ロック粒度はテーブル レベルですが、InnoDB は行レベルのロックをサポートします。
MyISAM はフルテキスト タイプのインデックスをサポートしていますが、InnoDB はフルテキスト インデックスをサポートしていません。
MyISAM は比較的シンプルなので、効率の点では InnoDB より優れています。小規模なアプリケーションでは MyISAM の使用を検討できます。
MyISAM テーブルはファイルの形式で保存されます。クロスプラットフォームのデータ転送で MyISAM ストレージを使用すると、多くの手間が省けます。
InnoDB テーブルは、MyISAM テーブルよりも安全であり、データが失われないようにしながら、非トランザクション テーブルをトランザクション テーブルに切り替えることができます (alter table tablename type=innodb)。
アプリケーション シナリオ:
MyISAM は非トランザクション テーブルを管理します。高速な保存と取得、および全文検索機能を提供します。アプリケーションが多数の SELECT クエリを実行する必要がある場合は、MyISAM の方が良い選択肢です。
InnoDB はトランザクション処理アプリケーションに使用され、ACID トランザクションのサポートを含む数多くの機能を備えています。アプリケーションで大量の INSERT または UPDATE 操作を実行する必要がある場合は、マルチユーザーの同時操作のパフォーマンスを向上できる InnoDB を使用する必要があります。
補足
メインメモリの格納と検索のプロセス
システムがメインメモリを読み出す必要がある場合、メインメモリがアドレス信号を読み取った後、アドレス信号をアドレスバスに乗せてメインメモリに渡します。 、信号を解析して指定された場所のストレージ ユニットを特定し、他のコンポーネントが読み取れるようにストレージ ユニットのデータをデータ バス上に置きます。
メイン メモリへの書き込みプロセスも同様です。システムは、書き込むユニット アドレスとデータをそれぞれアドレス バスとデータ バスに配置し、2 つのバスの内容を読み取り、対応する書き込み操作を実行します。
ここで、メインメモリへのアクセス時間はアクセス数と直線的にのみ関係していることがわかります。たとえば、2 回アクセスされるデータの「距離」は時間に影響を与えません。 、最初に A0 を取得し、次に A1 を取得するのにかかる時間は、最初に A0 を取得してから D3 を取得するのと同じです