
ホームページ >データベース >mysql チュートリアル >MySQL でのインデックス長の計算の詳細
MySQL でのインデックス長の計算の詳細

- 黄舟オリジナル
- 2017-03-01 13:31:022407ブラウズ
まず、テーブル t について、3 つのフィールド a、b、c が含まれていると仮定して、結合インデックス (a、b、c) を作成します。 ) 分析するには select * from t where a=1 and c=1 と select * from t where a=1 and b=1 の違いは何ですか?
まずテーブルを作成します
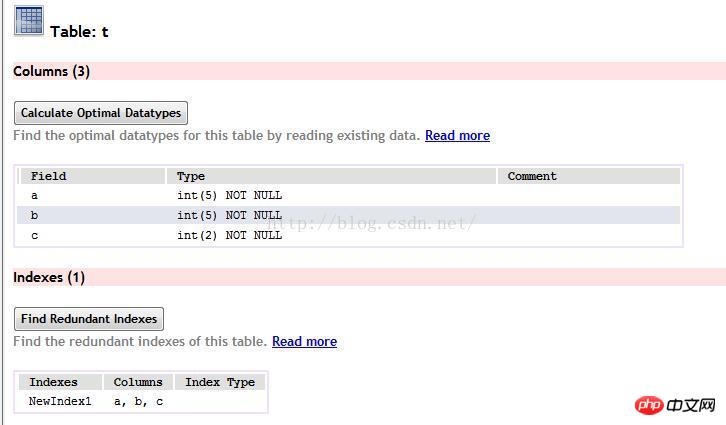
これら2つのステートメントをそれぞれ実行します
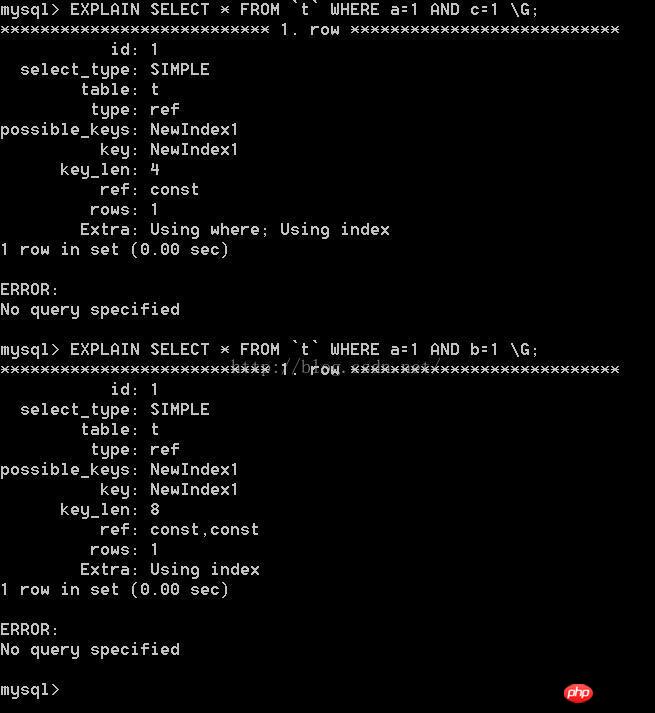
2つの違いは主にkey_lenにあることがわかりました。なぜ違うのか毛織物とは違う?
私の理解は次のとおりです:
結合されたインデックスは、index(a,b, など) の本の第 1 レベルのディレクトリ、第 2 レベルのディレクトリ、および第 3 レベルのディレクトリと考えることができます。 c) これは、 a が第 1 レベルのディレクトリ、 b が第 1 レベルのディレクトリの下の第 2 レベルのディレクトリ、 c が第 2 レベルのディレクトリの下の第 3 レベルのディレクトリであることに相当します。ディレクトリを使用するには、最初に、第 1 レベルのディレクトリを除く、その上位ディレクトリを使用する必要があります。
つまり、a=1 と c=1 は第 1 レベルのディレクトリのみを使用し、c は第 3 レベルのディレクトリにあり、第 2 レベルのディレクトリは使用されず、その後、第 3 レベルのディレクトリが使用されます。ディレクトリは使用できません
ここで、a=1 と b=1 は、第 1 レベルのディレクトリと第 2 レベルのディレクトリのみを使用します。
つまり、2 番目のクエリの
key_lenの方が大きくなります。
しかし、上記の 4 と 8 はどのように計算されるのでしょうか?
Explain を通じて SQL クエリ ステートメントのパフォーマンスを分析するとき、select_type、type、 possible_key、key、ref、rows、extra にさらに注目しました。今回は、 key_len の計算を明確にする必要があると感じます。 1. すべてのインデックスフィールドで、null が設定されていない場合は、1 バイトを追加する必要があります。
2. 固定長フィールド。int は 4 バイト、date は 3 バイト、char(n) は n 文字を占めます。
3. フィールド varchar(n) には、n 文字 + 2 バイトがあります。 4. 文字セットが異なると、1 つの文字が占めるバイト数も異なります。 latin1 エンコードでは 1 文字が 1 バイトを占め、gbk エンコードでは 1 文字が 2 バイトを占め、utf8 エンコードでは 1 文字が 3 バイトを占めます。
したがって、
は次のように結論付けることができます
where a=1 and c=1, key_len=4
where a=1 and c=1, key_len=4 +4=8
さて、別の質問をしてみましょう。t2テーブルを作成します。データ構造は次のとおりです
Explain selectを実行してください* t2 where name="001" and id=1 G; key_len とは何ですか? 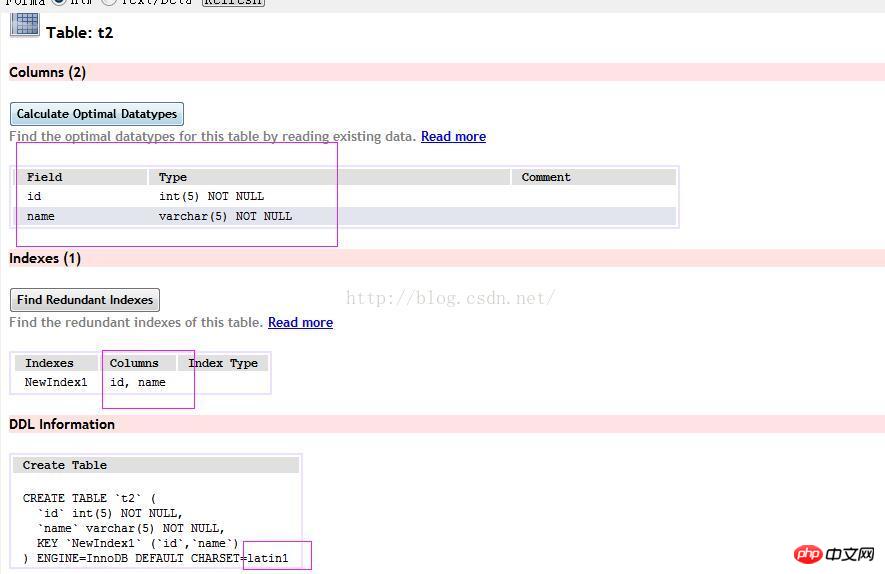
varchar(5) は 7 バイトを占めます。構造は以下の通りです
MySQL にはクエリ オプティマイザーがあるため、フィールドの順序は (a=1 および c=1) 型のクエリには影響せず、クエリ オプティマイザーが自動的に最適化します。 where c=1 および a=1 は where a=1 および c=1 に最適化されますが、where を使用することをお勧めします
a=1 および c=1。理解しやすくクエリのバッファリングを目的としています。クエリのバッファリングとハッシュキーの値は SQL ステートメントに基づいて計算され、大文字と小文字が区別されるため、SQL ステートメントを作成するときは、同じクエリが複数回キャッシュされないように一貫性を保つようにしてください。
上記は、MySQL でのインデックスの長さの計算の詳細です。その他の関連コンテンツについては、PHP 中国語 Web サイト (www.php.ん)! 補足