
ホームページ >テクノロジー周辺機器 >AI >データ代入のためのPandas Fillna()
データ代入のためのPandas Fillna()

- Jennifer Anistonオリジナル
- 2025-03-17 10:46:08881ブラウズ
欠落データの処理は、データ分析と機械学習の重要なステップです。データ入力エラーや固有のデータ制限などのさまざまなソースに由来する欠損値は、分析の精度とモデルの信頼性に深刻な影響を与える可能性があります。強力なPythonライブラリであるPandasは、 fillna()メソッドを提供します。これは、効果的な欠落データ代入のための汎用ツールです。この方法により、欠損値をさまざまな戦略に置き換えることができ、分析のためのデータの完全性を確保できます。

目次
- データ代入とは何ですか?
- データ代入の重要性
- データセットの歪み
- 機械学習ライブラリの制限
- モデルのパフォーマンスへの影響
- データセットの完全性を復元します
- Pandas
fillna()理解-
fillna()構文
-
-
fillna()を使用したデータ代入技術- 前/次の値を使用します
- 最大/最小値の代入
- 平均代入
- 中央値の代入
- 移動平均代入
- 丸い平均代入
- 固定値代入
- 結論
- よくある質問
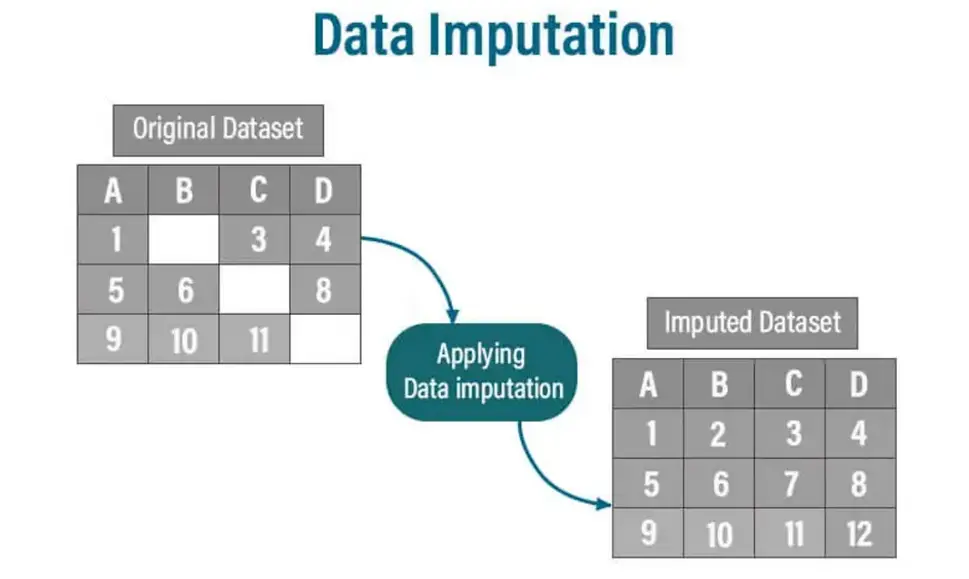
データ代入とは何ですか?
データの代入は、データセット内の欠落データポイントに記入する手法です。欠落データは、完全なデータセットを必要とする多くの分析方法と機械学習アルゴリズムに大きな課題をもたらします。 Inpputationは、使用可能なデータに基づいて欠損値をもっともらしい代替物に推定および置き換えることにより、これに対処します。
なぜデータの代入は重要なのですか?
いくつかの重要な理由は、データの代入の重要性を強調しています。
- データセットの歪み:データの欠落は、変数分布を歪め、データの整合性を損なう可能性があります。これは、不正確な結論につながる可能性があります。
- 機械学習ライブラリの制約:多くの機械学習ライブラリが完全なデータセットを想定しています。値が欠けていると、エラーが発生したり、アルゴリズムの実行を防ぐことができます。
- モデルのパフォーマンスへの影響:欠損データはバイアスを導入し、信頼できない予測と洞察をもたらします。
- データセットの完全性:データが限られている状況では、少量の欠落情報でさえ分析に大きな影響を与える可能性があります。帰属は、利用可能なすべての情報を保存するのに役立ちます。
Pandas fillna()理解
Pandas fillna()メソッドは、データフレームまたはシリーズのNaN (数ではない)値を置き換えるように設計されています。さまざまな帰属戦略を提供します。
fillna()構文

重要なパラメーターには、 value (交換値)、 method (例えば、前方塗りつぶしの「fill」、後方塗り方の「bfill」)、 axis 、 inplace 、 limit 、およびdowncast含まれます。
さまざまな帰属技術にfillna()を使用します
fillna()を使用して、いくつかの帰属手法を実装できます。
- 次の値または以前の値:シーケンシャルデータの場合、このメソッドは最も近い有効な値を使用します。
- 最大値または最小値:データが制限されている場合に役立ちます。
- 平均代入:欠損値を列の平均に置き換えます。外れ値に敏感。
- 代入の中央値:欠損値を列の中央値に置き換えます。平均よりも外れ値に対して堅牢です。
- 移動平均代入:周囲の値のウィンドウの平均を使用します。時系列データに効果的です。
- 丸い平均代入:データの精度を維持するのに役立つ丸い平均に置き換えられます。
- 固定値の代入:所定の値(例:0、 '不明」)に置き換えます。
(各手法のコードの例は、元のテキストのコード例の構造と内容を反映して、ここに含まれます。)
結論
信頼できるデータ分析と機械学習には、効果的な欠落データ処理が不可欠です。 Pandas ' fillna()メソッドは、強力で柔軟なソリューションを提供し、さまざまなデータ型とコンテキストに合わせてさまざまな帰属戦略を提供します。適切な方法を選択すると、データセットの特性と分析目標に依存します。
よくある質問
(FAQSセクションは保持され、元のテキストのコンテンツを反映しています。)
以上がデータ代入のためのPandas Fillna()の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。