
ホームページ >テクノロジー周辺機器 >AI >ACL 2024 賞の発表: HuaTech による Oracle 解読に関する最優秀論文の 1 つ、GloVe Time Test Award
ACL 2024 賞の発表: HuaTech による Oracle 解読に関する最優秀論文の 1 つ、GloVe Time Test Award

- 王林オリジナル
- 2024-08-15 16:37:02646ブラウズ
貢献者は、この ACL カンファレンスから多くのものを得ました。


著者: Julie Kallini、Isabel Papadimitriou、Richard Futre ll、カイル・マホワルド、クリストファー・ポッツ -
機関: スタンフォード大学、カリフォルニア大学アーバイン校、テキサス大学オースティン校 論文リンク: https://arxiv.org/abs/2401.06416

著者: Michael Hahn、Mark Rofin 機関: ザールランド大学 論文リンク: https://arxiv. /abs/2402.09963

著者: Haisu Guan、Huanxin Yang、Xinyu Wang、Shengwei Han、他 -
機関: 華中大学科学技術、アデレード大学、安養師範大学、華南理工大学 論文リンク: https://arxiv.org/pdf/2406.00684

著者: Pietro Lesci、Clara Meister、Thomas Hofmann、Andreas Vlachos、Tiago Pimentel Instituteション: ケンブリッジ大学、チューリッヒ工科大学アカデミー 論文リンク: https://arxiv.org/pdf/2406.04327
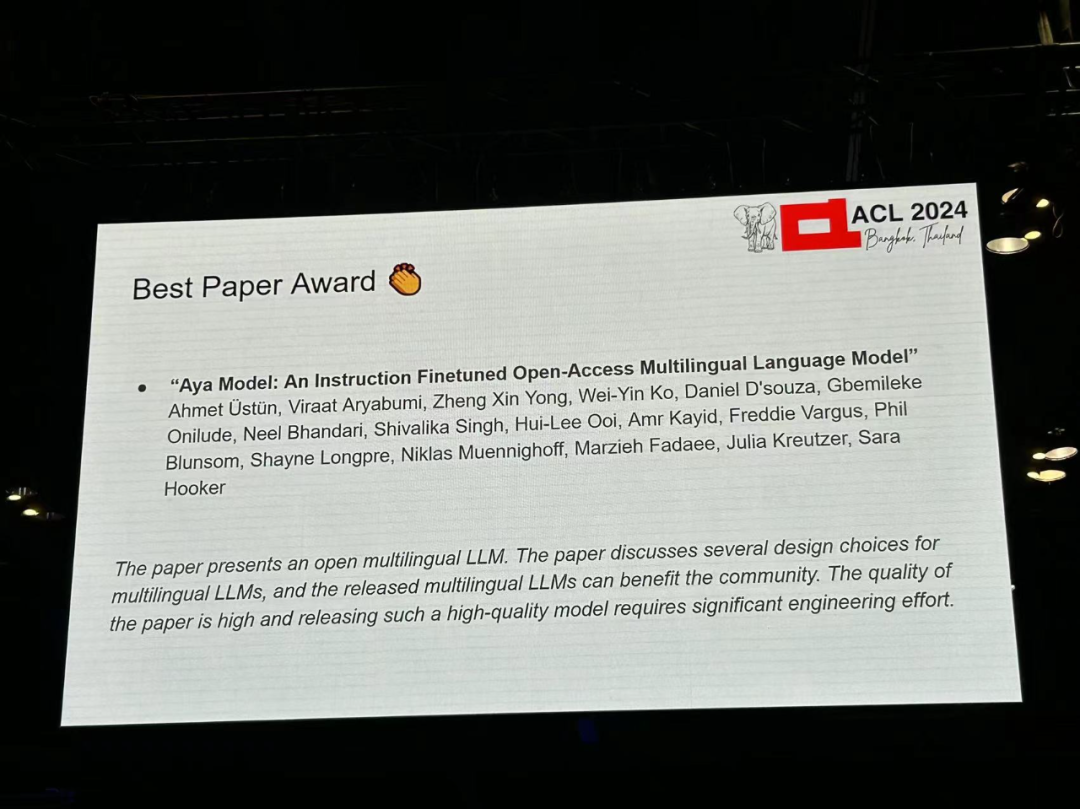
著者: Ahmet Üstün、Viraat Aryabumi、Zheng Xin Yong、Wei-ying Ko など 機関: Cohere、ブラウン大学ほか 論文リンク: https://arxiv.org/pdf/2402.07827

著者: Liang Lu、Peiron Xie、David R. Mortensen -
機関: CMU、University of南カリフォルニア -
論文リンク: https://arxiv.org/pdf/2406.05930

- 著者: Tharindu Madusanka、Ian Pratt-Hartmann、Riza Batista-Navarro

Authors: Jeffrey Pennington, Richard Socher, Christopher D. Manning Institution: Stanford University Paper link: https:// /aclanthology.org/D14-1162.pdf

Author: Lillian Lee Institution: Cornell University -
Paper link: https://aclanthology .org/P99-1004.pdf


Paper 1: Quantized Side Tuning: Fast and Memory-Efficient Tuning of Quantized Large Language Models Authors: Zhengxin Zhang, Dan Zhao, Xupeng Miao , Gabriele Oliaro, Zhihao Zhang, Qing Li, Yong Jiang, Zhihao Jia Institutions: CMU, Tsinghua University, Pengcheng Laboratory, etc. -
Paper link: https://arxiv.org/pdf/2401.07159
Paper 2: L-Eval: Instituting Standardized Evaluation for Long Context Language Models Authors: Chenxin An, Shansan Gong, Ming Zhong, Xingjian Zhao, Mukai Li, Jun Zhang, Lingpeng Kong, Xipeng Qiu Institutions: Fudan University, University of Hong Kong, University of Illinois at Urbana-Champaign, Shanghai AI Lab Paper link: https://arxiv.org/abs/2307.11088
Paper 3: Causal-Guided Active Learning for Debiasing Large Language Models Paper link: https://openreview.net/forum?id=idp_1Q6F-lC
Paper 4: CausalGym: Benchmarking causal interpretability methods on linguistic tasks Authors: Aryaman Arora, Dan Jurafsky, Christopher Potts Institution: Stanford University -
Paper link: https://arxiv.org/abs/2402.12560
Paper 5: Don't Hallucinate, Abstain: Identifying LLM Knowledge Gaps via Multi-LLM Collaboration Authors: Shangbin Feng, Weijia Shi, Yike Wang, Wenxuan Ding, Vidhisha Balachandran, Yulia Tsvetkov Institutions: University of Washington, University of California, Berkeley, Hong Kong University of Science and Technology, CMU Paper link: https://arxiv.org/abs/2402.00367
Paper 6: Speech Translation with Speech Foundation Models and Large Language Models: What is There and What is Missing? Author: Marco Gaido, Sara Papi, Matteo Negri, Luisa Bentivogli -
Institution: Bruno Kessler Foundation, Italy Paper link: https://arxiv.org/abs/2402.12025
Paper 7: Must NLP be Extractive? Author: Steven Bird Institution : Charles Darwin University Paper link: https://drive.google.com/file/d/1hvF7_WQrou6CWZydhymYFTYHnd3ZIljV/view
Paper 8: IRCoder: Intermediate Representations Make Language Models Robust Multilingual Code Gen erators Authors: Indraneil Paul, Goran Glavaš, Iryna Gurevych Institution: TU Darmstadt, etc. -
Paper link: https://arxiv.org/abs/2403.03894 -
Paper 9: MultiLegalPile: A 689GB Multilingual Legal Corpus Authors: Matthias Stürmer, Veton Matoshi, etc. Institutions: University of Bern, Stanford University, etc. Paper link: https://arxiv.org/ pdf/2306.02069
Paper 10: PsySafe: A Comprehensive Framework for Psychological-based Attack, Defense, and Evaluation of Multi-agent System Safety Authors: Zaibin Zhang , Yongting Zhang , Lijun Li , Hongzhi Gao, Lijun Wang, Huchuan Lu, Feng Zhao, Yu Qiao, Jing Shao Institution: Shanghai Artificial Intelligence Laboratory, Dalian University of Technology, University of Science and Technology of China Paper link: https://arxiv .org/pdf/2401.11880
Paper 11: Can Large Language Models be Good Emotional Supporter? Mitigating Preference Bias on Emotional Support Conversation Author: Dongjin Kang, Sunghwan Kim, etc. Institution: Yonsei University, etc. Paper link: https://arxiv.org/pdf/2402.13211
Paper 12: Political Compass or Spinning Arrow? Towards More Meaningful Evaluations for Values and Opinions in Large Language Models Authors: Paul Röttger, Valentin Hofmann, etc. Institutions: Bocconi University, Allen Institute for Artificial Intelligence, etc. Paper link: https://arxiv.org/pdf/ 2402.16786
Paper 13: Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models Author: Mosh Levy, Alon Jacoby, Yoav Goldberg Institution: Pakistan Elan University, Allen Institute for Artificial Intelligence Paper link: https://arxiv.org/pdf/2402.14848
Paper 14: Do Llamas Work in English? On the Latent Language of Multilingual Transformers Authors: Chris Wendler, Veniamin Veselovsky, etc. -
Institution: EPFL - Paper 15: Getting Serious about Humor: Crafting Humor Datasets with Unfunny Large Language Models
- Institutions: Columbia University, EPFL
- Paper link: https://arxiv.org/pdf/2403.00794
- Paper 16: Estimating the Level of Dialectness Predicts Inter-annotator Agreement in Multi-dialect Arabic Datasets
- Institution: University of Edinburgh
- Paper link: https://arxiv.org/pdf/2405.11282
- Paper 17: G-DlG: Towards Gradient-based Dlverse and hiGh-quality Instruction Data Selection for Machine Translation
- Institution: ByteDance Research
- Paper link: https: https://arxiv.org/pdf/2405.12915
-
- Paper 19: SPZ: A Semantic Perturbation-based Data Augmentation Method with Zonal-Mixing for Alzheimer's Disease Detection
- Paper 20: Greed is All You Need: An Evaluation of Tokenizer Inference Methods
- Institution: Ben Guri, Negev Ann University, MIT
- Paper link: https://arxiv.org/abs/2403.01289
- Institution: University of Notre Dame (USA)
- Author: Chihiro Taquchi, David Chiang
- Paper link : https://arxiv.org/abs/2406.09202
- Institutions: Anthropic, Harvard University, University of Göttingen (Germany), Center for Human-Compatible AI
- Authors: Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan J Hubinger, Alexander Matt Turner
- Paper link: https://arxiv.org/abs/2312.06681
- Institution: Tsinghua University - Shenzhen International Graduate School, Tsinghua University
- Authors: Nian Li, Chen Gao , Mingyu Li, Yong Li, Qingmin Liao
- Paper link: https://arxiv.org/abs/2310.10436
- Institutions: Chinese University of Hong Kong, Huawei Noah's Ark Laboratory, Hong Kong University of Science and Technology
- Authors: Wai-Chung Kwan, Xingshan Zeng, Yufei Wang, Yusen Sun, Liangyou Li, Lifeng Shang, Qun Liu, Kam-Fai Wong
- Paper link: https://arxiv.org/abs/2310.19240
- Author: Jiasheng Si, Yibo Zhao, Yingjie Zhu, Haiyang Zhu, Wenpeng Lu, Deyu Zhou
- On Paper 26: On EFFICIENT and Statistics. U darmstadt , Apple Inc.
- Paper 27: Emulated Disalignment: Safety Alignment for Large Language Models May Backfire!
- Author : Zhanhui Zhou, Jie Liu, Zhichen Dong, Jiaheng Liu, Chao Yang, Wanli Ouyang, Yu Qiao
- Institution: Shanghai Artificial Intelligence Laboratory
- Paper 28: IndicLLMSuite: A Blueprint for Creating Pre-training and Fine-Tuning Datasets for Indian Languages
- Author: Mohammed Safi Ur Rahman Khan, Priyam Mehta, Ananth Sankar, etc.
- Institutions: Nilekani Center at AI4Bharat, Indian Institute of Technology (Madras), Microsoft, etc.
- Paper 29: MultiPICo: Multilingual Perspectivist lrony Corpus
- Authors: Silvia Casola, Simona Frenda, Soda Marem Lo, Erhan Sezerer, etc.
- Institutions: University of Turin, aqua-tech, Amazon Development Center (Italy), etc.
- Paper 30: MMToM-QA: Multimodal Theory of Mind Question Answering
- Authors: Chuanyang Jin, Yutong Wu, Jing Cao, jiannan Xiang, etc.
- Institutions: New York University, Harvard University, MIT, University of California, San Diego, University of Virginia, Johns Hopkins University
- Paper 31: MAP's not dead yet: Uncovering true language model modes by conditioning away degeneracy
- Author: Davis Yoshida , Kartik Goyal, Kevin Gimpel
- Institution: Toyota Institute of Technology Chicago, Georgia Institute of Technology
- Paper 32 : NounAtlas: Filling the Gap in Nominal Semantic Role Labeling
- Author: Roberto Navigli, Marco Lo Pinto, Pasquale Silvestri, etc.
- Paper 33: The Earth is Flat because... lnvestigating LLMs' Belief towards Misinformation via PersuasiveConversation
- Authors: Rongwu Xu, Brian S. Lin, Shujian Yang, Tiangi Zhang, etc.
- Institutions: Tsinghua University, Shanghai Jiao Tong University, Stanford University, Nanyang Technological University
- Paper 34: Let's Go Real Talk: Spoken Dialogue Model for Face-to-Face Conversation
- Author: Se Jin Park, Chae Won Kim, Hyeongseop Rha, Minsu Kim, etc.
- Institution: Korea Advanced Institute of Science and Technology (KAIST)
- Paper 35 :Word Embeddings Are Steers for Language Models
- Authors: Chi Han, Jialiang Xu, Manling Li, Yi Fung, Chenkai Sun, Nan Jiang, Tarek F. Abdelzaher, Heng Ji
- Institution: University of Illinois at Urbana - Champaign
- Best Theme Paper Award
Authors: Dirk Groeneveld, Iz Beltagy, etc. Institution: Allen Institute for Artificial Intelligence, University of Washington, etc. Paper link : https://arxiv.org/pdf/2402.00838 Authors: Julen Etxaniz, Oscar Sainz, Naiara Perez, Itziar Aldabe, German Rigau, Eneko Agirre, Aitor Ormazabal, Mikel Artetxe, Aitor Soroa Link: https://arxiv.org/pdf/2403.20266 Institution: Allen Institute for Artificial Intelligence, University of California, Berkeley, etc. Author: Luca Soldaini, Rodney Kinney, etc. Link: https://arxiv.org/abs/2402.00159 Institutions: State University of New York at Stony Brook, Allen Institute for Artificial Intelligence, etc. -
Authors: Harsh Trivedi, Tushar Khot, etc. Link: https://arxiv.org/abs/2407.18901 -
Authors: Yi Zeng, Hongpeng Lin, Jingwen Zhang, Diyi Yang, etc. Institutions: Virginia Tech, Renmin University of China, University of California, Davis, Stanford University Paper link: https://arxiv.org/pdf/2401.06373 -
Author: Fahim Faisal, Orevaoghene Ahia, Aarohi Srivastava, Kabir Ahuja, etc. Institutions: George Mason University, University of Washington, University of Notre Dame, RC Athena Paper link: https://arxiv.org/pdf/2403.11009 Author: Tarek Naous, Michael J. Ryan, Alan Ritter, Wei Xu Institution: Georgia Institute of Technology Paper link: https://arxiv.org/pdf/2305.14456
以上がACL 2024 賞の発表: HuaTech による Oracle 解読に関する最優秀論文の 1 つ、GloVe Time Test Awardの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
Java 架构 Resource for Length map 事件 input li 线性回归 oracle 人工智能 transformer nlp https proteus 重构 自动化 kong gpt llama Access word Foundation
声明:
この記事の内容はネチズンが自主的に寄稿したものであり、著作権は原著者に帰属します。このサイトは、それに相当する法的責任を負いません。盗作または侵害の疑いのあるコンテンツを見つけた場合は、admin@php.cn までご連絡ください。