
ホームページ >テクノロジー周辺機器 >AI >1 優秀、5 口頭!今年のByteDanceのACLは熾烈を極めるのか? ライブブロードキャストルームにチャットしに来てください!
1 優秀、5 口頭!今年のByteDanceのACLは熾烈を極めるのか? ライブブロードキャストルームにチャットしに来てください!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBオリジナル
- 2024-08-15 16:32:32813ブラウズ
Der Schwerpunkt akademischer Kreise liegt diese Woche zweifellos auf dem ACL 2024 Summit in Bangkok, Thailand. Diese Veranstaltung zog viele herausragende Forscher aus der ganzen Welt an, die zusammenkamen, um die neuesten akademischen Ergebnisse zu diskutieren und auszutauschen.
Offizielle Daten zeigen, dass die diesjährige ACL fast 5.000 Papiereinreichungen erhalten hat, von denen 940 von der Hauptkonferenz angenommen wurden und 168 Arbeiten für den mündlichen Bericht (mündlich) der Konferenz ausgewählt wurden. Die Annahmequote liegt unter 3,4 %. Darunter hat ByteDance insgesamt 5 ausgewählte Oral-Ergebnisse.
In der Paper Awards-Sitzung am Nachmittag des 14. August wurde ByteDances Errungenschaft „G-DIG: Towards Gradient-based DIverse and high-quality Instruction Data Selection for Machine Translation“ vom Veranstalter offiziell als Outstanding Paper bekannt gegeben ( 1/ 35).现 ACL 2024 vor Ort Fotos
 Zurück zu ACL 2021, Byte Beating hat die einzigen besten Arbeiten mit Lorbeer gewonnen. Es ist das zweite Mal, dass das chinesische Wissenschaftlerteam zum zweiten Mal seit der Gründung von ACL ausgewählt wurde. Hauptpreis!
Zurück zu ACL 2021, Byte Beating hat die einzigen besten Arbeiten mit Lorbeer gewonnen. Es ist das zweite Mal, dass das chinesische Wissenschaftlerteam zum zweiten Mal seit der Gründung von ACL ausgewählt wurde. Hauptpreis!
Um eine ausführliche Diskussion über die neuesten Forschungsergebnisse dieses Jahres zu führen, haben wir speziell die wichtigsten Mitarbeiter des ByteDance-Artikels zur Interpretation und zum Austausch eingeladen. Nächsten Dienstag, 20. August, von 19:00-21:00 Uhr, wird die „ByteDance ACL 2024 Cutting-edge Paper Sharing Session“ online übertragen!
Wang Mingxuan, Leiter des Doubao-Sprachmodell-Forschungsteams, wird mit vielen ByteDance-Forschern
Huang Zhichao, Zheng Zaixiang, Li Chaowei, Zhang Xinbo und dem mysteriösen Gast von Outstanding Paperzusammenarbeiten, um einige der aufregenden Ergebnisse zu teilen und Forschungsrichtungen von ACL. Es umfasst die Verarbeitung natürlicher Sprache, Sprachverarbeitung, multimodales Lernen, das Denken großer Modelle und andere Bereiche. Vereinbaren Sie gerne einen Termin! ?? ech Discretization Device
Papieradresse: https:// arxiv.org/pdf/2309.00169Angesichts der jüngsten rasanten Entwicklung großer Sprachmodelle (LLMs) spielt die diskrete Sprachtokenisierung eine wichtige Rolle bei der Injektion von Sprache in LLMs. Diese Diskretisierung führt jedoch zu einem Informationsverlust und beeinträchtigt somit die Gesamtleistung. Um die Leistung dieser diskreten Sprachtokens zu verbessern, schlagen wir RepCodec vor, einen neuartigen Sprachdarstellungscodec für die semantische Sprachdiskretisierung.
🔜 wie HuBERT oder data2vec. Der Sprachkodierer, der Codec-Kodierer und das VQ-Codebuch bilden zusammen einen Prozess, der Sprachwellenformen in semantische Token umwandelt. Umfangreiche Experimente zeigen, dass RepCodec aufgrund seiner verbesserten Informationsspeicherfähigkeiten die weit verbreitete K-Means-Clustering-Methode beim Sprachverständnis und der Sprachgenerierung deutlich übertrifft. Darüber hinaus gilt dieser Vorteil für eine Vielzahl von Sprachcodierern und Sprachen, was die Robustheit von RepCodec bestätigt. Dieser Ansatz kann die groß angelegte Sprachmodellforschung in der Sprachverarbeitung erleichtern. 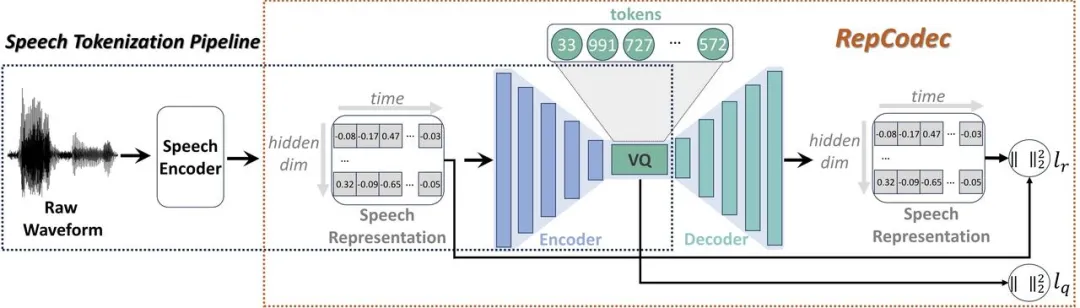

Während der. diff usionsmodell generiert Mit kontinuierlichen Signalen wie Bildern und Audio wurden große Erfolge erzielt, es bestehen jedoch weiterhin Schwierigkeiten beim Erlernen diskreter Sequenzdaten wie natürlicher Sprache. Obwohl eine neuere Reihe von Textdiffusionsmodellen diese Herausforderung der Diskretion umgehen, indem sie diskrete Zustände in einen latenten Zustandsraum mit kontinuierlichen Zuständen einbetten, ist ihre Generierungsqualität immer noch unbefriedigend. Um dies zu verstehen, analysieren wir zunächst den Trainingsprozess von Sequenzgenerierungsmodellen basierend auf Diffusionsmodellen und identifizieren drei schwerwiegende Probleme damit: (1) Lernfehler; (3) Vernachlässigung des Bedingungssignals; Wir glauben, dass diese Probleme auf die Unvollkommenheit der Diskretion im Einbettungsraum zurückzuführen sind, wo das Ausmaß des Rauschens eine entscheidende Rolle spielt. In dieser Arbeit schlagen wir DINOISER vor, das Diffusionsmodelle für die Sequenzgenerierung durch Manipulation von Rauschen verbessert. Wir bestimmen adaptiv den Bereich der abgetasteten Rauschskala während der Trainingsphase in einer von der optimalen Übertragung inspirierten Weise und ermutigen das Modell während der Inferenzphase, das bedingte Signal durch Verstärkung der Rauschskala besser auszunutzen. Experimente zeigen, dass DINOISER auf der Grundlage der vorgeschlagenen effektiven Trainings- und Inferenzstrategie die Basislinie früherer Diffusionssequenz-Generierungsmodelle bei mehreren bedingten Sequenzmodellierungs-Benchmarks übertrifft. Weitere Analysen bestätigten auch, dass DINOISER bedingte Signale besser zur Steuerung seines Generierungsprozesses nutzen kann. 
冗長性を削減することで視覚的条件付き言語生成のトレーニングを加速します 論文アドレス: https://arxiv.org/pdf/2310.03291
簡略化されたAのためのツールEVLGenを紹介します凍結された事前トレーニングされた大規模言語モデル (LLM) を活用し、高い計算要件を持つ視覚的条件付き言語生成モデルの事前トレーニング用に設計されたフレームワーク。 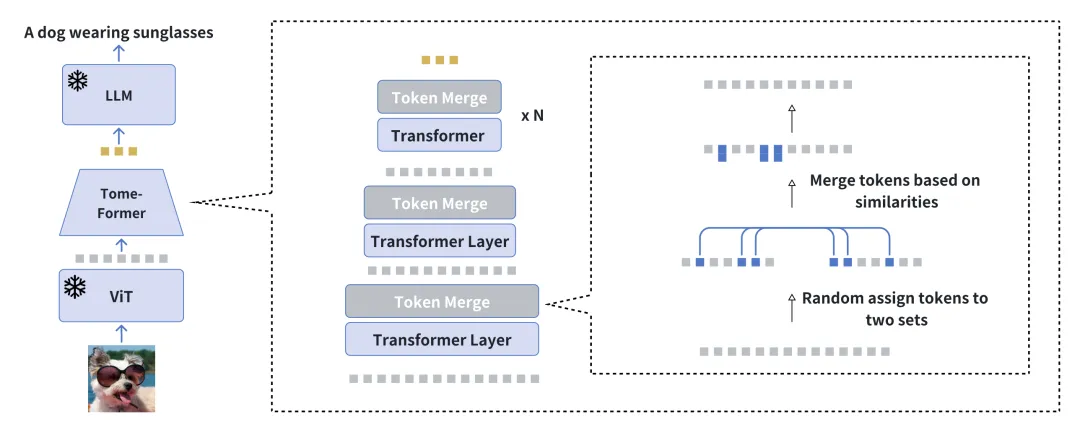
視覚言語事前トレーニング (VLP) における従来のアプローチには、通常 2 段階の最適化プロセスが含まれます: 一般的な視覚言語に特化したリソース集約型の初期段階 表現学習に焦点を当てる関連する視覚的特徴の抽出と統合について。これに続いて、視覚モダリティと言語モダリティの間のエンドツーエンドの調整を強調するフォローアップ フェーズが続きます。私たちの新しい単一ステージ、単一損失フレームワークは、BLIP-2 タイプ モデルの単一ステージ トレーニングによって引き起こされるモデルの不都合を回避しながら、トレーニング中に同様の視覚的ランドマークを徐々にマージすることで、計算量の多い最初のトレーニング ステージを回避します。段階的なマージ プロセスにより、セマンティックな豊かさを維持しながら視覚情報を効果的に圧縮し、パフォーマンスに影響を与えることなく高速な収束を実現します。
実験結果は、私たちの方法が全体的なパフォーマンスに大きな影響を与えることなく、視覚言語モデルのトレーニングを5倍高速化することを示しています。さらに、私たちのモデルは、わずか 10 分の 1 のデータを使用して、現在のビジュアル言語モデルとのパフォーマンスのギャップを大幅に縮めます。最後に、新しいソフト注意時間ラベル付きコンテキスト モジュールを介して、画像テキスト モデルをビデオ条件付き言語生成タスクにどのようにシームレスに適応できるかを示します。 
StreamVoice: リアルタイムのゼロショット音声変換のためのストリーミング可能なコンテキスト認識言語モデリング
論文アドレス: https://arxiv.org/pdf/2401.11053
ストリーミング ストリーミングゼロショット音声変換とは、入力音声を任意の話者の音声にリアルタイムで変換する機能を指し、参照として話者の音声の 1 文のみが必要で、追加のモデルの更新は必要ありません。既存のゼロサンプル音声変換方法は通常、オフライン システム用に設計されており、リアルタイム音声変換アプリケーションのストリーミング機能要件を満たすことが困難です。言語モデル (LM) に基づく最近の方法は、ゼロショット音声生成 (変換を含む) で優れたパフォーマンスを示していますが、文全体の処理が必要であり、オフライン シナリオに限定されます。 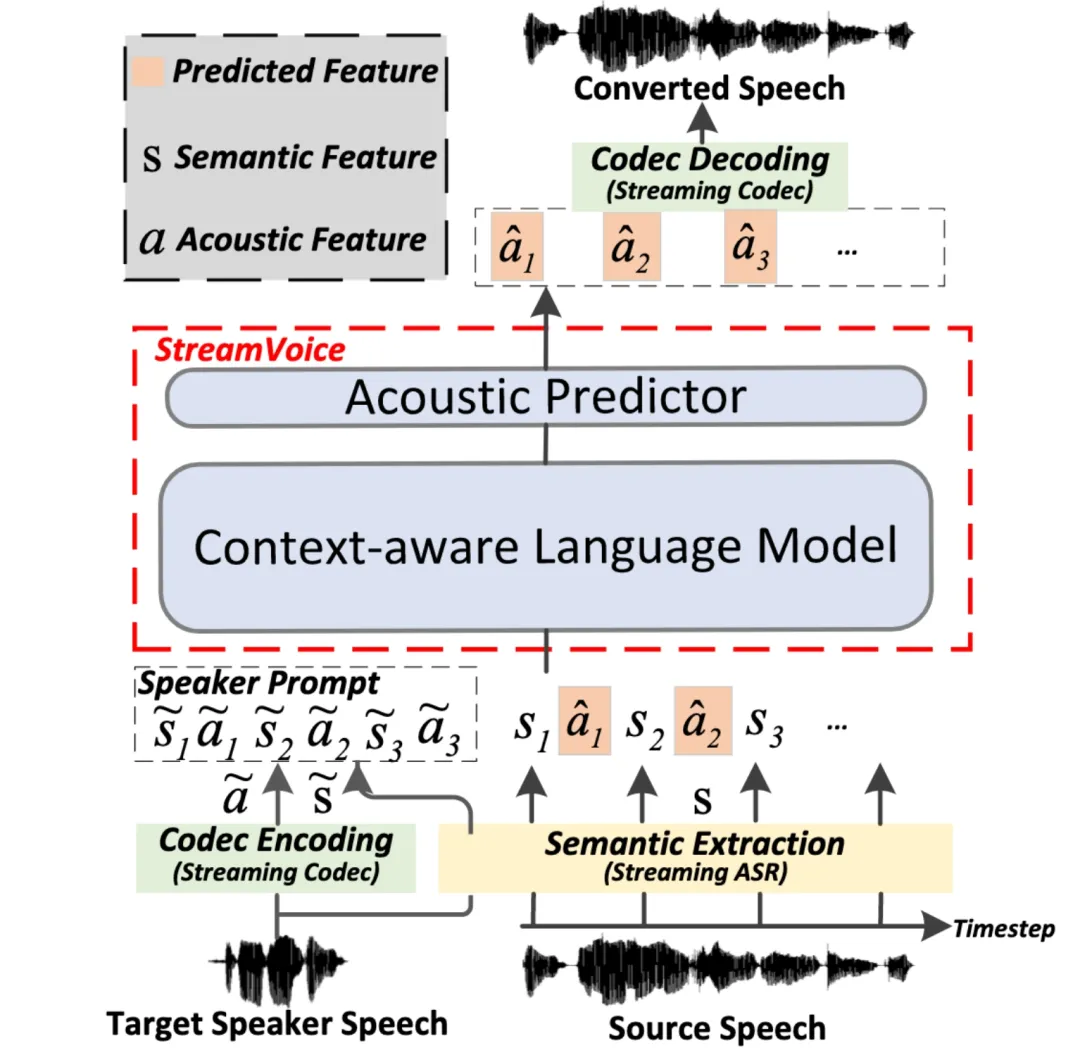 StreamV の全体的なアーキテクチャoice
StreamV の全体的なアーキテクチャoice この研究では、任意の話者と入力音声のリアルタイム変換を実現する、ストリーミング LM に基づく新しいゼロショット音声変換モデル StreamVoice を提案します。具体的には、ストリーミング機能を実現するために、StreamVoice はコンテキストを認識した完全因果 LM とタイミングに依存しない音響予測子を使用し、自己回帰プロセスで意味論的特徴と音響特徴を交互に使用することで、完全なソース音声への依存を排除します。
ストリーミング シナリオにおける不完全なコンテキストによって引き起こされるパフォーマンスの低下を解決するために、LM の未来と歴史のコンテキスト認識を強化するために 2 つの戦略が使用されます: 1) 教師主導のコンテキスト予測を通じて、教師主導のコンテキスト予測を通じて、モデルは次のことを要約します。欠落したコンテキストを予測する際にモデルを導く、現在および将来の正確なセマンティクス。2) セマンティック マスキング戦略により、モデルが以前に損傷したセマンティック入力から音響予測を達成し、歴史的コンテキストの学習能力を強化します。実験の結果、StreamVoice にはストリーミング変換機能があり、非ストリーミング VC システムに近いゼロショット パフォーマンスを達成できることがわかりました。

G-DIG: 勾配ベースの機械翻訳の多様性と高品質な命令データの選択に取り組んでいます 論文アドレス: https://arxiv.org/pdf/2405.12915
Large言語モデル (LLM) は、一般的なシナリオにおいて並外れた機能を実証しています。命令を微調整することで、さまざまなタスクで人間と同等のパフォーマンスを発揮できるようになります。ただし、命令データの多様性と品質は、命令の微調整にとって依然として 2 つの大きな課題です。この目的を達成するために、機械翻訳用に高品質で多様な命令微調整データを自動的に選択する新しい勾配ベースのアプローチを提案します。私たちの主なイノベーションは、個々のトレーニング サンプルがトレーニング中にモデルにどのような影響を与えるかを分析することにあります。 
G-DIG の概要
具体的には、インフルエンス関数と小規模で高品質なシード データ セット。さらに、トレーニング データの多様性を高めるために、勾配をクラスタリングしてリサンプリングすることで、モデルに対するデータの影響の多様性を最大化します。 WMT22 および FLORES 翻訳タスクに関する広範な実験により、私たちの手法の優位性が実証され、詳細な分析により、その有効性と一般性がさらに検証されました。

GroundingGPT: 言語強化マルチモーダルグラウンディングモデル 論文アドレス: https://arxiv.org/pdf/2401.06071
マルチモーダルなビッグ言語モデルさまざまなモダリティにわたるさまざまなタスクで優れたパフォーマンスを発揮します。ただし、以前のモデルは主にマルチモーダル入力のグローバル情報を取得することに重点を置いているため、入力データの詳細を効果的に理解する能力が不足しており、同時に、入力の詳細な理解を必要とするタスクではパフォーマンスが低下します。これらのモデルには深刻な幻覚の問題があり、その普及が制限されています。
この問題を解決し、より広範囲のタスクにおける大規模なマルチモーダル モデルの汎用性を高めるために、画像、ビデオ、オーディオのさまざまな粒度の理解を達成できるマルチモーダル モデルである GroundingGPT を提案します。グローバルな情報をキャプチャすることに加えて、私たちが提案するモデルは、画像内の特定の領域やビデオ内の特定の瞬間を正確に特定するモデルの機能など、より詳細な理解を必要とするタスクの処理にも優れています。この目標を達成するために、私たちは、マルチモーダルかつマルチ粒度のトレーニング データ セットを構築するための多様なデータセット構築プロセスを設計しました。複数の公開ベンチマークでの実験により、モデルの多用途性と有効性が実証されました。

ReFT: 強化微調整に基づく推論 論文アドレス: https://arxiv.org/pdf/2401.08967
強化大規模言語モデル (LLM) の一般的なタイプ) 推論 有効なアプローチは、思考連鎖 (CoT) 注釈付きデータを使用した教師あり微調整 (SFT) です。ただし、トレーニングは指定された CoT データのみに依存するため、この方法では十分な一般化能力が得られません。具体的には、数学的問題に関連するデータ セットでは、通常、トレーニング データ内の各問題に対して注釈付きの推論パスが 1 つだけ存在します。アルゴリズムの場合、問題に対して複数のラベル付き推論パスを学習できれば、より強力な汎化機能が得られます。
 CoT代替手段の存在に関するSFTとReFTの比較
CoT代替手段の存在に関するSFTとReFTの比較
この課題を解決するために、数学的問題を例として、推論中の LLM の汎化能力を強化する強化微調整 (ReFT) と呼ばれるシンプルで効果的な方法を提案します。 ReFT は、まず SFT を使用してモデルをウォームアップし、次にオンライン強化学習 (特にこの作業では PPO アルゴリズム) を使用して最適化します。これにより、特定の問題に対する多数の推論パスが自動的にサンプリングされ、問題に対する実際の回答に基づいて報酬が得られます。モデルをさらに微調整します。
インタラクティブな質問をお待ちしています
ライブ放送時間: 2024年8月20日(火) 19:00-21:00 ライブブロードキャストプラットフォーム: WeChatビデオアカウント[Doubao Big Model Team]、 Xiao Red Book Number [Doubao 研究者]

Beanbao モデルチームは引き続き募集中です。チーム募集関連情報については、このリンクをクリックしてください。
Während der. diff usionsmodell generiert Mit kontinuierlichen Signalen wie Bildern und Audio wurden große Erfolge erzielt, es bestehen jedoch weiterhin Schwierigkeiten beim Erlernen diskreter Sequenzdaten wie natürlicher Sprache. Obwohl eine neuere Reihe von Textdiffusionsmodellen diese Herausforderung der Diskretion umgehen, indem sie diskrete Zustände in einen latenten Zustandsraum mit kontinuierlichen Zuständen einbetten, ist ihre Generierungsqualität immer noch unbefriedigend. Um dies zu verstehen, analysieren wir zunächst den Trainingsprozess von Sequenzgenerierungsmodellen basierend auf Diffusionsmodellen und identifizieren drei schwerwiegende Probleme damit: (1) Lernfehler; (3) Vernachlässigung des Bedingungssignals; Wir glauben, dass diese Probleme auf die Unvollkommenheit der Diskretion im Einbettungsraum zurückzuführen sind, wo das Ausmaß des Rauschens eine entscheidende Rolle spielt. In dieser Arbeit schlagen wir DINOISER vor, das Diffusionsmodelle für die Sequenzgenerierung durch Manipulation von Rauschen verbessert. Wir bestimmen adaptiv den Bereich der abgetasteten Rauschskala während der Trainingsphase in einer von der optimalen Übertragung inspirierten Weise und ermutigen das Modell während der Inferenzphase, das bedingte Signal durch Verstärkung der Rauschskala besser auszunutzen. Experimente zeigen, dass DINOISER auf der Grundlage der vorgeschlagenen effektiven Trainings- und Inferenzstrategie die Basislinie früherer Diffusionssequenz-Generierungsmodelle bei mehreren bedingten Sequenzmodellierungs-Benchmarks übertrifft. Weitere Analysen bestätigten auch, dass DINOISER bedingte Signale besser zur Steuerung seines Generierungsprozesses nutzen kann.冗長性を削減することで視覚的条件付き言語生成のトレーニングを加速します 論文アドレス: https://arxiv.org/pdf/2310.03291 簡略化されたAのためのツールEVLGenを紹介します凍結された事前トレーニングされた大規模言語モデル (LLM) を活用し、高い計算要件を持つ視覚的条件付き言語生成モデルの事前トレーニング用に設計されたフレームワーク。 視覚言語事前トレーニング (VLP) における従来のアプローチには、通常 2 段階の最適化プロセスが含まれます: 一般的な視覚言語に特化したリソース集約型の初期段階 表現学習に焦点を当てる関連する視覚的特徴の抽出と統合について。これに続いて、視覚モダリティと言語モダリティの間のエンドツーエンドの調整を強調するフォローアップ フェーズが続きます。私たちの新しい単一ステージ、単一損失フレームワークは、BLIP-2 タイプ モデルの単一ステージ トレーニングによって引き起こされるモデルの不都合を回避しながら、トレーニング中に同様の視覚的ランドマークを徐々にマージすることで、計算量の多い最初のトレーニング ステージを回避します。段階的なマージ プロセスにより、セマンティックな豊かさを維持しながら視覚情報を効果的に圧縮し、パフォーマンスに影響を与えることなく高速な収束を実現します。 実験結果は、私たちの方法が全体的なパフォーマンスに大きな影響を与えることなく、視覚言語モデルのトレーニングを5倍高速化することを示しています。さらに、私たちのモデルは、わずか 10 分の 1 のデータを使用して、現在のビジュアル言語モデルとのパフォーマンスのギャップを大幅に縮めます。最後に、新しいソフト注意時間ラベル付きコンテキスト モジュールを介して、画像テキスト モデルをビデオ条件付き言語生成タスクにどのようにシームレスに適応できるかを示します。
StreamVoice: リアルタイムのゼロショット音声変換のためのストリーミング可能なコンテキスト認識言語モデリング
論文アドレス: https://arxiv.org/pdf/2401.11053
ストリーミング ストリーミングゼロショット音声変換とは、入力音声を任意の話者の音声にリアルタイムで変換する機能を指し、参照として話者の音声の 1 文のみが必要で、追加のモデルの更新は必要ありません。既存のゼロサンプル音声変換方法は通常、オフライン システム用に設計されており、リアルタイム音声変換アプリケーションのストリーミング機能要件を満たすことが困難です。言語モデル (LM) に基づく最近の方法は、ゼロショット音声生成 (変換を含む) で優れたパフォーマンスを示していますが、文全体の処理が必要であり、オフライン シナリオに限定されます。 この研究では、任意の話者と入力音声のリアルタイム変換を実現する、ストリーミング LM に基づく新しいゼロショット音声変換モデル StreamVoice を提案します。具体的には、ストリーミング機能を実現するために、StreamVoice はコンテキストを認識した完全因果 LM とタイミングに依存しない音響予測子を使用し、自己回帰プロセスで意味論的特徴と音響特徴を交互に使用することで、完全なソース音声への依存を排除します。
ストリーミング シナリオにおける不完全なコンテキストによって引き起こされるパフォーマンスの低下を解決するために、LM の未来と歴史のコンテキスト認識を強化するために 2 つの戦略が使用されます: 1) 教師主導のコンテキスト予測を通じて、教師主導のコンテキスト予測を通じて、モデルは次のことを要約します。欠落したコンテキストを予測する際にモデルを導く、現在および将来の正確なセマンティクス。2) セマンティック マスキング戦略により、モデルが以前に損傷したセマンティック入力から音響予測を達成し、歴史的コンテキストの学習能力を強化します。実験の結果、StreamVoice にはストリーミング変換機能があり、非ストリーミング VC システムに近いゼロショット パフォーマンスを達成できることがわかりました。
G-DIG: 勾配ベースの機械翻訳の多様性と高品質な命令データの選択に取り組んでいます 論文アドレス: https://arxiv.org/pdf/2405.12915 Large言語モデル (LLM) は、一般的なシナリオにおいて並外れた機能を実証しています。命令を微調整することで、さまざまなタスクで人間と同等のパフォーマンスを発揮できるようになります。ただし、命令データの多様性と品質は、命令の微調整にとって依然として 2 つの大きな課題です。この目的を達成するために、機械翻訳用に高品質で多様な命令微調整データを自動的に選択する新しい勾配ベースのアプローチを提案します。私たちの主なイノベーションは、個々のトレーニング サンプルがトレーニング中にモデルにどのような影響を与えるかを分析することにあります。
G-DIG の概要
具体的には、インフルエンス関数と小規模で高品質なシード データ セット。さらに、トレーニング データの多様性を高めるために、勾配をクラスタリングしてリサンプリングすることで、モデルに対するデータの影響の多様性を最大化します。 WMT22 および FLORES 翻訳タスクに関する広範な実験により、私たちの手法の優位性が実証され、詳細な分析により、その有効性と一般性がさらに検証されました。
GroundingGPT: 言語強化マルチモーダルグラウンディングモデル 論文アドレス: https://arxiv.org/pdf/2401.06071 マルチモーダルなビッグ言語モデルさまざまなモダリティにわたるさまざまなタスクで優れたパフォーマンスを発揮します。ただし、以前のモデルは主にマルチモーダル入力のグローバル情報を取得することに重点を置いているため、入力データの詳細を効果的に理解する能力が不足しており、同時に、入力の詳細な理解を必要とするタスクではパフォーマンスが低下します。これらのモデルには深刻な幻覚の問題があり、その普及が制限されています。
この問題を解決し、より広範囲のタスクにおける大規模なマルチモーダル モデルの汎用性を高めるために、画像、ビデオ、オーディオのさまざまな粒度の理解を達成できるマルチモーダル モデルである GroundingGPT を提案します。グローバルな情報をキャプチャすることに加えて、私たちが提案するモデルは、画像内の特定の領域やビデオ内の特定の瞬間を正確に特定するモデルの機能など、より詳細な理解を必要とするタスクの処理にも優れています。この目標を達成するために、私たちは、マルチモーダルかつマルチ粒度のトレーニング データ セットを構築するための多様なデータセット構築プロセスを設計しました。複数の公開ベンチマークでの実験により、モデルの多用途性と有効性が実証されました。
ReFT: 強化微調整に基づく推論 論文アドレス: https://arxiv.org/pdf/2401.08967 強化大規模言語モデル (LLM) の一般的なタイプ) 推論 有効なアプローチは、思考連鎖 (CoT) 注釈付きデータを使用した教師あり微調整 (SFT) です。ただし、トレーニングは指定された CoT データのみに依存するため、この方法では十分な一般化能力が得られません。具体的には、数学的問題に関連するデータ セットでは、通常、トレーニング データ内の各問題に対して注釈付きの推論パスが 1 つだけ存在します。アルゴリズムの場合、問題に対して複数のラベル付き推論パスを学習できれば、より強力な汎化機能が得られます。
この課題を解決するために、数学的問題を例として、推論中の LLM の汎化能力を強化する強化微調整 (ReFT) と呼ばれるシンプルで効果的な方法を提案します。 ReFT は、まず SFT を使用してモデルをウォームアップし、次にオンライン強化学習 (特にこの作業では PPO アルゴリズム) を使用して最適化します。これにより、特定の問題に対する多数の推論パスが自動的にサンプリングされ、問題に対する実際の回答に基づいて報酬が得られます。モデルをさらに微調整します。
GSM8K、MathQA、SVAMP データセットに関する広範な実験により、ReFT が SFT を大幅に上回り、多数決や並べ替えなどの戦略を組み合わせることでモデルのパフォーマンスをさらに向上できることが示されました。ここで、ReFT は SFT と同じトレーニング問題のみに依存し、追加または強化されたトレーニング問題には依存しないことに注意してください。これは、ReFT が優れた汎化能力を持っていることを示しています。 インタラクティブな質問をお待ちしています
ライブ放送時間: 2024年8月20日(火) 19:00-21:00 ライブブロードキャストプラットフォーム: WeChatビデオアカウント[Doubao Big Model Team]、 Xiao Red Book Number [Doubao 研究者] アンケートに記入して、ACL 2024 論文に関して興味のある質問について教えてください。オンラインで複数の研究者とチャットできます。 Beanbao モデルチームは引き続き募集中です。チーム募集関連情報については、このリンクをクリックしてください。
以上が1 優秀、5 口頭!今年のByteDanceのACLは熾烈を極めるのか? ライブブロードキャストルームにチャットしに来てください!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。