



AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出電子メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com

論文タイトル: SpatialBot: Precise Depth Understanding with Vision Language Models 論文リンク: https://arxiv.org/abs/2406.13642 プロジェクトホームページ: https://github. com/BAAI-DCAI/SpatialBot
 2. 中央のティーカップを掴みます
2. 中央のティーカップを掴みます 
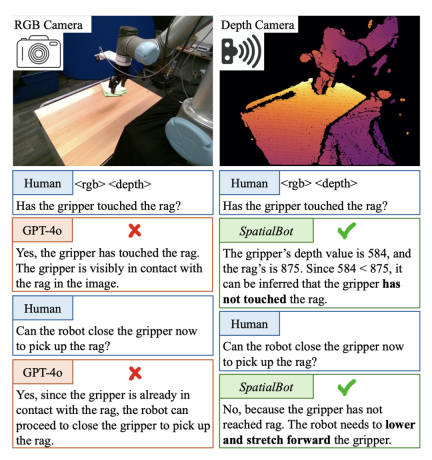
既存のモデルは深度マップ入力を直接理解できません。たとえば、画像エンコーダ CLIP/SigLIP は、深度マップをまったく参照せずに RGB 画像でトレーニングされます。 既存の大規模モデル データセットのほとんどは、RGB のみを使用して分析し、回答することができます。したがって、既存のデータが単に RGBD 入力に変更された場合、モデルは知識を深度マップに積極的にインデックス付けしません。モデルが深度マップを理解し、深度情報を使用できるようにするには、特別に設計されたタスクと QA が必要です。

在 low level 引导模型理解深度图,引导从深度图直接获取信息; 在 middle level 让模型将 depth 与 RGB 对齐; 在 high level 设计多个深度相关任务,标注了 50k 的数据,让模型在理解深度图的基础上,使用深度信息完成任务。任务包括:空间位置关系,物体大小,物体接触与否,机器人场景理解等。
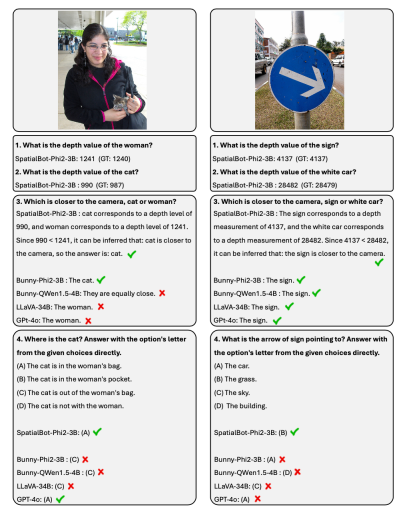


直接理解深度图,让模型看深度图,分析深度的分布,猜测其中可能包含的物体; 空间关系理解和推理; 机器人场景理解:描述 Open X-Embodiment 和本文收集的机器人数据中的场景、包含的物体、可能的任务,并人工标注物体、机器人的 bounding box。



以上が李飛飛の「空間知能」の後、上海交通大学、知源大学、北京大学などが大規模空間モデルSpatialBotを提案したの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Huggingface smollmであなたの個人的なAIアシスタントを構築する方法Apr 18, 2025 am 11:52 AM
Huggingface smollmであなたの個人的なAIアシスタントを構築する方法Apr 18, 2025 am 11:52 AMオンデバイスAIの力を活用:個人的なチャットボットCLIの構築 最近では、個人的なAIアシスタントの概念はサイエンスフィクションのように見えました。 ハイテク愛好家のアレックスを想像して、賢くて地元のAI仲間を夢見ています。
 メンタルヘルスのためのAIは、スタンフォード大学でのエキサイティングな新しいイニシアチブによって注意深く分析されますApr 18, 2025 am 11:49 AM
メンタルヘルスのためのAIは、スタンフォード大学でのエキサイティングな新しいイニシアチブによって注意深く分析されますApr 18, 2025 am 11:49 AMAI4MHの最初の発売は2025年4月15日に開催され、有名な精神科医および神経科学者であるLuminary Dr. Tom Insel博士がキックオフスピーカーを務めました。 Insel博士は、メンタルヘルス研究とテクノでの彼の傑出した仕事で有名です
 2025年のWNBAドラフトクラスは、成長し、オンラインハラスメントの成長と戦いに参加しますApr 18, 2025 am 11:44 AM
2025年のWNBAドラフトクラスは、成長し、オンラインハラスメントの成長と戦いに参加しますApr 18, 2025 am 11:44 AM「私たちは、WNBAが、すべての人、プレイヤー、ファン、企業パートナーが安全であり、大切になり、力を与えられたスペースであることを保証したいと考えています」とエンゲルバートは述べ、女性のスポーツの最も有害な課題の1つになったものに取り組んでいます。 アノ
 Pythonビルトインデータ構造の包括的なガイド-AnalyticsVidhyaApr 18, 2025 am 11:43 AM
Pythonビルトインデータ構造の包括的なガイド-AnalyticsVidhyaApr 18, 2025 am 11:43 AM導入 Pythonは、特にデータサイエンスと生成AIにおいて、プログラミング言語として優れています。 大規模なデータセットを処理する場合、効率的なデータ操作(ストレージ、管理、アクセス)が重要です。 以前に数字とstをカバーしてきました
 Openaiの新しいモデルからの代替案からの第一印象Apr 18, 2025 am 11:41 AM
Openaiの新しいモデルからの代替案からの第一印象Apr 18, 2025 am 11:41 AM潜る前に、重要な注意事項:AIパフォーマンスは非決定論的であり、非常にユースケース固有です。簡単に言えば、走行距離は異なる場合があります。この(または他の)記事を最終的な単語として撮影しないでください。これらのモデルを独自のシナリオでテストしないでください
 AIポートフォリオ| AIキャリアのためにポートフォリオを構築する方法は?Apr 18, 2025 am 11:40 AM
AIポートフォリオ| AIキャリアのためにポートフォリオを構築する方法は?Apr 18, 2025 am 11:40 AM傑出したAI/MLポートフォリオの構築:初心者と専門家向けガイド 説得力のあるポートフォリオを作成することは、人工知能(AI)と機械学習(ML)で役割を確保するために重要です。 このガイドは、ポートフォリオを構築するためのアドバイスを提供します
 エージェントAIがセキュリティ運用にとって何を意味するのかApr 18, 2025 am 11:36 AM
エージェントAIがセキュリティ運用にとって何を意味するのかApr 18, 2025 am 11:36 AM結果?燃え尽き症候群、非効率性、および検出とアクションの間の隙間が拡大します。これは、サイバーセキュリティで働く人にとってはショックとしてはありません。 しかし、エージェントAIの約束は潜在的なターニングポイントとして浮上しています。この新しいクラス
 Google対Openai:学生のためのAIの戦いApr 18, 2025 am 11:31 AM
Google対Openai:学生のためのAIの戦いApr 18, 2025 am 11:31 AM即時の影響と長期パートナーシップ? 2週間前、Openaiは強力な短期オファーで前進し、2025年5月末までに米国およびカナダの大学生にChatGpt Plusに無料でアクセスできます。このツールにはGPT ‑ 4o、Aが含まれます。


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

メモ帳++7.3.1
使いやすく無料のコードエディター

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

ドリームウィーバー CS6
ビジュアル Web 開発ツール

