
ホームページ >テクノロジー周辺機器 >AI >AIイメージングの新基準、元データのわずか1%で最高のパフォーマンスを達成できる、一般医療基本モデルがNatureサブジャーナルに掲載
AIイメージングの新基準、元データのわずか1%で最高のパフォーマンスを達成できる、一般医療基本モデルがNatureサブジャーナルに掲載

- 王林オリジナル
- 2024-07-22 17:38:001063ブラウズ

Editor | Cabbage Leaf
大規模な事前トレーニングされた基本モデルは、非医療分野で大きな成功を収めています。ただし、これらのモデルのトレーニングには、生物医学イメージングで一般的な小規模でより特殊なデータセットとは対照的に、大規模で包括的なデータセットが必要になることがよくあります。
ドイツのフラウンホーファーデジタル医学研究所 MEVIS の研究者らは、トレーニング タスクの数とメモリ要件を分離するマルチタスク学習戦略を提案しました。
彼らは、断層撮影、顕微鏡検査、X 線画像などのマルチタスク データベース上でユニバーサル生物医学事前トレーニング モデル (UMedPT) をトレーニングし、分類、セグメンテーション、物体検出などのさまざまなラベリング戦略を採用しました。 UMedPT 基本モデルは、ImageNet の事前トレーニング済みモデルや以前の STOA モデルよりも優れたパフォーマンスを発揮します。
外部の独立した検証では、UMedPT を使用して抽出された画像特徴が中心間伝達性の新しい標準を設定することが証明されました。
この研究は「基礎的なマルチタスクモデルによる生物医学イメージングにおけるデータ不足の克服」と題され、2024年7月19日に「Nature Computational Science」に掲載されました。

ディープラーニングは、有用な画像表現を学習して抽出する機能により、生物医学画像分析に徐々に革命をもたらしています。
一般的な方法は、大規模な自然画像データセット (ImageNet や LAION など) でモデルを事前トレーニングし、特定のタスクに合わせて微調整するか、事前トレーニングされた特徴を直接使用することです。ただし、微調整にはより多くのコンピューティング リソースが必要です。
同時に、生物医学イメージングの分野では、効果的な深層学習の事前トレーニングのために大量の注釈付きデータが必要ですが、そのようなデータは不足していることがよくあります。
マルチタスク学習 (MTL) は、複数のタスクを同時に解決するようにモデルをトレーニングすることで、データ不足に対する解決策を提供します。生物医学イメージングにおいて多くの中小規模のデータセットを活用して、すべてのタスクに適した画像表現を事前トレーニングし、データが不足している領域に適しています。
MTL は、さまざまなタスク用に複数の中小規模のデータセットからトレーニングしたり、単一の画像上で複数のラベル タイプを使用したりするなど、さまざまな方法で生物医学画像分析に適用されており、共有特徴がタスクのパフォーマンスを向上させることができることを実証しています。
最新の研究では、大規模な事前トレーニングのために異なるラベルタイプを持つ複数のデータセットを組み合わせるために、MEVIS Instituteの研究者は、特に異なるモダリティにわたる多用途表現の学習を通じて、マルチタスクトレーニング戦略と対応するモデルアーキテクチャを導入しました。 、疾患、およびラベルの種類を考慮して、生物医学イメージングにおけるデータ不足に対処します。
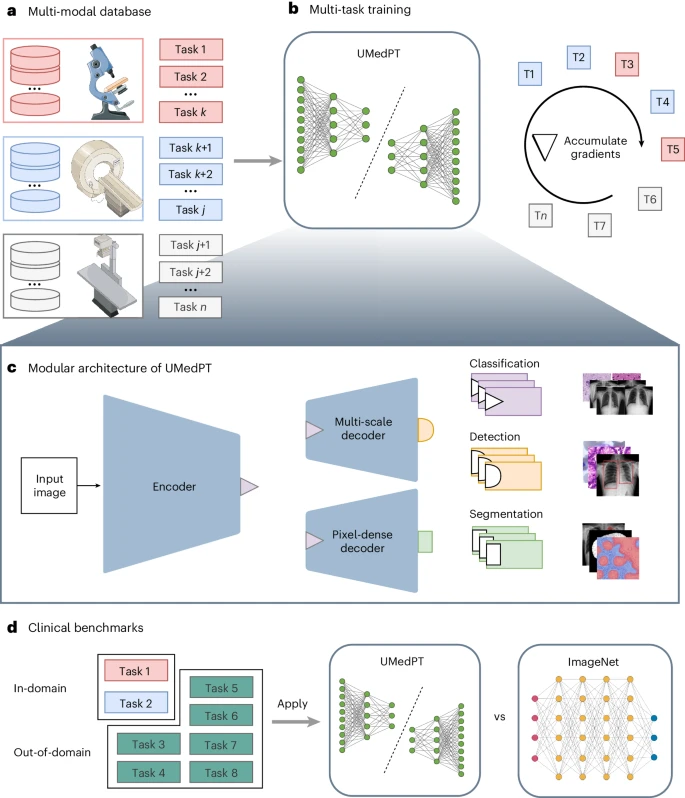
大規模なマルチタスク学習で遭遇するメモリの制約に対処するために、この方法では勾配累積ベースのトレーニング ループが採用されており、その拡張はトレーニング タスクの数によってほぼ無制限です。
これに基づいて、研究者らは 17 のタスクとそのオリジナルのアノテーションを使用して、UMedPT と呼ばれる完全に教師付きの生物医学イメージング基本モデルをトレーニングしました。
下の画像は、エンコーダー、セグメンテーション デコーダー、ローカリゼーション デコーダーを含む共有ブロックとタスク固有のヘッドで構成されるチームのニューラル ネットワークのアーキテクチャを示しています。共有ブロックはすべての事前トレーニング タスクに適用できるようにトレーニングされ、共通の特徴を抽出するのに役立ちます。また、タスク固有のスーパーバイザーがラベル固有の損失計算と予測を処理します。
設定されたタスクには、オブジェクト検出、セグメンテーション、分類という 3 つの教師ありラベル タイプが含まれます。たとえば、分類タスクはバイナリ バイオマーカーをモデル化でき、セグメンテーション タスクは空間情報を抽出でき、物体検出タスクは細胞数に基づいてバイオマーカーをトレーニングするために使用できます。
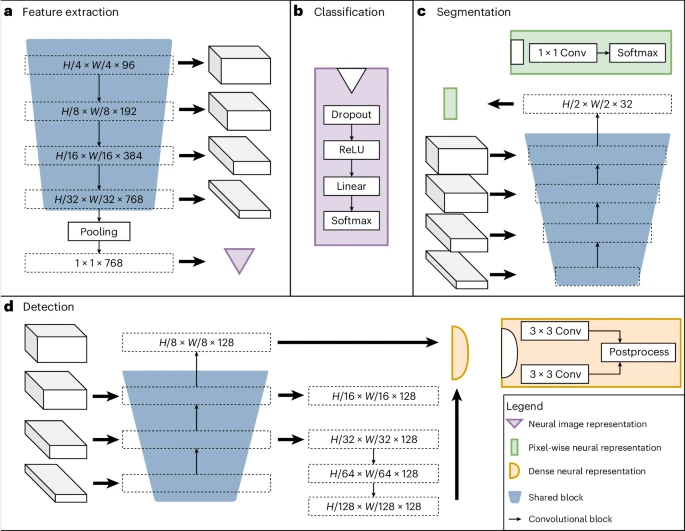
イラスト: UMedPT のアーキテクチャ。 (出典: 論文)
UMedPT は、画像表現 (フリーズ) と微調整設定を直接適用する際に、少ないトレーニング データを使用して強力なパフォーマンスを維持しながら、ドメイン内タスクとドメイン外タスクの両方で事前トレーニングされた ImageNet ネットワークと一貫して一致またはそれを上回るパフォーマンスを発揮します。
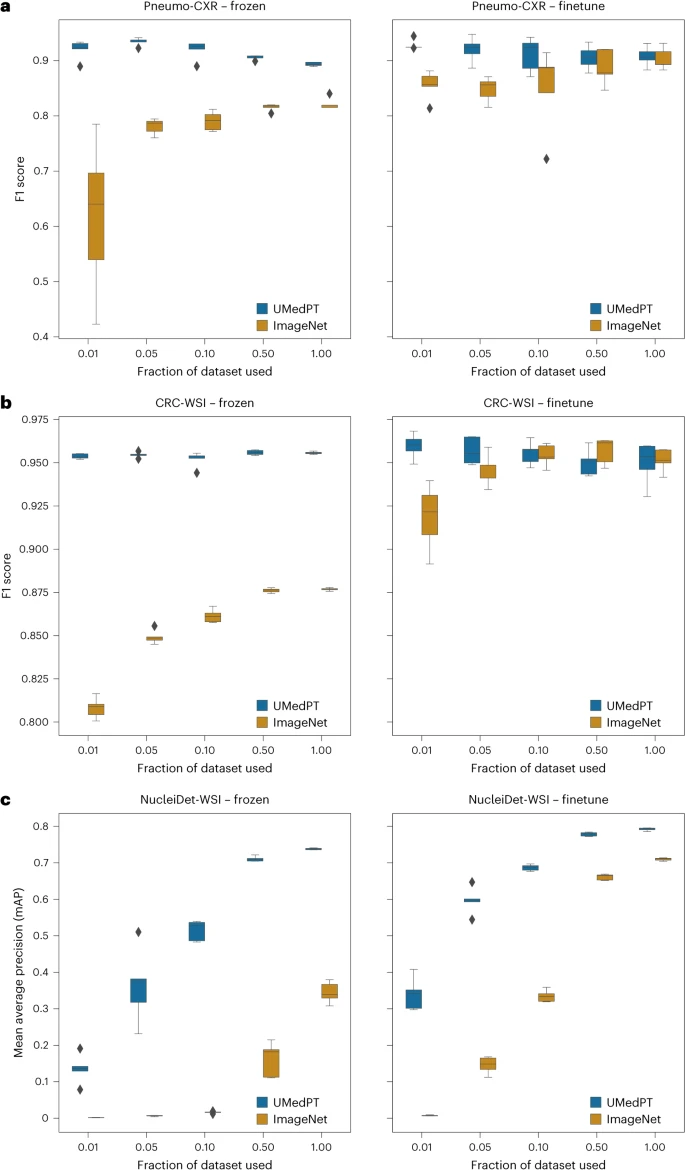
イラスト: ドメイン内のタスクの結果。 (出典: 論文)
事前トレーニングされたデータベースに関連付けられた分類タスクの場合、UMedPT は、元のトレーニング データの 1% のみを使用して、すべての構成で ImageNet ベースラインの最高のパフォーマンスを達成できます。このモデルは、ファインチューニングを使用したモデルと比較して、フリーズされたエンコーダーを使用してより高いパフォーマンスを実現します。
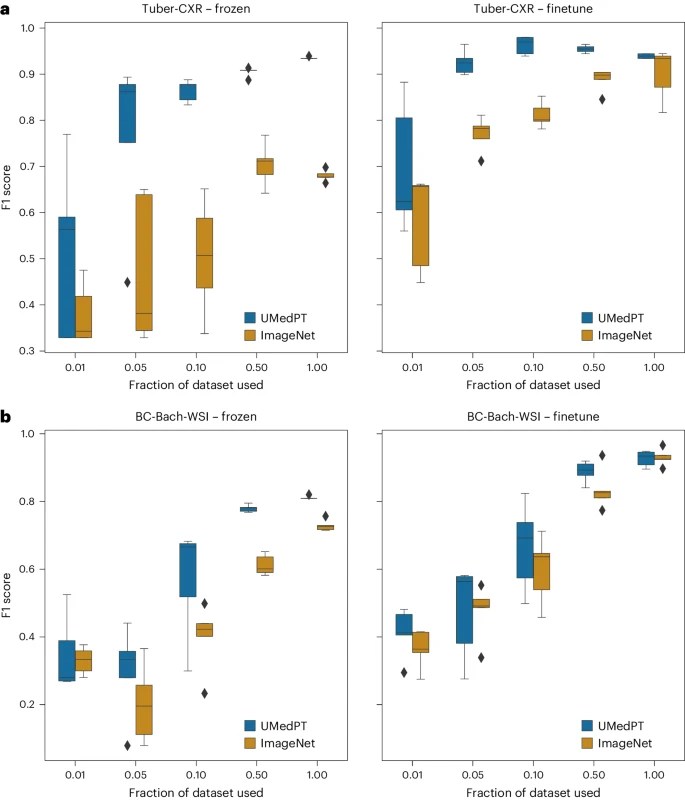
図: ドメイン外タスクの結果 (出典: 論文)
ドメイン外タスクの場合、UMedPT は、微細なデータを使用しても 50% 以下のデータのみを使用して ImageNet のパフォーマンスに匹敵することができます。チューニングが適用されました。
さらに、研究者らは UMedPT のパフォーマンスを文献で報告された結果と比較しました。フリーズされたエンコーダ構成を使用すると、ほとんどのタスクで UMedPT が外部参照の結果を超えました。この設定では、MedMNIST データベース 16 の平均曲線下面積 (AUC) よりも優れています。
UMedPT の凍結適用が参照結果を上回らなかったタスクは、領域外であったことは注目に値します (乳がんの分類には BC-Bach-WSI、中枢神経系腫瘍の診断には CNS-MRI)。微調整を行うと、UMedPT による事前トレーニングは、すべてのタスクにおいて外部参照の結果よりも優れたパフォーマンスを発揮します。

図: UMedPT がさまざまなイメージング ドメインのタスクで最先端のパフォーマンスを達成するために必要なデータ量。 (出典: 論文)
データが不足している分野における将来の開発の基盤として、UMedPT は、希少疾患や小児画像処理など、大量のデータの収集が特に困難な医療分野におけるディープラーニング応用の可能性を切り開きます。
論文リンク:https://www.nature.com/articles/s43588-024-00662-z
関連コンテンツ:https://www.nature.com/articles/s43588-024-00658- 9
以上がAIイメージングの新基準、元データのわずか1%で最高のパフォーマンスを達成できる、一般医療基本モデルがNatureサブジャーナルに掲載の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。