
ホームページ >バックエンド開発 >Python チュートリアル >Ibis を使用した宣言型マルチエンジン データ スタック
Ibis を使用した宣言型マルチエンジン データ スタック

- 王林オリジナル
- 2024-07-19 03:34:101577ブラウズ
TL;DR
私は最近、マルチエンジン データ スタックに関する Julien Hurault による Ju Data Engineering ニュースレターを見つけました。アイデアはシンプルです。新しいバックエンドや機能が開発されるにつれてパイプラインを拡張できる柔軟性を維持しながら、任意のバックエンドにコードを簡単に移植したいと考えています。これには、少なくとも次の高レベルのワークフローが必要になります:
- DuckDB、polars、DataFusion、chdb などを使用して、SQL クエリの一部をサーバーレス エンジンにオフロードします。
- さまざまな開発および展開シナリオに適したサイズのパイプライン。たとえば、開発者はローカルで作業し、自信を持って本番環境に出荷できます。
- データベース スタイルの最適化をパイプラインに自動的に適用します。
この投稿では、プログラミング言語からマルチエンジン パイプラインを実装する方法について詳しく説明します。 SQL の代わりに、対話型とバッチの両方のユースケースに使用できるデータフレーム API の使用を提案します。具体的には、パイプラインを小さな部分に分割し、DuckDB、pandas、Snowflake 全体で実行する方法を示します。また、マルチエンジン データ スタックの利点についても説明し、この分野の新たなトレンドに焦点を当てます。
この投稿で実装されたコードは GitHub で入手できます^[リポジトリをすぐに試すために、nix flake も提供しています]。オリジナルの実装を含むニュースレターの参考作品はここにあります。
概要
マルチエンジン データ スタック パイプラインは次のように動作します: 一部のデータは S3 バケットに配置され、重複を削除するために前処理されてから Snowflake テーブルにロードされ、そこで ML または Snowflake 固有の関数でさらに変換されます^[ご注意ください] Snowflake で可能な可能性のあるタイプの実装には立ち入らず、それがワークフローの要件であると想定します。]パイプラインは注文を寄木細工のファイルとして受け取り、ランディング場所に保存され、前処理されてからステージング場所の S3 バケットに保存されます。次に、ステージング データが Snowflake にロードされ、ダウンストリーム BI ツールに接続されます。パイプラインは SQL dbt によってバックエンドごとに 1 つのモデルと結合されており、ニュースレターではオーケストレーション ツールとして Dagster を選択しています。
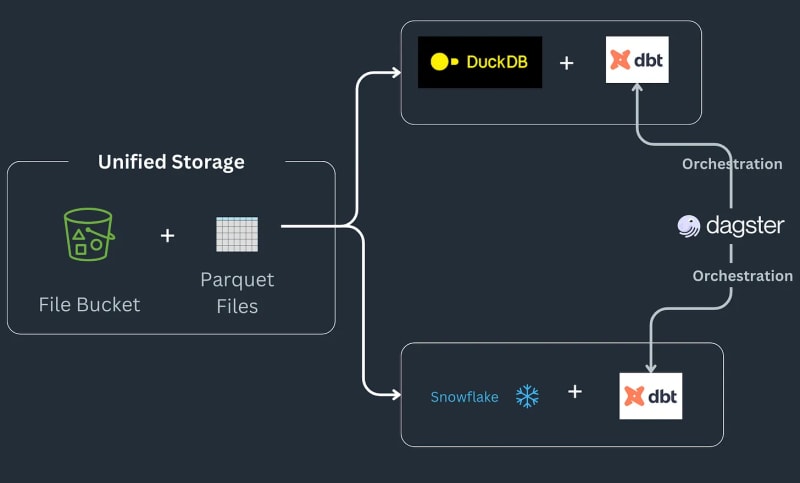
今日は、Julien Hurault のマルチ エンジン スタックの例 1 の完全な例を再現して、pandas コードを Ibis 式に変換する方法を詳しく説明します。 dbt モデルと SQL を使用する代わりに、ibis といくつかの Python を使用して、シェルから SQL エンジンをコンパイルおよび調整します。コードを Ibis 式として書き直すことで、遅延実行を使用してデータ パイプラインを宣言的に構築できます。さらに、Ibis は 20 を超えるバックエンドをサポートしているため、一度コードを記述して ibis.exprs を複数のバックエンドに移植できます。さらに単純化するために、Dagster によって提供されるスケジュールとタスクのオーケストレーション2 を読者に任せます。
マルチエンジン データ スタックの中心的な概念
ジュリアンのニュースレターで概要が説明されているマルチエンジン データ スタックの中心的な概念は次のとおりです。
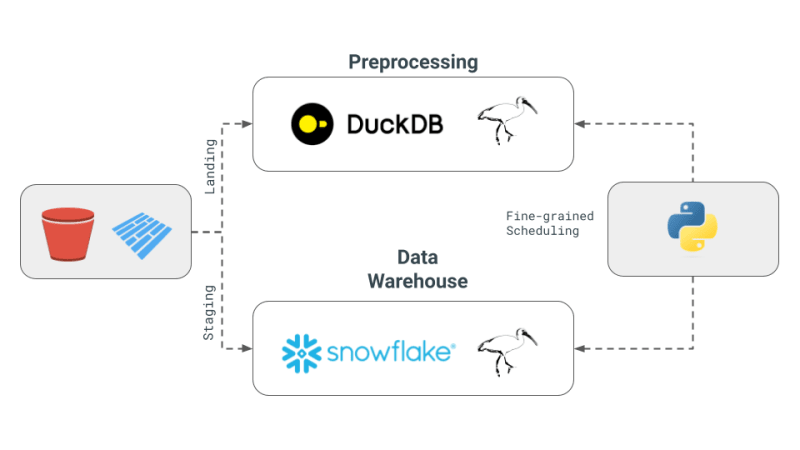
- マルチエンジン データ スタック: この概念には、Snowflake、Spark、DuckDB、BigQuery などのさまざまなデータ エンジンを組み合わせることが含まれます。このアプローチは、コストを削減し、ベンダーロックインを制限し、柔軟性を高めることを目的としています。 Julien 氏は、特定のベンチマーク クエリについては、DuckDB を使用すると、Snowflake と比較して大幅なコスト削減が達成できる可能性があると述べています。
- クロスエンジン クエリ レイヤーの開発: このニュースレターでは、データ チームが SQL またはデータフレーム コードをあるエンジンから別のエンジンにシームレスにトランスパイルできるようにするテクノロジーの進歩に焦点を当てています。この開発は、さまざまなエンジン間で効率を維持するために非常に重要です。
- Apache Iceberg と代替手段の使用: Apache Iceberg は潜在的な統合ストレージ層とみなされていますが、その統合はまだ dbt プロジェクトで使用できるほど成熟していません。代わりに、Julien は概念実証 (PoC) で、S3 に保存され、DuckDB と Snowflake の両方からアクセスされる Parquet ファイルを使用することを選択しました。
- PoC におけるオーケストレーションとエンジン: このプロジェクトでは、Julien はオーケストレーターとして Dagster を使用しました。これにより、dbt プロジェクト内のさまざまなエンジンのジョブ スケジューリングが簡素化されます。この PoC で組み合わせたエンジンは DuckDB と Snowflake でした。
DataFrame と Ibis を使用する理由
上記のパイプラインは ETL と ELT にとっては便利ですが、場合によっては、SQL のようなクエリ言語ではなく完全なプログラミング言語の力が必要になることがあります。デバッグ、テスト、複雑な UDF など。データ サイエンティストはコードを迅速に反復し、結果を視覚化し、データに基づいて意思決定を行う必要があるため、科学的調査にはインタラクティブ コンピューティングが不可欠です。
DataFrame はそのようなデータ構造です。DataFrame は、順序付けされたデータを処理し、対話形式でそのデータに計算操作を適用するために使用されます。 SQL スタイルの操作で大規模なデータを処理できる柔軟性を提供するだけでなく、Excel シートのセル レベルの変更を編集するための下位レベルの制御も提供します。 通常、すべてのデータはメモリ内で処理され、通常はメモリ内に収まることが期待されます。さらに、DataFrame を使用すると、遅延モード/バッチ モードと対話モードの間を簡単に行き来できます。
DataFrames は、ユーザー定義関数の適用を可能にする点で優れており、ユーザーを SQL の制限から解放します。つまり、コードを再利用したり、操作をテストしたり、複雑な操作のためにリレーショナル機構を簡単に拡張したりできるようになります。 DataFrame を使用すると、データの表形式の表現から、機械学習ライブラリで期待される配列やテンソルへの迅速な移行も簡単になります。
特殊なインプロセスデータベース(例: DuckDB for OLAP3 は、Snowflake のようなリモートの重量データベースと pandas のような人間工学に基づいたライブラリの間の境界を曖昧にしています。これは、ローカル Python シェルの対話性の期待と開発者の感覚を維持しながら、メモリより大きなデータを DataFrame で処理できるようになり、メモリより大きなデータを小さく感じる機会になると考えています。
技術的な詳細
私たちの実装は、前に示した 4 つの概念に焦点を当てています。
- マルチエンジン データ スタック: エンジンとして DuckDB、pandas、Snowflake を使用します。
- クロスエンジン クエリ レイヤー: Ibis を使用して式を作成し、DuckDB、pandas、および Snowflake で実行できるようにコンパイルします。
- Apache Iceberg と代替手段: s3fs パッケージを使用して S3 に拡張するのが簡単であることを期待して、ローカルに保存された Parquet ファイルをストレージ層として使用します。
- PoC におけるオーケストレーションとエンジン: エンジンのきめ細かいスケジューリングに焦点を当て、オーケストレーションは読者に任せます。きめ細かいスケジューリングは、オーケストレーション フレームワークと比較して、Ray、Dask、PySpark とより連携しています。ダグスター、エアフローなど
パンダで実装する

pandas は典型的な DataFrame ライブラリであり、おそらく上記のワークフローを実装する最も簡単な方法を提供します。まず、ニュースレターの実装から借用したランダム データを生成します。
#| echo: false
import pandas as pd
from multi_engine_stack_ibis.generator import generate_random_data
generate_random_data("landing/orders.parquet")
df = pd.read_parquet("landing/orders.parquet")
deduped = df.drop_duplicates(["order_id", "dt"])
パンダの実装はスタイル的に必須であり、データがメモリに収まるように設計されています。 pandas API は、さまざまなニュアンスを含む SQL にコンパイルするのが難しく、主に Python の視覚化、プロット、機械学習、AI、複雑な処理ライブラリをまとめた独自の特別な場所に置かれています。
pt.write_pandas(
conn,
deduped,
table_name="T_ORDERS",
auto_create_table=True,
quote_identifiers=False,
table_type="temporary"
)
パンダ演算子を使用して重複を排除した後、データを Snowflake に送信する準備が整いました。 Snowflake には、このユースケースに役立つ write_pandas というメソッドがあります。
Ibis (別名 Ibisify) を使用した実装
パンダの制限の 1 つは、パンダがリレーショナル代数に完全に対応していない独自の API を持っていることです。 Ibis は文字通り、複数の SQL バックエンドにマップバックできる健全な式システムを提供するために pandas を構築した人々によって構築されたライブラリです。 Ibis は dplyr R パッケージからインスピレーションを得て、リレーショナル代数に簡単にマッピングして SQL にコンパイルできる新しい式システムを構築します。また、スタイル的には宣言的であるため、完全な論理プランまたは式にデータベース スタイルの最適化を適用できます。 Ibis は、優れたコンポーザブル コーデックスで強調されているように、コンポーザビリティを実現するための重要なコンポーネントです。
#| echo: false
import pathlib
import ibis
import ibis.backends.pandas.executor
import ibis.expr.types.relations
from ibis import _
from multi_engine_stack_ibis.generator import generate_random_data
from multi_engine_stack_ibis.utils import (MyExecutor, checkpoint_parquet,
create_table_snowflake,
replace_unbound)
from multi_engine_stack_ibis.connections import make_ibis_snowflake_connection
ibis.backends.pandas.executor.PandasExecutor = MyExecutor
setattr(ibis.expr.types.relations.Table, "checkpoint_parquet", checkpoint_parquet)
setattr(
ibis.expr.types.relations.Table,
"create_table_snowflake",
create_table_snowflake,
)
ibis.set_backend("pandas")
p_staging = pathlib.Path("staging/staging.parquet")
p_landing = pathlib.Path("landing/orders.parquet")
snow_backend = make_ibis_snowflake_connection(database="MULTI_ENGINE", schema="PUBLIC", warehouse="COMPUTE_WH")
expr = (
ibis.read_parquet(p_landing)
.mutate(
row_number=ibis.row_number().over(group_by=[_.order_id], order_by=[_.dt]))
.filter(_.row_number == 0)
.checkpoint_parquet(p_staging)
.create_table_snowflake("T_ORDERS")
)
expr
Ibis 式は、データベース内の従来の論理プランに似たプランとしてそれ自体を出力します。論理プランは、実行する必要がある計算を記述する関係代数演算子のツリーです。次に、このプランはクエリ オプティマイザーによって最適化され、クエリ エグゼキューターによって実行される物理プランに変換されます。 Ibis 式は、実行する必要がある計算を記述するという点で論理プランに似ていますが、すぐには実行されません。代わりに、それらは SQL にコンパイルされ、必要に応じてバックエンドで実行されます。論理プランは通常、Dask などのタスク スケジューリング フレームワークによって生成される DAG よりも粒度が高くなります。理論的には、この計画は Dask の DAG にまとめられる可能性があります。
While pandas is embedded and is just a pip install away, it still has much documented limitations with plenty of performance improvements left on the table. This is where the recent embedded databases like DuckDB fill the gap of packing the full punch of a SQL engine, with all of its optimizations and benefiting from years of research that is as easy to import as is pandas. In this world, at minimum we can delegate all relational and SQL parts of our pipeline in pandas to DuckDB and only get the processed data ready for complex user defined Python.
Now, we are ready to take our Ibisified code and compile our expression above to execute on arbitrary engines, to truly realize the write-once-run-anywhere paradigm: We have successfully decoupled our compute engine with the expression system describing our computation.
Multi-Engine Data Stack w/ Ibis
DuckDB + pandas + Snowflake
Let's break our expression above into smaller parts and have them run across DuckDB, pandas and Snowflake. Note that we are not doing anything once the data lands in Snowflake and just show that we can select the data. Instead, we are leaving that up to the user's imagination what is possible with Snowflake native features.
Notice our expression above is bound to the pandas backend. First, lets create an UnboundTable expression to not have to depend on a backend when writing our expressions.

schema = {
"user_id": "int64",
"dt": "timestamp",
"order_id": "string",
"quantity": "int64",
"purchase_price": "float64",
"sku": "string",
"row_number": "int64",
}
first_expr_for = (
ibis.table(schema, name="orders")
.mutate(
row_number=ibis.row_number().over(group_by=[_.order_id], order_by=[_.dt])
)
.filter(_.row_number == 0)
)
first_expr_for
Next, we replace the UnboundTable expression with the DuckDB backend and execute it with to_parquet method4. This step is covered by the checkpoint_parquet operator that we added to pandas backend above. Here is an excellent blog that discusses inserting data into Snowflake from any Ibis backend with to_pyarrow functionality.
data = pd.read_parquet("landing/orders.parquet")
duck_backend = ibis.duckdb.connect()
duck_backend.con.execute("CREATE TABLE orders as SELECT * from data")
bind_to_duckdb = replace_unbound(first_expr_for, duck_backend)
bind_to_duckdb.to_parquet(p_staging)
to_sql = ibis.to_sql(bind_to_duckdb)
print(to_sql)
Once the above step creates the de-duplicated table, we can then send data to Snowflake using the pandas backend. This functionality is covered by create_table_snowflake operator that we added to pandas backend above.
second_expr_for = ibis.table(schema, name="T_ORDERS") # nothing special just a reading the data from orders table
snow_backend.create_table("T_ORDERS", schema=second_expr_for.schema(), temp=True)
pandas_backend = ibis.pandas.connect({"T_ORDERS": pd.read_parquet(p_staging)})
snow_backend.insert("T_ORDERS", pandas_backend.to_pyarrow(second_expr_for))
Finally, we can select the data from the Snowflake table to verify that the data has been loaded successfully.
third_expr_for = ibis.table(schema, name="T_ORDERS") # add you Snowflake ML functions here third_expr_for
We successfully broke up our computation in pieces, albeit manually, and executed them across DuckDB, pandas, and Snowflake. This demonstrates the flexibility and power of a multi-engine data stack, allowing users to leverage the strengths of different engines to optimize their data processing pipelines.
Acknowledgments
I'd like to thank Neal Richardson, Dan Lovell and Daniel Mesejo for providing the initial feedback on the post. I highly appreciate the early review and encouragement by Wes McKinney.
Resources
- The Road to Composable Data Systems
- The Composable Codex
- Apache Arrow
- Multi-Engine Data Stack Newsleter v0 v1
- Ibis, the portable dataframe library
- dbt Docs
- Dagster Docs
- LanceDB
- KuzuDB
- DuckDB
-
In this post, we have primarily focused on v0 of the multi-engine data stack. In the latest version, Apache Iceberg is included as a storage and data format layer. NYC Taxi data is used instead of the random Orders data treated in this and v0 of the posts. ↩
-
Orchestration Vs fine-grained scheduling: ↩
- The orchestration is left to the reader. The orchestration can be done using a tool like Dagster, Prefect, or Apache Airflow.
- The fine-grained scheduling can be done using a tool like Dask, Ray, or Spark.
-
Some of the examples of in-process databases is described in this post extending DuckDB example above to newer purpose built databases like LanceDB and KuzuDB. ↩
-
The Ibis docs use backend.to_pandas(expr) commands to bind and run the expression in the same go. Instead, we use replace_unbound method to show a generic way to just compile the expression and not execute it to said backend. This is just for illustration purposes. All the code below, uses the backend.to_pyarrow methods from here on. ↩
以上がIbis を使用した宣言型マルチエンジン データ スタックの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。