
ホームページ >テクノロジー周辺機器 >AI >300 以上の関連研究、復丹大学と南洋理工大学による最新のマルチモーダル画像編集レビュー論文
300 以上の関連研究、復丹大学と南洋理工大学による最新のマルチモーダル画像編集レビュー論文

- PHPzオリジナル
- 2024-06-29 06:14:41596ブラウズ

AIxivコラムは、本サイト上で学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出電子メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
この記事の筆頭著者Shuai Xinchengは現在、復旦大学のFVL研究室で博士号取得を目指して勉強しており、上海交通大学を卒業しました。学士号。彼の主な研究対象は、画像とビデオの編集とマルチモーダル学習です。

論文タイトル: テキストから画像への拡散モデルによるマルチモーダルガイド付き画像編集の調査 出版単位: 復旦大学 FVL 研究室、南洋理工大学 論文アドレス: https://arxiv 。 org/abs/2406.14555 プロジェクトアドレス: https://github.com/xinchengshuai/Awesome-Image-Editing

2.3 議論の包括性。私たちは 300 以上の関連論文を調査し、さまざまなシナリオにおけるさまざまなモードの制御信号の応用を体系的かつ包括的に説明しました。トレーニング ベースの編集方法については、この記事ではさまざまなシナリオで T2I モデルにソース イメージを挿入するための戦略も提供します。さらに、ビデオ分野における画像編集技術の応用についても説明し、読者がさまざまな分野の編集アルゴリズム間のつながりをすぐに理解できるようにしました。
と編集アルゴリズム

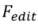
は、ソース画像セット
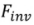 をソース画像の識別子として使用します。チューニングベース
をソース画像の識別子として使用します。チューニングベース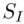 とフォワードベース
とフォワードベース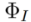 の2種類の反転アルゴリズムが含まれています。これは次のように形式化できます:
の2種類の反転アルゴリズムが含まれています。これは次のように形式化できます: 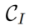
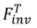
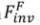 チューニングベースの反転
チューニングベースの反転

ここで、 は導入された学習可能なパラメーター、および
は導入された学習可能なパラメーター、および
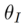
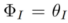
は、拡散モデルの逆プロセス(
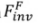
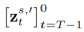
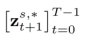
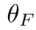 はメソッドに導入されたパラメータであり、
はメソッドに導入されたパラメータであり、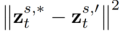 を最小化するために使用されます。
を最小化するために使用されます。 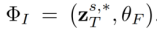
 とマルチモーダル ガイダンス セット
とマルチモーダル ガイダンス セット 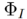 に基づいて、最終的な編集結果
に基づいて、最終的な編集結果 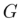 を生成します。アテンションベース
を生成します。アテンションベース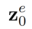 、ブレンディングベース
、ブレンディングベース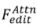 、スコアベース
、スコアベース 、最適化ベース
、最適化ベース を含む編集アルゴリズム。これは次のように形式化できます:
を含む編集アルゴリズム。これは次のように形式化できます: 

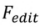

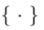 は、編集された画像
は、編集された画像  とソース画像コレクション
とソース画像コレクション  の間の一貫性を確保し、
の間の一貫性を確保し、 のガイダンス条件によって指定された視覚的な変換を反映するために使用されます。
のガイダンス条件によって指定された視覚的な変換を反映するために使用されます。 


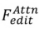 : ブレンドベース編集の形式的プロセス
: ブレンドベース編集の形式的プロセス

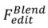 スコアベース編集の形式的プロセス
スコアベース編集の形式的プロセス
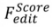 最適化ベースの編集
最適化ベースの編集
 3.3 トレーニングベースの編集方法。トレーニング不要の方法とは異なり、トレーニングベースのアルゴリズムは、ソース画像セットとタスク固有のデータセット内の編集画像のマッピングを直接学習します。このタイプのアルゴリズムは、追加の導入パラメーターを通じてソース イメージを生成分布にエンコードする、チューニング ベースの反転の拡張として見ることができます。このタイプのアルゴリズムで最も重要なことは、ソース画像を T2I モデルに挿入する方法です。以下に、さまざまな編集シナリオの挿入スキームを示します。
3.3 トレーニングベースの編集方法。トレーニング不要の方法とは異なり、トレーニングベースのアルゴリズムは、ソース画像セットとタスク固有のデータセット内の編集画像のマッピングを直接学習します。このタイプのアルゴリズムは、追加の導入パラメーターを通じてソース イメージを生成分布にエンコードする、チューニング ベースの反転の拡張として見ることができます。このタイプのアルゴリズムで最も重要なことは、ソース画像を T2I モデルに挿入する方法です。以下に、さまざまな編集シナリオの挿入スキームを示します。 



 5.テキストガイド付き編集シナリオにおけるさまざまな組み合わせの比較
5.テキストガイド付き編集シナリオにおけるさまざまな組み合わせの比較
 コンテンツを意識したタスクでは、主にオブジェクトの操作 (追加/削除/置換)、属性の変更、スタイルの移行を考慮します。特に、次のような挑戦的な実験設定を検討します。 1. 多目的編集。 2. 画像の意味論的なレイアウトに大きな影響を与えるユースケース。また、これらの複雑なシーンの高品質画像を収集し、さまざまな組み合わせで最先端のアルゴリズムを包括的に定量的に比較します。図 8. Content-AWARE ミッションの各組み合わせの定性的比較 左から右に、分析結果とその他の実験結果を示します。元の論文を参照してください。
コンテンツを意識したタスクでは、主にオブジェクトの操作 (追加/削除/置換)、属性の変更、スタイルの移行を考慮します。特に、次のような挑戦的な実験設定を検討します。 1. 多目的編集。 2. 画像の意味論的なレイアウトに大きな影響を与えるユースケース。また、これらの複雑なシーンの高品質画像を収集し、さまざまな組み合わせで最先端のアルゴリズムを包括的に定量的に比較します。図 8. Content-AWARE ミッションの各組み合わせの定性的比較 左から右に、分析結果とその他の実験結果を示します。元の論文を参照してください。 コンテンツのないタスクについては、主に主題主導のカスタマイズされたタスクを考慮します。また、背景の変更、オブジェクトとの対話、動作の変更、スタイルの変更など、さまざまなシナリオを考慮します。また、多数のテキスト ガイダンス テンプレートを定義し、各メソッドの全体的なパフォーマンスの定量的分析を実施しました。
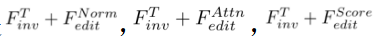
6.2.コンテンツフリーのタスクチャレンジ。コンテンツのない編集タスクの場合、既存の方法ではテスト中に調整プロセスに時間がかかり、オーバーフィッティングの問題が発生します。一部の研究では、少数のパラメーターを最適化したり、モデルをゼロからトレーニングしたりすることで、この問題を軽減することを目指しています。ただし、主題を個別化する詳細が失われたり、一般化能力が不十分であることがよくあります。さらに、現在の方法は、少数の画像から抽象的な概念を抽出するという点でも不十分であり、目的の概念を他の視覚要素から完全に分離することはできません。
研究の方向性について詳しく知りたい場合は、元の論文を確認してください。
以上が300 以上の関連研究、復丹大学と南洋理工大学による最新のマルチモーダル画像編集レビュー論文の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
声明:
この記事の内容はネチズンが自主的に寄稿したものであり、著作権は原著者に帰属します。このサイトは、それに相当する法的責任を負いません。盗作または侵害の疑いのあるコンテンツを見つけた場合は、admin@php.cn までご連絡ください。