


**4M** や **UnifiedIO** などの現在のマルチモーダルおよびマルチタスクの基本モデルは、有望な結果を示しています。ただし、さまざまな入力を受け入れ、さまざまなタスクを実行するすぐに使用できる能力は、トレーニング対象のモダリティとタスクの (通常は少数の) 数によって制限されます。
、これに基づいて、ローザンヌ工科大学 (EPFL) の研究者と Apple は共同で、数十の**幅広く**多様性のある**高度な** Any-to-Anyモーダル単一モデルを開発しました。さまざまなモダリティを利用し、大規模なマルチモーダル データセットとテキスト コーパスに対して共同トレーニングを実行します。
トレーニング プロセスの重要なステップは、画像のようなニューラル ネットワーク **特徴マップ**、ベクトル、インスタンス セグメンテーション、人間のポーズなどの構造化データであるかどうかにかかわらず、さまざまなモダリティに対して離散 **トークン化**を実行することです。テキストとして表現できるデータ。

論文アドレス: https://arxiv.org/pdf/2406.09406
論文ホームページ https://4m.epfl.ch/
論文タイトル: 4M-21: An Any数十のタスクとモダリティに対する任意のビジョン モデル
この研究は、単一モデルのトレーニングでも、既存のモデルの少なくとも**3倍**のタスク/**モダリティ**を完了できることを示しています。パフォーマンスが失われます。さらに、この研究では、よりきめ細かく、より制御可能なマルチモード データ生成機能も実現します。
この研究は、マルチモーダル マスクの事前トレーニング スキームに基づいて構築されており、数十の非常に多様なモダリティでトレーニングすることでモデルの機能を向上させます。この研究では、モダリティ固有の離散トークナイザーを使用してエンコードすることにより、異なるモダリティで単一の統合モデルをトレーニングできるようになります。
簡単に言うと、この研究はいくつかの主要な次元で既存のモデルの機能を拡張します:
モダリティ: 既存の最良の任意対任意モデルの 7 つのモダリティから 21 の異なるモダリティまで、クロスモーダル検索と制御可能な生成を可能にします。 、そしてすぐに使える強力なパフォーマンス。これは、パフォーマンスを損なうことなく、また従来のマルチタスク学習を行わずに、シングル ビジョン モデルが数十の異なるタスクを Any-to-Any 方式で解決できる初めてのことです。
多様性: 人間のポーズ、SAM インスタンス、メタデータなど、より構造化されたデータのサポートを追加します。
トークン化: グローバル画像埋め込み、人間のポーズ、セマンティック インスタンスなどのモダリティ固有の方法を使用して、さまざまなモダリティの個別のトークン化を研究します。
拡張: モデルサイズを 3B パラメーターに拡張し、データセットを 0.5B サンプルに拡張します。
共同トレーニング: 視覚と言語を同時に共同トレーニングします。
方法の紹介
この研究では、4M 事前トレーニング スキームを使用しています (この研究は EPFL と Apple からも提供され、昨年リリースされました)。これは、複数のユーザーに効果的に拡張できる一般的な方法であることが証明されています。 -モダリティ。
具体的には、この記事では、モデルとデータセットのサイズを拡大し、モデルのトレーニングに関与するモダリティの種類と数を増やし、複数のデータセットを共同でトレーニングすることで、アーキテクチャとマルチモーダルマスクトレーニングの目標を変更しません。モデルのパフォーマンスと適応性を向上させます。
モダリティは、以下の図に示すように、RGB、ジオメトリ、セマンティクス、エッジ、特徴マップ、メタデータ、テキストのカテゴリに分類されます。
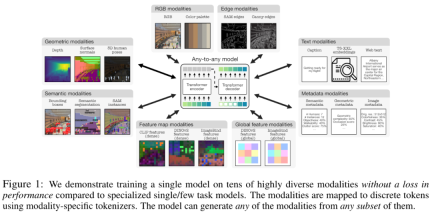
トークン化
トークン化には主に、さまざまなモダリティやタスクをシーケンスまたは離散トークンに変換し、それによってそれらの表現空間を統一することが含まれます。図 3 に示すように、研究者はさまざまなトークン化方法を使用して、さまざまな特性を持つモードを離散化します。要約すると、この記事では、ViT トークナイザー、MLP トークナイザー、テキスト トークナイザーを含む 3 つのトークナイザーを使用します。
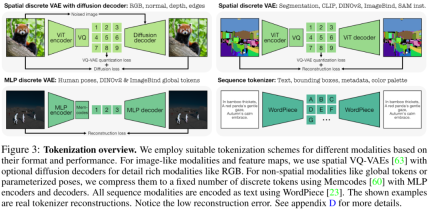
アーキテクチャの選択に関して、この記事では Transformer に基づく 4M エンコーダ/デコーダ アーキテクチャを採用し、新しいモダリティに適応するために追加のモーダル エンベディングを追加します。
実験結果
次に、論文は 4M-21 のマルチモーダル機能を実証します。
マルチモーダル生成
反復復号トークンに基づいて、4M-21 を使用してあらゆるトレーニング モダリティを予測できます。図 2 に示すように、この論文では、特定の入力モダリティから一貫した方法ですべてのモダリティを生成できます。 
さらに、この研究では、他のモダリティのサブセットから任意のトレーニング モダリティを条件付きおよび無条件で生成できるため、図 4 に示すように、きめの細かいマルチモーダル生成を実行するためのいくつかの方法がサポートされています。たとえば、マルチモーダル編集を実行します。 。さらに、4M-21 は、T5-XXL 埋め込みと通常の字幕の両方でテキスト理解の向上を示し、幾何学的および意味論的に音声生成を可能にします (図 4、右上)。

マルチモーダル取得
図 5 に示すように、4M-21 は、他のモダリティをクエリとして使用して RGB 画像や他のモダリティを取得するなど、元の DINOv2 および ImageBind モデルでは不可能な取得機能を解放します。 。さらに、4M-21 は、右の画像に示すように、複数のモダリティを組み合わせてグローバル エンベディングを予測し、取得の制御を向上させることができます。

すぐに使える
4M-21 は、図 6 に示すように、箱から出してすぐにさまざまな一般的な視覚タスクを実行できます。
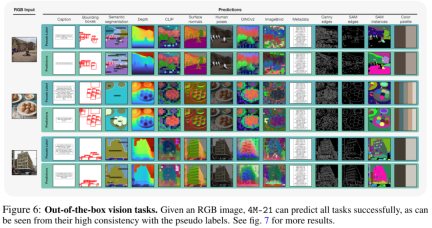
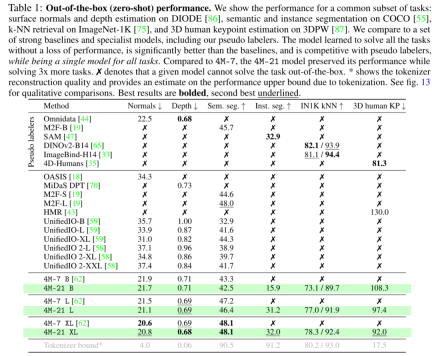
表 1 は、DIODE 表面法線と深さの推定、COCO セマンティックとインスタンスのセグメンテーション、3DPW 3D 人間の姿勢推定などを評価します。
転移実験
さらに、この記事では、B、L、XL の 3 つの異なるサイズのモデルもトレーニングしました。その後、エンコーダーはダウンストリーム タスクに転送され、シングル モダリティ (RGB) およびマルチ モダリティ (RGB + 深度) 設定で評価されます。すべての転送実験ではデコーダが破棄され、代わりにタスク固有のヘッドがトレーニングされます。結果を表 2 に示します。
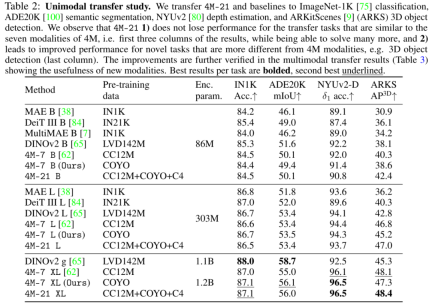
最後に、この論文では、NYUv2 でマルチモーダル転送、Hypersim セマンティック セグメンテーション、ARKitScenes で 3D オブジェクト検出を実行します。表 3 に示すように、4M-21 はオプションの深度入力を最大限に活用し、ベースラインを大幅に改善します。

以上が完成度高すぎ! Apple、21のモードが可能な新しいビジュアルモデル4M-21を発売の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 ほとんどが使用されています10 Power BIチャート - 分析VidhyaApr 16, 2025 pm 12:05 PM
ほとんどが使用されています10 Power BIチャート - 分析VidhyaApr 16, 2025 pm 12:05 PMMicrosoft PowerBIチャートでデータ視覚化の力を活用する 今日のデータ駆動型の世界では、複雑な情報を非技術的な視聴者に効果的に伝えることが重要です。 データの視覚化は、このギャップを橋渡しし、生データを変換するi
 AIのエキスパートシステムApr 16, 2025 pm 12:00 PM
AIのエキスパートシステムApr 16, 2025 pm 12:00 PMエキスパートシステム:AIの意思決定力に深く飛び込みます 医療診断から財務計画まで、あらゆることに関する専門家のアドバイスにアクセスできることを想像してください。 それが人工知能の専門家システムの力です。 これらのシステムはプロを模倣します
 3人の最高の雰囲気コーダーがこのAI革命をコードで分解するApr 16, 2025 am 11:58 AM
3人の最高の雰囲気コーダーがこのAI革命をコードで分解するApr 16, 2025 am 11:58 AMまず第一に、これがすぐに起こっていることは明らかです。さまざまな企業が、現在AIによって書かれているコードの割合について話しており、これらは迅速なクリップで増加しています。すでに多くの仕事の移動があります
 滑走路AIのGen-4:AIモンタージュはどのように不条理を超えることができますかApr 16, 2025 am 11:45 AM
滑走路AIのGen-4:AIモンタージュはどのように不条理を超えることができますかApr 16, 2025 am 11:45 AM映画業界は、デジタルマーケティングからソーシャルメディアまで、すべてのクリエイティブセクターとともに、技術的な岐路に立っています。人工知能が視覚的なストーリーテリングのあらゆる側面を再構築し始め、エンターテイメントの風景を変え始めたとき
 5日間のISRO AI無料コースを登録する方法は? - 分析VidhyaApr 16, 2025 am 11:43 AM
5日間のISRO AI無料コースを登録する方法は? - 分析VidhyaApr 16, 2025 am 11:43 AMISROの無料AI/MLオンラインコース:地理空間技術の革新へのゲートウェイ インド宇宙研究機関(ISRO)は、インドのリモートセンシング研究所(IIRS)を通じて、学生と専門家に素晴らしい機会を提供しています。
 AIのローカル検索アルゴリズムApr 16, 2025 am 11:40 AM
AIのローカル検索アルゴリズムApr 16, 2025 am 11:40 AMローカル検索アルゴリズム:包括的なガイド 大規模なイベントを計画するには、効率的なワークロード分布が必要です。 従来のアプローチが失敗すると、ローカル検索アルゴリズムは強力なソリューションを提供します。 この記事では、Hill ClimbingとSimulについて説明します
 OpenaiはGPT-4.1でフォーカスをシフトし、コーディングとコスト効率を優先しますApr 16, 2025 am 11:37 AM
OpenaiはGPT-4.1でフォーカスをシフトし、コーディングとコスト効率を優先しますApr 16, 2025 am 11:37 AMこのリリースには、GPT-4.1、GPT-4.1 MINI、およびGPT-4.1 NANOの3つの異なるモデルが含まれており、大規模な言語モデルのランドスケープ内のタスク固有の最適化への動きを示しています。これらのモデルは、ようなユーザー向けインターフェイスをすぐに置き換えません
 プロンプト:ChatGptは偽のパスポートを生成しますApr 16, 2025 am 11:35 AM
プロンプト:ChatGptは偽のパスポートを生成しますApr 16, 2025 am 11:35 AMChip Giant Nvidiaは、月曜日に、AI Supercomputersの製造を開始すると述べました。これは、大量のデータを処理して複雑なアルゴリズムを実行できるマシンを初めて初めて米国内で実行します。発表は、トランプSI大統領の後に行われます


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

Dreamweaver Mac版
ビジュアル Web 開発ツール

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

