
ホームページ >テクノロジー周辺機器 >AI >オリンピックで最も賢い AI を選択する: Claude-3.5-Sonnet 対 GPT-4o?
オリンピックで最も賢い AI を選択する: Claude-3.5-Sonnet 対 GPT-4o?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBオリジナル
- 2024-06-24 17:01:061276ブラウズ

AIxivコラムは、本サイト上で学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
オリンピック科目競技会は、人間(炭素ベースの知能)の思考の敏捷性、知識の習得、論理的推論に対する極限の挑戦であるだけでなく、AI(「シリコンベースの知能」)の優れた訓練の場でもあります。 AIと「超知能」の距離を測る重要な尺度。 OlympicArena - 真の AI オリンピック アリーナ。ここで、AI は従来の主題知識 (数学、物理学、生物学、化学、地理学などのトップコンテスト) でその深さを実証するだけでなく、モデル間の認知的推論能力でも競争する必要があります。
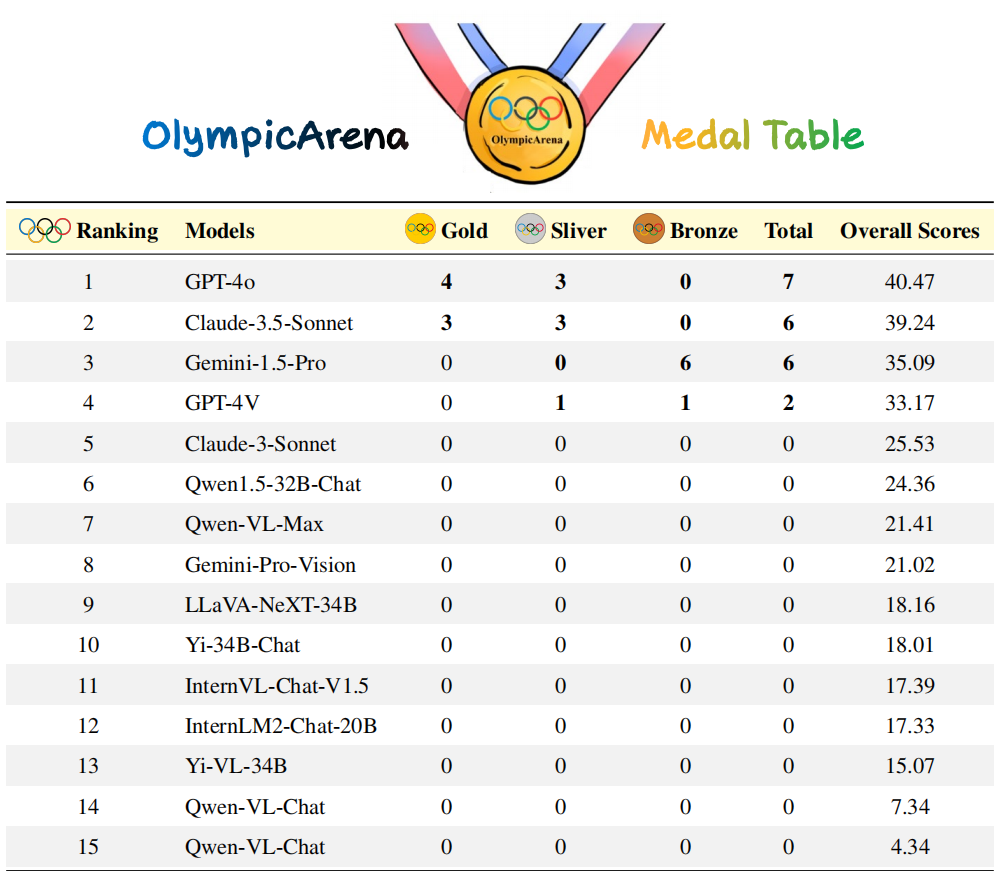
- オープンソース コミュニティの AI モデルのパフォーマンスは、これらの独自モデルに比べて明らかに遅れています。
- このベンチマークにおけるこれらのモデルのパフォーマンスが満足のいくものではないことは、超知性への道にはまだ長い道のりがあることを示しています。
-
プロジェクトのホームページ: https://gair-nlp.github.io/OlympicArena/
実験設定 研究チームは、OlympicArenaのテストセットを評価のために使用しました。このテスト セットの回答は、データ漏洩を防止し、モデルの真のパフォーマンスを反映するために公開されていません。研究チームは、マルチモーダル大規模モデル (LMM) とテキストのみの大規模モデル (LLM) をテストしました。 LLM のテストでは、画像関連情報は入力としてモデルに提供されず、テキストのみが提供されます。すべての評価では、ゼロショットの思考連鎖プロンプト ワードが使用されます。 評価対象 研究チームは、一連のオープンソースおよびクローズドソースのマルチモーダル大規模モデル (LMM) とテキストのみの大規模モデル (LLM) を評価しました。 LMM としては、GPT-4o、GPT-4V、Claude-3-Sonnet、Gemini Pro Vision、Qwen-VL-Max などのクローズドソース モデルに加え、LLaVA-NeXT-34B、InternVL-Chat が選択されました。 -V1.5、Yi-VL-34B、Qwen-VL-Chat、その他のオープンソース モデルも評価されました。 LLM については、Qwen-7B-Chat、Qwen1.5-32B-Chat、Yi-34B-Chat、InternLM2-Chat-20B などのオープンソース モデルが主に評価されました。 さらに、研究チームは、新しくリリースされたClaude-3.5-SonnetとGemini-1.5-Proを具体的に含めて、強力なGPT-4oおよびGPT-4Vと比較しました。最新モデルの性能を反映。 評価方法 メトリクス すべての問題がルールベースのマッチングによって評価できることを考慮して、研究チームは非プログラミングタスクには精度を、プログラミングタスクには不偏の pass@k メトリクスを使用しました。 
この評価では、k = 1、n = 5 に設定され、c はすべてのテスト ケースを通過する正しいサンプルの数を表します。 オリンピックアリーナメダルリスト: オリンピック競技大会で使用されるメダルシステムと同様に、さまざまな学術分野におけるAIモデルのパフォーマンスを評価するために特別に設計された先駆的なランキングメカニズムです。この表は、特定の分野で上位 3 位の結果を達成したモデルにメダルを授与するもので、さまざまなモデルを比較するための明確で競争力のある枠組みを提供します。研究チームはまず、金メダルの数に基づいてモデルを並べ替えました。金メダルの数が同じ場合は、全体のパフォーマンス スコアに基づいて並べ替えました。これは、さまざまな学術分野の主要なモデルを識別するための直感的かつ簡潔な方法を提供し、研究者や開発者がさまざまなモデルの長所と短所を理解しやすくなります。 きめの細かい評価: 研究チームは、さまざまな分野、さまざまなモダリティ、さまざまな言語、さまざまなタイプの論理的および視覚的推論能力に基づいて、精度に基づいたきめの細かい評価も実施しています。 結果と分析 分析内容は主にClaude-3.5-SonnetとGPT-4oに焦点を当てており、Gemini-1.5-Proの性能についても部分的に議論しています。 全体的な状況
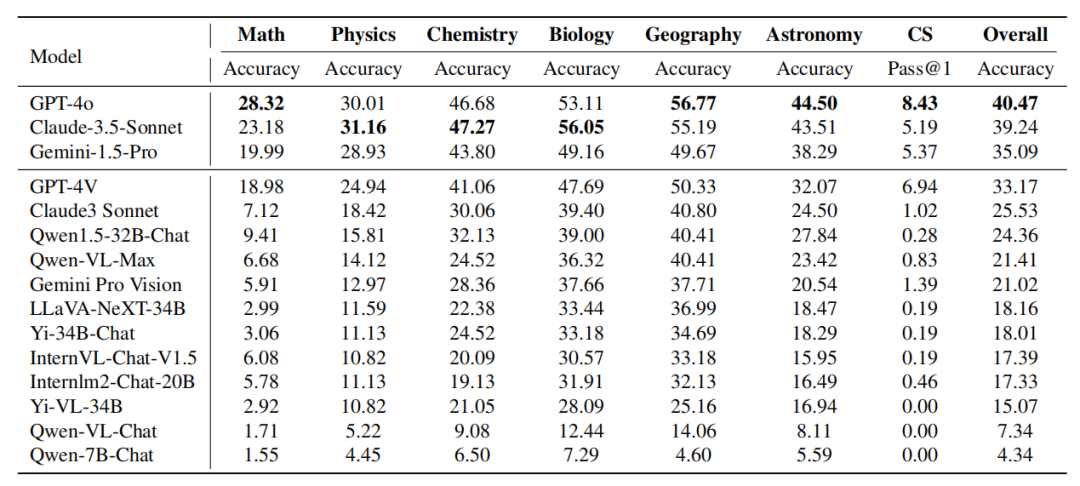
表: さまざまな主題におけるモデルのパフォーマンス Claude-3.5-Sonnet のパフォーマンスは強力で、GPT-4o とほぼ同等に達します。両者の全体的な精度の差はわずか約 1% です。新しくリリースされた Gemini-1.5-Pro もかなりの強さを示しており、ほとんどの分野で GPT-4V (OpenAI の現在 2 番目に強力なモデル) を上回っています。
この分野の急速な発展を反映して、この記事の執筆時点では、これら 3 つのモデルのうち最初のものはちょうど 1 か月前にリリースされたことは注目に値します。- 分野の詳細な分析
- GPT-4o vs. Claude-3.5-Sonnet:
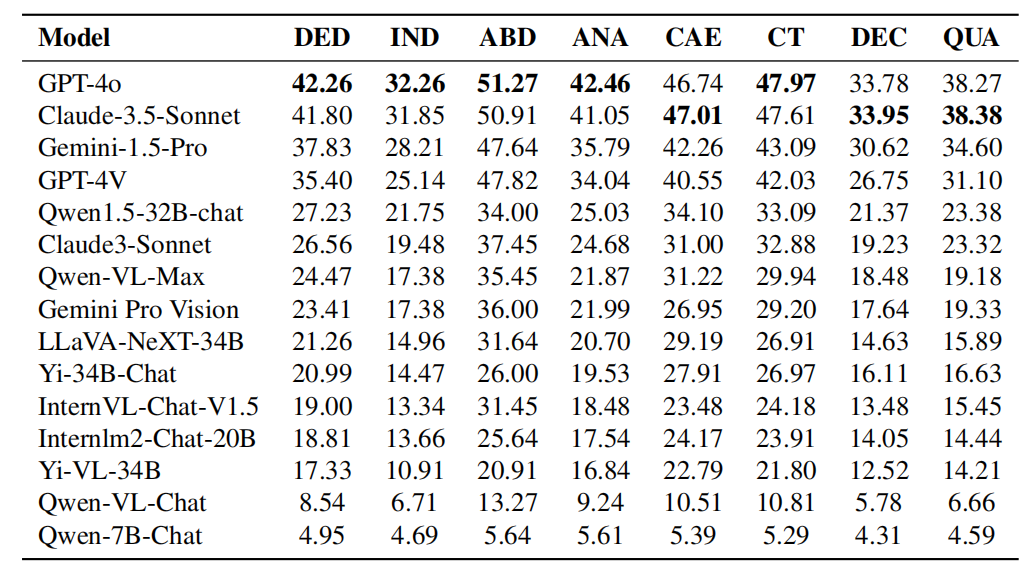
GPT-4o と Claude- 3. 5-ソネット全体としてパフォーマンスは似ていますが、両方のモデルは異なる主題の利点を示します。 GPT-4o は、特に数学とコンピューター サイエンスにおける従来の演繹的および帰納的推論タスクにおいて優れた能力を実証します。 Claude-3.5-Sonnet は、物理学、化学、生物学などの科目で優れたパフォーマンスを発揮し、特に生物学では GPT-4o を 3% 上回っています。 GPT-4V 対 Gemini-1.5-Pro: 同様の現象が Gemini-1.5-Pro と Gemini-1.5-Pro の比較でも観察できます。 Gemini-1.5-Pro は、物理学、化学、生物学において GPT-4V を大幅に上回ります。ただし、数学とコンピューター サイエンスの観点から見ると、Gemini-1.5-Pro の利点は明らかではなく、GPT-4V に劣ることさえあります。 これら 2 つの比較から、次のことがわかります: OpenAI の GPT シリーズは、従来の数学的推論とプログラミング機能において優れたパフォーマンスを発揮します。これは、GPT シリーズ モデルが、多くの演繹的推論とアルゴリズム的思考を必要とするタスクを処理するために厳密にトレーニングされていることを示しています。 推論タイプの詳細な分析 - キャプション: 論理推論機能における各モデルのパフォーマンス。論理的推論能力には、演繹的推論(DED)、帰納的推論(IND)、アブダクティブ推論(ABD)、類推的推論(ANA)、因果的推論(CAE)、批判的思考(CT)、分解推論(DEC)および定量的推論(クア)。
論理的推論能力に関する GPT-4o と Claude-3.5-Sonnet の比較:
表の実験結果からわかるように、GPT-4o は優れたパフォーマンスを持っています。ほとんどの論理的推論能力において、演繹的推論、帰納的推論、アブダクティブ推論、類推的推論、批判的思考などの分野においてクロード-3.5-ソネットよりも優れています。ただし、Claude-3.5-Sonnet は、因果推論、分解推論、定量推論において GPT-4o よりも優れています。全体として、両方のモデルのパフォーマンスは同等ですが、ほとんどのカテゴリで GPT-4o がわずかに優れています。表: 視覚的推論機能における各モデルのパフォーマンス。視覚的推論能力には、パターン認識 (PR)、空間的推論 (SPA)、図的推論 (DIA)、記号解釈 (SYB)、および視覚的比較 (COM) が含まれます。 GPT-4o vs. Claude-3.5-Sonnet 視覚的推論能力のパフォーマンス: 表の実験結果から分かるように、Claude-3.5-Sonnet は視覚的推論能力において優れています。パターン認識と図の推論をリードし、パターン認識と図の解釈における競争力を実証します。 2 つのモデルはシンボル解釈に関して同等のパフォーマンスを示し、シンボル情報の理解と処理において同等の能力があることを示しています。ただし、GPT-4o は、空間推論と視覚比較においては Claude-3.5-Sonnet よりも優れており、空間関係の理解と視覚データの比較が必要なタスクにおいてその優位性を示しています。 研究チームは、専門分野と推論タイプの包括的な分析により、次のことを発見しました: 数学とコンピュータープログラミングは、複雑な演繹的推論スキルとルールに基づいた普遍的な結論の導出を重視しており、依存度が低い傾向にあります。既存の知識。対照的に、化学や生物学などの分野では、因果関係や現象に関する既知の情報に基づいて推論するために大規模な知識ベースが必要になることがよくあります。これは、数学的能力とプログラミング能力が依然としてモデルの推論能力を示す有効な指標である一方で、内部知識に基づいてモデルの推論能力と問題分析能力をテストする方が他の分野の方が適切であることを示唆しています。 さまざまな分野の特性は、カスタマイズされたトレーニング データセットの重要性を示しています。たとえば、化学や生物学などの知識集約的な主題におけるモデルのパフォーマンスを向上させるには、モデルはトレーニング中にドメイン固有のデータに広範囲にさらされる必要があります。対照的に、数学やコンピューター サイエンスなど、強力な論理と演繹的推論を必要とする科目の場合、モデルは純粋に論理的推論に焦点を当てたトレーニングから恩恵を受けることができます。 さらに、推論能力と知識応用の区別は、このモデルが分野を超えて応用できる可能性があることを示しています。たとえば、強力な演繹推論機能を備えたモデルは、科学研究など、問題を解決するために体系的な思考が必要な分野を支援できます。また、知識が豊富なモデルは、医学や環境科学など、既存の情報に大きく依存する分野では貴重です。これらのニュアンスを理解することは、より専門的で汎用性の高いモデルを開発するのに役立ちます。
言語タイプの詳細な分析 キャプション: さまざまな言語問題における各モデルのパフォーマンス。 上の表は、さまざまな言語でのモデルのパフォーマンスを示しています。研究チームは、ほとんどのモデルは中国語よりも英語の方が正確であり、この差はトップランクのモデルで特に顕著であることを発見しました。いくつかの理由が考えられます: これらのモデルには大量の中国語のトレーニング データが含まれており、言語間の汎化機能がありますが、そのトレーニング データは主に英語ベースです。 中国語の問題は英語の問題よりも難しく、特に物理学や化学などの科目では、中国語オリンピックの問題の方が難しいです。 これらのモデルは、マルチモーダル画像内の文字を識別するには不十分であり、この問題は中国語環境ではさらに深刻です。
ただし、研究チームは、中国のメーカーが開発したモデルや、中国語をサポートする基本モデルに基づいて微調整された一部のモデルは、Qwen1.5-32B など、英語のシナリオよりも中国語のシナリオの方がパフォーマンスが高いことも発見しました。チャット、Qwen -VL-Max、Yi-34B-Chat、Qwen-7B-Chat など。 InternLM2-Chat-20B や Yi-VL-34B などの他のモデルは、依然として英語でのパフォーマンスが優れていますが、トップランクの多くのクローズド ソース モデルよりも英語と中国語のシーン間の精度の差がはるかに小さいです。これは、中国語データ、さらに世界中のさらに多くの言語のモデルの最適化には依然として大きな注意が必要であることを示しています。 モダリティのきめ細かい分析 解決すべきさまざまなモーダル問題を解決する。 上の表は、さまざまなモダリティでのモデルのパフォーマンスを示しています。 GPT-4o は、プレーン テキストとマルチモーダル タスクの両方で Claude-3.5-Sonnet よりも優れたパフォーマンスを発揮し、プレーン テキストではより顕著にパフォーマンスを発揮します。一方、Gemini-1.5-Pro は、プレーン テキスト タスクとマルチモーダル タスクの両方で GPT-4V よりも優れたパフォーマンスを発揮します。これらの観察結果は、現在利用可能な最も強力なモデルであっても、マルチモーダル タスクよりもテキストのみのタスクの方が精度が高いことを示しています。これは、複雑な推論問題を解決するためにマルチモーダル情報を利用する際に、このモデルにはまだ改善の余地がかなりあることを示しています。 結論 このレビューでは、研究チームは主に最新モデルであるClaude-3.5-SonnetおよびGemini-1.5-Proに焦点を当て、それらをOpenAIのGPT-4oおよびGPT-と比較しました。比較のため4V。さらに、研究チームは、さまざまなモデルの能力を明確に比較するために、大型モデル向けの新しいランキング システムであるOlympicArenaメダルテーブルも設計しました。研究チームは、GPT-4oが数学やコンピューターサイエンスなどの科目に優れており、強力な複雑な演繹推論能力と、ルールに基づいて一般的な結論を導き出す能力を備えていることを発見した。一方、クロード-3.5-ソネットは、確立された因果関係や現象から推論するのが得意です。さらに、研究チームは、これらのモデルが英語の問題でより優れたパフォーマンスを示し、マルチモーダル機能に大きな改善の余地があることも観察しました。モデルのこうしたニュアンスを理解することは、さまざまな学術分野や専門分野の多様なニーズに適切に対応する、より特化したモデルを開発するのに役立ちます。 4年に一度のオリンピックイベントが近づくにつれ、人工知能も参加できたら、知恵とテクノロジーの頂上決戦がどのようなものになるかを想像せずにはいられません。これはもはや単なる物理的な競技ではありません。AI の追加により、間違いなく知性の限界への新たな探求が開かれることになります。また、より多くの AI プレーヤーがこの知的オリンピックに参加することを楽しみにしています。 参考链接: [1] Huang et al.、OlympicArena: 超知能 AI の多分野認知推論のベンチマーク https://arxiv.org/abs/2406.12753v1
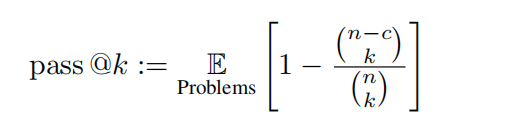
 キャプション: さまざまな言語問題における各モデルのパフォーマンス。
キャプション: さまざまな言語問題における各モデルのパフォーマンス。 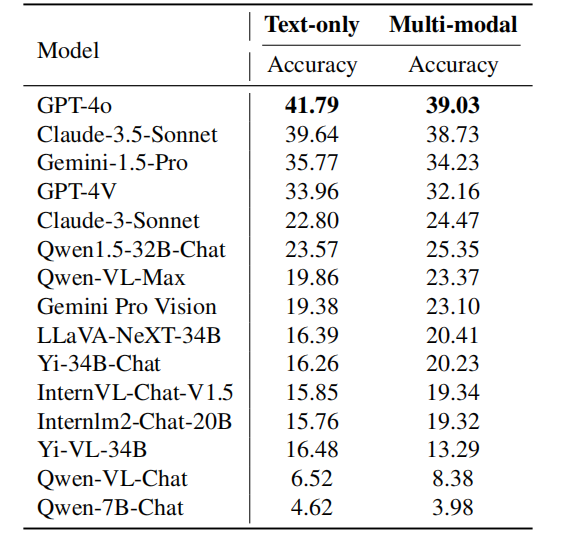
以上がオリンピックで最も賢い AI を選択する: Claude-3.5-Sonnet 対 GPT-4o?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
声明:
この記事の内容はネチズンが自主的に寄稿したものであり、著作権は原著者に帰属します。このサイトは、それに相当する法的責任を負いません。盗作または侵害の疑いのあるコンテンツを見つけた場合は、admin@php.cn までご連絡ください。