
ホームページ >テクノロジー周辺機器 >AI >ワールドモデルも広がります!訓練を受けたエージェントはかなり優秀であることが判明
ワールドモデルも広がります!訓練を受けたエージェントはかなり優秀であることが判明

- PHPzオリジナル
- 2024-06-13 10:12:24457ブラウズ
ワールド モデルは、安全かつサンプル効率の高い方法で強化学習エージェントをトレーニングする方法を提供します。最近、世界モデルは主に環境力学をシミュレートするために離散的な潜在変数シーケンスで動作しています。
ただし、コンパクトな離散表現に圧縮するこの方法では、強化学習にとって重要な視覚的な詳細が無視される可能性があります。一方で、拡散モデルは画像生成の主流の方法となっており、離散潜在モデルに課題をもたらしています。
このパラダイムシフトによって促進され、ジュネーブ大学、エディンバラ大学、Microsoft Research の研究者は共同で、拡散世界モデル - DIAMOND (環境の夢のモデルとしての拡散) で訓練された強化学習エージェントを提案しました。

- 論文アドレス: https://arxiv.org/abs/2405.12399
- プロジェクトアドレス: https://github.com/eloialonso/ダイヤモンド
- 論文のタイトル: ワールド モデリングの普及: Atari におけるビジュアルの詳細が重要
Atari 100k ベンチマークでは、DIAMOND+ は平均 1.46 の Human Normalized Score (HNS) を達成しました。これは、ワールド モデルでトレーニングされたエージェントは、ワールド モデルでトレーニングされたエージェントの SOTA レベルで完全にトレーニングできることを意味します。この研究は、拡散世界モデルの長期にわたる効率的な安定性を確保するには、DIAMOND 設計の選択が必要であることを示す安定性分析を提供します。
画像空間で動作する利点に加えて、拡散ワールド モデルが環境を直接表現できるようになり、ワールド モデルとエージェントの動作についてのより深い理解が得られます。特に、この研究では、特定のゲームのパフォーマンス向上は、主要なビジュアル詳細のモデリングを改善することによってもたらされることがわかりました。
手法の紹介
次に、この記事では、拡散世界モデルで訓練された強化学習エージェントである DIAMOND を紹介します。具体的には、セクション 2.2 で導入したドリフト係数 f と拡散係数 g に基づいてこれを作成します。これらは拡散パラダイムの特定の選択に対応します。さらに、この研究では Karras らの論文に基づいた EDM 配合も選択しました。
まず、摂動カーネル  を定義します。ここで
を定義します。ここで  は、ノイズ スケジュールと呼ばれる、拡散時間に関連する実数値関数です。これは、ドリフト係数と拡散係数を
は、ノイズ スケジュールと呼ばれる、拡散時間に関連する実数値関数です。これは、ドリフト係数と拡散係数を  と
と  に設定することに対応します。
に設定することに対応します。
次に、Karras et al. (2022) によって導入されたネットワーク前処理を使用し、式 (5) の 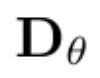 をノイズのある観測値とニューラル ネットワークの
をノイズのある観測値とニューラル ネットワークの 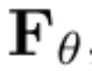 予測値の加重和としてパラメータ化します。 (6)
予測値の加重和としてパラメータ化します。 (6)
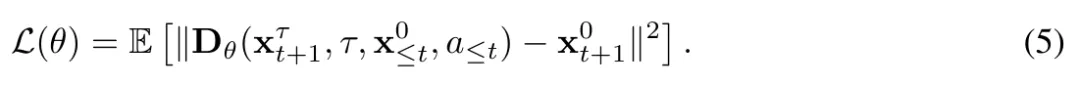
ここで、簡潔に定義するために、 にはすべての条件変数が含まれます。
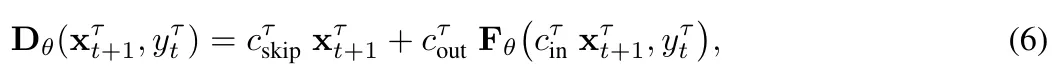
プリプロセッサの選択。プリプロセッサ  と
と  は、あらゆるノイズ レベル
は、あらゆるノイズ レベル  でネットワーク入出力の単位分散を維持するために選択されます。
でネットワーク入出力の単位分散を維持するために選択されます。  はノイズレベルの経験的変換であり、
はノイズレベルの経験的変換であり、 は
は とデータ分布の標準偏差
とデータ分布の標準偏差 によって与えられ、式は
によって与えられ、式は
式5と6を組み合わせると、 のトレーニングターゲットが得られます:
のトレーニングターゲットが得られます:

この研究では、標準の U-Net 2D を使用してベクトル場 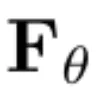 を構築し、過去の L 個の観測とアクションを含むバッファーを保持することでモデルを条件付けします。次に、これらの過去の観測値をチャネルごとに次のノイズのある観測値と連結し、適応グループ正規化層を通じてアクションを U-Net の残差ブロックに入力しました。セクション 2.3 と付録 A で説明したように、トレーニングされた拡散モデルから次の観測値を生成するためのサンプリング方法は数多くあります。研究によって公開されたコード ベースは複数のサンプリング スキームをサポートしていますが、オイラー法は追加の NFE (関数評価の数) を必要とせず、高次サンプラーやランダム サンプリングの不必要な複雑さを回避することが効果的であることがわかりました。
を構築し、過去の L 個の観測とアクションを含むバッファーを保持することでモデルを条件付けします。次に、これらの過去の観測値をチャネルごとに次のノイズのある観測値と連結し、適応グループ正規化層を通じてアクションを U-Net の残差ブロックに入力しました。セクション 2.3 と付録 A で説明したように、トレーニングされた拡散モデルから次の観測値を生成するためのサンプリング方法は数多くあります。研究によって公開されたコード ベースは複数のサンプリング スキームをサポートしていますが、オイラー法は追加の NFE (関数評価の数) を必要とせず、高次サンプラーやランダム サンプリングの不必要な複雑さを回避することが効果的であることがわかりました。
実験
DIAMOND を完全に評価するために、調査では確立された Atari 100k ベンチマークを使用しました。このベンチマークには、エージェントの幅広い機能をテストするための 26 のゲームが含まれています。各ゲームについて、エージェントには、評価される前にゲームのプレイ方法を学習するために、環境内で 100,000 回のアクションのみが許可されました。これは、人間のゲーム時間の約 2 時間に相当します。参考までに、制約のない Atari エージェントは通常、5,000 万ステップのトレーニングを受けます。これは、経験の 500 倍の増加に相当します。研究者たちは、5 つのランダムなシードを使用して、各ゲームで DIAMOND をゼロからトレーニングしました。各実行には約 12 GB の VRAM が使用され、単一の Nvidia RTX 4090 で約 2.9 日かかりました (合計 1.03 GPU 年)。
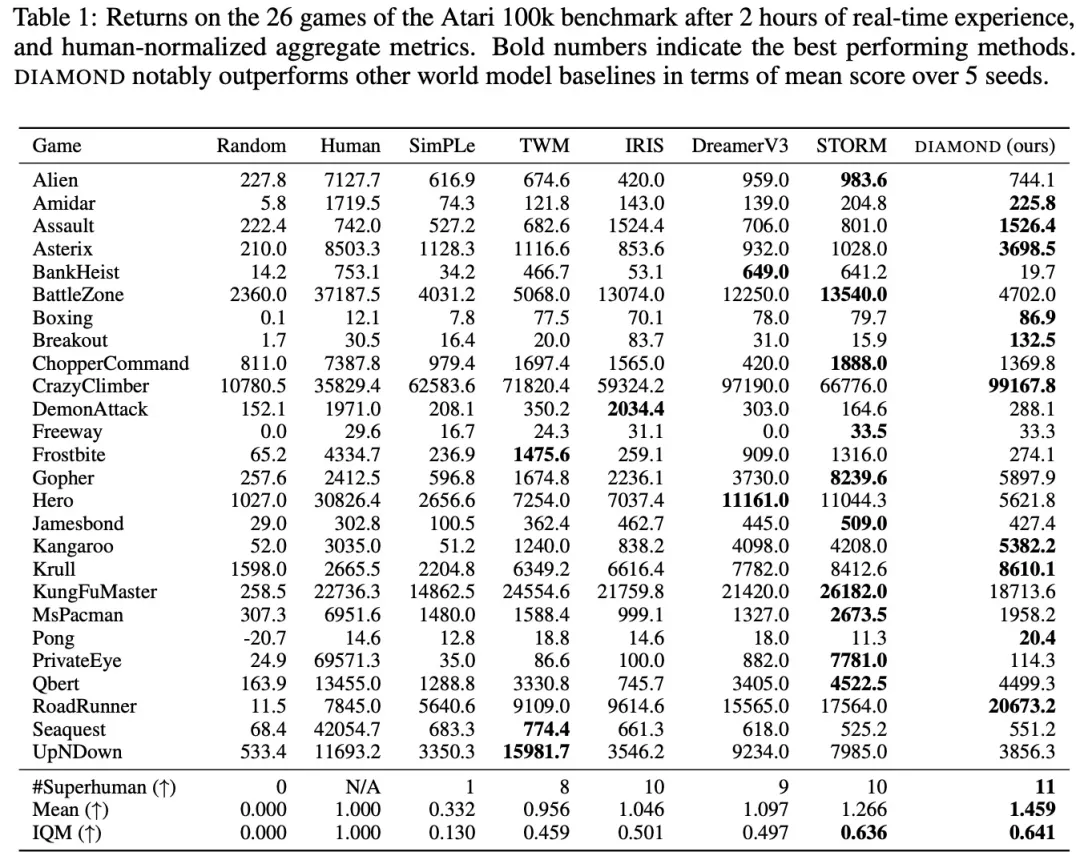
表 1 は、世界モデルでエージェントをトレーニングするためのさまざまなスコアを比較しています。
平均と IQM (四分位平均) 信頼区間を図 2 に示します。
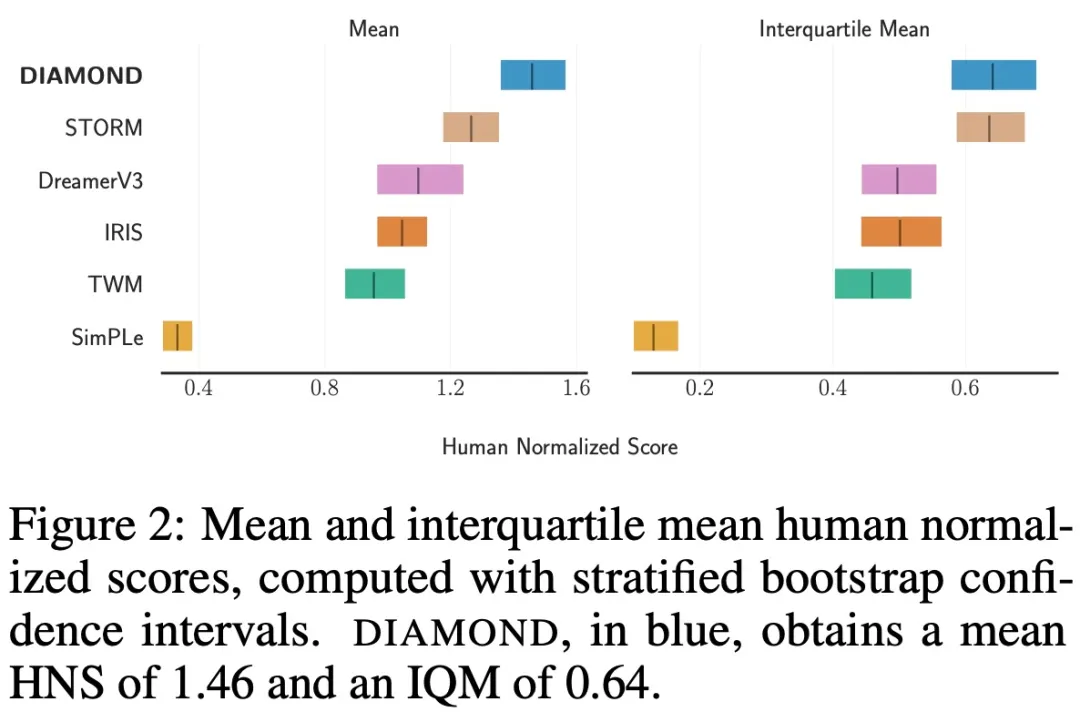
結果は、DIAMOND がベンチマークで優れたパフォーマンスを示し、11 試合で人間のプレイヤーを上回り、HNS スコア 1.46 を達成しました。これは、完全に世界モデルでトレーニングされたエージェントの新記録です。この調査では、DIAMOND が、Asterix、Breakout、Road Runner など、細部のキャプチャが重要な環境で特に優れたパフォーマンスを発揮することもわかりました。
拡散変数の安定性を研究するために、この研究では、以下の図 3 に示すように、自己回帰によって生成された想像上の軌跡を分析しました。 調査では、図 4 に示すボクシング ゲームなど、サンプリング プロセスを特定のモードにするには反復ソルバーが必要な状況があることがわかりました。 IRIS によって想像された軌道と比較して、DIAMOND によって想像された軌道は、一般に視覚的な品質が高く、実際の環境との一貫性が高くなります。 
以上がワールドモデルも広がります!訓練を受けたエージェントはかなり優秀であることが判明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
関連記事
続きを見る- 3D モデルのセグメンテーションの新しい方法により、両手が解放されます。手動のラベル付けは必要なく、必要なトレーニングは 1 回だけで、ラベルのないカテゴリも認識可能 | HKU & Byte
- メタ研究者が AI の新たな試みを行う:地図やトレーニングなしで物理的に移動するようにロボットに教える
- 大規模モデルを使用してテキスト要約トレーニングの新しいパラダイムを作成する
- 完全な自律性に一歩近づいた清華大学と香港大学の新しいクロスタスク自己進化戦略により、エージェントは「経験から学ぶ」ことが可能になります
- 普及モデルはどのようにして新世代の意思決定主体を構築するのでしょうか?自己回帰を超えて、長いシーケンス計画軌道を同時に生成