AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出電子メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
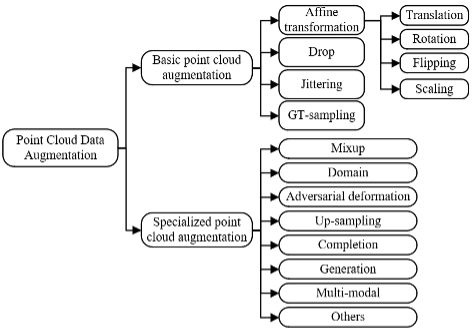
この論文の筆頭著者、Zhu Qinfeng は、西安交通大学とリバプール大学が共同で訓練した 1 年生の博士候補者です。リバプール大学の教授であり、指導教官はファン・レイ准教授です。彼の主な研究方向は、セマンティック セグメンテーション、マルチモーダル情報融合、3D ビジョン、ハイパースペクトル画像、データ強化です。当研究会では24/25レベルの博士課程学生を募集しています。メールでのお問い合わせも歓迎です。 メール: qinfeng.zhu21@student.xjtlu.edu.cnホームページ: https://zhuqinfeng1999.github.io/この記事は、トップジャーナルである Pattern のレビューですパターン認識の分野における Recognition 2024 の最新レビュー論文: 「深層学習のための点群データ拡張の進歩: 調査」の解釈。 この論文は、西安交通リバプール大学のZhu Qinfeng、Fan Lei、Weng Ningxinによって完成されました。 このレビューは、点群データ強化関連の研究成果を初めて包括的に要約しています。 ディープラーニングは、検出、セグメンテーション、分類などの点群分析タスクの主流かつ効果的な方法の 1 つになりました。深層学習モデルのトレーニング中の過剰適合を軽減するため、特にトレーニング データの量や多様性が限られている場合にモデルのパフォーマンスを向上させるには、多くの場合、データ拡張が鍵となります。さまざまな点群データ拡張手法がさまざまな点群処理タスクで広く使用されていますが、これらの手法に関する系統的なレビューや議論はまだ発表されていません。 したがって、この論文では、これらの方法を調査し、基本的および具体的な点群データ拡張方法を含む 分類フレームワーク に分類します。このペーパーでは、これらの拡張方法の包括的な評価を通じて、その可能性と限界を特定し、適切な拡張方法を選択するための有用な参考情報を提供します。 さらに、この記事では、将来の研究の潜在的な方向性を探ります。この調査は、点群データ拡張に関する現在の研究の包括的な概要を提供し、その幅広い応用と開発を促進するのに役立ちます。 無料アクセス: https://authors.elsevier.com/c/1j3TW77nKoLGMarXiv: https://arxiv.org/pdf/2308.12113著者ホームページ: https://zhuqinfeng1999.github.io図 1. 点群データの強化方法の分類。 ディープラーニングの分野では、利用可能なトレーニングデータセットが限られている場合にデータ拡張がよく使用されます。これには、特定の一連の操作を実行して元のデータを変更または拡張することが含まれ、それによってデータ セットのサイズと多様性が増加します。
データ拡張は、深層学習ネットワークをトレーニングする場合、ほぼ常に理想的であると考えられています。これは、高品質の拡張データセットがネットワークの堅牢性を向上させ、汎化機能を強化し、過剰学習を軽減するのに役立つためです。画像データの強化とテキストデータの強化の分野では、包括的な発展が見られます。
点群処理タスクに関する最近発表された多数の研究論文で、研究者は点群データを強化するさまざまな方法を検討してきました。これらの手法は多岐にわたるため、研究者は適切な手法を選択することが困難になります。したがって、これらの方法を体系的に調査し、さまざまなグループに分類することは非常に価値があります。
この論文では、点群データの拡張方法に関する包括的な調査を紹介します。
調査に基づいて、図 1 に示すように、これらの強化方法の分類システムを提案します。
強化方法は、基本点群強化と特定点群強化の 2 つの主なカテゴリに分類できます。これは、画像強化の一般的な分類方法と同様です。基本点群拡張 は、調査文献の他の方法と組み合わせて広く使用されていることからわかるように、さまざまなタスクやアプリケーションのコンテキストにおいて概念的にシンプルで普遍的な方法を指します。 特定点群強化は、通常、特定の課題を解決したり、特定のアプリケーション環境に対応したりするために開発された手法を指します。ほとんどの場合、特定の点群の強化は、強化方法の実装の詳細に応じて、基本の強化よりも計算が複雑になります。私たちが提案する分類システムのサブカテゴリは、文献で点群データの強化に使用されてきたさまざまな方法、または点群データの強化に使用される可能性のあるさまざまな方法の概要を表します。
- これは、点群データ強化方法を包括的に調査する最初のレビューであり、点群データ強化の最新の進歩をカバーしています。強調操作の特性に基づいて、点群データ強調手法の分類システムを提案します。
- この研究では、さまざまな点群データ拡張手法を要約し、検出、セグメンテーション、分類などの典型的な点群処理タスクへの応用について説明し、将来の研究の可能性についての提案を提供します。
アフィン変換には、共線性と距離スケーリングを維持するアフィン空間の変換が含まれます。画像データの強調処理で一般的に使用されるアフィン変換方法には、スケーリング、平行移動、回転、反転、およびせん断が含まれます。同様に、アフィン変換は点群データの拡張にも適用できます。典型的な方法には、平行移動、回転、反転、およびスケーリングが含まれ、これらの方法は追加の新しいトレーニング データを生成するために広く使用されています。 これらの操作は、特定の戦略を使用して点群データセット全体、または点群データ内の選択されたインスタンス (インスタンスとは、図 2(a) に示す車両などの意味論的なオブジェクトを指します) に適用したり、選択したインスタンスの特定の部分。 ただし、アフィン変換によって強化されたデータは、情報損失や不合理なセマンティクスの問題に直面する可能性があります。これらのアフィン変換の具体的な操作と説明については、論文で詳しく説明されています。図 2. 模倣変換によって点群データを強化する例: (a) 元の点群データ、(b) 車両、(C) 車両、(d) 車両、(E) シーンの反転。 破棄拡張 は、図 3 に示すように、点群データ内の一部のデータ ポイントを破棄することを指します。除去ポイントの選択は、特定の戦略によって決まります。破棄されるポイントは、点群データ全体の一部である場合も、シーン内でランダムに選択されたポイントである場合もあります。ドロップアウト拡張により、ディープ ラーニング モデルが、遮蔽されたシーンや部分的に表示されているシーンを表す欠落データや不完全なデータに対してより堅牢になります。 また、深層学習モデルがトレーニング データセット内の特定のデータ ポイントに依存しすぎることも防ぎます。ただし、過剰または重要な点群情報が失われると、トレーニング データ内の現実世界のオブジェクトが非現実的に表現され、深層学習モデルのトレーニングに影響を与える可能性があります。この論文では、ドロップアウト強化に基づくさまざまな方法と議論について詳しく説明されています。図 3. 強化の強化の例: (a) 元の点群データ、(b) 強化点群をランダムに破棄、(C) 強化点群の一部を破棄。 ジッターとは、図 4 に示すように、点群内の 1 つの点の位置に小さな摂動またはノイズを適用することを指します。この論文では、ジッター強化に基づくさまざまな方法と議論について詳しく説明されています。 
図 4. 強化の判定例: (a) 元の点群データ、(b) ジッターによって強化された点群データ。
屋外の自動運転シーンなどのシーンレベルの点群データセットでは、通常、ラベル付きインスタンスは制限されています。この場合、GT サンプリングはシンプルで効果的なデータ拡張方法になります。
GT サンプリングは、ラベル付きインスタンスをトレーニング データセットに追加する操作を指します。図 5 に示すように、ラベル付き GT インスタンスは同じトレーニング データセットまたは他のデータセットから取得されます。 GT サンプリングは通常、シーン レベルの点群データセットに適していますが、ShapeNet などのインスタンス レベルの点群データセットは通常考慮されません。この論文では、GT サンプリングの強化に基づくさまざまな方法と議論について詳しく説明されています。
。 (b) 意味的に不合理な GT サンプリング。1 台の車は建物の壁の内側にあり、もう 1 台は木の内側にあります。
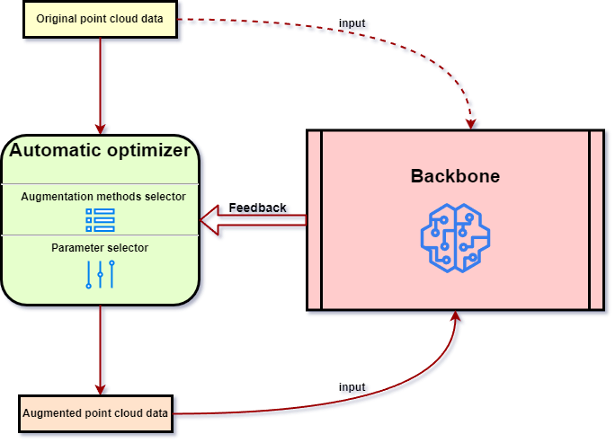
さらに、この記事では、パッチベースの戦略や自動最適化戦略など、基本的な点群データの強化方法に適用される戦略も紹介します (図 6 を参照)。この記事では、表 1 に示すような、典型的な基本的な点群強化方法を要約します。図 6. 自動最適化の一般的なプロセス。
特定点群強化方法は、通常、特定の課題やアプリケーション シナリオを解決するために設計されています。具体的な点群の強化には、ミックスアップ強化、ドメイン強化、敵対的変形強化、アップサンプリング強化、補完強化、生成強化、マルチモーダル強化などが含まれます。
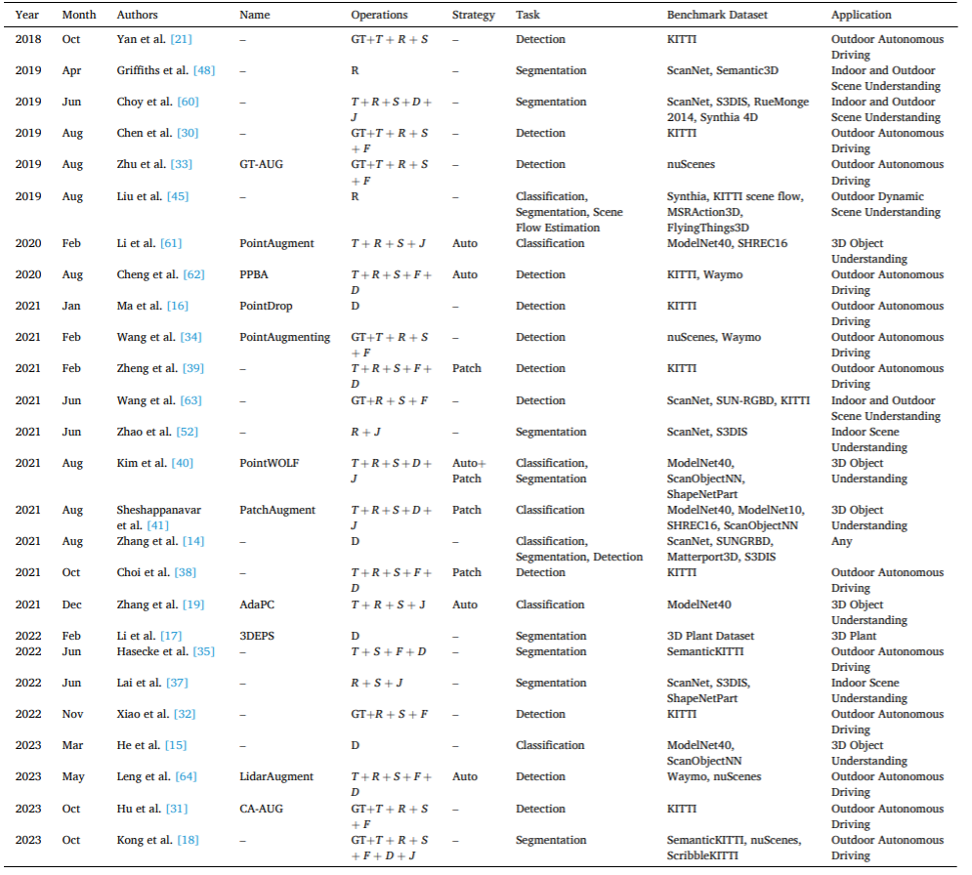
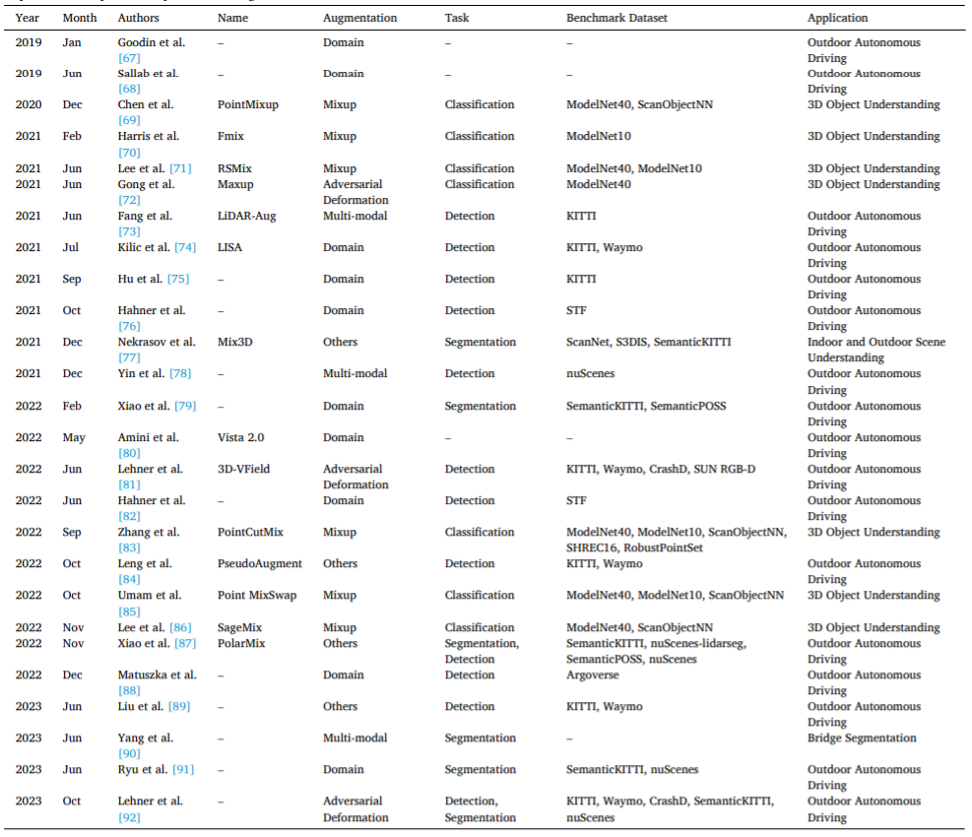
これらの特定の強化方法の具体的な定義と議論は本文で詳しく説明されています。表 2 は、代表的な特定の強化方法の開発の概要を示し、さまざまな情報を提供します。表 2. 代表的な特定の点群強化方法。 表 3 に示すように、現在の一部の敵対的変形、アップサンプリング、補完および生成テクノロジは、点群データの強化に直接適用されていないことに注意してください。特定の方法を包括的に分類するために、この記事ではこれらの潜在的な方法も含めて説明します。表 3. 潜在的な特定の点群強化方法。
この論文では、点群データ強化法の適用可能なタスクとシナリオが詳細に説明されており、一貫性学習における点群データ強化の役割が指摘されています。図 7 に示すように。
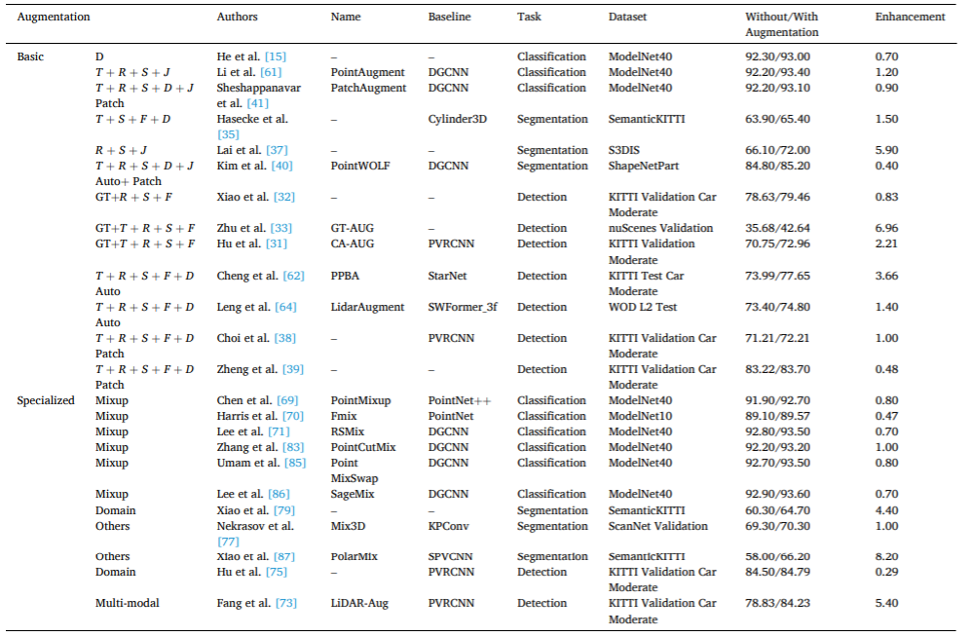
図 7. (a) 従来の深層学習トレーニング。元のデータと強化されたデータをトレーニングのために深層学習ネットワークに送信し、トレーニングされたモデルを取得します。(b) さまざまな強化手法を使用して入力ポイントを変更する一貫性学習。クラウド データは変換されて複数の拡張変数が生成され、一貫した学習のために複数のネットワークに供給され、トレーニング中に一貫した予測が行われます。 表 4 は、データ強化前後の定量的評価に関する文献を整理し、データ強化の効果を示しています。さまざまな拡張手法の比較のもう 1 つの部分として、付録 (詳細については論文を参照) では、拡張点群データを使用した下流タスクの定量的パフォーマンスと、これらのタスクで使用される拡張手法の概要も提供します。
表 4. ポイントのレポート結果強化されたモデルのパフォーマンスによるクラウド データの強化。 研究チームは、この分野のさらなる研究の9つの可能性のある方向性を指摘しました:
-
研究者は点群のAdversを十分に研究していませんエリアルワープ、データ拡張のためのアップサンプリング、補完、生成。 GAN と拡散モデルの進歩を考慮すると、これらのモデルを使用して現実的で多様な点群インスタンスを生成できます。今後の研究では、特定の点群処理タスクのベンチマーク データセットでこれらの手法を評価し、拡張手法としての有効性を評価する必要があります。
-
現在、一貫したベースライン ネットワークとデータセットを使用して、さまざまな点群処理タスクに対する点群データ拡張手法のパフォーマンスを評価する研究はほとんどありません。このような評価により、さまざまな拡張方法のパフォーマンスについての理解が深まります。したがって、将来の研究活動は、点群データ拡張手法の有効性と深層学習モデルのパフォーマンスへの影響を評価するための新しい手法、指標、データセットの確立に焦点を当てる可能性があります。
-
一部の特定の拡張手法は、大規模な点群データセットに適用すると、計算コストが高くなる可能性があります。今後の作業は、計算コストと効率の向上をトレードオフする効率的なアルゴリズムの開発に焦点を当てることができます。さらに、一部の特定の点群強化方法は比較的複雑で再現が困難です。広範な採用を促進するために、プラグアンドプレイのアプローチを開発することをお勧めします。
-
点群データの強調には、広く受け入れられている基本的な強調操作の組み合わせが不足しています。したがって、拡張効率を犠牲にすることなく、さまざまなアプリケーションドメイン、タスク、および/またはデータセットの拡張操作を選択するための標準プロトコルを確立するには、将来の作業が必要です。
-
拡張によって生成された複数の点群バリアントは、一貫性学習の有効性に影響します。現在、私たちの知る限り、一貫性学習では基本的なブースティング手法のみが使用されています。敵対的変形や生成的強化などの特定の点群強化方法を探索することは、一貫性学習の有効性を向上させる興味深い方法を提供し、将来の貴重な研究の方向性と考えられています。
-
現在、基本的な点群強化方法と特定の点群強化方法を組み合わせる研究は限られています。このような組み合わせは、データ拡張の汎用性をさらに高める可能性があり、将来の研究に値します。
-
拡張では、オブジェクトのサイズ、位置、向き、外観、環境の変化など、点群データの変化を現実的にシミュレートして、シミュレートされたデータが現実世界の状況と一貫性があり、意味的に保たれていることを確認する必要があります。正しい。将来の研究では、特定のアプリケーション シナリオに合わせてさまざまな拡張範囲の標準化を検討する可能性があります。
-
ターゲット検出などの一部のアプリケーションには、シーン内の動的オブジェクトが含まれる場合があります。動的環境でキャプチャされた点群には、オブジェクトの時間的変化を考慮した特定の拡張戦略が必要になる場合があります。たとえば、移動オブジェクトの特定の軌道を設計できます。これは、移動、回転、破棄などの一連の組み合わせた強調操作を通じて実現できます。
-
ViT は、基本的な操作を組み合わせるだけで、セグメンテーションおよび分類タスクでも強力なパフォーマンスを実現します。バックボーン ネットワークとして最先端の ViT と統合した場合の、強化されたメソッドのパフォーマンスを調査することは有意義です。
[1] Qinfeng Zhu 、 Lei Fan 、 Ningxin Weng 、 Advancements in Point ディープ向けのクラウド データ拡張学習: 調査、パターン認識 (2024)、doi:https://doi.org/10.1016/j.patcog.2024.110532以上がXJTLU とリバプール大学が提案: 点群データ強化に関する最初の包括的なレビューの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。