
Maison >Périphériques technologiques >IA >Le premier grand modèle multimodal XVERSE-V de Yuanxiang est open source, actualisant la liste des grands modèles faisant autorité et prenant en charge toute entrée de rapport d'aspect
Le premier grand modèle multimodal XVERSE-V de Yuanxiang est open source, actualisant la liste des grands modèles faisant autorité et prenant en charge toute entrée de rapport d'aspect

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-04-28 16:43:08815parcourir
83 % des informations que les humains obtiennent proviennent de la vision. Les grands modèles multimodaux de graphiques et de textes peuvent percevoir des informations du monde réel plus riches et plus précises, construire une intelligence cognitive plus complète et ainsi faire de plus grands pas vers l'AGI (Intelligence Générale Artificielle). .
Yuanxiang a lancé aujourd'hui le grand modèle multimodal XVERSE-V, qui prend en charge la saisie d'images avec n'importe quel rapport d'aspect et est en tête des évaluations grand public. Ce modèle est entièrement open source et inconditionnellement gratuit pour un usage commercial, et continue de promouvoir la R&D et l'innovation applicative d'un grand nombre de petites et moyennes entreprises, de chercheurs et de développeurs.  XVERSE-V a d'excellentes performances, surpassant les modèles open source tels que Yi-VL-34B, l'OmniLMM-12B intelligent face au mur et DeepSeek-VL-7B dans plusieurs évaluations multimodales faisant autorité et dans l'évaluation complète des capacités MMBench Il dépasse modèles fermés bien connus tels que Google GeminiProVision, Alibaba Qwen-VL-Plus et Claude-3V Sonnet.
XVERSE-V a d'excellentes performances, surpassant les modèles open source tels que Yi-VL-34B, l'OmniLMM-12B intelligent face au mur et DeepSeek-VL-7B dans plusieurs évaluations multimodales faisant autorité et dans l'évaluation complète des capacités MMBench Il dépasse modèles fermés bien connus tels que Google GeminiProVision, Alibaba Qwen-VL-Plus et Claude-3V Sonnet. 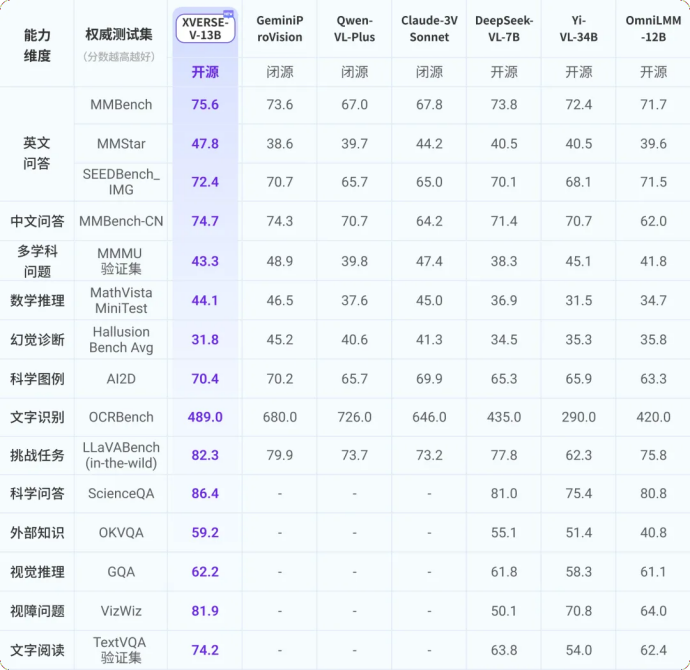 Figure. Évaluation complète des grands modèles multimodaux
Figure. Évaluation complète des grands modèles multimodaux
Fusion de la représentation d'image haute définition globale et locale
La représentation d'image de modèle multimodale traditionnelle n'a que le tout, XVERSE-V adopte de manière innovante une stratégie d'intégration du tout. et la partie prend en charge la saisie d'images avec n'importe quel rapport hauteur/largeur. En prenant en compte à la fois les informations globales et les informations locales détaillées, il peut identifier et analyser les caractéristiques subtiles des images, voir plus clairement et comprendre plus précisément. E Remarque : Concate* indique que la méthode de traitement est effectuée en fonction de la colonne. 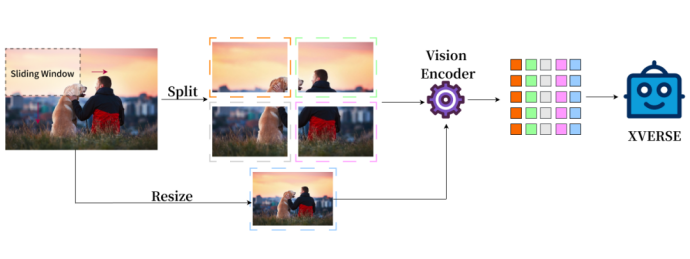
 Les modèles peuvent être utilisés dans un large éventail de domaines, notamment la reconnaissance de diagrammes panoramiques, les images satellite et l'analyse par balayage d'antiquités.
Les modèles peuvent être utilisés dans un large éventail de domaines, notamment la reconnaissance de diagrammes panoramiques, les images satellite et l'analyse par balayage d'antiquités.

 Téléchargement gratuit du grand modèle
Téléchargement gratuit du grand modèle
•Hugging Face : https://huggingface.co/xverse/XVERSE-V-13B
•ModelScope :https ://modelscope.cn/models/xverse/XVERSE-V-13B•Github : https://github.com/xverse-ai/XVERSE-V-13B•Pour toute demande de renseignements, veuillez envoyer : opensource@xverse .cnYuanxiang continue de construire des références open source nationales, avecle premier open source en Chine avec un paramètre maximum de 65B
, le premier open source au monde avec le contexte le plus long de 256Ket le MoE international de pointe modèle, et leader du pays dans l'évaluation SuperCLUE. Le lancement du modèle MoE comble cette fois le vide de l’open source national et le propulse au premier niveau international. En termes d'application commerciale, le grand modèle Yuanxiang est l'un des premiers modèles du Guangdong à obtenir un enregistrement national et peut fournir des services à l'ensemble de la société. Yuanxiang Large Model mène une coopération approfondie et une exploration d'applications avec un certain nombre de produits Tencent depuis l'année dernière, notamment
QQ Music, Huya Live, National Karaoke, Tencent Cloud, etc., pour créer des produits innovants et leaders dans les domaines de la culture, du divertissement, du tourisme et de la finance. Performances exceptionnelles dans les applications pratiques multidirectionnelles
Le modèle fonctionne non seulement bien dans les capacités de base, mais fonctionne également bien dans les scénarios d'application réels. Avoir la capacité de comprendre différents scénarios et être capable de gérer différents besoins tels que des graphiques d'information, des documents, des scénarios réels, des questions mathématiques, des documents scientifiques, la conversion de code, etc. •
Compréhension des graphiquesQu'il s'agisse de la compréhension de graphiques d'informations combinant des graphiques et du texte complexes, ou de l'analyse et du calcul d'un seul graphique, le modèle peut le gérer facilement. 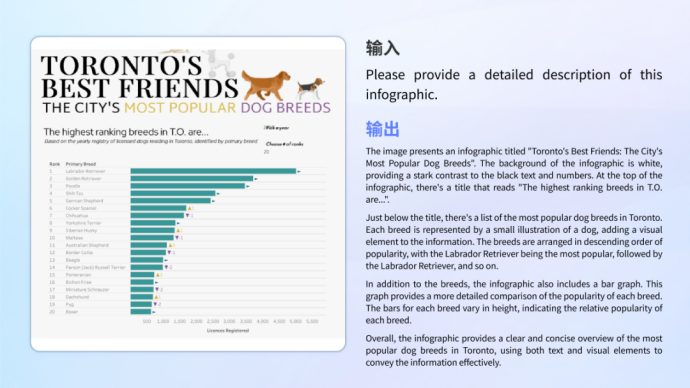
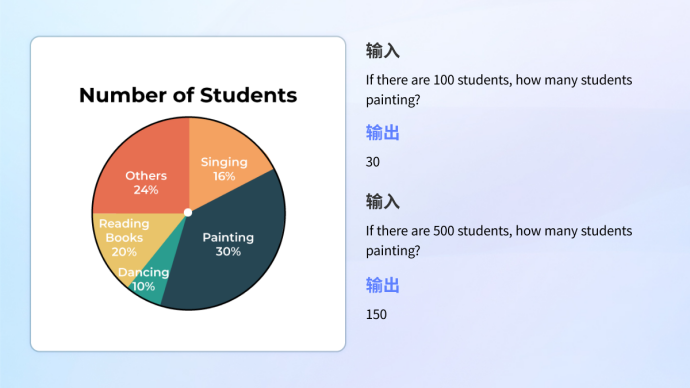
•Scènes réelles de déficience visuelle
Dans l'ensemble de tests de scènes réelles pour malvoyants VizWiz, XVERSE-V a bien fonctionné, surpassant presque tous les open source grand public tels que InternVL-Chat-V1.5 et DeepSeek-VL- 7B Grands modèles multimodaux. Cet ensemble de tests contient plus de 31 000 questions et réponses visuelles provenant de vrais utilisateurs malvoyants, qui peuvent refléter avec précision les besoins réels et les problèmes triviaux des utilisateurs, et aider les personnes malvoyantes à surmonter leurs véritables défis visuels quotidiens.测试 Exemple de test Vizwiz 
• •
Xverse-V a une capacité multimodale tout en conservant une forte capacité de génération de texte.

Résolution de problèmes éducatifs
Le modèle dispose d'un large éventail de réserves de connaissances et de capacités de raisonnement logique, et peut reconnaître des images pour répondre à des questions dans différentes disciplines.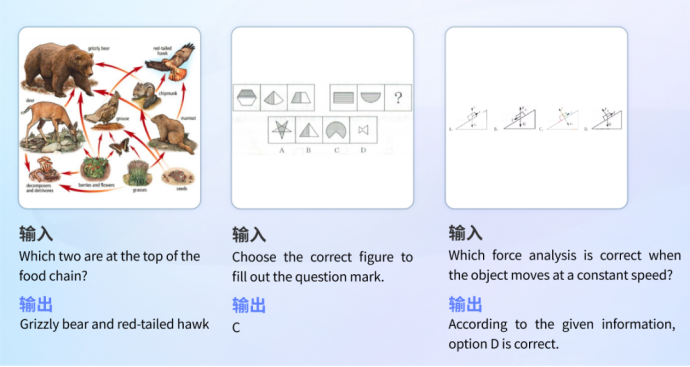
Réponses de l'Encyclopédie
Le modèle stocke des connaissances sur divers sujets tels que l'histoire, la culture, la technologie et la sécurité.
Écriture de codes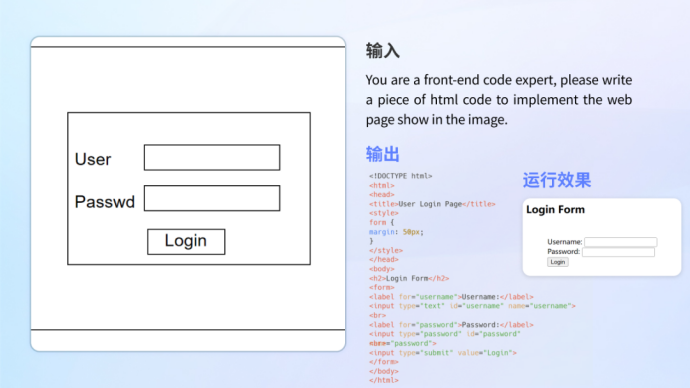
Conduite autonome
Compréhension et reconnaissance des émotions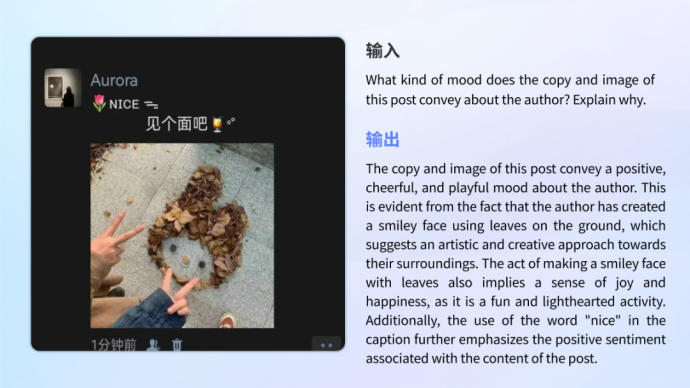
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!