
La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com.
Récemment, des modèles d'IA à grande échelle tels que les grands modèles de langage et les modèles de graphes vincentiens se sont développés rapidement. Dans cette situation, comment s'adapter à l'évolution rapide des besoins et adapter rapidement les grands modèles à diverses tâches en aval est devenu un défi important. Limitées par les ressources informatiques, les méthodes traditionnelles de réglage fin de tous les paramètres peuvent s'avérer insuffisantes, c'est pourquoi des stratégies de réglage fin plus efficaces doivent être explorées. Les défis ci-dessus ont donné lieu au récent développement rapide de la technologie de réglage fin efficace des paramètres (PEFT). Afin de résumer de manière exhaustive l'histoire du développement de la technologie PEFT et de suivre les derniers progrès de la recherche, des chercheurs de l'Université Northeastern, de l'Université de Californie Riverside, de l'Université d'État de l'Arizona et de l'Université de New York ont récemment étudié, organisé et résumé les paramètres. L'application de la technologie de réglage fin efficace (PEFT) sur les grands modèles et ses perspectives de développement sont résumées dans une revue complète et avant-gardiste. 
Lien papier : https://arxiv.org/pdf/2403.14608.pdfPEFT fournit un moyen efficace d'adaptation des tâches en aval pour les modèles pré-entraînés en corrigeant la plupart des paramètres de pré-entraînement et affinant un très petit nombre de paramètres, permettant aux grands modèles de se déplacer facilement et de s'adapter rapidement à diverses tâches en aval, faisant ainsi des grands modèles non plus des « gros Mac ». Le texte intégral fait 24 pages, couvrant près de 250 documents les plus récents. Il a été cité par l'Université de Stanford, l'Université de Pékin et d'autres institutions dès sa publication, et a gagné en popularité sur diverses plateformes. 

Plus précisément, cette revue analyse de manière exhaustive l'historique de développement et les derniers progrès de PEFT sous quatre aspects : la classification de l'algorithme PEFT, la conception PEFT efficace, l'application multi-domaines PEFT, ainsi que la conception et le déploiement du système PEFT et son explication détaillée. . Que vous soyez un praticien dans des secteurs connexes ou un débutant dans le domaine de la mise au point de grands modèles, cette revue peut servir de guide d'apprentissage complet. 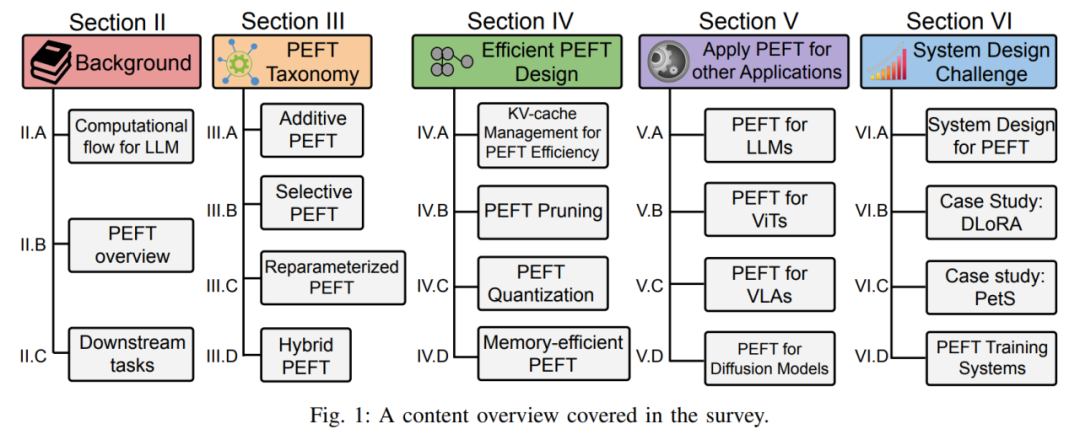
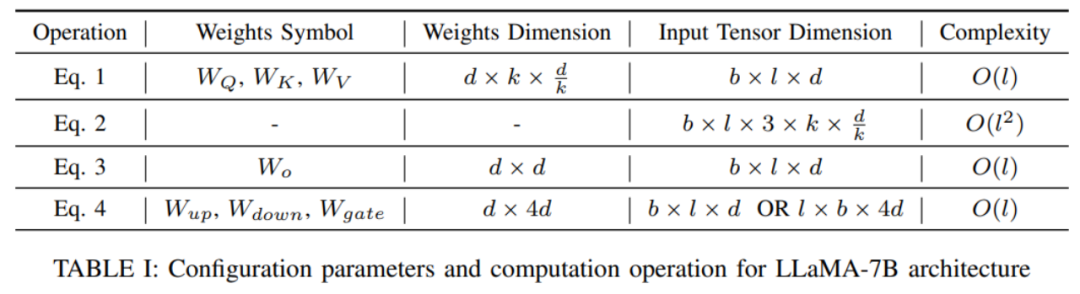
1. Introduction générale à PEFTL'article utilise d'abord le modèle LLaMA récemment populaire comme représentant pour analyser et expliquer l'architecture et le processus de calcul des grands modèles de langage (LLM) et autres Transformer- modèles basés sur . et définit la représentation symbolique requise pour faciliter l'analyse ultérieure de diverses technologies PEFT. 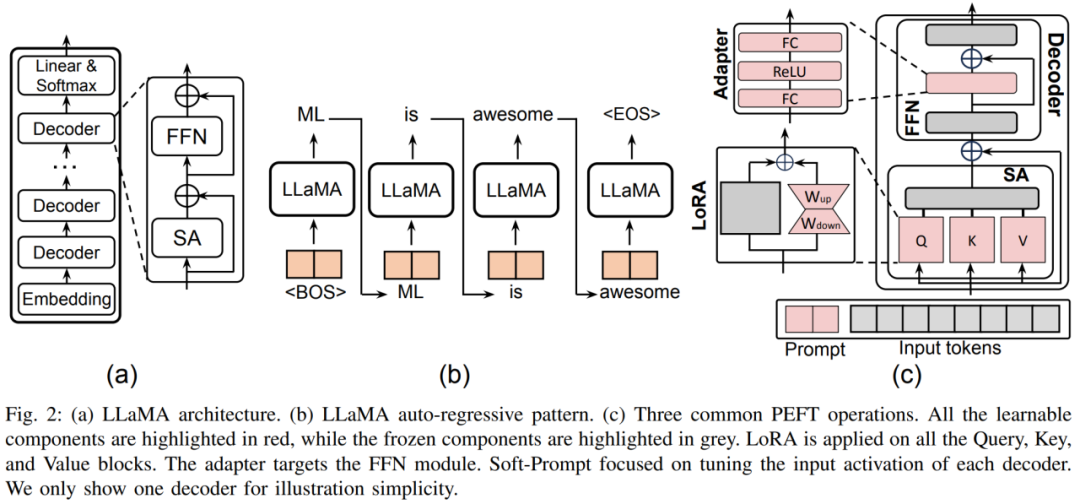
De plus, l'auteur décrit également la méthode de classification de l'algorithme PEFT. L'auteur divise l'algorithme PEFT en réglage fin additif, réglage fin sélectif, réglage fin fortement paramétré et réglage fin hybride selon différentes opérations. La figure 3 montre la classification des algorithmes PEFT et les noms d'algorithmes spécifiques inclus dans chaque catégorie. Les définitions spécifiques de chaque catégorie seront expliquées en détail ultérieurement. 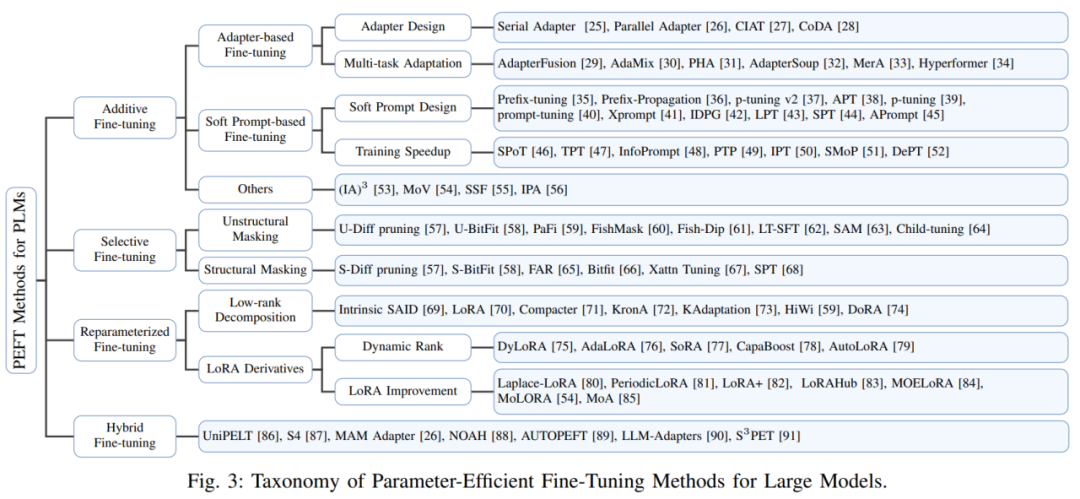
Dans la section de contexte, l'auteur présente également des références communes en aval et des ensembles de données utilisés pour vérifier les performances de la méthode PEFT, permettant ainsi aux lecteurs de se familiariser plus facilement avec les paramètres de tâches courants. 2. Classification de la méthode PEFT
L'auteur donne d'abord les définitions du réglage fin additif, du réglage fin sélectif, du réglage fin fortement paramétré et du réglage fin hybride :
- Réglage fin additionnel En ajoutant des modules ou des paramètres apprenables à des emplacements spécifiques dans le modèle pré-entraîné pour minimiser le nombre de paramètres pouvant être entraînés du modèle lors de l'adaptation aux tâches en aval.
- Réglage fin sélectifDans le processus de réglage fin, seule une partie des paramètres du modèle est mise à jour, tandis que les paramètres restants restent fixes. Par rapport au réglage fin additif, le réglage fin sélectif ne nécessite pas de modifier l'architecture du modèle pré-entraîné.
- Le réglage fin reparamétré fonctionne en construisant des représentations (de bas rang) de paramètres de modèle pré-entraînés pour l'entraînement. Pendant l'inférence, les paramètres seront convertis de manière équivalente dans la structure de paramètres du modèle pré-entraîné pour éviter d'introduire des retards d'inférence supplémentaires.
La distinction entre les trois est illustrée dans la figure 4 : 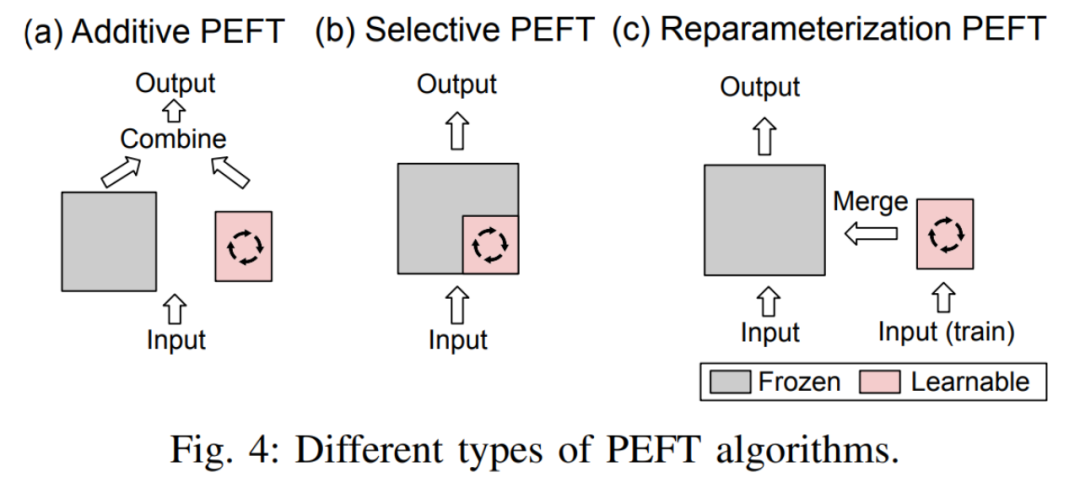
Le réglage fin hybride combine les avantages de diverses méthodes PEFT et construit un PEFT unifié en analysant les similitudes de l'architecture des différentes méthodes, ou trouver des hyperparamètres PEFT optimaux. Ensuite, l'auteur subdivise chaque catégorie PEFT : A. Réglage fin de l'additif : Adaptateur en ajoutant un petit transformateur à l'intérieur du bloc Transformateur. La couche Adaptateur implémente un réglage fin efficace des paramètres. Chaque couche d'adaptateur contient une matrice de projection vers le bas, une fonction d'activation et une matrice de projection vers le haut. La matrice de projection vers le bas mappe les entités d'entrée sur la dimension du goulot d'étranglement r, et la matrice de projection vers le haut mappe les entités de goulot d'étranglement sur la dimension d'origine d. 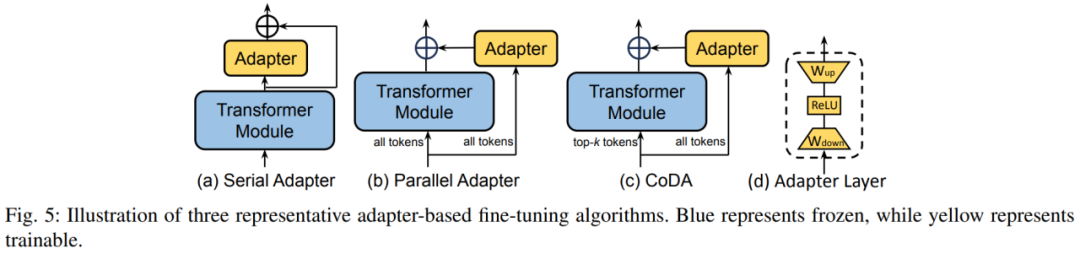
La figure 5 montre trois stratégies d'insertion typiques de la couche Adaptateur dans le modèle. L'adaptateur série est inséré séquentiellement après le module transformateur et l'adaptateur parallèle est inséré en parallèle à côté du module transformateur. CoDA est une méthode d'adaptateur clairsemée. Pour les jetons importants, CoDA utilise à la fois le module Transformer pré-entraîné et la branche Adapter pour le raisonnement ; pour les jetons sans importance, CoDA utilise uniquement la branche Adapter pour le raisonnement afin d'économiser la surcharge de calcul. Soft Prompt permet un réglage fin efficace des paramètres en ajoutant des vecteurs apprenables en tête de la séquence d'entrée. Les méthodes représentatives incluent le réglage du préfixe et le réglage des invites. Le réglage des préfixes permet d'affiner la représentation du modèle en ajoutant des vecteurs apprenables devant les matrices de clé, de valeur et de requête de chaque couche Transformer. Prompt Tuning insère uniquement les vecteurs apprenables dans la première couche de vecteurs de mots pour réduire davantage les paramètres de formation. En plus des deux classifications ci-dessus, il existe également certaines méthodes PEFT qui introduisent également de nouveaux paramètres dans le processus de formation. 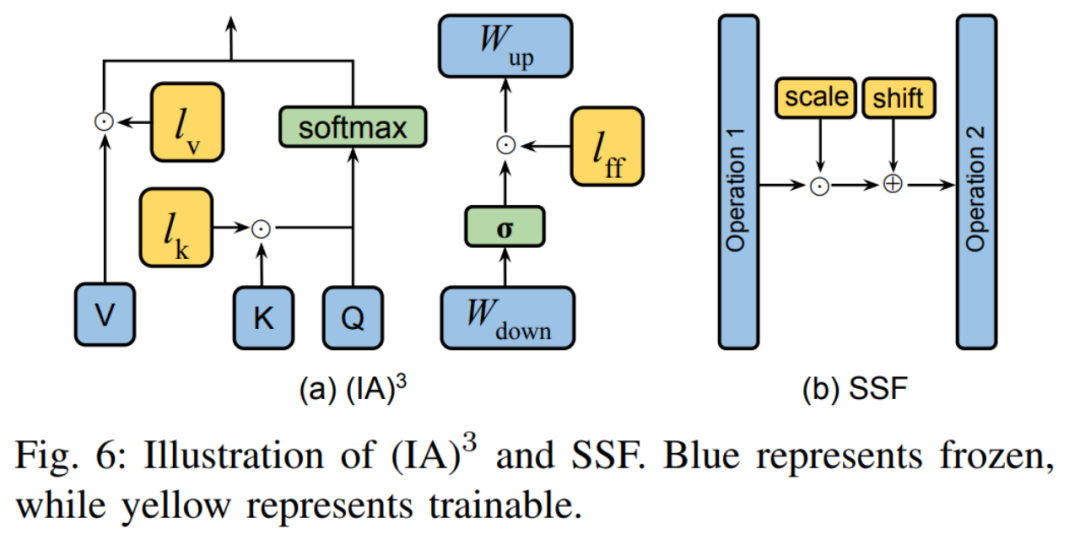
Les deux méthodes typiques sont présentées dans la figure 6. (IA) 3 introduit trois vecteurs de mise à l'échelle pour ajuster les clés, les valeurs et les activations des réseaux à réaction. SSF ajuste la valeur d'activation du modèle par transformation linéaire. Après chaque étape, SSF ajoute une couche SSF-ADA pour permettre la mise à l'échelle et la traduction des valeurs d'activation. Ce type de méthode détermine les paramètres qui peuvent être affinés en ajoutant un masque binaire apprenable aux paramètres du modèle. . De nombreux travaux, tels que Diff pruning, FishMask et LT-SFT, etc., se concentrent sur le calcul de la position du masque. Le masque non structuré n'a aucune restriction sur la forme du masque, mais cela conduit à une inefficacité dans son impact. Ainsi, certains travaux, comme FAR, S-Bitfit, Xattn Tuning, etc., imposent des restrictions structurées sur la forme du masque. La différence entre les deux est montrée dans l'image ci-dessous : 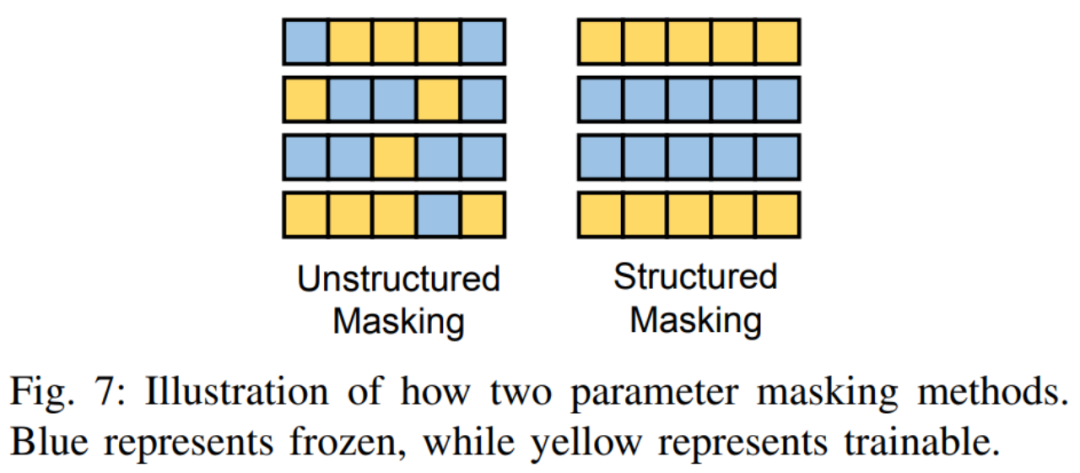
C. Affinement reparamétré : 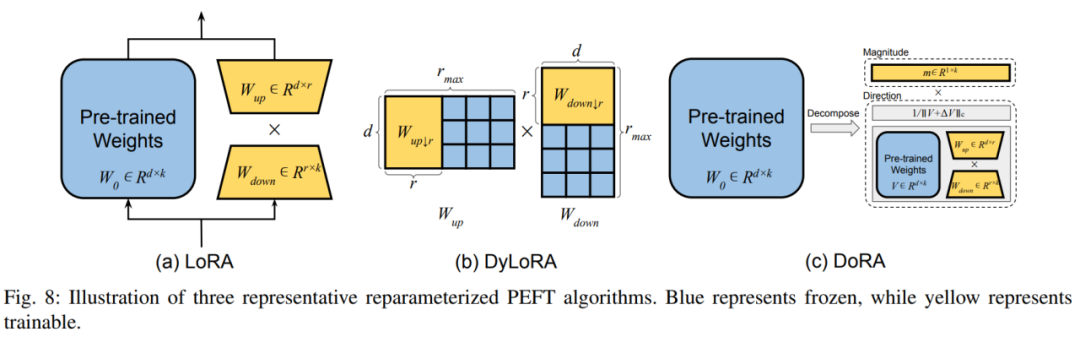
1) Décomposition de bas rang Ce type de méthode fonctionne en trouvant diverses formes reparamétrées de faible dimension de la matrice de poids pré-entraînée à représenter. tout l'espace des paramètres pour un réglage fin. La méthode la plus courante est LoRA, qui construit une représentation de bas rang des paramètres du modèle d'origine pour la formation en ajoutant deux matrices supplémentaires de projection vers le haut et vers le bas. Après l'entraînement, des paramètres supplémentaires peuvent être fusionnés de manière transparente dans des poids pré-entraînés pour éviter d'introduire une surcharge d'inférence supplémentaire. DoRA découple la matrice de poids en longueur et direction modulaires, et exploite LoRA pour affiner la matrice de direction. 2) Méthode de dérivation LoRA L'auteur divise la méthode de dérivation LoRA en sélection dynamique du rang de LoRA et amélioration de LoRA sous divers aspects. Dans le classement dynamique LoRA, la méthode typique est DyLoRA, qui construit une série de rangs pour un entraînement simultané pendant le processus d'entraînement, réduisant ainsi les ressources dépensées pour trouver le classement optimal. Dans l'amélioration de LoRA, l'auteur énumère les lacunes de LoRA traditionnelle sous divers aspects et les solutions correspondantes. Cette partie étudie comment intégrer différentes technologies PEFT dans un modèle unifié et trouver un modèle de conception optimal. De plus, certaines solutions utilisant la recherche d'architecture neuronale (NAS) pour obtenir des hyperparamètres de formation PEFT optimaux sont également introduites. 3. Conception PEFT efficace
Dans cette section, l'auteur discute des recherches visant à améliorer l'efficacité du PEFT, en se concentrant sur la latence et la surcharge mémoire maximale de sa formation et de son inférence. L'auteur décrit principalement comment améliorer l'efficacité du PEFT sous trois angles. Ce sont : Stratégie d'élagage PEFT : Combinant la technologie d'élagage des réseaux neuronaux et la technologie PEFT pour améliorer encore l'efficacité. Les tâches représentatives incluent AdapterDrop, SparseAdapter, etc. Stratégie de quantification PEFT : C'est-à-dire réduire la taille du modèle en réduisant la précision du modèle, améliorant ainsi l'efficacité des calculs. En combinaison avec PEFT, la principale difficulté est de savoir comment mieux équilibrer les poids de pré-entraînement et le traitement de quantification du nouveau module PEFT. Les travaux représentatifs incluent QLoRA, LoftQ, etc. Conception PEFT efficace en mémoire : Bien que PEFT ne soit capable de mettre à jour qu'un petit nombre de paramètres pendant l'entraînement, son empreinte mémoire est toujours importante en raison de la nécessité de calculer le gradient et de rétropropagation. Pour relever ce défi, certaines méthodes tentent de réduire la surcharge de mémoire en contournant le calcul du gradient à l'intérieur des poids pré-entraînés, telles que Side-Tuning et LST. En parallèle, d’autres méthodes tentent d’éviter la rétropropagation au sein du LLM pour résoudre ce problème, comme HyperTuning, MeZO, etc. 4. Applications inter-domaines du PEFTDans ce chapitre, l'auteur explore les applications du PEFT dans différents domaines et explique comment concevoir de meilleures méthodes PEFT pour améliorer des modèles ou des tâches spécifiques. discuté. Cette section se concentre principalement sur divers modèles pré-entraînés à grande échelle, notamment LLM, Visual Transformer (ViT), le modèle de texte visuel et le modèle de diffusion, et décrit en détail le rôle de PEFT dans l'adaptation des tâches en aval de ces modèles pré-entraînés. En termes de LLM, l'auteur a présenté comment utiliser PEFT pour affiner LLM afin d'accepter la saisie d'instructions visuelles, des travaux représentatifs tels que LLaMA-Adapter. En outre, l'auteur explore également l'application du PEFT dans l'apprentissage continu du LLM et mentionne comment affiner le LLM avec le PEFT pour élargir sa fenêtre contextuelle. Pour ViT, l'auteur décrit comment utiliser la technologie PEFT pour l'adapter aux tâches de reconnaissance d'images en aval, et comment utiliser PEFT pour donner à ViT des capacités de reconnaissance vidéo. En termes de modèles de texte visuel, l'auteur a présenté de nombreux travaux appliquant PEFT pour affiner les modèles de texte visuel pour les tâches de classification d'images ouvertes. Pour le modèle de diffusion, l'auteur identifie deux scénarios courants : comment ajouter des entrées supplémentaires en plus du texte et comment réaliser une génération personnalisée, et décrit l'application de PEFT dans ces deux types de tâches respectivement. 5. Défis de conception du système PEFT Dans ce chapitre, l'auteur décrit d'abord les défis rencontrés par le système PEFT basé sur les services cloud. Il comprend principalement les points suivants : Service de requête PEFT centralisé : Dans ce mode, le serveur cloud stocke une seule copie du modèle LLM et plusieurs modules PEFT. Selon les exigences des différentes requêtes PEFT, le serveur cloud sélectionnera le module PEFT correspondant et l'intégrera au modèle LLM. Service de requête PEFT distribué : Dans ce mode, le modèle LLM est stocké sur le serveur cloud, tandis que les poids et ensembles de données PEFT sont stockés sur l'appareil utilisateur. La machine utilisateur utilise la méthode PEFT pour affiner le modèle LLM, puis télécharge les poids PEFT affinés et l'ensemble de données sur le serveur cloud. 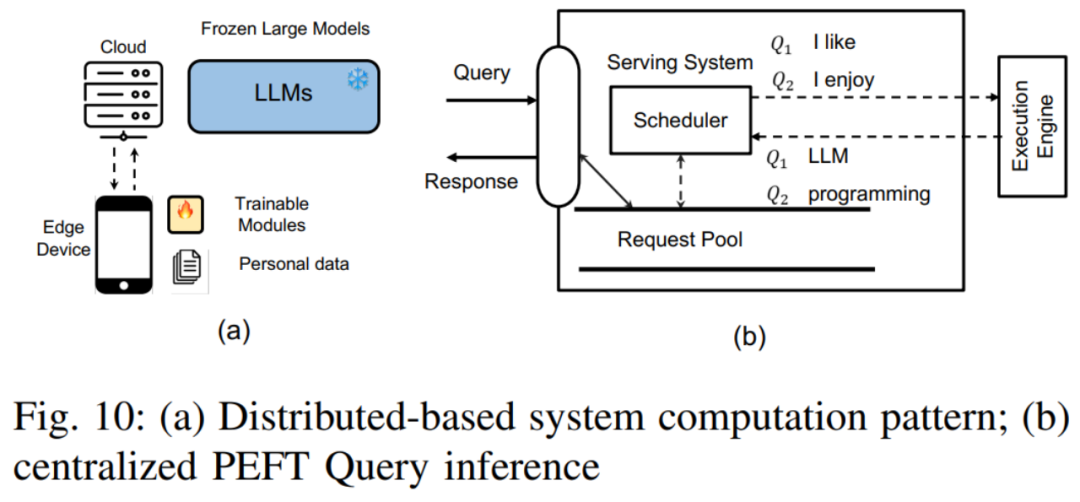 Formation PEFT multiple : Les défis incluent comment gérer les gradients de mémoire et le stockage du poids du modèle, et comment concevoir un noyau efficace pour entraîner le PEFT par lots, etc.
Formation PEFT multiple : Les défis incluent comment gérer les gradients de mémoire et le stockage du poids du modèle, et comment concevoir un noyau efficace pour entraîner le PEFT par lots, etc.
En réponse aux défis de conception de système ci-dessus, l'auteur a répertorié trois cas de conception de système détaillés pour fournir une analyse plus approfondie de ces défis et des stratégies de solutions réalisables. Réglage hors site : Résout principalement le dilemme de la confidentialité des données et les problèmes massifs de consommation de ressources qui surviennent lors du réglage fin du LLM. PetS : Fournit un cadre de service unifié et fournit un mécanisme de gestion et de planification unifié pour les modules PEFT. 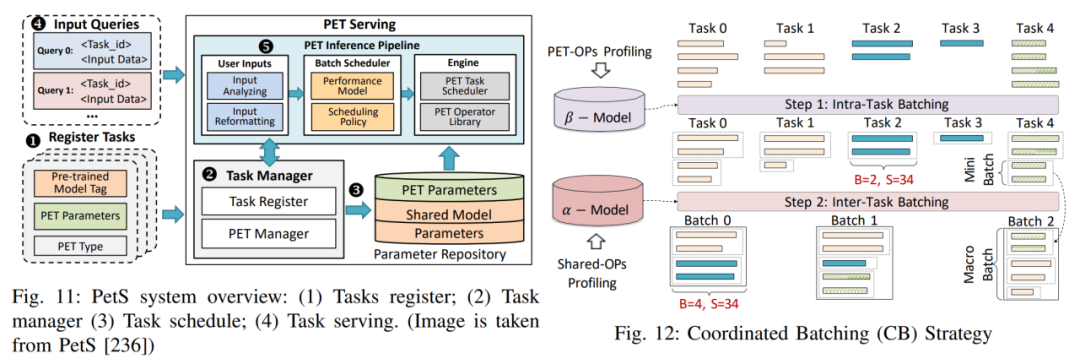
Cadre de formation parallèle PEFT : Présente deux cadres de formation PEFT parallèles, dont S-LoRA et Punica, et comment ils améliorent l'efficacité de la formation PEFT. 6. Orientations futures de la recherche L'auteur estime que même si la technologie PEFT a réussi dans de nombreuses tâches en aval, certaines lacunes doivent encore être résolues dans les travaux futurs. Établir un référentiel d'évaluation unifié : Bien que certaines bibliothèques PEFT existent, il manque un référentiel complet pour comparer équitablement l'efficacité et l'efficience des différentes méthodes PEFT. L’établissement d’une référence reconnue favorisera l’innovation et la collaboration au sein de la communauté. Efficacité de l'entraînement améliorée : La quantité de paramètres pouvant être entraînés par le PEFT n'est pas toujours cohérente avec les économies de calcul et de mémoire pendant l'entraînement. Comme indiqué dans la section Conception efficace du PEFT, les recherches futures pourront explorer davantage les moyens d’optimiser la mémoire et l’efficacité informatique. Explorer la loi de la mise à l'échelle : De nombreuses techniques PEFT sont mises en œuvre sur des modèles de transformateurs plus petits, et leur efficacité n'est pas nécessairement applicable aux différents modèles actuels à grands paramètres. Des recherches futures pourraient explorer comment adapter la méthode PEFT aux grands modèles. Au service de plus de modèles et de tâches : Avec l'émergence de modèles à plus grande échelle, tels que Sora, Mamba, etc., la technologie PEFT peut débloquer de nouveaux scénarios d'application. Les recherches futures pourraient se concentrer sur la conception de méthodes PEFT pour des modèles et des tâches spécifiques. Confidentialité améliorée des données : Les systèmes centralisés peuvent être confrontés à des problèmes de confidentialité des données lors de la diffusion ou du réglage précis de modules PEFT personnalisés. Des recherches futures pourraient explorer les protocoles de cryptage pour protéger les données personnelles et les résultats intermédiaires de formation/inférence. PEFT et compression de modèle : L'impact des techniques de compression de modèle telles que l'élagage et la quantification sur la méthode PEFT n'a pas été entièrement étudié. Les recherches futures pourraient se concentrer sur la manière dont le modèle compressé s’adapte aux performances de la méthode PEFT. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

