
Maison >Périphériques technologiques >IA >CVPR 2024 | Modèle de diffusion LiDAR pour la génération de scènes photoréalistes
CVPR 2024 | Modèle de diffusion LiDAR pour la génération de scènes photoréalistes

- PHPzavant
- 2024-04-24 16:28:01894parcourir
Titre original : Vers une génération de scènes réalistes avec des modèles de diffusion LiDAR
Lien papier : https://hancyran.github.io/assets/paper/lidar_diffusion.pdf
Lien code : https://lidar-diffusion.github. io
Affiliation de l'auteur : CMU Toyota Research Institute University of Southern California

Idée de thèse :
Les modèles de diffusion (DM) excellent dans la synthèse d'images photoréalistes, mais les adaptent à la génération de scènes lidar L'existence est confrontée à des défis majeurs. Cela est principalement dû au fait que les DM opérant dans l'espace de points ont du mal à conserver le style de courbe et les caractéristiques tridimensionnelles des scènes lidar, ce qui consomme la plupart de leurs capacités de représentation. Cet article propose des modèles de diffusion LiDAR (LiDM), qui simulent des scénarios LiDAR réels en incorporant une compression géométrique dans le processus d'apprentissage. Cet article présente la compression de courbe pour simuler des modèles lidar du monde réel et le codage par patch pour obtenir un contexte d'objet 3D complet. Avec ces trois conceptions principales, cet article établit un nouveau SOTA dans des scénarios de génération lidar inconditionnelle tout en maintenant une efficacité élevée (jusqu'à 107 fois plus rapide) par rapport aux DM basés sur des points. De plus, en compressant les scènes lidar dans un espace latent, cet article permet aux DM de contrôler dans diverses conditions, telles que des cartes sémantiques, des vues de caméra et des invites textuelles.
Principales contributions :
Cet article propose un nouveau modèle de diffusion de fléchettes laser (LiDM), un modèle génératif capable de générer des scènes lidar réalistes basées sur des conditions d'entrée arbitraires. À notre connaissance, il s’agit de la première méthode capable de générer des scènes lidar à partir de conditions multimodales.
Cet article présente la compression au niveau de la courbe pour conserver des motifs laser réalistes, la supervision des coordonnées au niveau du point pour standardiser le modèle de géométrie au niveau de la scène et le codage au niveau du bloc pour capturer pleinement le contexte des objets 3D.
Cet article présente trois indicateurs pour évaluer de manière globale et quantitative la qualité de la scène laser générée dans l'espace perceptuel, en comparant diverses représentations, notamment les images de distance, les volumes clairsemés et les nuages de points.
La méthode décrite dans cet article atteint le dernier niveau en matière de synthèse de scènes inconditionnelles en utilisant des scènes lidar à 64 lignes et atteint une augmentation de vitesse jusqu'à 107 fois par rapport au modèle de diffusion basé sur des points.
Conception Web :
Ces dernières années ont vu le développement rapide de modèles génératifs conditionnels capables de générer des images visuellement attrayantes et très réalistes. Parmi ces modèles, les modèles de diffusion (DM) sont devenus l’une des méthodes les plus populaires en raison de leurs performances impeccables. Pour réaliser la génération dans des conditions arbitraires, les modèles de diffusion latente (MLD) [51] combinent des mécanismes d'attention croisée et des auto-encodeurs convolutifs pour générer des images haute résolution. Ses extensions ultérieures (par exemple, Stable Diffusion [2], Midjourney [1], ControlNet [72]) ont encore amélioré son potentiel de synthèse d'images conditionnelles.
Ce succès a déclenché la réflexion de cet article : Pouvons-nous appliquer des modèles de diffusion contrôlables (DM) à la génération de scènes lidar dans la conduite autonome et la robotique ? Par exemple, étant donné un ensemble de cadres englobants, ces modèles peuvent-ils synthétiser les scènes lidar correspondantes, convertissant ainsi ces cadres englobants en données d'annotation coûteuses et de haute qualité ? Alternativement, est-il possible de générer une scène 3D à partir d’un simple ensemble d’images ? De manière encore plus ambitieuse, pourrions-nous concevoir un générateur lidar piloté par le langage pour une simulation contrôlée ? Pour répondre à ces questions étroitement liées, l'objectif de cet article est de concevoir un modèle de diffusion pouvant combiner plusieurs conditions (par exemple, mise en page, vue de la caméra, texte) pour générer des scènes lidar réalistes.
Pour cela, cet article tire quelques enseignements de travaux récents sur les modèles de diffusion (DM) dans le domaine de la conduite autonome. Dans [75], un modèle de diffusion basé sur des points (c'est-à-dire LiDARGen) est introduit pour la génération inconditionnelle de scènes lidar. Cependant, ce modèle produit souvent des arrière-plans bruyants (par exemple des routes, des murs) et des objets flous (par exemple des voitures), ce qui génère des scènes lidar loin de la réalité (voir Figure 1). De plus, l’étalement des points sans aucune compression rend le processus d’inférence plus lent sur le plan informatique. De plus, l’application directe de modèles de diffusion basés sur des patchs (c’est-à-dire la diffusion latente [51]) à la génération de scènes lidar ne permet pas d’obtenir des performances satisfaisantes, tant qualitativement que quantitativement (voir Figure 1).
Pour parvenir à une génération de scènes lidar réalistes et conditionnelles, cet article propose un générateur basé sur des courbes appelé modèles de diffusion lidar (LiDM) pour répondre aux questions ci-dessus et combler les lacunes des travaux récents. Les LiDM sont capables de gérer des conditions arbitraires telles que des cadres de délimitation, des images de caméra et des cartes sémantiques. Les LiDM utilisent des images de distance comme représentations de scène LiDAR, qui sont très courantes dans diverses tâches en aval telles que la détection [34, 43], la segmentation sémantique [44, 66] et la génération [75]. Ce choix est basé sur la conversion réversible et sans perte entre les images de distance et les nuages de points, ainsi que sur les avantages significatifs tirés des opérations de convolution 2D hautement optimisées. Afin de saisir l'essence sémantique et conceptuelle de la scène lidar pendant le processus de diffusion, notre méthode convertit les points d'encodage de la scène lidar en un espace latent perceptuellement équivalent avant le processus de diffusion.
Pour améliorer encore la simulation réaliste des données lidar du monde réel, cet article se concentre sur trois éléments clés : l'authenticité des motifs, l'authenticité géométrique et l'authenticité des objets. Premièrement, cet article utilise la compression de courbe pour maintenir le modèle de courbe des points pendant le codage automatique, qui s'inspire de [59]. Deuxièmement, afin d'atteindre l'authenticité géométrique, cet article introduit la supervision des coordonnées au niveau du point pour apprendre à notre auto-encodeur à comprendre la structure géométrique au niveau de la scène. Enfin, nous élargissons le champ réceptif en ajoutant des stratégies supplémentaires de sous-échantillonnage au niveau des blocs pour capturer le contexte complet d'objets visuellement plus grands. Amélioré par ces modules proposés, l'espace perceptuel résultant permet au modèle de diffusion de synthétiser efficacement des scènes lidar de haute qualité (voir Figure 1), tout en offrant de bonnes performances en termes de vitesse par rapport aux modèles de diffusion basés sur des points (évalués sur NVIDIA). RTX 3090) et prend en charge tout type de conditions basées sur des images et des jetons.
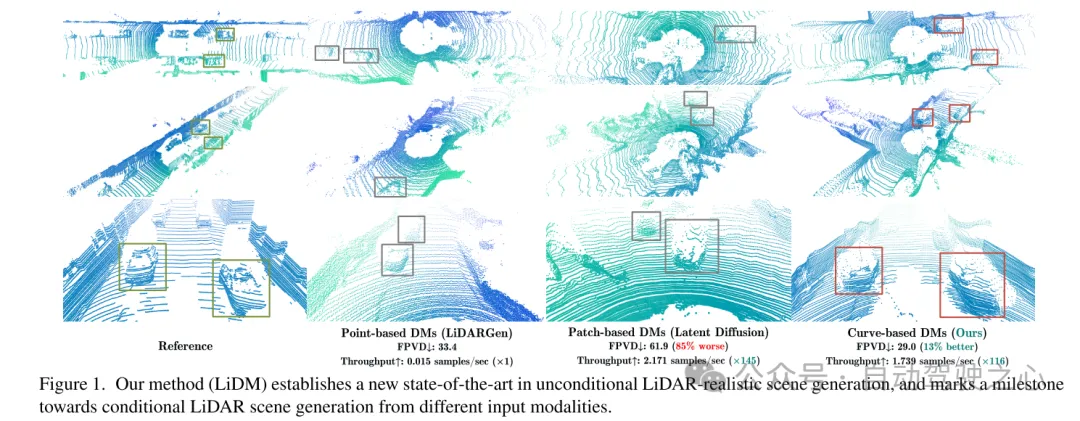
Figure 1. Notre méthode (LiDM) établit un nouveau SOTA dans la génération de scènes réalistes LiDAR inconditionnelles et marque une étape importante dans la direction de la génération de scènes LiDAR conditionnelles à partir de différentes modalités d'entrée.
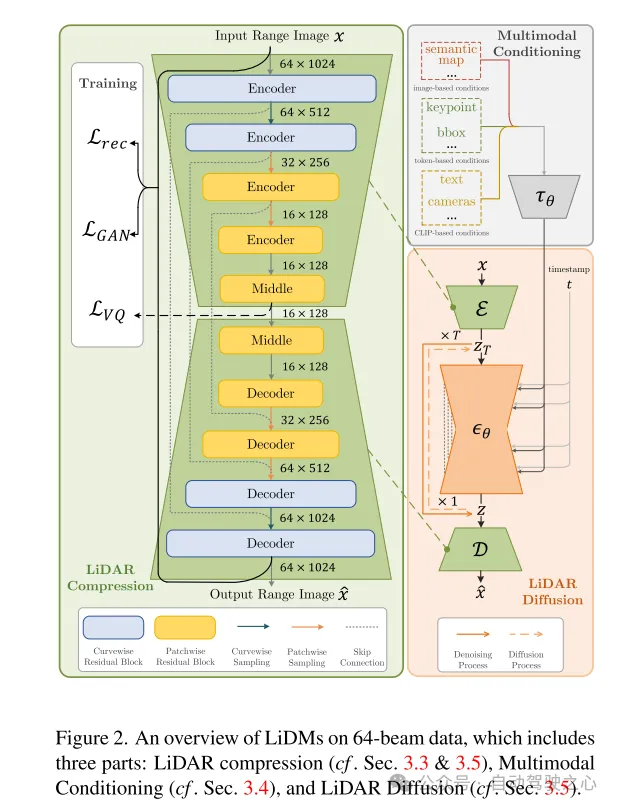
Figure 2. Aperçu des LiDM sur des données de 64 lignes, comprenant trois parties : compression LiDAR (voir sections 3.3 et 3.5), conditionalisation multimodale (voir section 3.4) et diffusion LiDAR (voir section 3.5).
Résultats expérimentaux :

Figure 3. Exemples de LiDM de LiDARGen [75], Latent Diffusion [51] et cet article dans le scénario 64 lignes.

Figure 4. Exemple de LiDM de cet article dans le scénario de 32 lignes.
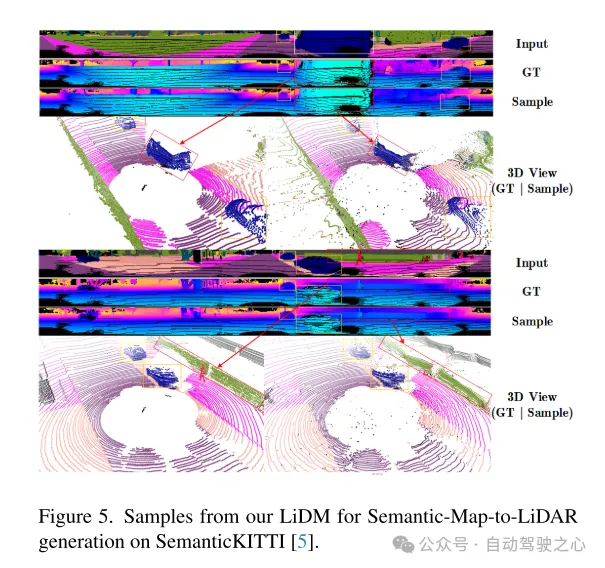
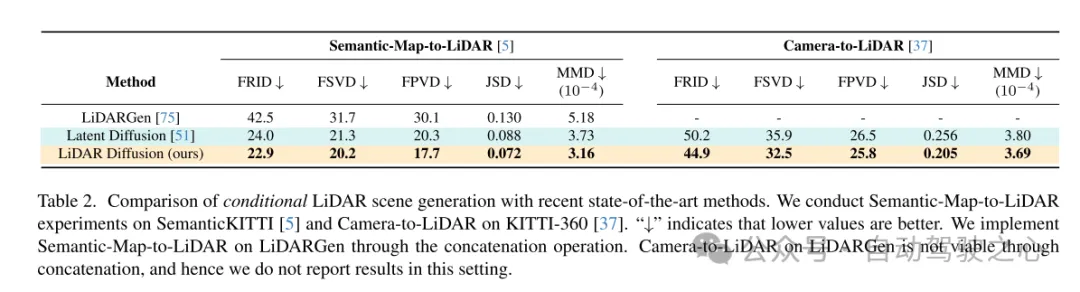
Figure 5. Exemple du LiDM de cet article pour la génération de cartes sémantiques vers lidar sur l'ensemble de données SemanticKITTI [5].
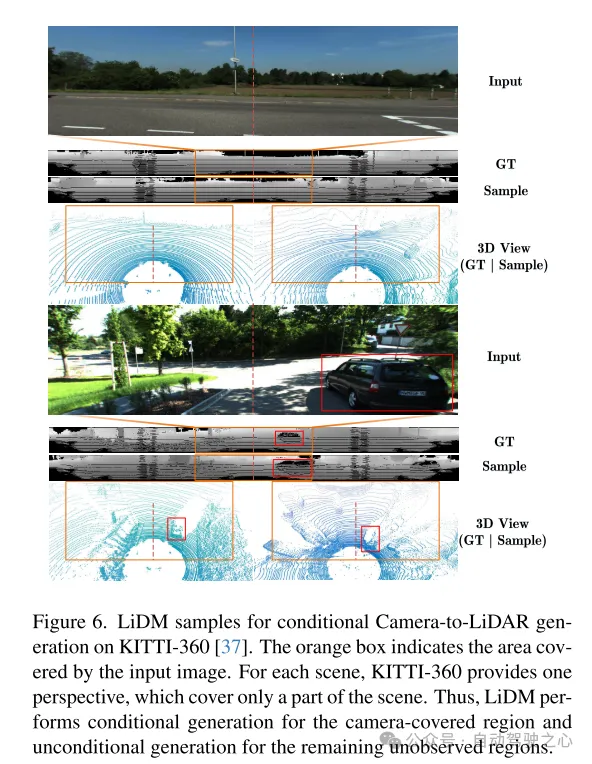
Figure 6. Exemple de LiDM pour la génération conditionnelle caméra-lidar sur l'ensemble de données KITTI-360 [37]. La case orange indique la zone couverte par l’image d’entrée. Pour chaque scène, KITTI-360 fournit une perspective qui ne couvre qu'une partie de la scène. Par conséquent, LiDM effectue une génération conditionnelle sur les zones couvertes par la caméra et une génération inconditionnelle sur les zones restantes non observées.
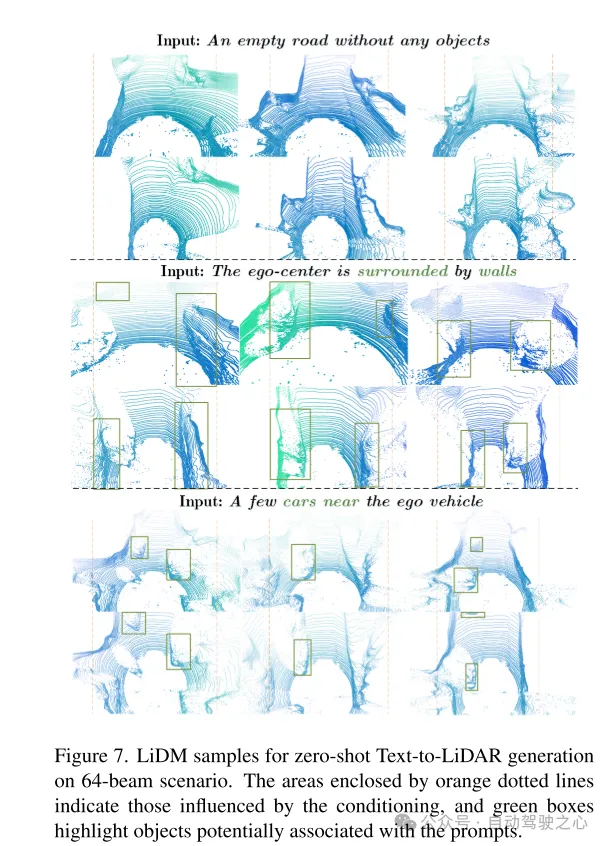
Figure 7. Exemple de LiDM pour la génération texte-lidar sans tir dans un scénario de 64 lignes. La zone encadrée par la ligne pointillée orange représente la zone affectée par la condition, et le cadre vert met en évidence les objets pouvant être associés au mot indicateur.
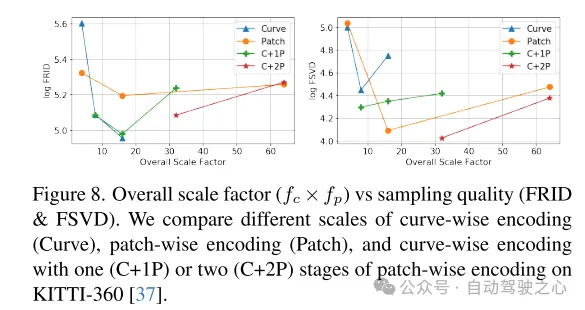
Figure 8. Facteur d'échelle global ( ) par rapport à la qualité d'échantillonnage (FRID et FSVD). Cet article compare le codage au niveau courbe (Curve), le codage au niveau bloc (Patch) et les courbes avec une (C+1P) ou deux (C+2P) étapes de codage au niveau bloc à différentes échelles sur le KITTI-360 [ 37] encodage au niveau de l’ensemble de données.
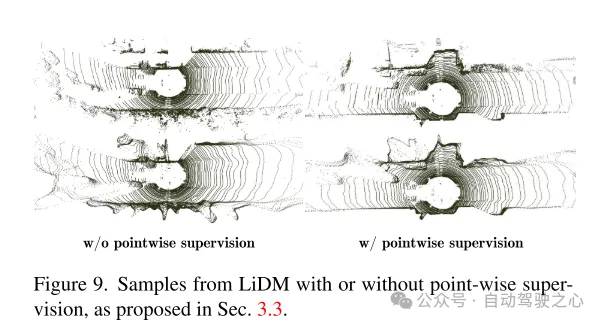
Figure 9. Exemples de LiDM avec et sans supervision de niveau ponctuel, comme proposé dans la section 3.3.

Résumé :
Cet article propose des modèles de diffusion LiDAR (LiDM), un cadre conditionnel général pour la génération de scènes LiDAR. La conception de cet article se concentre sur le maintien du motif incurvé et de la structure géométrique du niveau scène et du niveau objet, et conçoit un espace latent efficace pour le modèle de diffusion afin d'obtenir une génération lidar réaliste. Cette conception permet aux LiDM présentés dans cet article d'atteindre des performances compétitives en matière de génération inconditionnelle dans un scénario de 64 lignes, et d'atteindre le niveau de pointe en matière de génération conditionnelle. Les LiDM peuvent être contrôlés à l'aide de diverses conditions, y compris des cartes sémantiques. , Vue de la caméra et invites textuelles. À notre connaissance, notre méthode est la première à introduire avec succès des conditions dans la génération lidar.
Citation :
@inproceedings{ran2024towards,
title={Vers une génération de scènes réalistes avec des modèles de diffusion LiDAR},
author={Ran, Haoxi et Guizilini, Vitor et Wang, Yue},
booktitle={Proceedings de la conférence IEEE/CVF sur la vision par ordinateur et la reconnaissance de formes},
année={2024}
}
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quelle est la différence entre Git et Github ?
- Aubizhong Photonics et Stander Robotics coopèrent en profondeur pour promouvoir conjointement la recherche et le développement d'une nouvelle génération de lidar
- La conduite intelligente mène la tendance, Nezha Automobile choisit Hesai Technology LiDAR
- Le Radarcoin augmentera-t-il en 2024 ? Est-ce que cela montera à 0,5 $ ?
- Comment aligner la tour radar dans Submarine 2