
Maison >Périphériques technologiques >IA >750 000 rounds de bataille en tête-à-tête entre grands modèles, GPT-4 a remporté le championnat et Llama 3 s'est classé cinquième
750 000 rounds de bataille en tête-à-tête entre grands modèles, GPT-4 a remporté le championnat et Llama 3 s'est classé cinquième

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-04-23 15:28:011005parcourir
Concernant Llama 3, il y a de nouveaux résultats de tests -
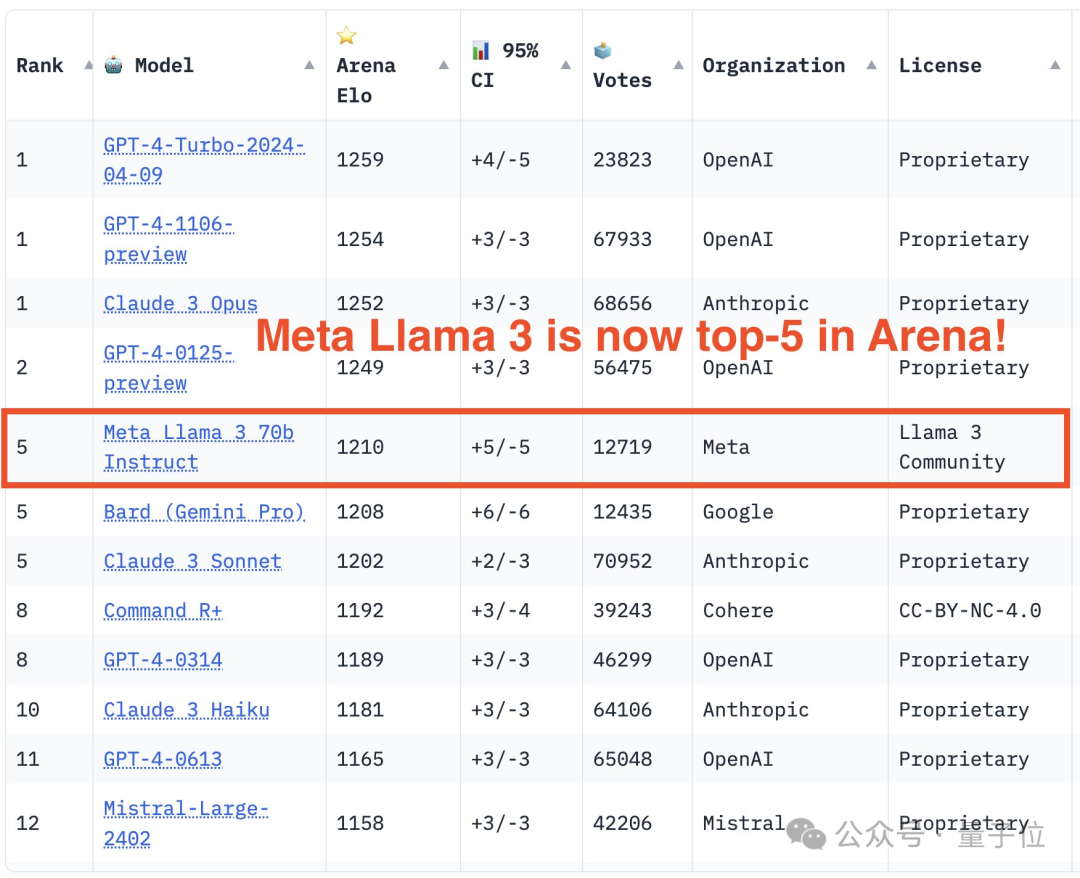
La grande communauté d'évaluation de modèles LMSYS a publié un grand classement de modèles, Llama 3 s'est classé cinquième et à égalité à la première place avec GPT-4 dans la catégorie anglaise.
 Photos
Photos
Différent des autres benchmarks, cette liste est basée sur des modèles de batailles individuelles, qui sont réalisées et notées par des évaluateurs à travers le réseau.
Au final, Llama 3 s'est classé cinquième sur la liste, suivi de trois versions différentes de GPT-4 et Claude 3 Super Cup Opus.
Dans la liste simple anglaise, Llama 3 a dépassé Claude et est à égalité avec GPT-4.
LeCun, le scientifique en chef de Meta, était très heureux de ce résultat et a retweeté le tweet et laissé un « Nice ».
 Photos
Photos
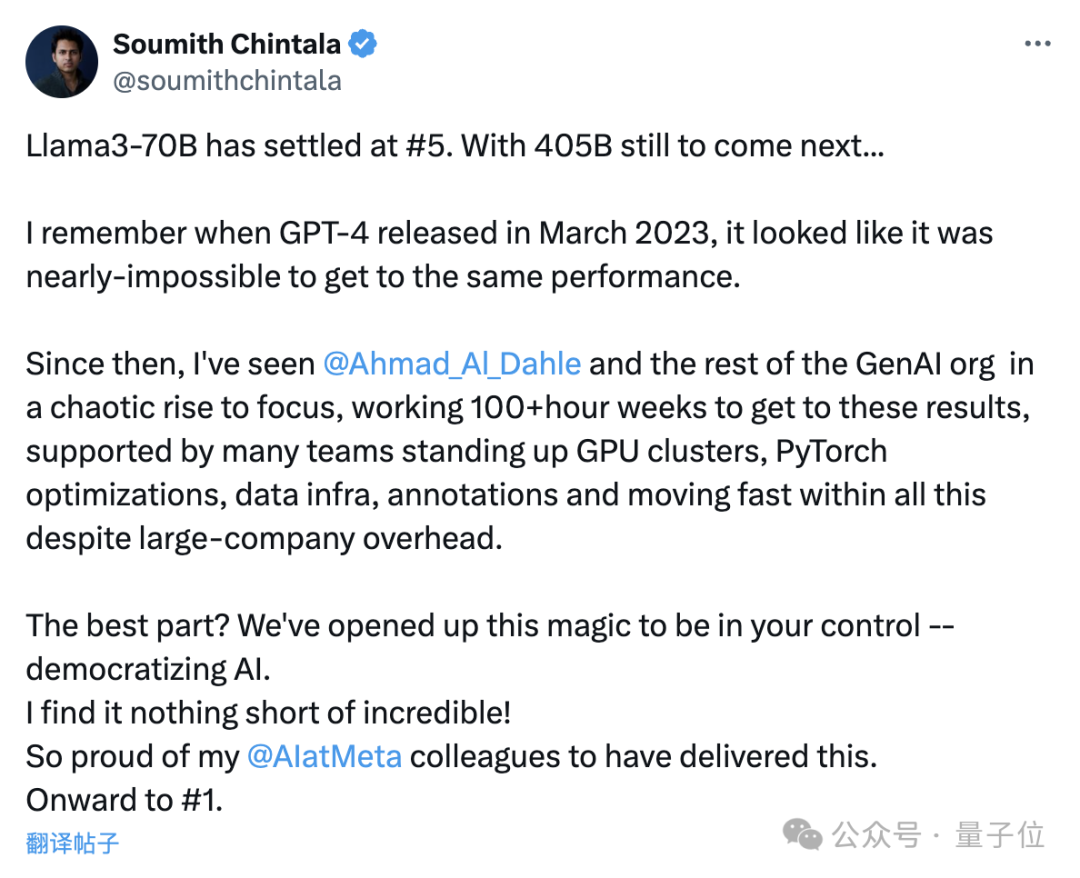
Soumith Chintala, le père de PyTorch, a également exprimé avec enthousiasme que de tels résultats sont incroyables et qu'il est fier de Meta.
La version 400B de Llama 3 n'est pas encore sortie, et elle a remporté la cinquième place avec les seuls paramètres 70B...
Je me souviens encore lorsque GPT-4 est sorti en mars de l'année dernière, il était presque impossible d'atteindre le même performance.
…
La popularisation de l'IA est aujourd'hui vraiment incroyable, et je suis très fier de mes collègues de Meta AI pour avoir obtenu un tel succès.
 Photos
Photos
Alors, quels résultats spécifiques cette liste montre-t-elle ?
Près de 90 modèles ont concouru dans 750 000 rounds
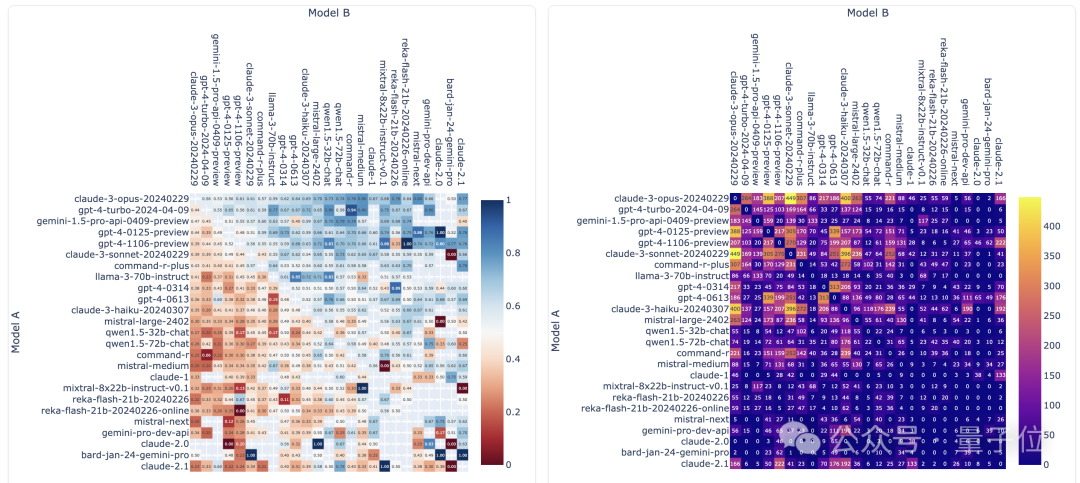
Depuis la publication de la dernière liste, LMSYS a collecté près de 750 000 résultats de batailles solo de grands modèles, impliquant 89 modèles.
Parmi eux, Llama 3 a participé 12 700 fois et GPT-4 a plusieurs versions différentes, la plus participante étant de 68 000 fois.
 Photo
Photo
L'image ci-dessous montre le nombre de compétitions et les taux de victoire de certains modèles populaires. Aucun des deux indicateurs de l'image ne compte le nombre de tirages.
 Photos
Photos
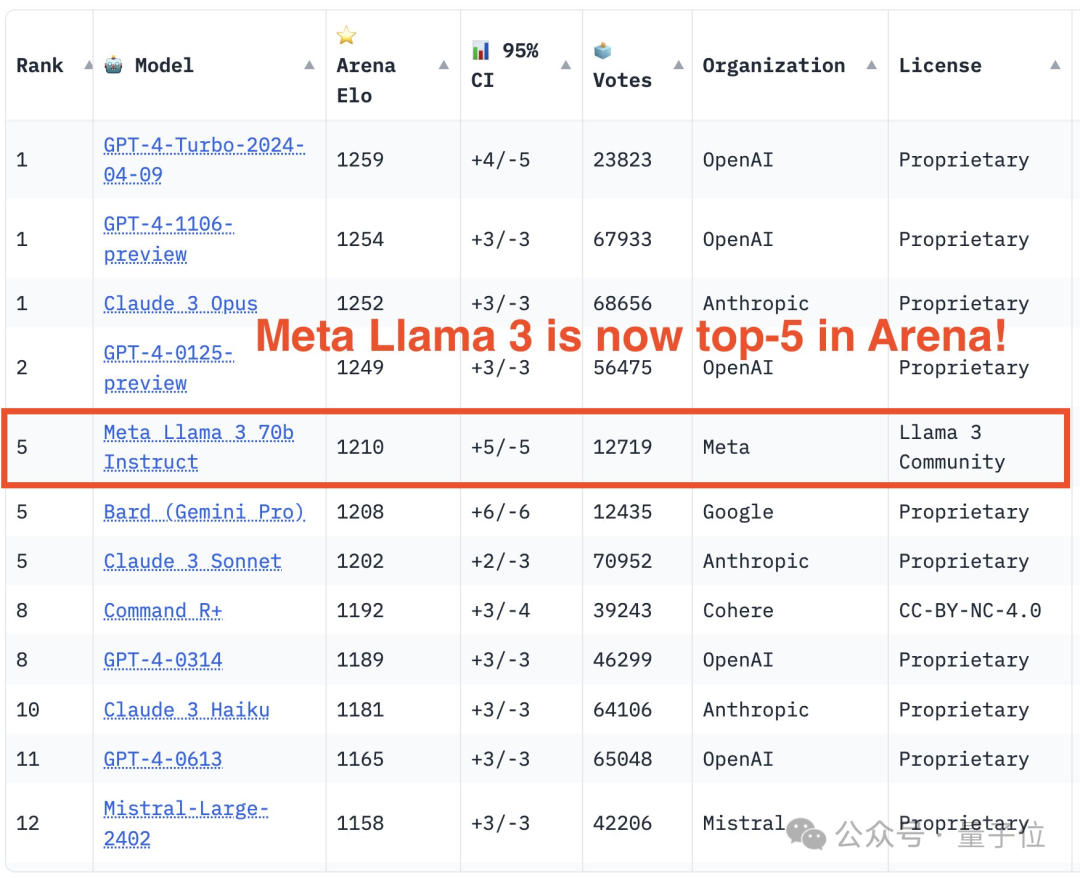
En termes de liste, LMSYS est divisé en une liste générale et plusieurs sous-listes. GPT-4-Turbo se classe premier, à égalité avec la version précédente 1106, et Claude 3 Super Large Cup Opus.
Une autre version (0125) de GPT-4 arrive en deuxième position, suivie de près par Llama 3.
Mais ce qui est plus intéressant, c'est que la nouvelle version 0125 ne fonctionne pas aussi bien que l'ancienne version 1106.
 Photos
Photos
Dans la liste unique anglaise, les résultats de Llama 3 sont directement à égalité avec les deux GPT-4, et ont même dépassé la version 0125.
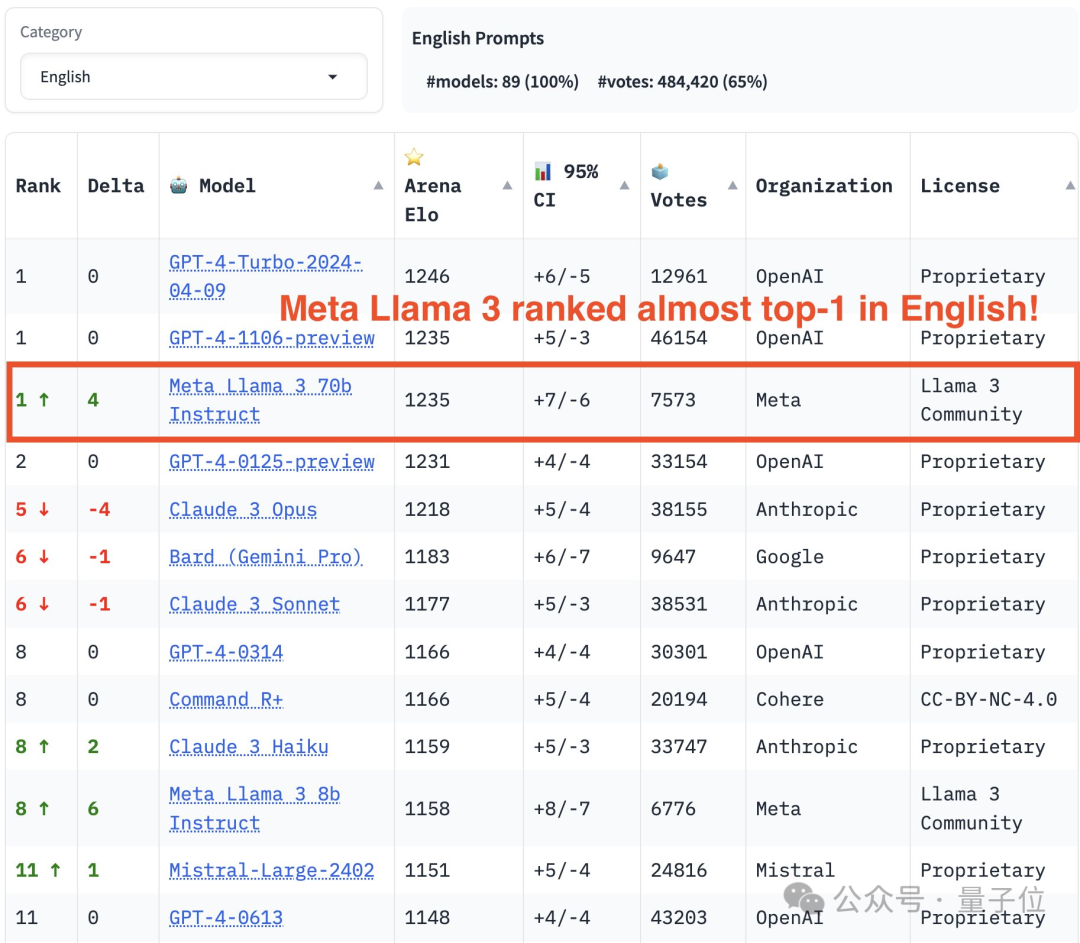 Photos
Photos
La première place du classement de compétence chinoise est partagée par Claude 3 Opus et GPT-4-1106, tandis que Llama 3 a été classé en dehors de la 20ème place.
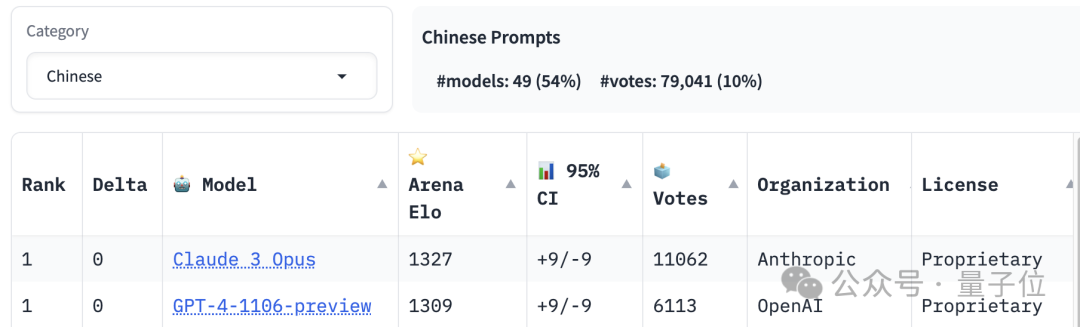 Photos
Photos
En plus des capacités linguistiques, la liste établit également des classements pour les textes longs et les capacités de codage, et Llama 3 est également parmi les meilleurs.
Mais quelles sont les « règles du jeu » spécifiques à LMSYS ?
Un test sur grand modèle auquel tout le monde peut participer
Il s'agit d'un test sur grand modèle auquel tout le monde peut participer. Les questions et les critères d'évaluation sont décidés par les participants eux-mêmes.
Le processus spécifique de « compétition » est divisé en deux modes : combat et côte à côte.
 Photos
Photos
En mode combat, après avoir entré la question sur l'interface de test, le système appellera au hasard deux modèles dans la bibliothèque, et le testeur ne sait pas qui le système a sélectionné, et seul "Modèle" est affiché dans l'interface A" et "Modèle B".
Une fois que le modèle a fourni la réponse, l'évaluateur doit choisir lequel est le meilleur ou l'égalité. Bien sûr, si les performances du modèle ne répondent pas aux attentes, il existe des options correspondantes.
Ce n'est qu'après une sélection que l'identité du modèle est révélée.
Côte à côte est l'endroit où l'utilisateur choisit le modèle spécifié pour PK. Le reste du processus de test est le même que pour le mode bataille.
Cependant, seuls les résultats du vote en mode anonyme de la bataille seront pris en compte. et le modèle peut ne pas faire attention pendant la conversation. Exposer votre identité invalidera les résultats.
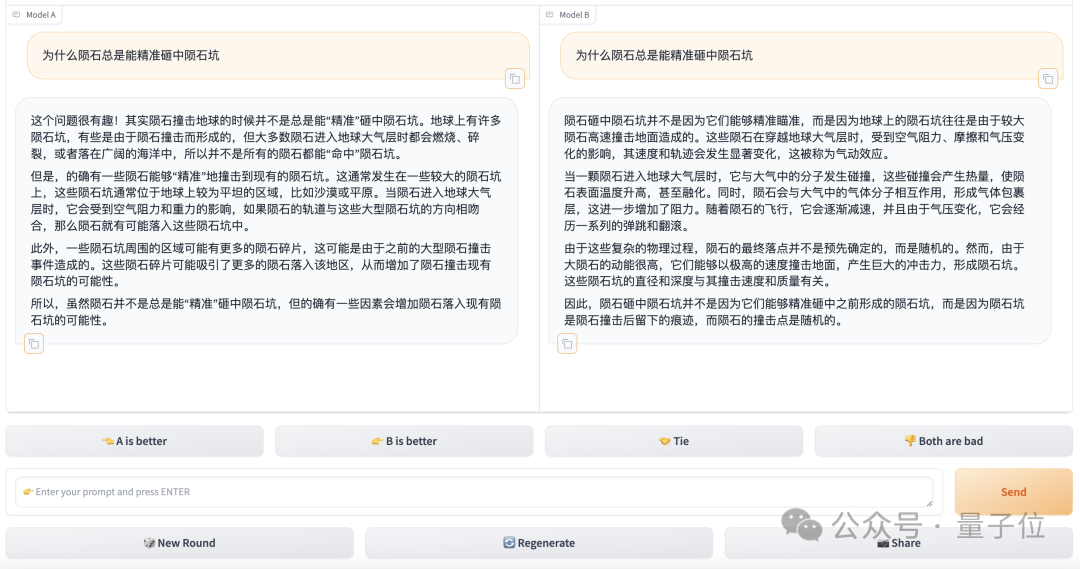 Photos
Photos
Selon le taux de victoire de chaque modèle par rapport aux autres modèles, une telle image peut être dessinée :
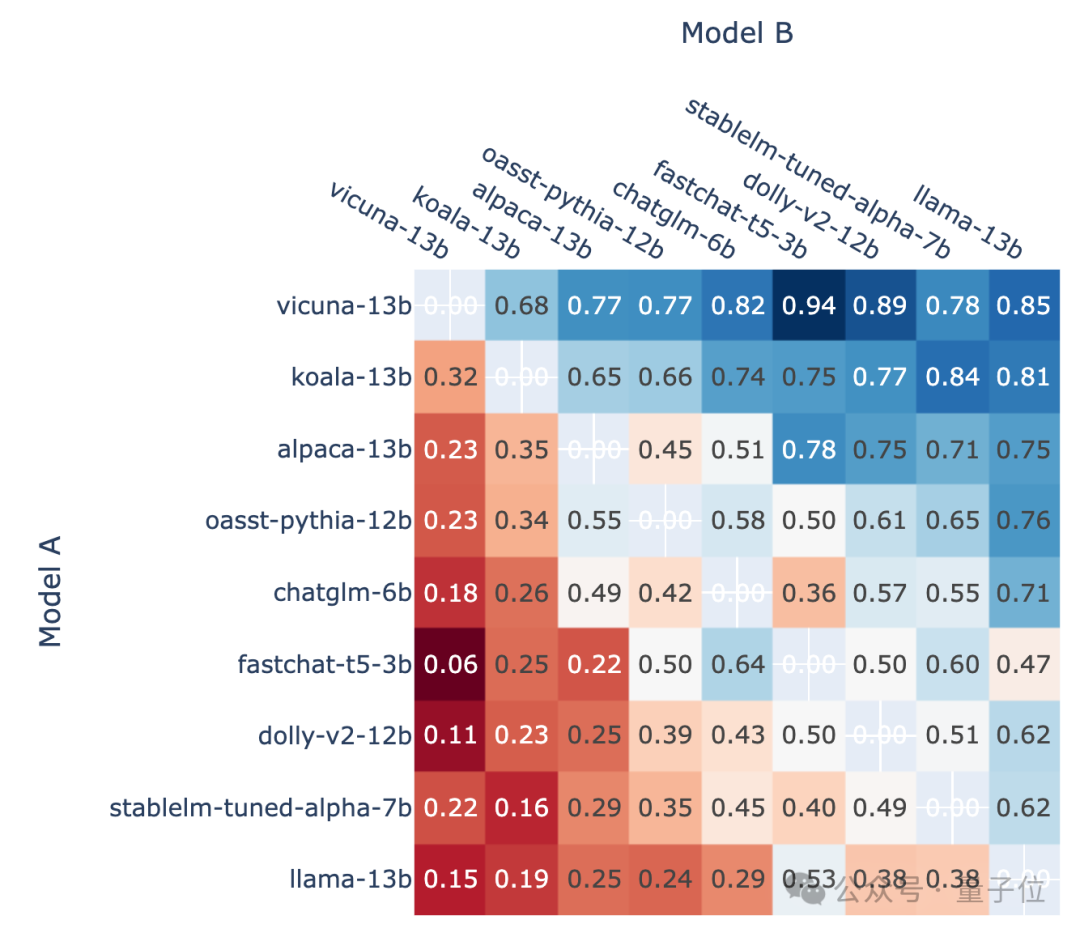 Photos
Photos
△Schéma schématique, version antérieure
Et le classement final utilise Win Les données de taux sont converties en scores via le système d'évaluation Elo.
Le système de notation Elo est une méthode de calcul du niveau de compétence relatif des joueurs, conçue par le professeur de physique américain Arpad Elo.
Spécifiquement pour LMSYS, dans les conditions initiales, les notes (R) de tous les modèles sont fixées à 1000, puis le taux de gain attendu (E) est calculé sur la base d'une telle formule.
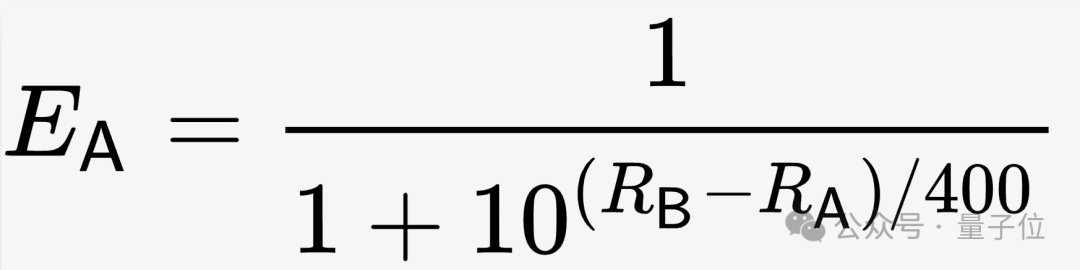 Photos
Photos
Au fur et à mesure du test, le score sera révisé en fonction du score réel (S a trois valeurs1, 0 et 0,5, correspondant aux trois situations de gagner, de perdre). et dessin respectivement.
L'algorithme de correction est présenté dans la formule suivante, où K est le coefficient qui doit être ajusté par le testeur en fonction de la situation réelle.
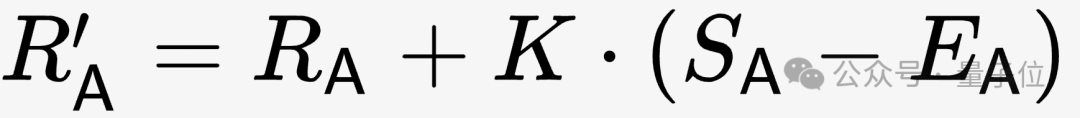 Photos
Photos
Enfin, une fois que toutes les données valides sont incluses dans le calcul, le score Elo du modèle est obtenu.
Cependant, lors de l'opération proprement dite, l'équipe LMSYS a constaté que la stabilité de cet algorithme était insuffisante, elle a donc utilisé des méthodes statistiques pour le corriger.
Ils ont utilisé la méthode Bootstrap pour un échantillonnage répété, ont obtenu des résultats plus stables et ont estimé l'intervalle de confiance.
Le score Elo final révisé est devenu la base du classement dans la liste.
One More Thing
Llama 3 peut déjà fonctionner sur la plateforme d'inférence de grands modèles Groq (pas Musk's Grok).
Le plus gros point fort de cette plateforme est sa « vitesse ». Auparavant, le modèle Mixtral était utilisé pour atteindre une vitesse de près de 500 jetons par seconde.
Llama 3 est également très rapide lors de l'exécution. On mesure en fait que la version 70B peut exécuter environ 300 jetons par seconde, et la version 8B est proche de 800.
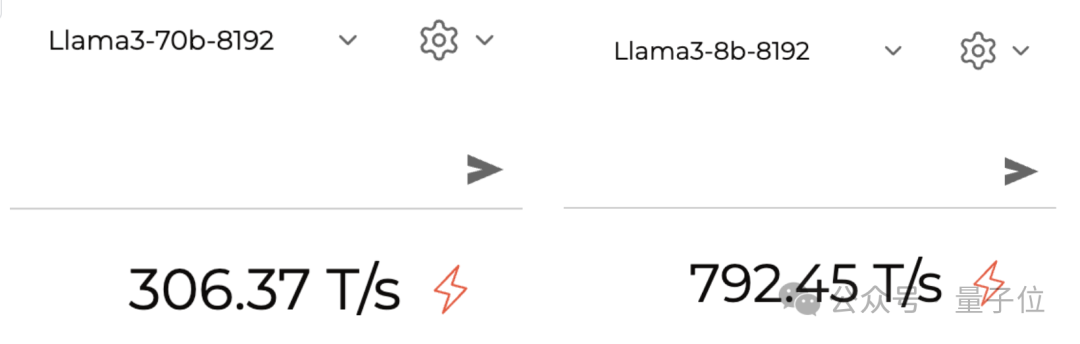 Photos
Photos
Lien de référence :
[1]https://lmsys.org/blog/2023-05-03-arena/
[2]https://chat.lmsys.org/?leaderboard
[3]https://twitter.com/lmsysorg/status/1782483699449332144
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quelles sont les deux manières d'écrire le tri à bulles ? Utilisez le tri à bulles pour organiser 10 nombres.
- commande d'affichage de la version Linux
- Comment définir la hauteur des lignes dans bootstrap
- 8 modèles de sites Web d'entreprise Bootstrap (téléchargement gratuit du code source)
- Comment vérifier la version de MySQL