La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com.
Avec le développement de l'intelligence artificielle, les modèles de langage et les modèles génératifs ont obtenu beaucoup de succès, et dans le processus de conception du modèle, le nombre de paramètres du modèle augmente également. Pour les tâches de compréhension fine, le nombre de paramètres du modèle augmente également. Cependant, il existe une contradiction entre l'échelle et la précision dans les ensembles de données existants. Par exemple, 99,1 % des masques de l'ensemble de données SA-1B sont générés par machine, mais il n'y a pas d'étiquettes sémantiques. Certains autres ensembles de données publics sont également précis. problèmes, et ceux-ci La taille de l'ensemble de données est généralement relativement petite. Récemment, ByteDance a proposé une nouvelle génération d'ensembles de données de compréhension fine. En réponse aux besoins de conception des modèles d'apprentissage profond contemporains, un total de 383 000 images ont été annotées manuellement pour la segmentation panoramique et ont finalement atteint 5,18 millions. Le masque Zhang est à ce jour le plus grand ensemble de données de compréhension de segmentation panoramique avec des étiquettes artificielles, nommé COCONut. Ce résultat a été sélectionné pour le CVPR2024. 
- Lien papier : https://arxiv.org/abs/2404.08639
- Lien code et ensemble de données : https://xdeng7.github.io/coconut.github.io/
La vidéo montre la densité du masque et les statistiques de catégorie sémantique d'une seule image de COCONut. On peut voir que la sémantique de l'ensemble de données est riche et la granularité de segmentation du masque est bonne. L'ensemble de données prend également en charge diverses tâches de compréhension, telles que la segmentation panoramique, la segmentation d'instance, la segmentation sémantique, la détection d'objets, la génération sémantiquement contrôlée et la segmentation de vocabulaire ouvert, permettant d'obtenir des améliorations significatives des performances sur plusieurs tâches simplement en remplaçant l'ensemble de données. 
Habituellement, l'utilisation uniquement de l'annotation manuelle est très coûteuse, ce qui est également une raison importante pour laquelle la plupart des ensembles de données publiques existantes ne peuvent pas augmenter d'échelle. Certains ensembles de données utilisent également directement les étiquettes générées par le modèle, mais souvent, ces étiquettes générées n'améliorent pas grandement la formation du modèle. Cet article le vérifie également. Par conséquent, cet article propose une nouvelle méthode d’annotation, combinée à une génération manuelle semi-automatique d’étiquettes. Cela peut non seulement garantir l'exactitude de l'annotation des données, mais également réduire le coût du travail manuel, tout en accélérant le processus d'annotation. 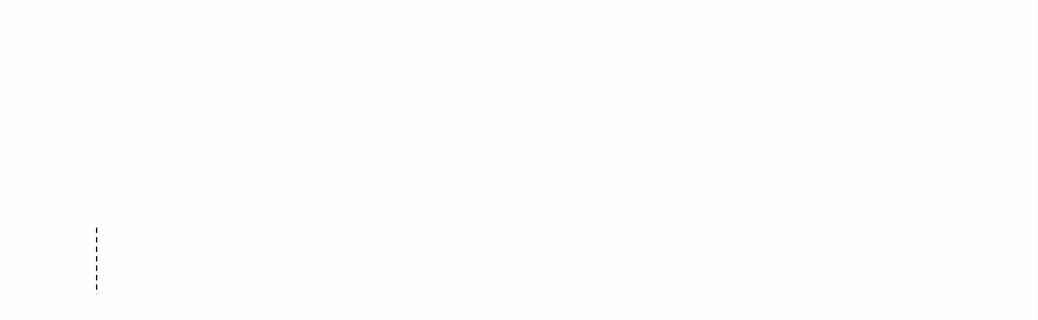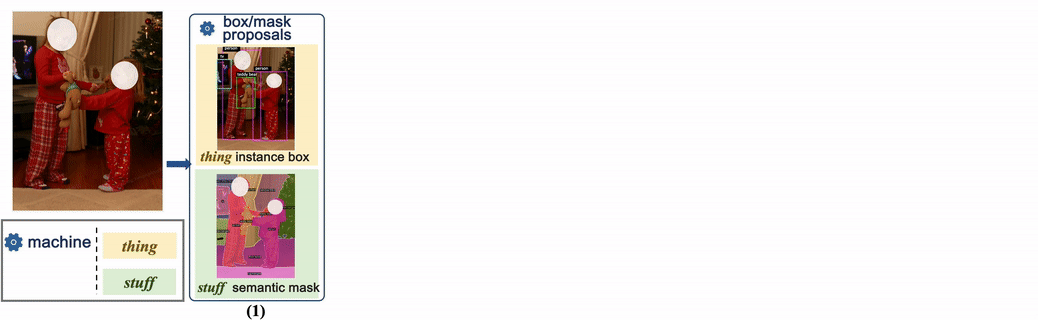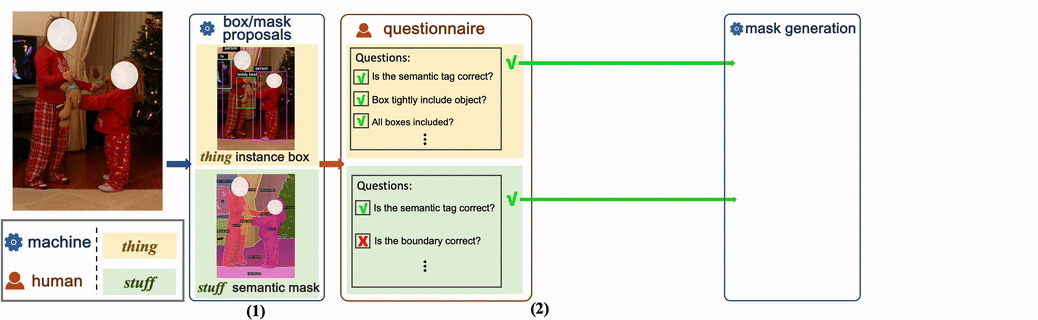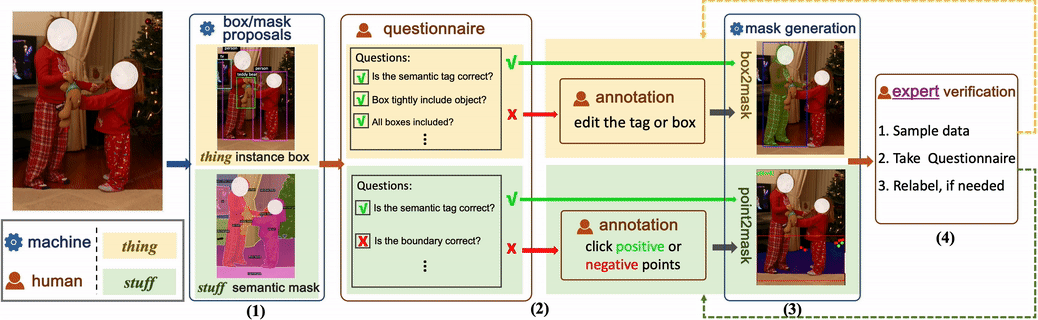
Comparaison de la précision des annotationsLes chercheurs ont comparé les annotations de COCONut et COCO sur la même image. D'après la comparaison dans la figure ci-dessous, nous pouvons voir que la méthode d'annotation proposée dans cet article atteint presque la même précision qu'une annotation purement manuelle à l'aide de Photoshop, mais la vitesse d'annotation est augmentée de plus de 10 fois. 

Détails de l'ensemble de données COCONutPar rapport à l'ensemble de données COCO existant, la distribution de chaque catégorie de l'ensemble de données est relativement similaire, mais la quantité totale de masques dans chaque image est supérieure à COCO ensemble de données, surtout lorsqu'il existe un grand nombre d'images uniques avec plus de 100 masques, ce qui montre que l'annotation de COCONut est plus raffinée et la segmentation granulaire est plus dense. 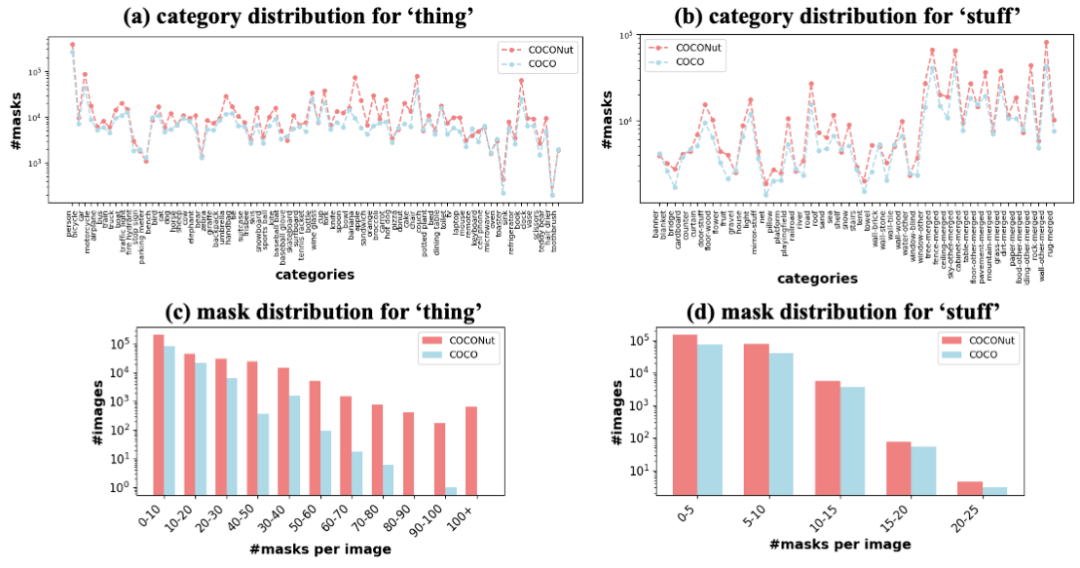
Vérification expérimentaleEn plus de proposer un meilleur ensemble de formation, les chercheurs ont également constaté que l'ensemble de vérification existant ne peut pas bien refléter l'amélioration des performances du modèle, cet article propose donc également un ensemble de tests plus stimulant qui peut refléter l'amélioration du modèle est nommé COCONut-val Comme le montre le tableau ci-dessous, seul le remplacement de l'ensemble de données et un ensemble d'entraînement de plus grande précision peuvent apporter de grandes améliorations au modèle, par exemple atteindre plus de 4 pouces. segmentation panoramique. Un point PQ. Cependant, lorsque la taille de l'ensemble de formation augmente, on peut constater que les tests avec l'ensemble de test existant ne reflètent pas l'amélioration du modèle, tandis que COCONut-val peut refléter que le modèle présente encore des améliorations évidentes après avoir augmenté la quantité de formation. définir les données promouvoir. 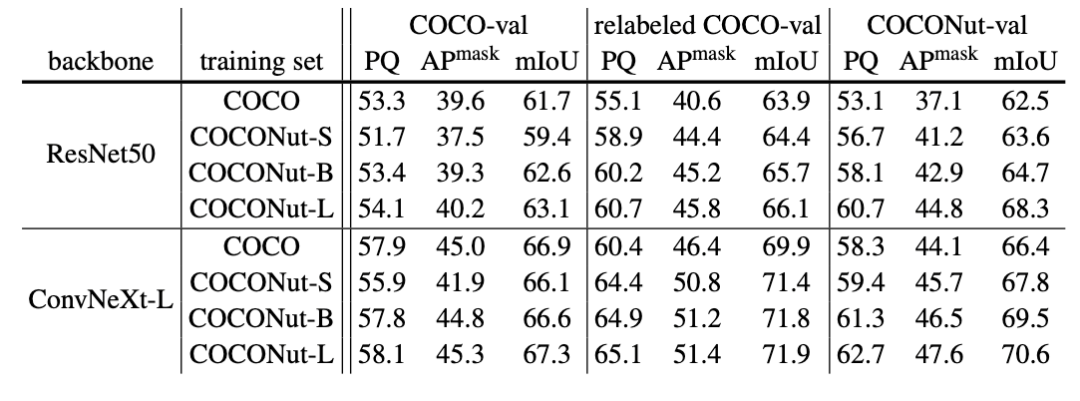
La figure suivante montre une comparaison des catégories sémantiques et de la densité des masques de l'ensemble de vérification. On peut voir que l'ensemble de vérification nouvellement proposé est plus difficile et peut mieux refléter l'amélioration du modèle. 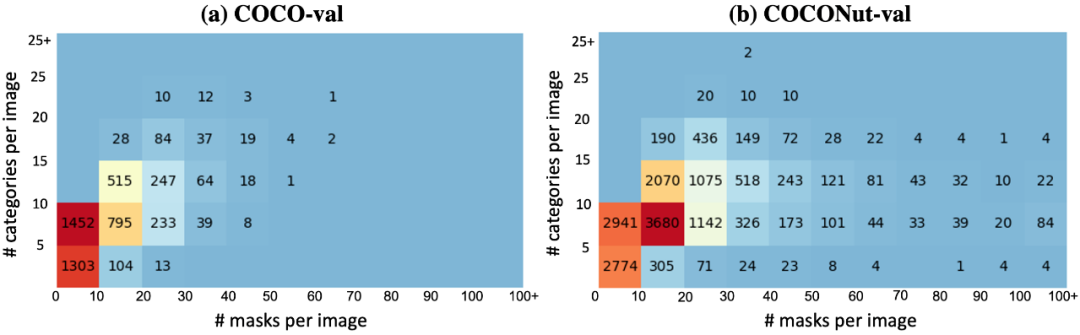
Pour plus de résultats expérimentaux, veuillez vous référer à l'article original. L'équipe fournira l'ensemble de données et le modèle correspondant pour téléchargement public sur la page d'accueil de GitHub. ByteDance Intelligent Creation TeamL'équipe de création intelligente est l'équipe d'IA et de technologie multimédia de ByteDance, couvrant la vision par ordinateur, le montage audio et vidéo, le traitement des effets spéciaux et d'autres domaines techniques, avec l'aide de l'entreprise Des scénarios commerciaux riches, des ressources d'infrastructure et une atmosphère de collaboration technique réalisent une boucle fermée d'algorithmes de pointe - de systèmes d'ingénierie - de produits, visant à fournir une compréhension de contenu, une création de contenu et une interaction de pointe pour diverses entreprises au sein de l'entreprise sous diverses formes. . Expérience et capacités de consommation et solutions industrielles. Actuellement, l'équipe de création intelligente a ouvert ses capacités techniques et ses services aux entreprises via Volcano Engine, une plateforme de services cloud appartenant à ByteDance. D’autres postes liés aux algorithmes de grands modèles s’ouvrent. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

